

R-CNN 是第一个成功将深度学习应用到目标检测上的算法,也是后续Fast R-CNN , Faster R-CNN等系列算法的鼻祖
一、R-CNN整体架构
R-CNN的全貌如下图所示
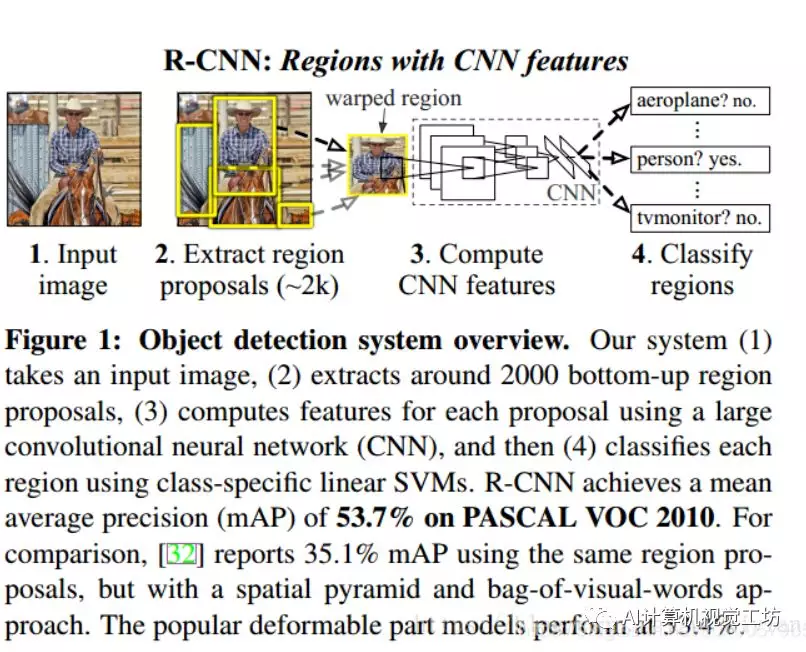
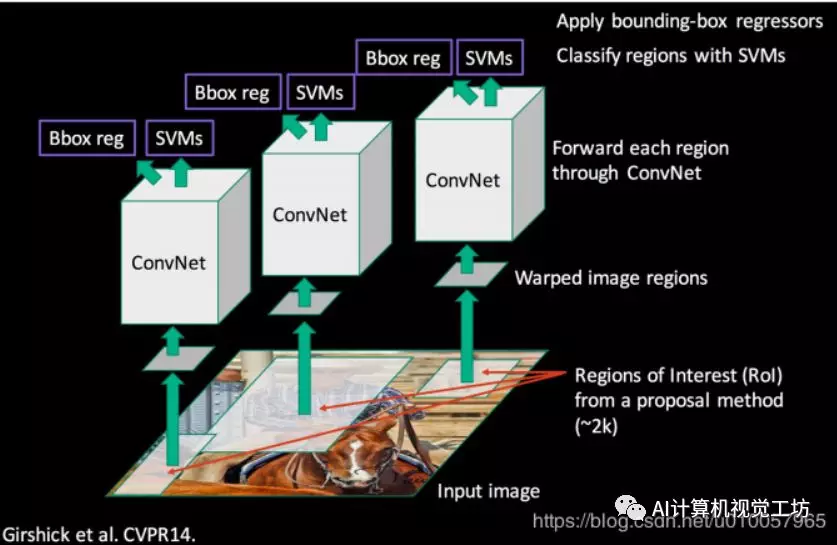
它主要分为4个模块
候选区域(region proposal)提取
一个大型的CNN网络用来特征提取
使用SVM分类模型进行类别分类
使用回归(Regression)模型进行具体定位
具体RCNN的训练流程如下:
先使用ImageNet数据集训练一个CNN网络(论文中使用的是AlexNet)
使用选择性搜索(selective search)算法提取出2000个候选框
将提取出来的候选框统一resize到 CNN网络所需要的尺寸
使用自己的数据集对CNN网络进行fine-tuning(微调)
利用fine-tuning后的CNN网络对候选框进行特征提取
训练多个二元SVM分类模型
Bounding-box回归来减少候选区域误差
二、具体模块设计
1.在ImageNet数据集上训练一个CNN网络
论文中提到,因为实际标签数据太少,远远不够去训练一个大型的CNN网络模型,所以需要先借助ImageNet数据集进行训练CNN网络,也就是预训练过程,然后再在自己的数据集上针对特定任务进行微调,也就是调优。这是在训练数据稀少的情况下一个非常有效的训练大型卷积神经网络的方法
2. 候选区域提取
R-CNN算法使用的 选择性搜索(selective search)算法提取出了2000个候选框,Selective search综合考虑图像的颜色、纹理、尺寸相似性和空间重合度来划分区域,并将小区域按照相似性合并为大区域。
具体选择SS算法的大概思路如下:
1. 使用图像分割算法创建候选区域
2. 使用贪心算法来进行候选区域合并:
计算所有候选区域的相似度
将最相似的两个候选区域合并为一个区域
3. 重复迭代2过程,直到满足条件
3.候选框的缩放
因为CNN网络输入的图像尺寸是固定(论文中为224*224),所以需要将不同大小的候选框resize到CNN网络所需要的尺寸,
候选区域大小调整选择最简单的各向异性缩放,同时论文中在缩放之前,还对原候选区域增加了一个边缘(padding),大小为16个像素,用原始图像中的点进行填充,这样使候选区域边缘有一定的缓冲
4. fine-tuning CNN网络
通过ImageNet数据集训练来的CNN网络是用来进行1000种类别分类,需要替换掉最后的分类层,改为一个随机初始化的K+1类分类层,K即为自己数据集上针对特定任务的目标分类数,后面+1是因为还需要加上背景类别。论文中作者是在VOC数据集上进行目标检测的,所以为20+1,即21个类别的分类任务。
CNN网络中的卷积层则保持不变。关于进行fine-tuning时的正负样本,如果候选框与真实标注框的IOU>=0.5,就认为此候选框为正样例,否则为负样例,另外,由于对于一张图片的多有候选区域来说,负样本是远远大于正样本数,所以需要将正样本进行上采样来保证样本分布均衡
在进行fine-tuning 时,需要选用比较小的学习率,以保证不会破坏初始化的成果,论文中所采用的learn_rate为0.001。每轮迭代,统一使用32个正例窗口(跨所有类别)和96个负例窗口(背景),即每个mini-batch的大小是128
5.候选框特征提取
R-CNN算法是用CNN网络来进行特征提取,然后用提取出来的特征进行后续的SVM分类。
所有需要将fine-tuning 后的CNN网络去掉最后的softmax层,然后用来对候选框进行特征提取
6. 训练多个二元SVM分类模型
R-CNN算法,对于每个类别单独训练一个二元SVM分类。这块有个问题,为什么不用上面CNN网络的softmax直接进行分类,而要把CNN网络提取出来的特征,重新用SVM进行分类?作者给出的答案是经过测试发现,重新使用SVM单独进行分类效果更好。另外,在训练每个SVM分类模型时,正负样本的构建和上面fine-tuning CNN网络 时有所不同。在训练对应某个类别的SVM分类模型时,ground-truth(即对应类别的真实标注框)为正样本,负样本为与ground-truth(真实标注框)的IOU小于0.3的候选框,也就是说IOU<0.3被作为负例,ground-truth是正例,其余的全部丢弃
7.Bounding-box回归
为了减少Selective search 候选框的误差,最后需要进行 Bounding-box Regression(BBR)来对候选框进行精修
这块需要注意,只有IOU值大于0.6的候选框,才会进行Bounding-box Regression
首先,来具体看下,Bounding-box Regression是什么,如下绿色框P为输入进来的候选框,红色框G为ground-truth,也就是真实标注框。我们的目标就是通过线性回归,训练一种关系,使得输入原始的窗口 P 经过映射得到一个回归窗口G'(蓝色框),需要尽可能的让回归窗口G'(蓝色框)跟真实窗口 G 更接近。
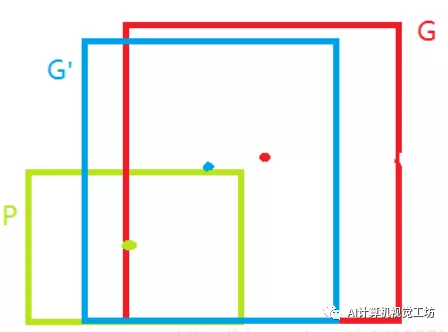
Bounding-box Regression的目的就是:给定(Px,Py,Pw,Ph),寻找一种映射f, 使得 f(Px,Py,Pw,Ph)=(Gx',Gy',Gw',Gh') 并且(Gx',Gy',Gw',Gh')≈(Gx,Gy,Gw,Gh)
所以我们需要经过平移和尺度缩放,将窗口P变为窗口G'。
首先看下平移变化,假设
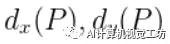
为对应平移转换,所以有:
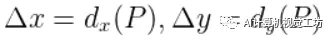
由于候选框的大小各不相同,所以这块需要使用相对位移来进行统一,所以
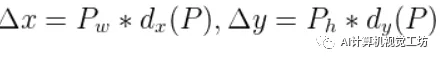
即
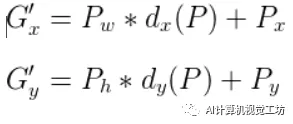
接下来看下尺度缩放:
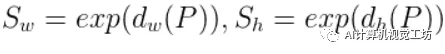
,这块统一进行对数变换,是为了确保缩放比例大于0
所以:
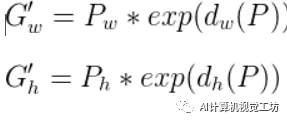
所以,Bounding-box Regression 最终是为了获得
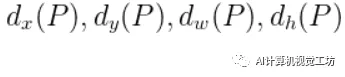
这四个变化。
Bounding-box Regression 的输入是一组N个训练对(P,G), 输出为
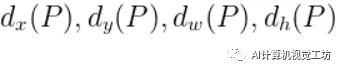
我们设从P到G实际的转换为:
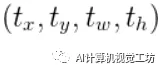
,所以有
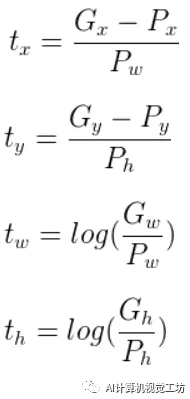
所以最终的损失函数为:
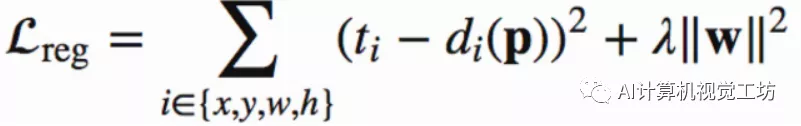
训练结束后,可以获得最终的
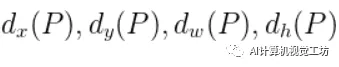
,进而获得
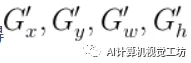
到此,R-CNN的训练就结束了
三、R-CNN不足之处
R-CNN作为目标检测算法中的一个里程碑之作,本身也就有许多缺点
首先,最大的一个缺点就是不管是预测还是训练,速度都很慢,
因为
1.候选框选择算法严重耗时
2.每张图片2000个候选框中会有很多重复的部分,从而导致后面在使用CNN时有很多重复计算
3.在进行候选区域的特征提取时,为了适应CNN网络的输入,需要对候选区域进行扭曲,缩放等操作,这会导致一些图片特征信息的丢失和变形,从而降低了检测的准确性
另外,RCNN是分步骤进行,过程比较繁琐
所有后面在此基础上,衍生出来其他一些目标检测算法,来对相关问题进行改进优化,具体我们后面再介绍
欢迎关注我的个人公众号 AI计算机视觉工坊,本公众号不定期推送机器学习,深度学习,计算机视觉等相关文章,欢迎大家和我一起学习,交流。

