

过拟合专题
过拟合的原因:
- 训练集的数量级要小于模型的复杂度;
- 训练集和测试集特征分布不一致;
- 样本里的噪音数据干扰过大;
- 权值学习迭代次数足够多(Overtraining)。
过拟合的解决方案:
- 数据层面:增加数据,数据增强
- 模型层面:合适的模型(参数量较小),权重衰减(正则化),噪声(包括权重噪声和输入噪声),训练早停,模型剪枝, 激活函数选择Relu
- 集成学习:bagging,boosting,dropout
大数据专题
大数据排序
方法一: bitmap排序(要求无重复数据)
bitmap就是每一位存一个数字,一个byte有8个bit,可以存8个数据。1M内存可以存:8x1024X1024 = 8,388,608的数据。
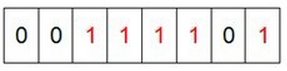
#Bitmap
class Bitmap():
def __init__(self,max):
'确定所需数组个数'
self.size = int ((max + 31 - 1) / 31)
self.array = [0 for i in range(self.size)]
def bitindex(self,num):
'确定数组中元素的位索引'
return num % 31
def set(self,num):
'将元素所在的位置1'
elemindex = num // 31
byteindex = self.bitindex(num)
ele = self.array[elemindex]
self.array[elemindex] = ele | (1 << byteindex)
def test(self,i):
'检测元素存在的位置'
elemindex = i // 31
byteindex = self.bitindex(i)
if self.array[elemindex] & (1 << byteindex):
return True
return False
if __name__ == '__main__':
Max = 110
suffle_array = [51, 100 ,2, 4, 34]
result = []
bitmap = Bitmap(Max)
for c in suffle_array:
bitmap.set(c)
for i in range(Max+1):
if bitmap.test(i):
result.append(i)
print('原始数组为: %s' % suffle_array)
print('排序后的数组为: %s' % result)
大数据TopK
题目:从1亿个整数里找出100个最大的数 方法一:堆排序
- 1.读取前100个数字,建立最大值堆。
- 2.依次读取余下的数,与最大值堆作比较,维持最大值堆。
- 3.将堆进行排序,即可得到100个有序最大值。
方法二:多路归并
- 1.从大数据中抽取样本,将需要排序的数据切分为多个样本数大致相等的区间,例如:1-100,101-300…
- 2.将大数据文件切分为多个小数据文件,这里要考虑IO次数和硬件资源问题,例如可将小数据文件数设定为1G(要预留内存给执行时的程序使用)
- 3.使用最优的算法对小数据文件的数据进行排序,将排序结果按照步骤1划分的区间进行存储
- 4.对各个数据区间内的排序结果文件进行处理,最终每个区间得到一个排序结果的文件
- 5.将各个区间的排序结果合并
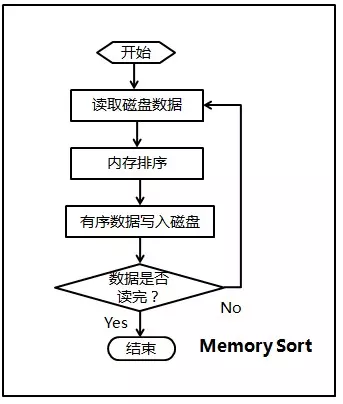
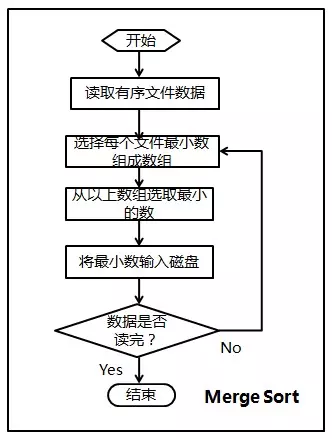
注意以上merge时候的方法是循环比较的,假设有n个元素,每个需要比较k次,复杂度为O(nk)。更好的办法使用最小堆实现,具体的方法和下面算法题中合并K个列表一样。
算法题目
合并两个有序数组
思路:开一个数组存放结果,依次比较两个list元素的大小,直到一个list为空,剩下的加入res即可
def merge(nums1, nums2):
res = []
while nums1 and nums2:
if nums1[0]<nums2[0]:
res.append(nums1.pop(0))
else:
res.append(nums2.pop(0))
res = res+nums1+nums2
return res
print(merge([1,2,3,4],[3,4,5,6,7]))
合并K个有序数组
注意这种思路很重要
可以利用最小堆完成,时间复杂度是O(nklogk),具体过程如下:
- 创建一个大小为n*k的数组保存最后的结果
- 创建一个大小为k的最小堆,堆中元素为k个数组中的每个数组的第一个元素
重复下列步骤n*k次:
- 每次从堆中取出最小元素(堆顶元素),并将其存入输出数组中
- 用堆顶元素所在数组的下一元素将堆顶元素替换掉,
- 如果数组中元素被取光了,将堆顶元素替换为无穷大。每次替换堆顶元素后,重新调整堆
初始化最小堆的时间复杂度O(k),总共有kn次循环,每次循环调整最小堆的时间复杂度是O(logk),所以总的时间复杂度是O(knlogk)
合并两个有序链表
思路和合并list一样
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
res = ListNode(None)
node = res
while l1 and l2:
if l1.val<l2.val:
node.next,l1 = l1,l1.next
else:
node.next,l2 = l2,l2.next
node = node.next
if l1:
node.next = l1
else:
node.next = l2
return res.next
合并K个有序链表
思路和合并list一样
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
heap = []
for ln in lists:
if ln:
heap.append((ln.val, ln))
dummy = ListNode(0)
cur = dummy
heapq.heapify(heap)
while heap:
valu, ln_index = heapq.heappop(heap)
cur.next = ln_index
cur = cur.next
if ln_index.next:
heapq.heappush(heap, (ln_index.next.val, ln_index.next))
return dummy.next
二叉树的各种遍历
class Tree:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def inorder(root):
stack = []
result = []
cur = root
while stack or cur:
if cur:
stack.append(cur)
cur = cur.left
else:
cur = stack.pop()
result.append(cur.val)
cur = cur.right
return result
def preorder(root): ## 前序遍历
stack = []
result = []
cur = root
while stack or cur:
if cur:
result.append(cur.val)
stack.append(cur.right)
cur = cur.left
else:
cur = stack.pop()
return result
def postorder(root): ## 后序遍历
stack = []
result = []
cur = root
while stack or cur:
if cur:
result.append(cur.val)
stack.append(cur.left)
cur = cur.right
else:
cur = stack.pop()
return result[::-1]
def levelOrder(root): #层次遍历
if not root:
return []
result = []
cur = root
queue = [cur]
while queue:
cur = queue.pop(0)
result.append(cur.val)
if cur.left:
queue.append(cur.left)
if cur.right:
queue.append(cur.right)
return result
tree = Tree(1)
tree.left = Tree(2)
tree.left.left = Tree(4)
tree.left.right = Tree(5)
tree.right = Tree(3)
tree.right.left = Tree(6)
tree.right.right = Tree(7)
print(preorder(tree))
print(inorder(tree))
print(postorder(tree))
print(levelOrder(tree))
常用算法模板
适用于笔试的时候
二分查找
利用python的库进行二分查找:bisect_left:数据的左插入区间,bisect_right:数据的右插入区间
from bisect import bisect_left, bisect_right
def find(A, data):
index = bisect_left(A, data)
if index != len(A) and A[index] == data :
return index
return None
A = [1,2,2,2,2,3,3,3,3]
index = find(A, 2)
print(index)
有序数组查找某个值的个数
from bisect import bisect_left, bisect_right
def find(A,data):
return bisect_right(A,data) - bisect_left(A, data)
A = [1,2,2,2,2,3,3,3,3]
res = find(A, data = 2)
print(res)
有序数组区间中元素个数
from bisect import bisect_left, bisect_right
def find(A, min, max):
return bisect_left(A, min), bisect_right(A, max)
A = [1,2,2,2,2,3,3,3,3]
l, r = find(A, min = 0.1, max = 2.5)
print(r-l)
迷宫题目的DFS搜索
dirs =[(0 ,1) ,(1 ,0) ,(0 ,-1) ,(-1 ,0)] # 当前位置四个方向的偏移量
path =[] # 存找到的路径
def mark(maze ,pos): # 给迷宫maze的位置pos标"2"表示“访问过了”
maze[pos[0]][pos[1]] =2
def passable(maze ,pos): # 检查迷宫maze的位置pos是否可通行
if pos[0] >=len(maze) or pos[1]>=len(maze[0]) or pos[0] <0 or pos[1] <0 or maze[pos[0]][pos[1]]==1 or maze[pos[0]][pos[1]]==2:
return False
return True
def maze_dfs(maze ,start ,end):
if start==end:
print(start)
return
st= []
mark(maze ,start)
st.append(start) # 入口和方向0的序对入栈
while st!= [] : # 走不通时回退
pos =st.pop() # 取栈顶及其检查方向
for i in range(4): # 依次检查未检查方向,算出下一位置
nextp = pos[0] + dirs[i][0], pos[1] + dirs[i][1]
if nextp==end:
st.append(pos)
st.append(end)
print(st) # 到达出口,打印位置
return
if passable(maze , nextp): # 遇到未探索的新位置
st.append(pos) # 原位置和下一方向入栈
mark(maze ,nextp)
st.append(nextp) # 新位置入栈
break # 退出内层循环,下次迭代将以新栈顶作为当前位置继续
print("找不到路径")
if __name__ == '__main__':
#0表示可以走通,1表示不可以走通,2表示走过的位置
maze = [[0, 1, 0, 0, 1],
[0, 1, 0, 1, 0],
[0, 0, 0, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 0, 1, 0]]
start = (0 ,0)
end = (4 ,4)
maze_dfs(maze ,start,end)
