


| 导语 《孙子兵法·谋攻》:「知彼知己,百战不殆。」在和产品pk的时候,产品最经常的说一句话是,你看他们(竞品)都能实现,你为啥不能?你看他们(竞品)的速度怎么这么快,你看看你,为啥这么慢?
《孙子兵法·谋攻》:「知彼知己,百战不殆。」在和产品pk的时候,产品最经常的说一句话是,你看他们(竞品)都能实现,你为啥不能?你看他们(竞品)的速度怎么这么快,你看看你,为啥这么慢?每每遇到这样的责难的时候,我往往都只能陷入到沉思,我只能告知产品,我们的页面很快,真的很快,你看,我的报表。产品总是在这个时候说,不听不听,我不听。如果你不能拿出竞品的客观数据,那么,在产品看来这样的呓语只能是开发自己的寡妇心态。在每个无人的夜晚,遇到这个问题的时候,我不得不得默默的打开了浏览器。
所以,如何把监控做到客观,独立,第三方,就变得很重要了。
如何客观的监控页面的体验
首先,第一个来自灵魂的深思就是,如何客观的对页面体验进行评价?你说你的页面体验牛逼,你的页面体验就牛逼了么?你说竞品的页面不行,竞品的页面就真的不行么?每晚思及如此,我都默默的打开了浏览器。
对于页面的客观评价体系,有很多不同的说法,基于速度,基于错误率,基于SEO…,这么多的评价标准中,要怎么样,找到最能说明用户体验的指标?或者换句话来说,怎么样的指标是最能够表现用户真实的用户体验的?
从直觉上来说,一个页面的体验可以分成以下几个部分:
渲染体验
这个体验最直白,用户打开页面的耗时如何,用户花了多长的时间来打开你的页面。在页面的打开过程中,是一种什么样的体验?是白屏,是渐进加载,是菊花图,还是骨架屏?不同的体验体验,给用户的直觉感官是不同的,这些感官应该怎么样来客观评价?
交互体验
页面的各种交互是否能够及时?页面上的各个交互针对不同的人群是否兼顾?是否照顾了视觉障碍人群,是否考虑到了键盘党?各个交互是否符合浏览器预期?页面上的脚本是否使用了有危险的API?是否加载了太多的资源?
SEO
页面是否对蜘蛛友好?页面是否对于能够被正确的收入?
当然,上面列的比较简单,只涵盖了页面的一部分,但是,如上已经覆盖了很多我们平时需要关注的页面信息了,那么我们要怎么来获取和评价这些信息呢?
最简单的方法是,我们把浏览器的devtools打开,选中到performance tab,点击record。然后,我们就可以看到所有我们想要的数据了。那么问题来了,performance tab是怎么工作的呢?它是怎么拿到我们页面的各种渲染数据的呢?
浏览器的performance tab是怎么工作的?
一切的一切,都要以这个协议开始:chrome devTools protocol。 chrome会通过这个协议,把内核和浏览器的一些状态暴露出来。我们平时使用的performance tab的本质起始就是使用这个协议的一个美化了的查看器。performance里面还是有一些内容比较没有被充分展示,如果你想了解更多,更详细的内核信息,可以进入到以下的页面查看
chrome://tracing/
点击record,你会看到如下的选择框。
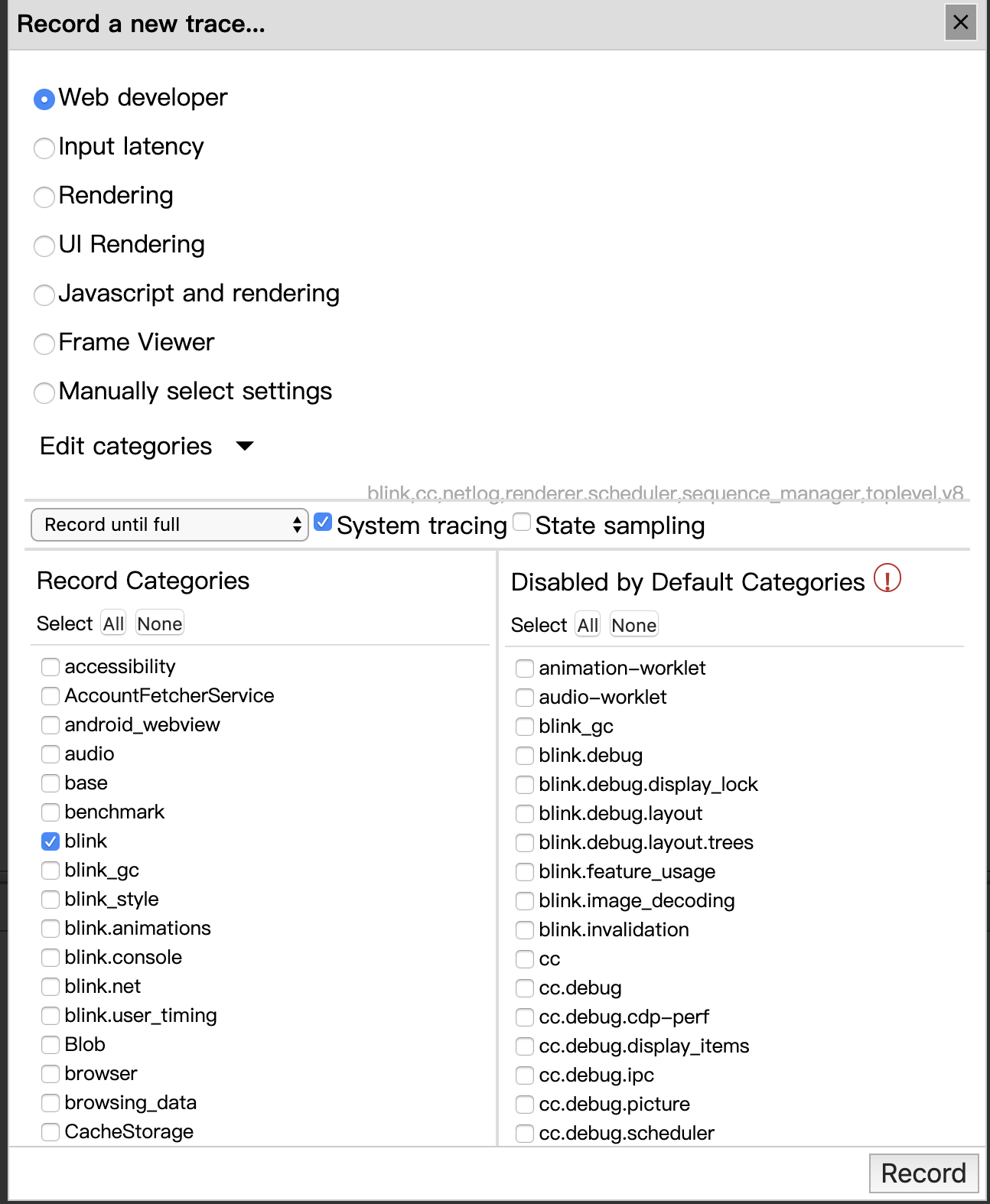
这里将会允许你,更为详细的去定义,你想要监控和了解的内核内容。
嗯,这里有一点比较好,也是比较不幸的一点,这个tracing tab将会监控当前chrome 所有tab的渲染信息。所以,使用的时候,请务必小心。还有一个需要注意的点事,这个tracing的日志量多到爆炸,尽可能的选择较少的追踪项,这样,可以让你保护好你的内存条。:)
如果有时间好好研究一下,这个tracing出来的内容,你会发现,浏览器的运行,好像并不是你想象那样的。:)
当然了,除了使用这样的形式去使用chrome devtools protocol,我们还可以使用nodejs的来获取。毕竟,Anything that can be Written in JavaScript, will Eventually be Written in JavaScript。比较常见的nodejs的库有chrome-remote-interface(下文为了方便,简述为cri),当然,如果你说我不要,我不要js,那也不是不可以,在这里,自己选一个自己喜欢的实践吧。什么typescript,go, python,ruby都有,当然,还有,我们大家都喜欢的php。
好了,作为一个前端工程师,我们还是老老实实用nodejs吧,虽然,typescript很好,但是我选择js,我们来康康,我们要怎么把各种各样的工具,组合起来,使之成为一个能够被工具化使用的页面监控呢?
具体的cri使用,请参考这个wiki
工具化的页面监控
一切的一切,我们要有一个开启了debugger端口的chrome。这个简单,你可以用shell脚本,自己起一个,当然,我们还有更优雅的方式:chrome-launcher,有了它,在寂静无人的夜,你就再也不用自己写shell脚本来启动chrome了:)。
通过chrome-launcher,我们把chrome拉起来,然后得到了一个我们需要需要调试端口,然后,我们拿着这个端口,使用cri来获取我们需要chrome-debugger-Protocol,拿到了具体的Protocol之后,我们来康康,拿到的都是些啥东西:
{"pid":8784,"tid":8728,"ts":4123614461,"ph":"X","cat":"ipc,toplevel","name":"ChannelMojo::OnMessageReceived","args":{"class":50,"line":101},"dur":2,"tdur":1,"tts":22268542},
{"pid":8784,"tid":8728,"ts":4123615131,"ph":"X","cat":"toplevel","name":"MessageLoop::RunTask","args":{"src_file":"../../content/browser/renderer_host/media/media_stream_manager.cc","src_func":"SendMessageToNativeLog"},"dur":4,"tdur":4,"tts":22268810},
{"pid":8784,"tid":8728,"ts":4123615138,"ph":"X","cat":"toplevel","name":"MessageLoop::RunTask","args":{"src_file":"../../ipc/ipc_channel_proxy.cc","src_func":"Send"},"dur":8,"tdur":8,"tts":22268817},
{"pid":8784,"tid":8788,"ts":4123551336,"ph":"X","cat":"toplevel","name":"MessageLoop::RunTask","args":{"src_file":"../../base/trace_event/trace_log.cc","src_func":"SetEnabled"},"dur":130,"tdur":130,"tts":64927429},
{"pid":8784,"tid":8788,"ts":4123551358,"ph":"I","cat":"disabled-by-default-devtools.timeline","name":"TracingStartedInBrowser","args":{"data":{"frameTreeNodeId":101,"persistentIds":true,"frames":[{"frame":"7CB62147F076D4C38B128F711003B9E9","url":"https://www.huya.com/badaozongcai","name":"201905171157120c93bb02c2ca5f727133a5547b2a8d4000016f6b3731c1440","processId":5368}]}},"tts":64927451,"s":"t"},
是不是觉得似曾相识,嗯,用chrome save下来的profile.json和上面的内容的格式一模一样。那么,这一大坨json到底是啥意思呢?这个时候,我就要把我祖传的chrome tracing event format的文档给你掏出来了。我相信,等你看完之后,你一定会,大吼一声,卧槽,这是什么鬼!这么诘屈聱牙的文档,简直了。浏览器的底层运行原理是非常复杂的,不同的类和组件的调用,使得追踪浏览器事件变成了一个不是这么容易的事情。当然,如果,想要图文并茂的了解浏览器的运行原理,请参考《life of a pixel》。
如果是我们想要程序化,工具化的去监控和管理浏览器的底层渲染行为,我们只能从上面厚厚的trace event log里,把我们需要的内容剥离出来,进行统计分析。这时候,我们会就想呀,有没有大神把这个事情给做了呀,我们这种小弟,观摩学习一下就好?
答案是,当然有啦!google chrome团队,自己就开源了一个基于typescript的分析工具Lighthouse,能够帮助我们快速的进行页面的质量分析。
Lighthouse是什么
lighthouse 是这么介绍自己的:
Lighthouse analyzes web apps and web pages, collecting modern performance metrics and insights on developer best practices.
在我看来,Lighthouse更像是一个google推行标准的衡量器。让广大的开发同学知道什么是好,什么是不好,在茫茫的人海中,找到对的那个人。
Lighthouse的工作原理
与其让我重复一遍上面的内容,还不如康康Lighthouse自己是怎么说自己的工作原理的:
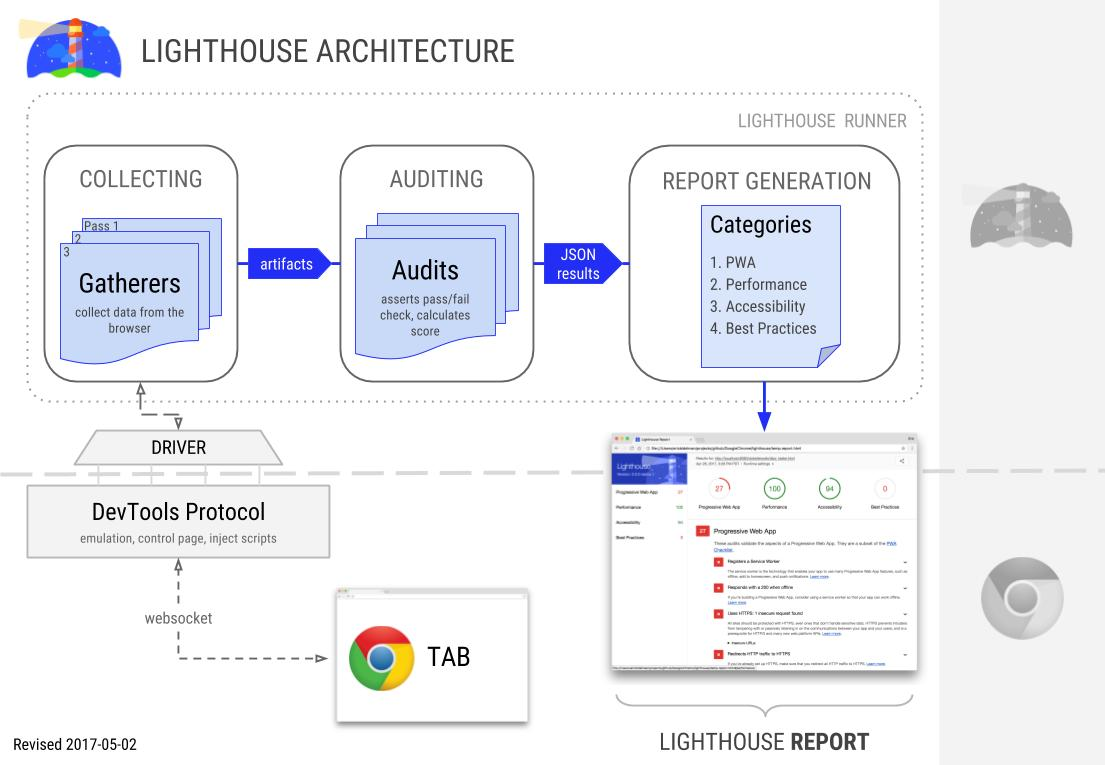
依照上图和前文,我相信大家已经对于Lighthouse是怎么执行的,有了非常深刻的理解了,通过github上Lighthouse的readme,我相信,大家也能够非常容易的把Lighthouse跑起来了。这里就不赘述了。无非就是npm install, npx lighthouse 诸如此类。
等我们把lighthouse跑起来之后,我们就可以得到下面这样的一个报告:
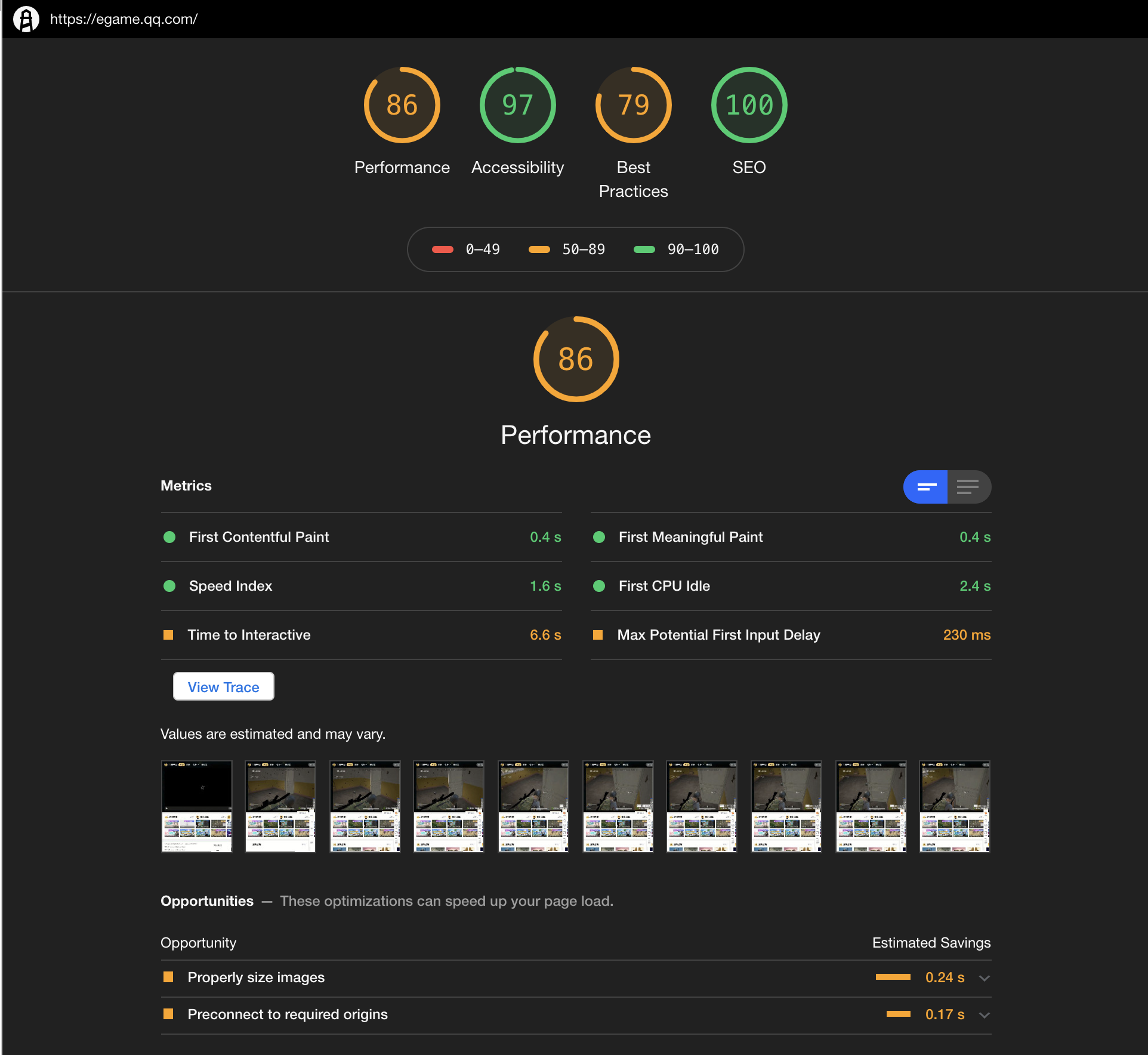
我们除了会使用到Lighthouse提供的这些评价标准和评价体系,更多的时候,会使用到属于我们自己的评价标准和评价体系。这个时候问题就来了,我们要怎么对Lighthouse进行二次开发?我们怎么基于Lighthouse做一个属于我们自己的标准衡量器?
Lighthouse的二次开发指南
在开发之前,我们先了解基本流程,从上图,我们可以清楚的得知Lighthouse的工作流程如下:
+--------------+ +-------------+ +------------+ +-------------------+
| | | | | | | |
| connecting +----->+ collecting +------->+ auditing +------>+ report generation |
| | | | | | | |
+--------------+ +-------------+ +------------+ +-------------------+
建立连接 收集日志 分析,审计 生成报告
了解了流程,我们再来了解一些基本概念,在Lighthouse里面,有如下几个特别重要的概念:
- Driver: 连接器,是前文说道的cri。用来链接和获取chrome devtools Protocol
- gatherers:采集器,对trace event log进行分类收集
- audits:对收集到的日志进行审计,最后给出出分数。
- metic:对日志内容进行分析和计算。一般是被audts调用的工具类
好了,知道了,以上这些内容,你就可以自己来搞一个Lighthouse了,正常来说,一个优秀的框架设计,都是会留有插件机制的,能够让我们非常优雅的,无侵入的把我们的逻辑添加到框架的逻辑体系中去。Lighthouse也不例外。当然,如果你说,不要,我不要,我要硬核魔改,让它变成我自己的崽,下文也会给出一些指南。
插件化的开发方式
在开发插件之前,我们需要知道,我们这个插件的结构是怎么样的。先俩简单的看一下:
-
|-your_audit.js
|-plugin.js
|-package.json
只需要三个文件,就可以自行实现一个lighthouse的插件了,是不是很简单!!!
package.json是一个npm包的必备文件,我们需要把package.json中的main指向,我们的plugin.js。
作为一个plugin,你只是需要暴露以下一个对象即可:
//plugin.js
module.exports = {
audits: [{
path: 'path/to/your/aduit',
}],
category: {
title: 'My Plugin',
description: 'my plugin.',
auditRefs: [
{id: 'your_audit', weight: 1}, //这里需要注意,id和文件名一直
{id: 'meta-description', weight: 1}, // lighthourse的默认审计项目
],
},
};
然后,在audit文件里,你可以自己定义你自己的审计规则,就像下面这样:
//my-audit.js
const Audit = require('lighthouse').Audit;
class myAudit extends Audit {
static get meta() {
return {
id: 'my-aduit',
title: '展示的title',
failureTitle: '未通过的时候,展示的文案',
description: '补充的一点的描述内容',
// 你所需要的收集内容
requiredArtifacts: ['LinkElements'],
};
}
static audit(artifacts) { // 上面指定的内容,将会被传递到这个函数中
// 处理你的逻辑
return {
score: 0, // 外显的分数以及决定是否算通过
displayValue: '显示的内容',
};
}
}
module.exports = myAudit;
在执行lighthouse命令的时候,我们需要这样来明文指示我们要用的plugin:
npx lighthouse https://example.com --plugins=my-plugin --view
然后,lighthouse就会去node_modules里面去寻找,你要使用到的lighthouse plugin。
lighthouse官方自己给了一个插件的demo,大家可以自行参考一下。里面还有plugin的效果图。
上面可以看到,开发一个plugin是很简单的。但是呢,我们也很明显的发现一个问题,这个plugin的机制有点弱,好像只能就已经收集到的信息进行审计级别的重写,并不能捕获更多的数据,然后来定义自己想要的内容。
其实吧,如果,只是想自己定义一个属于自己的评价体系,做到这一步,已经够了,毕竟lighthouse的articles给的也挺多。基本上,你能想到的常用的内容,都有。如果想知道所有的articles都有啥,请看这里。如果你想更多的了解插件的开发内容,可以参考这里。
对于我们这种,向来都不喜欢被约束的人而言,这么点东西,就想打发我,不行!作为一个成年人,作为一个半夜打开浏览器的男人,我都要!ok,那么我们来看看,我们怎么硬核的二次开发,把lighthouse变成我们自己的崽。
魔改源码
Lighthouse的源码写的很规整,加上typescript的加持,非常好读,同时大量的注释,更是如有神助。
在对lighthouse进行二次开发之前,我们需要知道lighthouse的源码结构是怎么样的。如下所示(为了不浪费篇幅,把一些和魔改无关的逻辑去掉了):
——
├─assets
├─build
├─clients // 浏览器中的展示逻辑
│ └─extension // 扩展
├─docs // 文档
├─lighthouse-cli // 命令行工具
│ ├─commands // 命令
│ └─test
├─lighthouse-core // 核心逻辑
│ ├─audits
│ ├─computed
│ │ └─metrics
│ ├─config
│ ├─gather
│ │ ├─connections
│ │ └─gatherers
│ ├─lib // 工具库
│ ├─report // 报告生成器
│ │ └─html
│ │ └─renderer
│ └─test // 测试用例
├─lighthouse-logger // 日志收集
├─lighthouse-viewer // 报告渲染工具
└─types // 类型文件
从上文所描述的内容中,我们已经知道了lighthouse的一些基本的内容和结构,所以我们可以很容易的从目录结构中,看出我们需要修改的内容,一般是围绕在Lighthouse-core的逻辑中。整体文件看起来好像比较多,但是呢,其实核心逻辑,其实还是比较集中。在Lighthouse-core。
整体的调用关系如下图
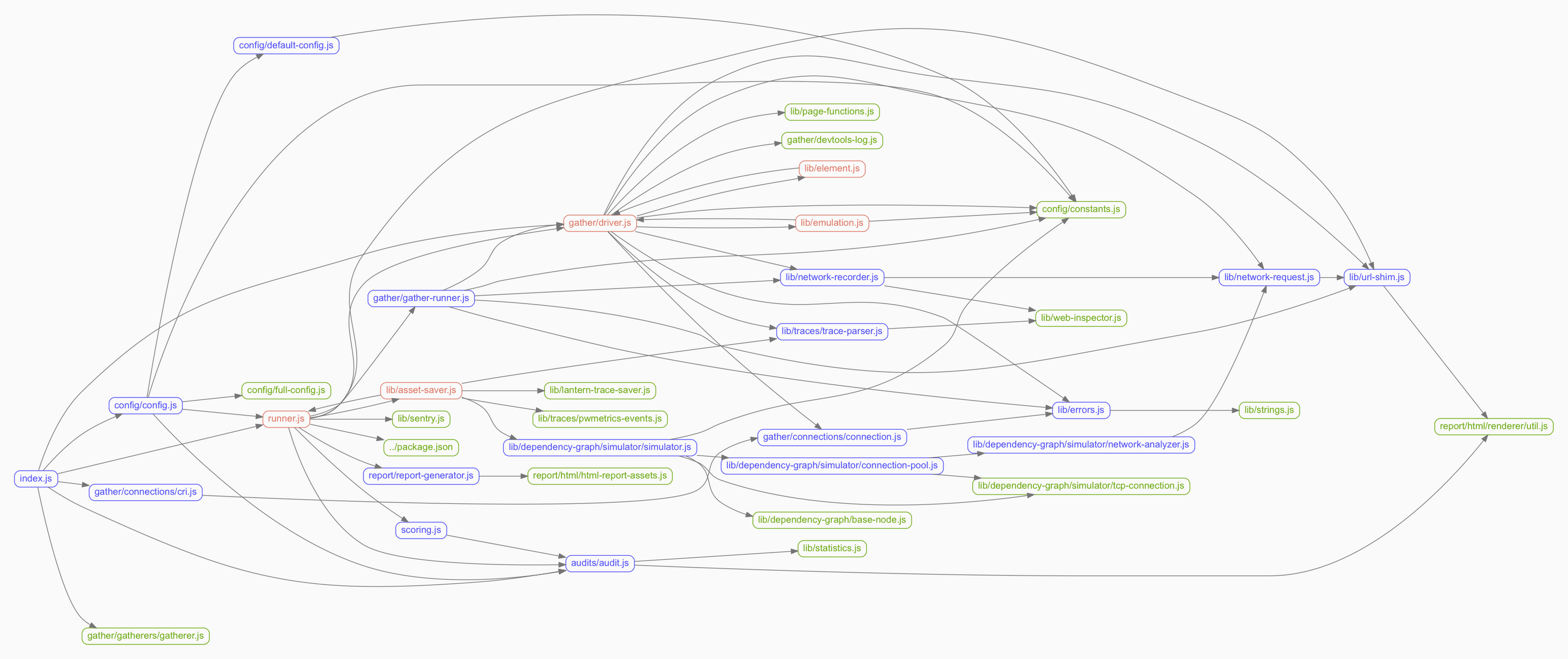
好像很复杂,重新整理了一下如下:
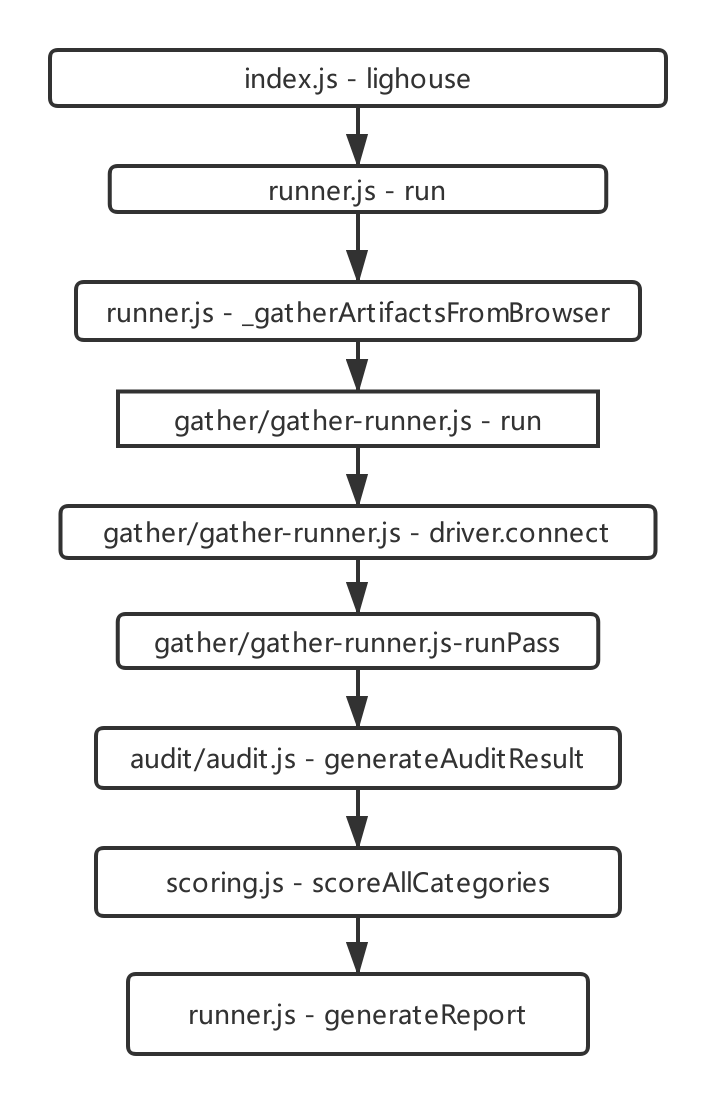
从调用链,我们可以很清楚看到前文提到的connecting->collecting->auditing->report generation的过程,其实基本上根据函数名,大家都能够分析出函数的内容。大家按照自己的需要,切进去魔改就好了,想改啥都行。
说实话,Lighthouse的整体设计还是很不错的,加上typescript的加持,整个代码的可读性还是很强的。其实基于plugin的机制,基本上已经可以满足大家的各种需求了。如果真的有一天,已经到了,必须要修改源码的地步了,希望上述内容能帮助到大家。
如何做到更加客观?
好了,基于上文的魔改,我们已经得到了一个属于我们自己的lighthouse和我们自己的审计规则。但是,在你电脑上跑出来的数据,并不真实,并不能代表广大的人民群众。所以,我们需要做以下的工作:
- 云端部署
把我们的服务部署在云端的机器,直接接受外部网络环境的洗礼。同时限制硬件素质,保持一个比较贴近现实的机器水平。
- 多地部署
在天津,上海,广州等多个节点进行部署,看看地理位置因素,到底会给页面带来多大的影响。
- 多时运行
一天在不同的时间段内执行,看看不同的时间里,随着网络流量的周期变化,你的页面在哪个时间最糟糕?当然,这里还有一个更为重要的作用,就是,抽查页面的可访问性,页面是不是挂了?让你成为最早知道页面完整信息的人。
- 多次运行
多次执行取平均值咯,去除单一缓存的影响。
基于这种考虑,我们开发了leadership,可以同时对比多份报告,云端运行。
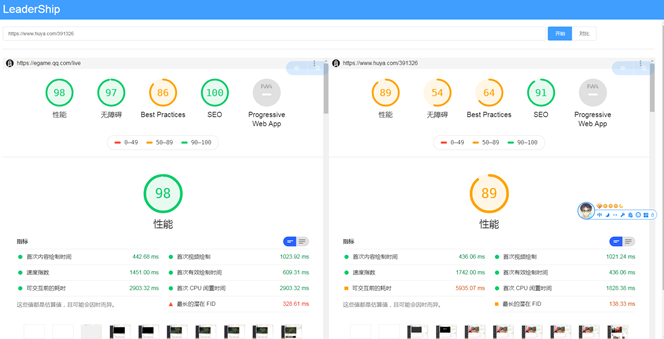
完成了如此种种,我终于才能够在寂静无人的夜,比较客观公正的对产品说,我的页面真的比竞品的页面快!你看,这是我的报告!

关注【IVWEB社区】公众号获取每周最新文章,通往人生之巅!
