

前言
本文是以作者自己理解的思路拆分的JS运行机制,见解有限难免疏漏,欢迎留言勘误、交流。
浏览器
浏览器的主要功能是向服务器发送请求,在窗口中展示目标网络资源。
伴随着浏览器的的普及,Javascript是作为浏览器的附属工具诞生的,当初主要是为了做浏览器端的简单校验。
浏览器的主要功能可以总结为
- 展示资源
- 功能交互
浏览器内核
浏览器的内核是支持浏览器运行的最核心的程序。 对应着上述浏览器的主要功能, 主要有两个部分:
- 渲染引擎
- Javascript引擎
渲染引擎
渲染引擎: 将HTML、CSS、Javascript文本及相应的资源转换成图像结果。
其主要作用解析资源文件并渲染在屏幕上。
同时,它也是我们通常所说的狭义的浏览器内核
想想看,提及浏览器内核我们立马想到的是什么?
- Webkit (safari、老版本的chrome)
- Trident (老朋友IE)
- Gecko (熟悉的陌生人Firefox)
- Blink (新版本的chrome)
它们的主要工作内容就是根据我们HTML、CSS、JS的定义,绘制出相应的页面结构及展现形式。
Javascript引擎
1.是什么?为什么?做什么?
Javascript 是解释型语言,在代码运行之前不会进行编译工作,将源码转换成字节码等中间代码或者是机器码,
而是在执行的过程中实时编译,边编译边执行。
因此需要一个功能模块做编译转换相关的工作,Javascript引擎就是来做这些事儿的。
总结来说就是: 运行过程中解析JS源代码并将其转换成可执行的机器码并执行。
解释型语言 && 编译型语言
解释型: 代码运行之前,不需要编译,而是在执行过程中现编译,边编译边执行
编译型: 代码在运行之前,需要先用编译器将其转换成机器语言或者中间字节码,然后再执行
通常情况下,说解释型语言慢,就是因为编译过程发生在执行过程中
2.常见的Javascript引擎
常见的Javascript引擎如下:
- Chrome V8引擎 (chrome、Node、Opera)
- SpiderMonkey (Firefox)
- Nitro (Safari)
- Chakra (Edge)
BUT, 仅仅依靠Javascript引擎是不能胜任浏览器的JS处理工作的,事实上Javascript引擎只是浏览器处理JS相关的模块中的一个小积木.
运行时Runtime
在Web开发中,我们通常不会直接用到Javascript引擎。 事实上,Javascript引擎是工作在一个环境(容器)内的, 这个环境提供了一些额外的功能(API),我们的代码在执行的时候可以使用这些特性。
Stack overflow 上有一个高赞的回答,关于Javascript引擎和Javascript Runtime。
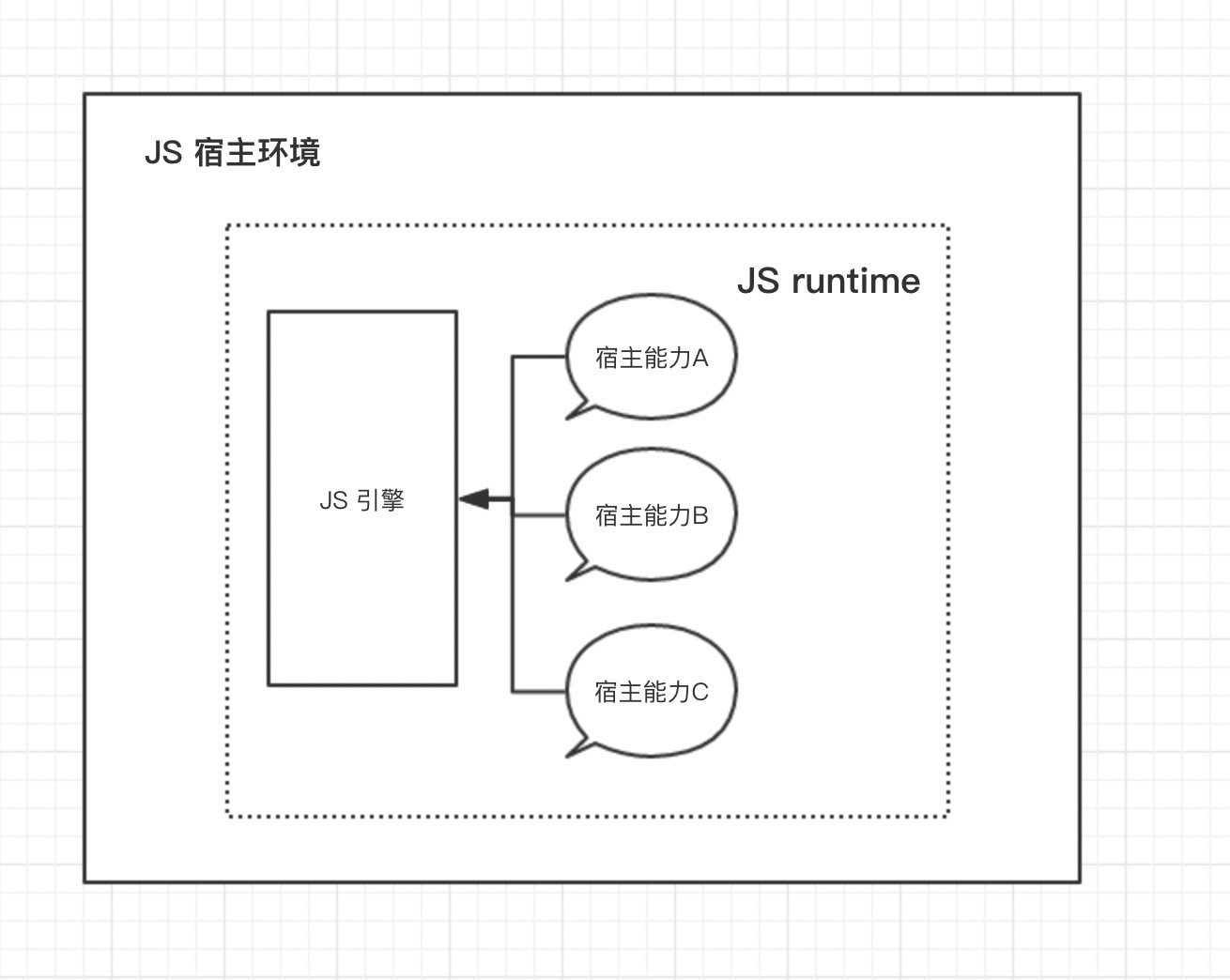
在这个观点中,不像其他编译型语言,编译之后成为机器码可以直接在主机上运行。 JS是运行在一个宿主环境中的(一个可以识别并且执行JS代码的程序),这个容器一般必须要做2件事情:
- 解析JS代码,转换成可执行的机器语言
- 暴露一些额外的对象(API),可以与JS代码做交互
做第一部分工作的就是Javascript引擎
做第二部分功能的实际上就是我们本节所说的 Javascript Runtime, 因此我们可以粗略地理解为, Javascript Runtime 就是JS宿主环境创建的一个scope, 在这个scope内JS可以访问宿主环境提供的一系列特性
常见的JS宿主环境有什么?
- web 浏览器
- node.js
那么在这两个环境中,对应的引擎和runtime分别如下:
| 宿主环境 | JS引擎 | 运行时特性 |
|---|---|---|
| 浏览器 | chrome V8引擎 | DOM、 window对象、用户事件、Timers等 |
| node.js | chrome V8引擎 | require对象、 Buffer、Processes、fs 等 |
相同的JS引擎,只是在不同的环境下,提供了不同的能力。
总之, 最初的js被设计出来,只是为了做网页校验的,但是通过不同环境下的Javascript RuntimeJS可以做更多的工作。
至此,关于JS运行时,我们有一个简单的了解。
接下来,我们再以浏览器环境中代码执行的逻辑为思路,看一看JS的运行机制。
JS引擎
根据上文的描述,JS源代码是需要经过JS引擎解析、转化之后才执行的。
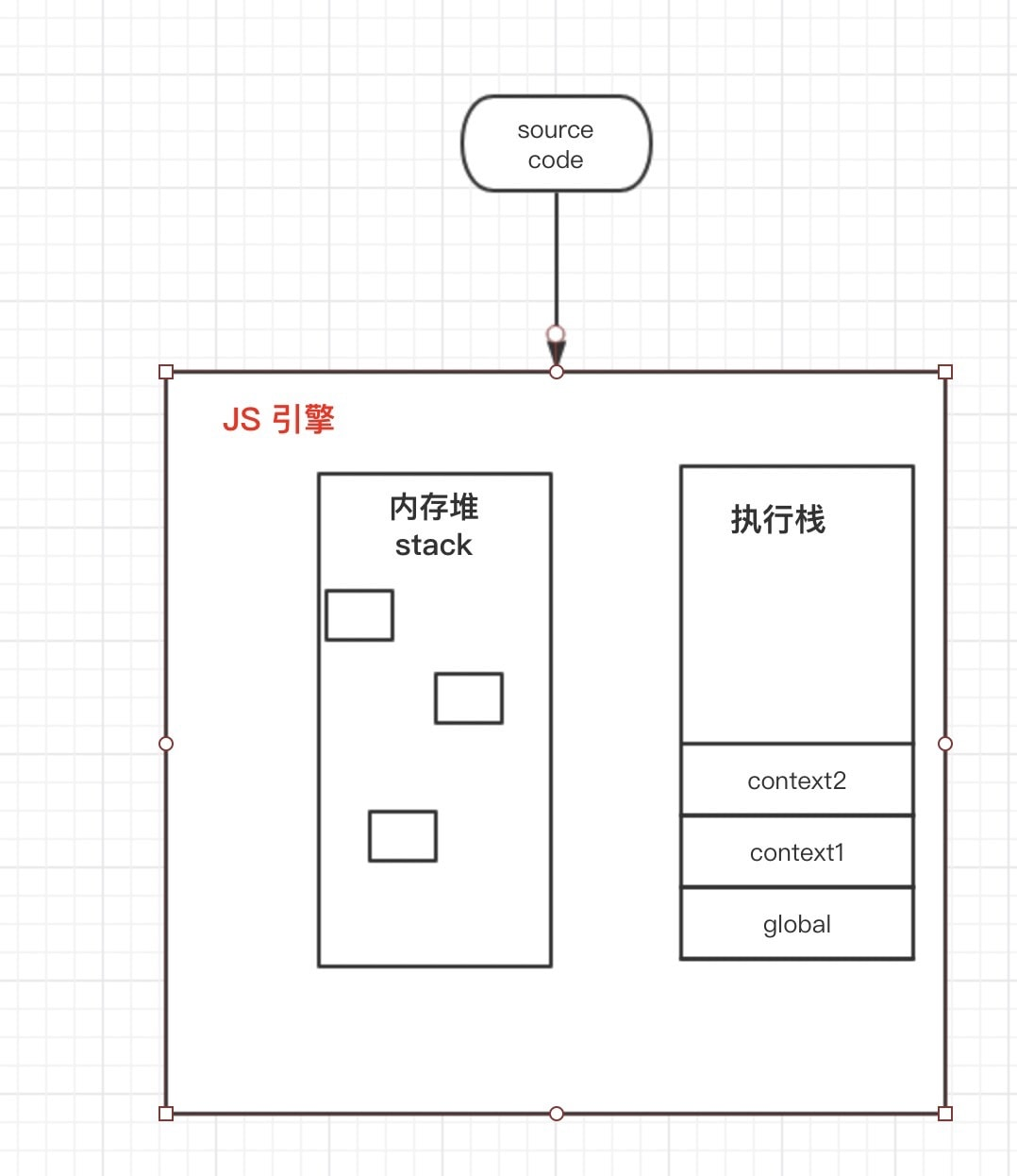
通常认为,JS引擎主要有两部分组成:
- 内存堆 引用类型实际值、内存分配的地方
- 调用栈 基本类型存储、引用类型地址名存储、代码逻辑执行的地方
源代码进入JS引擎之后,顺序读取代码,按照变量声明、函数执行等不同规则,分配到堆、或者栈内。
内存堆
存储项目引用类型数据的地方, 系统分配的内存,
JS中的引用类型数据,实际值是零散地存在这里面的
事实上,引用类型的存储是分为2部分存储的:
- 真实值存储在内存中, 是系统根据自身情况,内存区哪里有合适的位置,就分配在哪里,没有严格的顺序的,因此说是零散的
- 真实值所在的物理内存地址,这个值是以基本值的形式存储在栈内的
平时代码中的引用类型赋值,就是仅仅把栈内存储的内存地址赋给新变量,就相当于是告诉新变量该值在内存中的位置,需要的时候去取就行,并不是把真正的值传递过去,内存中该值是只有一份的。这也是引起引用问题的原因
执行栈
执行栈,是代码中实际逻辑语句执行的地方,同时项目运行过程中产生的基本类型的值也是存在此处。
引擎会把代码分成一个个可执行单元,然后依次进入执行栈,被执行
那么可执行单元是什么?
可执行单元,标准的说法是执行上下文
JS中,执行上下文可以是以下几种:
- Global code -----> 全局执行上下文
- Function code -----> 函数执行上下文
- Eval code -----> eval函数执行上下文
这些东西有什么共同点?
全局代码可以看作是一个IIFE(立即执行函数),
函数就是通俗意义上的函数
eval 是可以把传入字符串执行的函数
函数啊, 全部都是函数啊
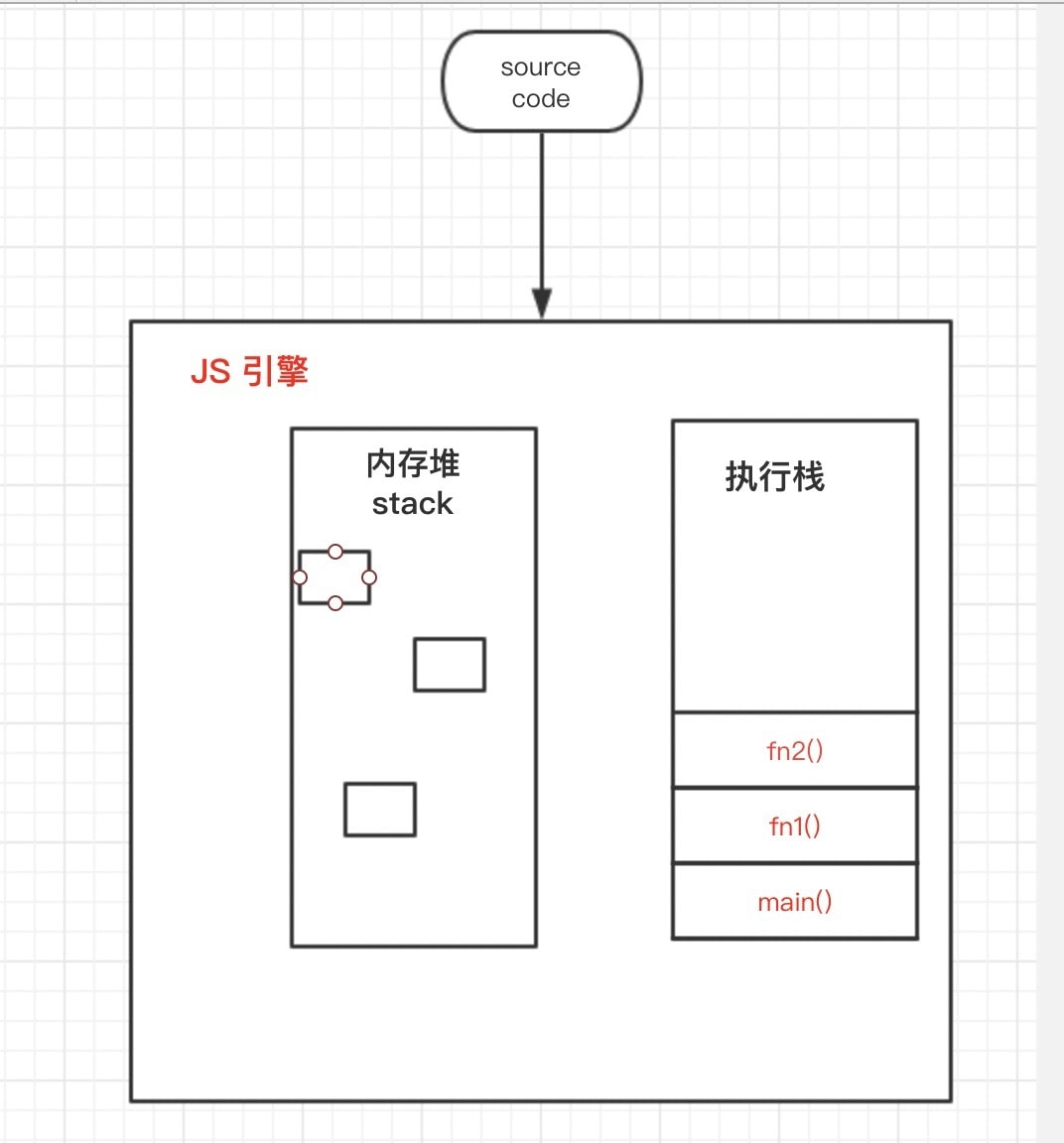
因此我们可以粗略的理解为: 执行栈里面的东西,都是一个个函数调用。
- 首先是入口文件的全部JS代码作为一个IIFE,最先入栈被调用
- 然后在实际执行过程中,调用了其他函数,就会顺次被压入栈内执行
因此, JS引擎的示意图可以更新为如下:
单线程
JS是单线程的。 地球人都知道。
什么意思?
JS引擎中,代码执行是在调用栈的里发生的。
栈是一种LIFO(last in first out 后进先出)的数据结构。
只有栈顶的函数会被处理, 处理完成之后弹出栈, 后面的进入栈顶,再被执行...
举个🌰:
如下的JS文件
function first() {
second();
}
function second() {
console.log('log fn');
}
first();
... // 后续操作
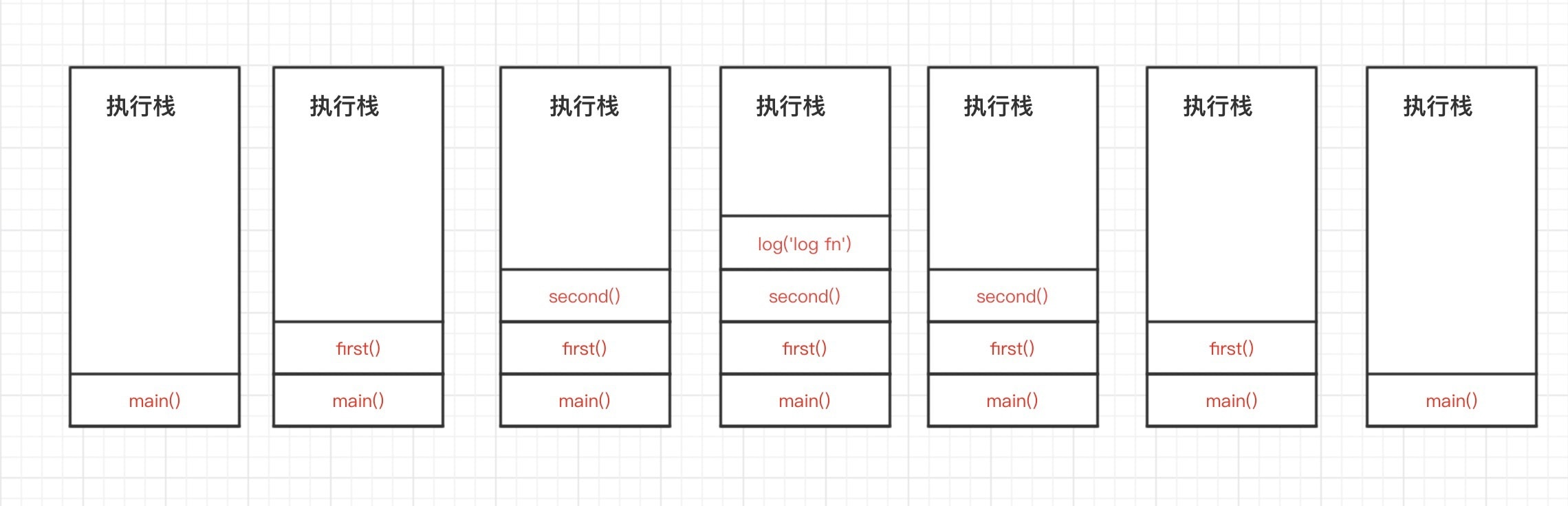
JS引擎处理这段代码的步骤如下 (只关注函数调用)
- 整段代码作为一个IIFE,入栈, main()函数调用进入栈顶,开始执行
- 遇到first函数调用, first函数进入栈顶,开始进入first函数体执行 (此时main函数还未执行完毕)
- 进入first函数体之后,遇到调用second函数, 把second函数压入栈顶,进入second函数体执行
- 进入second函数体之后,遇到console.log函数调用, 把console.log压入栈顶执行
- console.log函数打印完毕之后,执行结束, 弹出栈顶
- 此时栈顶是second函数,继续执行second函数体中,console.log之后的代码,发现没有可执行代码了,OK,那就宣告second执行完毕,弹出
- 此时first函数进入栈顶,那就执行first函数体中,second函数调用之后的代码,发现空空如也,那么first函数执行完毕,弹出
- 栈顶main函数执行后续代码
因此JS单线程,指的是在JS引擎中,解析执行JS代码的调用栈是唯一的,所有的JS代码都在这一个调用栈里按照调用顺序执行,不能同时执行多个函数。
单线程意味着什么?
意味着,正常情况下,JS引擎会按照代码书写的逻辑,依次调用函数,在任意时间点,有且只能有一个函数被执行。外层函数必须等到内层函数处理完毕有返回值之后才能继续执行。
为什么要单线程?
JS最初被设计使用在浏览器上,作为浏览器上的脚本语言,需要与用户的操作互动以及操作DOM, 如果时多线程的话,需要关注各个线程之间状态的同步问题。
想象一下,js引擎中可以同时执行2个函数,如果两个函数操作同一个对象,那么到底以哪个为准?
然后,操作DOM结构,在线程A上已经删了某节点,线程B同时还在对该节点一顿操作,这就尴尬了。
而做多线程的状态同步又是得不偿失的,因此就直接用单线程了。
有什么问题?
假如,某个函数耗时比较久,那么调用它的外层函数必须安安静静的等待这个函数执行完成才能继续执行, 如果,这个函数出错了,那么外层的函数也没办法继续执行了。
function foo(){
bar()
console.log('after bar')
}
function bar(){
while(true) {}
}
foo()
比如这个栗子,foo函数中调用了bar函数,那么foo函数必须等待bar函数执行完毕才能继续执行后续代码,然而bar函数是个无限执行的函数哟,回不来的,那么foo函数等到花儿都谢了也没办法执行后面的代码的。
当然这是比较极端的情况,但是在前端的业务场景中有几类常见的case,在此是有问题的:
- 定时器延迟操作
- 网络请求
- 网页事件等
这些就是我们常见的异步操作, 事件触发之后并不能立即得到结果,按照之前的运行模式,浏览器就会阻塞其他操作,等待相应结果,表现在页面中就是页面卡死,这是一个优秀的应用所不能允许发生的。
同步&异步
关于同步和异步操作,借用朴灵大神的说法:
一般操作可以分为两个步骤,
- 发起调用
- 得到结果
发起调用,立马可以得到结果的是为
同步
发起调用,无法立即得到结果,需要额外操作才能得到结果的是为异步
因此当前的模型在异步操作中是有问题的
解决方案?
问题的本质是js引擎的单线程工作模式,只专注于一件事情, 必须【执行至完成】
而产生问题的那些操作往往不能直接得到 结果,必须经过额外操作才能得到结果 【异步问题】
思路:可以把这些异步操作分发给其他模块,得到处理结果之后再把回调函数一块放入主线程执行。
这就是 事件循环(Event Loop)的主体思路。
event loop 只是解决异步问题的一种思路 其他的思路还有:
- 轮询
- 事件
Web API's
上一章节提到,异步操作可以交给JS引擎之外的其他模块处理, 在浏览器中其他模块就是Web API模块
Web API 其实就是上述的 JS runtime 提供的一系列宿主环境的特性集合。
在浏览器中,主要包括以下能力:
- Event Listeners
- HTTP request
- Timing functions
完美的cover了上述产生异步问题的几类case
因此至此,我们可以得出以下的视图:
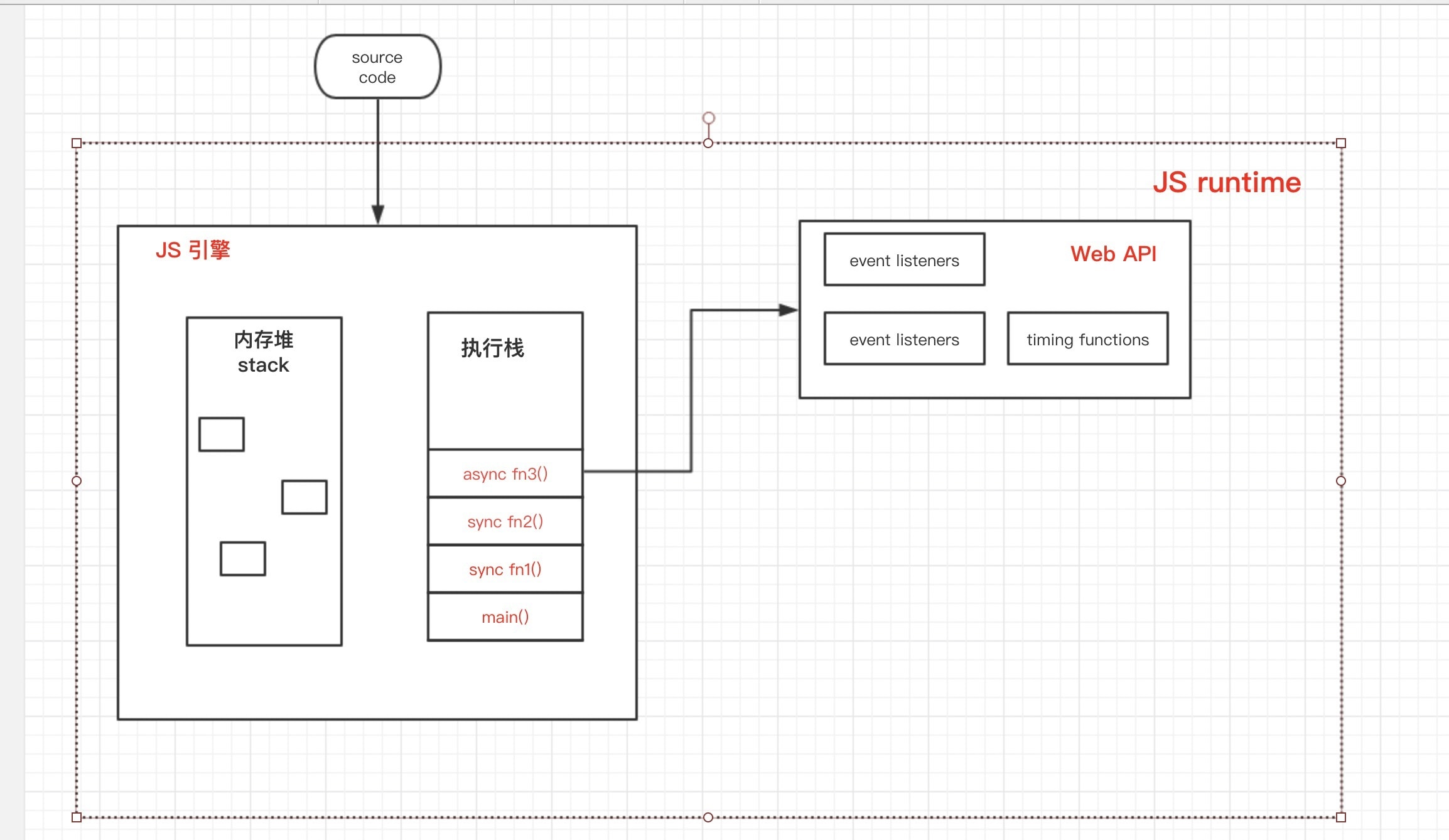
JS引擎中,执行栈遇到同步函数调用,直接执行得到结果后,弹出栈,继续下一个函数调用
遇到异步函数调用,将函数分发给Web API模块,然后该异步函数弹出栈,继续下一个函数调用,不会产生阻塞问题。
问题来了?
这些异步操作分发给Web API模块处理之后,不能说不管了,主线程还是需要知道结果做后续操作的,Web API得到结果之后怎么通知主线程呢?
这就需要其他的模块帮忙了。
这个地方提到了
主线程,就意味着还有其他的辅助线程。
是的,JS是单线程执行的,但是并不意味着浏览器内核是单线程的。
事实上,web api模块内就有多个线程,每个异步操作处理模块都对应一个线程
http请求线程、事件处理线程、定时器处理线程等
回调队列 (callback queue)
回调队列, 也叫事件队列、消息队列。
这个模块就是用来帮助Web API模块处理异步操作的。
在Web API模块中,异步操作在相应的线程中处理完成得到结果之后,会把结果注入异步回调函数的参数中,并且把回调函数推入回调队列中。
但是,只推到回调队列里也不是个事儿,因为前面说到了,所有的JS执行都发生在主线程调用栈里面。这些异步操作拿到结果之后,带着回调函数推入了回调队列,需要在适当的时机进入主线程调用栈执行。
那么,谁知道什么时候是合适的时机呢?
Event Loop 知道。
回调队列
队列是一个FIFO,先进先出的存储结构,
这样意味着异步操作的回调函数会按照进入队列的顺序被执行,而不是调用的顺序被执行
Event Loop
Event Loop 不停地检查主线程调用栈和回调队列,当发现主线程空闲的时候,就把回调队列里第一个任务推入主线程执行。 以此不停地循环。
至此,一个异步操作,兜兜转转最终拿到了结果,成功执行并且没有阻塞其他的操作。
overview
一个完整的图示如下:
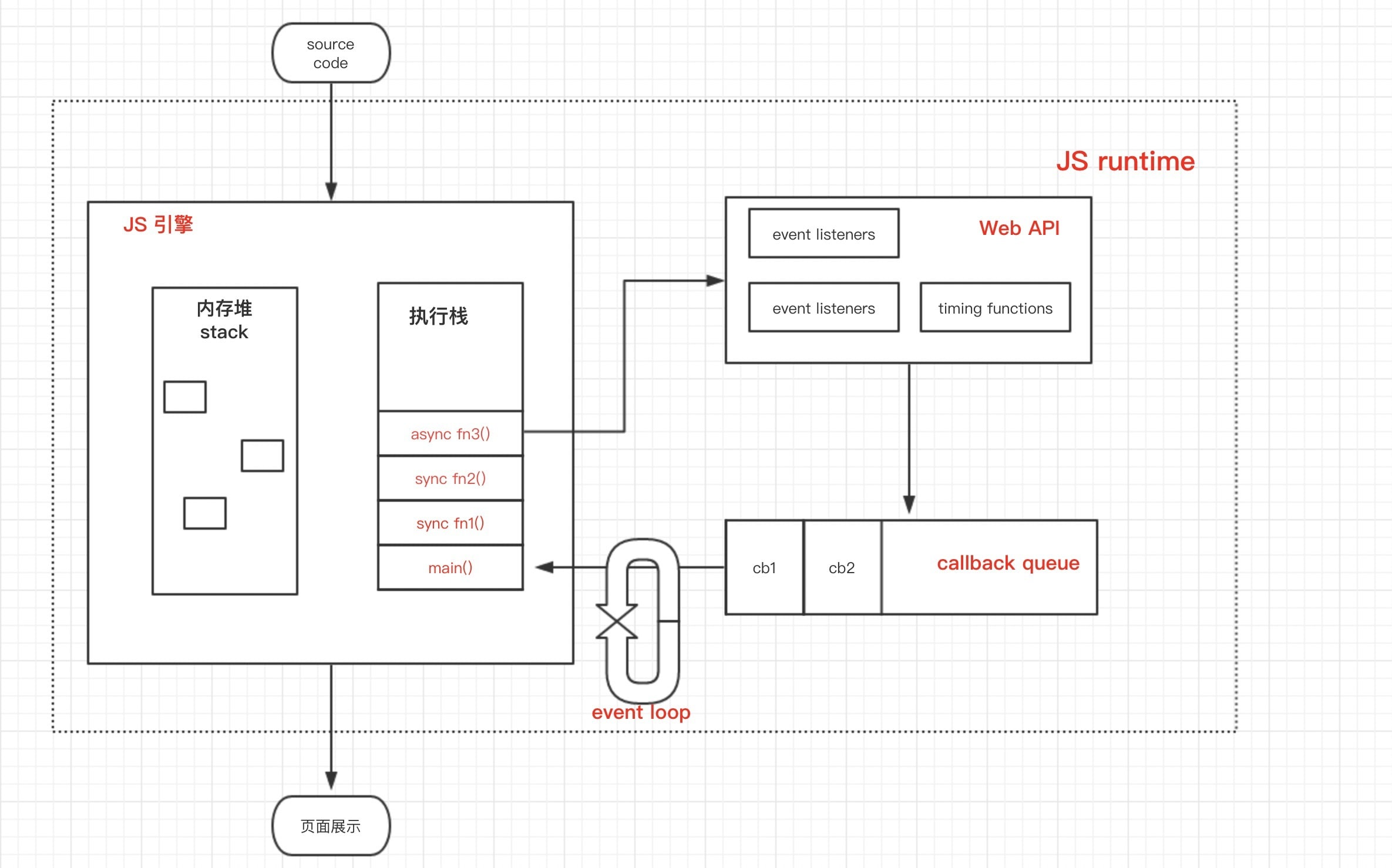
至此,本文在宏观结构上按照浏览器执行js文件的步骤,分析了浏览器环境的一些简单机制。 更多的执行细节,比如词法分析、作用域构建等在后续文章中会继续深入。
关于我们
快狗打车前端团队专注前端技术分享,定期推送高质量文章,欢迎关注点赞。
文章同步发布在公众号哟,想要第一时间得到最新的资讯,just scan it !

