

前言
最近有个段子,程序员不要拷贝代码,而是要一行一行的重新抄过去。好嘛,段子归段子,笔主始终觉得
think more, code less,多思考,能少写的代码尽量少写,从而也与标题呼应上,懒才制造生产力。继上次写的 excel 工具类之后,这次又来给大家 show 一下笔主是如何释放生产力的。
需求背景
项目中经常会有触达需求,简单来说就是群发微信公众号消息。这里有个刚需就是去重,已经下发过的用户不再下发,多个标签用户之间也可能会存在重复的用户 ,这些都需要去重。
解决方案
两层循环遍历:最 low 的办法不就是套两层循环遍历,时间复杂度 n 方。HashSet:稍微有点追求的小伙伴可能会想到使用 HashSet 去重,没错,HashSet 确实是个不错的选择,时间复杂度很低。但是面对海量数据,HashSet 似乎就不太适合了,HashSet 有个弱点就是,空间利用率低,而且元素占用的空间也相对较大。布隆过滤器:针对海量数据去重场景,布隆过滤器应运而生,关于布隆过滤器网上很多博客都说的很详细。
作者下面就简单说一下布隆过滤器的关键点,把主要精力放在如何应用到实际项目中。
布隆过滤器
使用场景:判断某个元素是否在海量数据之中。存储结构:使用比特数组存储。添加元素:- 每添加一个元素,分别对该元素进行 k 次不同的哈希。
- 将上面 k 个哈希的结果对应于数组的位置设为1。
检查元素:- 求出要查询的元素的 k 个哈希值。
- 如果k个位置有一个为0,则肯定不在集合中。
- 如果k个位置全部为1,则可能在集合中。
为什么需要进行 k 次哈希?
主要是为了降低哈希冲突引发的误差,对于 HashMap 来说,哈希冲突的时候,会用链表或者是红黑树将所有冲突的元素都保存起来。但是对于布隆过滤器不能也不需要把冲突的 key 用链表连接起来,因为他只需要判断 key 是否存在。
如何计算布隆过滤器占用的空间大小?
可以使用这个在线计算工具:Bloom Filter Calculator
去重工具使用姿势
在介绍具体的实现过程之前,先看看作者手撸的去重工具的正确使用姿势。
1. 配置布隆过滤器信息
根据约定将去重器的配置文件放在 deduplication.properties 下。
bloomList=goods,wechat
tableInfo=goods:goods_deduplication,wechat:wechat_deduplication
expectedInsertions=goods:200000
bloomList:布隆过滤器 bean 的名称,一个去重业务对应一个值,多个值之间使用逗号分割。tableInfo:布隆过滤器对应的数据表名,不配置会使用默认值。expectedInsertions:布隆过滤器的预计数据量,这个对数据的准确性有较大的影响,需要根据实际业务进行评估,默认值为 10000000。
2. 去重器使用
配置完上面的信息之后,就可以使用去重器了,使用姿势如下图所示,核心代码就一行。传入待比较的 List 和业务对应的布隆过滤器 bean 名称,返回目前还不存在的记录,且会将该记录入库,下次再进行去重,该记录就不会再出现了。
测试程序:
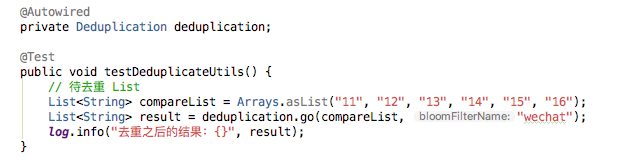
运行程序之前,已存在的数据如下,identifier 为 12、16、13 的记录已经存在了。
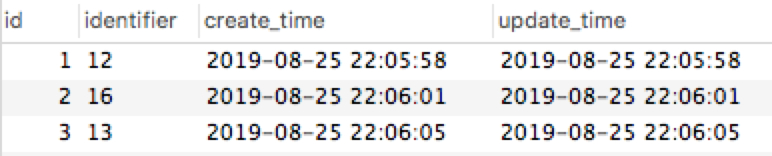
程序运行结果:

数据库状态:
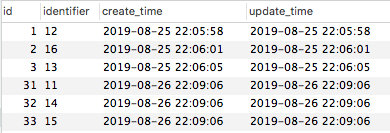
可以看到成功将 11、14、15 的记录返回且成功入库。
去重器源码分析
下面主要讲的是去重器实现的核心步骤,在分析代码之前,先把 ✨去重器源码地址✨ 贴出来,嘻嘻嘻,欢迎大家来 star。该工具的核心代码都在 deduplication 这个包下面。
设计目标
传入任意的唯一标识 List,或者是指定唯一标识的 CSV 文件进行去重,对任意的业务均适用。
实现思路
创建布隆过滤:针对某个去重业务需要一个布隆过滤器与之对应。初始化布隆过滤器:每个布隆过滤器的初始化数据从对应的数据库表中取。使用布隆过滤器:使用初始化过后的布隆过滤器判断元素是否存在,存在入库。
步骤很简单,但是想要实现的优雅点,使用起来方便一点,还是需要 think 一下。
创建布隆过滤
这里作者使用的布隆过滤器是 guava 提供的实现,并没有重复造轮子,毕竟 Google 出品。
这里主要解决的问题点有两个:
- 这个布隆过滤需要是创建一次,全局有效,且是单例,这个问题很好解决,把该布隆过滤器交给 Spring 容器管理即可,拍拍手,干净得很。
- 传统创建 guava 布隆过滤器是使用
BloomFilter#create()方法,但是我们的目标是懒!一懒到底!没理由新增一个去重业务,我们就去翻代码,new 一个布隆过滤器出来吧。所以这里我们需要向Spring 容器动态注册 bean的能力,可以使用 Spring 提供的BeanDefinitionRegistryPostProcessor接口 来实现这个功能。
创建布隆过滤核心代码:
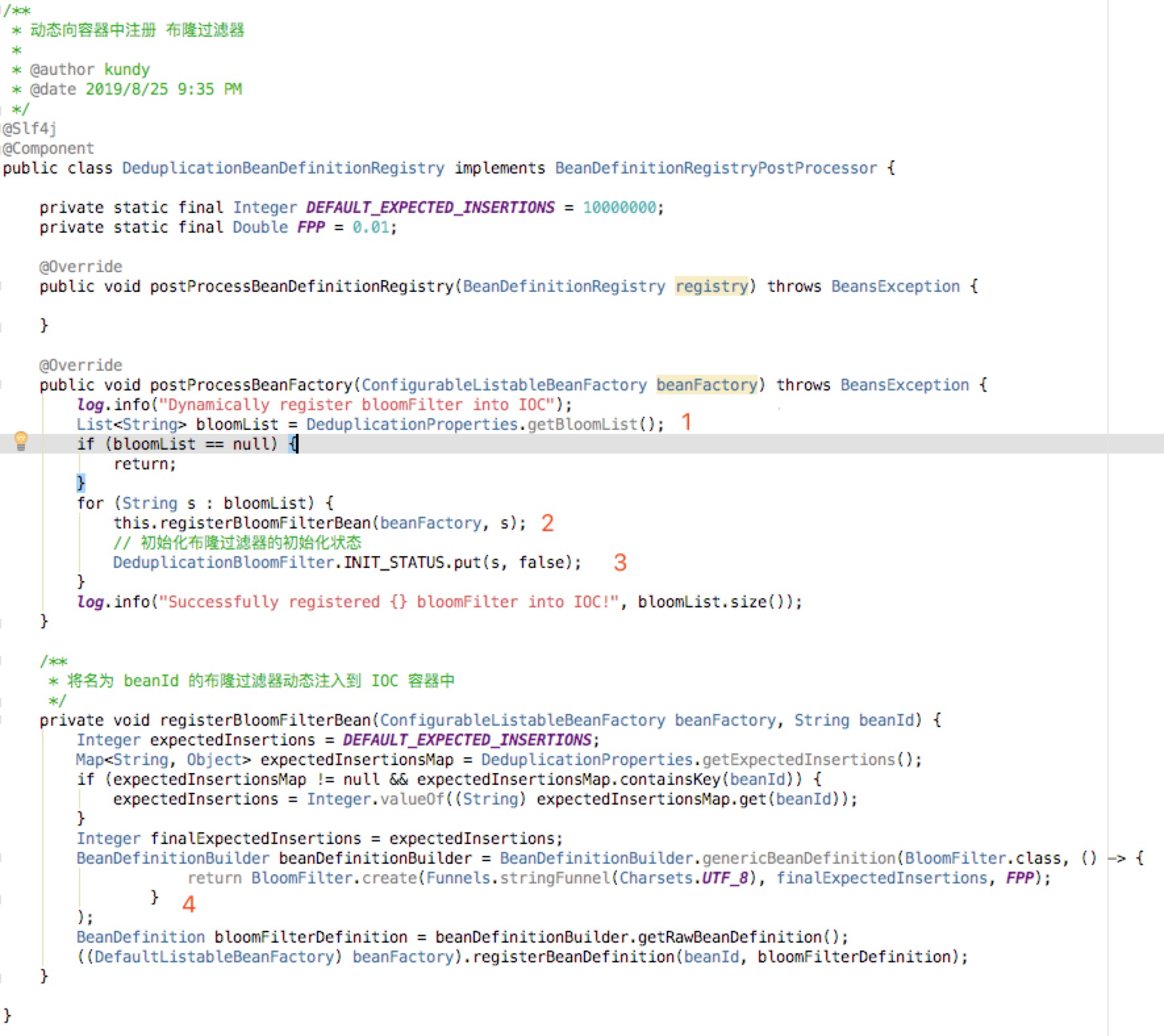
上面标出了四个关键点:
- 【1】 从配置文件中取出所有的 bean 名称。
- 【2】 循环 bean 列表,动态注册 bean。
- 【3】初始化布隆过滤器初始化状态的标识为 false,标识该布隆过滤还处于
not ready状态,不能开放使用。 - 【4】往 Spring 容器中注册了一个名为 beanId 的 BloomFilter 。
经过上面的步骤,我们已经创建好了所有的布隆过滤器。
初始化布隆过滤器
这一步主要是从数据库中查询数据,然后塞到布隆过滤器中。可能有朋友会问,为什么还要把初始化这一步单独拎出来?直接在创建bean的时候初始化不就行了。主要是因为在动态注册 bean 的时候,容器的上下文环境还没有准备好阶段。在容器中还无法获取到其他的 bean 。所以我们只能把初始化放在这一阶段来做。
在这里作者使用了 ApplicationListener 监听,他可以监听 SpringBoot 应用的生命周期,作者在这里监听了 SpringBoot 启动完成之后的事件,把对布隆过滤器的初始化工作放到这里面来进行。
DeduplicationApplicationListener 监听器核心代码:
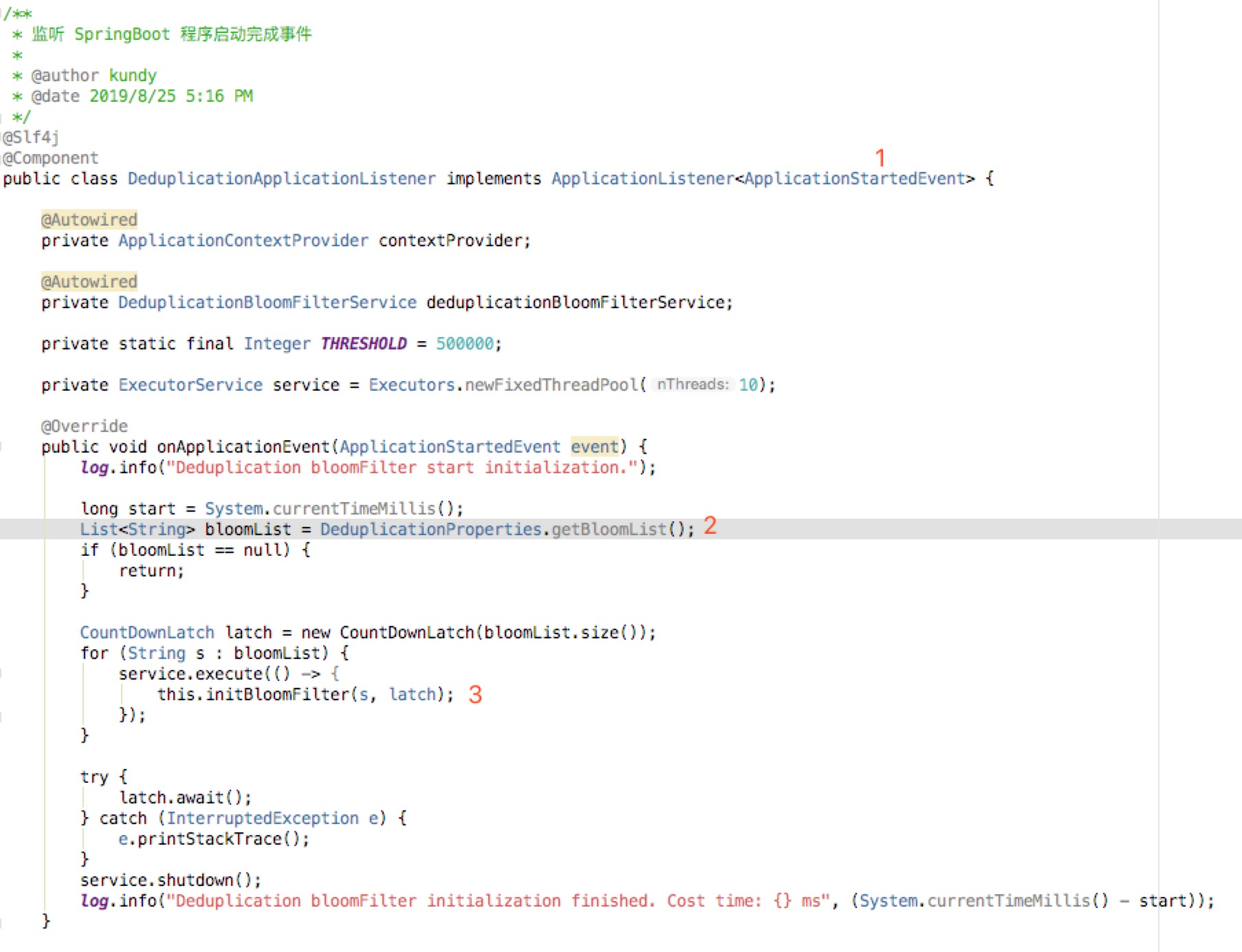
- 【1】选择监听应用启动完成之后的事件。
- 【2】取出所有的布隆过滤器名称。
- 【3】启动线程调用
initBloomFilter()初始化每个布隆过滤器。
initBloomFilter 方法:

- 【1】根据传入的布隆过滤器名称获取 bean 实例,这里主要是通过
ApplicationContextAware动态获取 bean 实例。 - 【2】根据传入的布隆过滤器名称获取对应的数据库表名。
- 【3】如果当前数据库表还不存在,建表后立即返回。
- 【4】否则调用
fillBloomFilter方法。
fillBloomFilter 方法:
这里面主要的工作就是将数据库中的数据塞到布隆过滤器中,通常这一步查询出来的数据会非常的多,这里选择了将查询任务切分,多线程查询,然后再合并子任务,没错!就是借鉴 MapReduce 的思想。
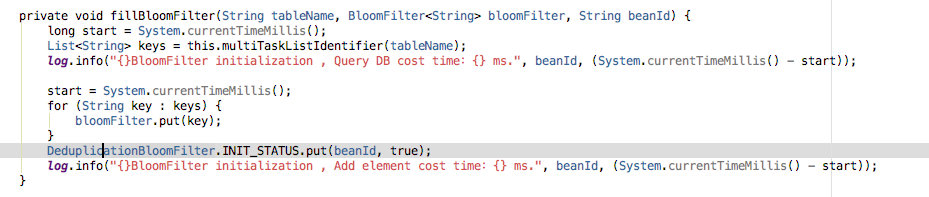
数据塞完之后,该布隆过滤器就可以对外开放使用了,所以会将该布隆过滤器对应的初始化状态置为 true。
经过上面的步骤,已经将布隆过滤器初始化完成了,下面对布隆过滤器进行一定的封装就可以使用了。
封装布隆过滤器
这一步主要是对布隆过滤器进行封装,使之用起来更加的方便,这里主要支持两种类型的数据源去重,分别是 List 和 CSV 文件。这里都是批量去重,入库也是批量入库。如果需要单条记录去重,例如过滤黑名单,就需要自己封装对应的业务了,因为毕竟不同用户的业务还是不太一样的。
对外暴露的两个方法:
go 是一个重载函数,仅对内部使用:
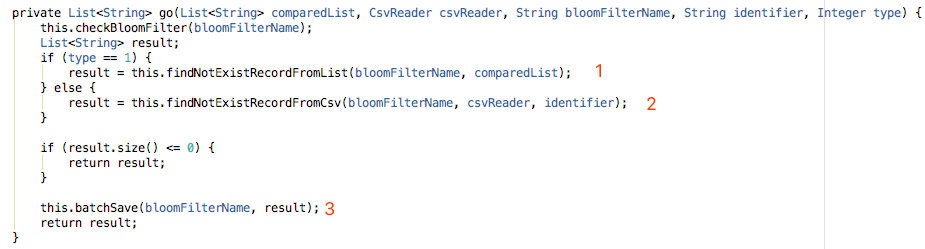
- 【1】查找 List 中不存在的元素。
- 【2】查找 CSV 文件中不存在的记录。
- 【3】批量入库。
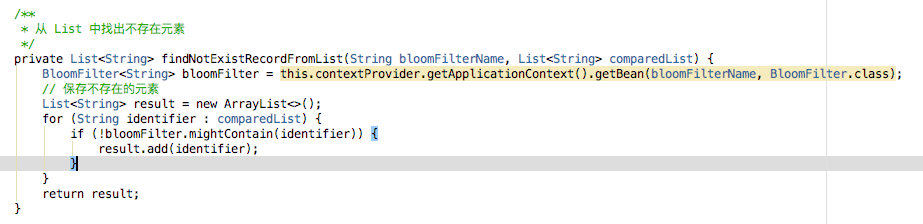
这里再来看看 findNotExistRecordFromList 方法。很简单,遍历传入的 list,如果布隆过滤器判断为还不存在,加入到结果集中返回。
写在最后
关于去重器的核心步骤就介绍到这里啦,对于实现的细节,感兴趣的朋友可以到 github 上把代码 fork 下来看一哈,有问题欢迎随时与我交流。
打波广告嘛
✨github:cranberry✨ 是作者最近在写的一个项目,主要是对 java web 开发过程中的一些常见问题的实现与分析,后续也会持续更新,希望对大家会有帮助,感觉不错也可以给做个 star 一个哦!
