

这篇文章是续上一篇(爬取抖音数据实践方案《基础版》)。根据实际情况,落地的方案是:mitmdump+模拟器+python脚本+mysql数据库。
最终达到的效果截图:
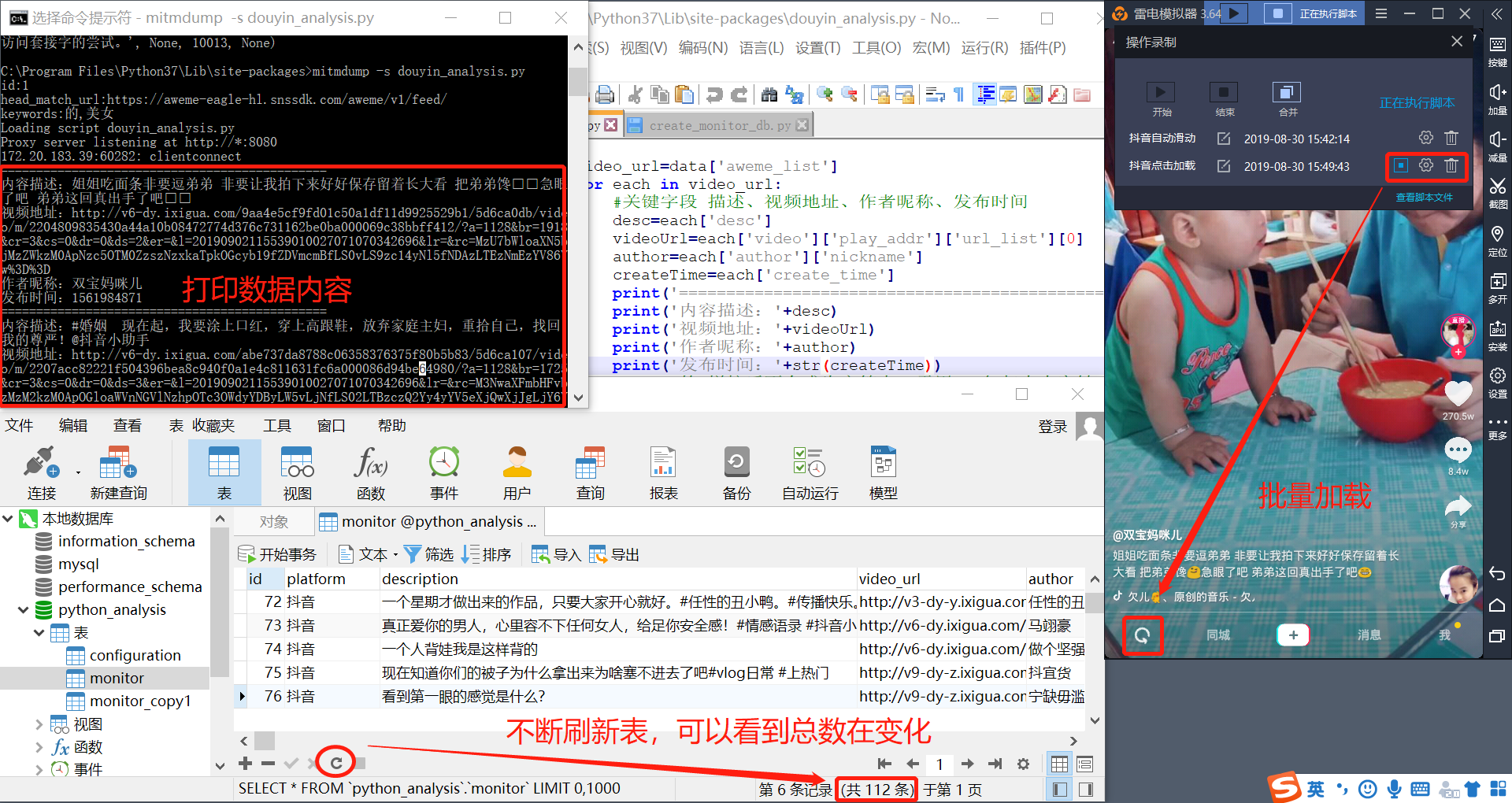
接下来我把上面方案拆解为以下几部分介绍,重点是模拟器的代理设置和python脚本写法。
一、mitmdump设置
这里假设你已经在本地电脑安装好了mitmdump代理服务器,并设置好了pc端的https证书。(不知道怎么操作可以参看上一篇文章)
二、模拟器的代理设置
市面上的模拟器种类很多,参差不齐。我们尽量选一款功能比较全的,并且可以录制自动执行脚本。(这个后面会用到,我用的是雷电模拟器。)
主要需要处理的点是:
1)模拟器代理设置
2)模拟器安装https证书
3)证书安装需要设置pin码
4)录制模拟器自动执行脚本
1)代理设置:
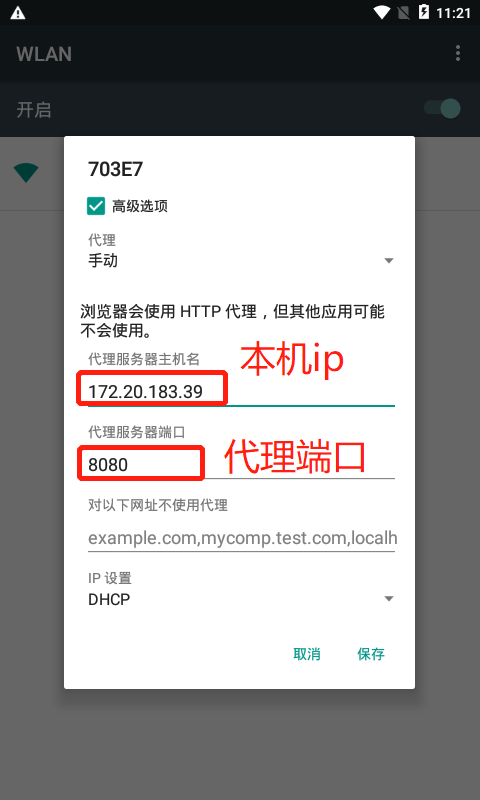
2)安装证书:
对于mitmdump的代理服务器,只要代理服务器启动了。可以在终端的浏览器输入mitm.it来下载证书安装,我尝试了雷电模拟器的证书下载、夜神模拟器的证书下载。有点奇怪的是,下载的文件我找不到放在哪个目录,在安装证书选择的目录时,层级目录和下载证书的目录貌似是隔离的。
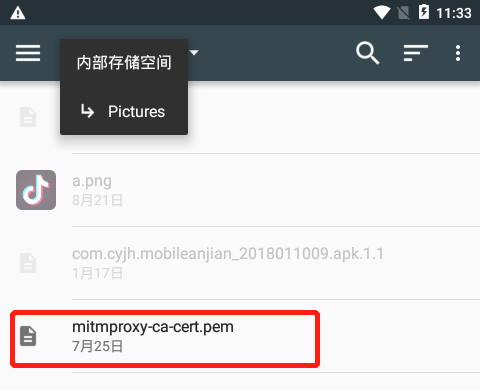
最后,我是通过手动copy的方式,把证书拖拽到雷电模拟器上。然后安装证书选择目录时,在Picture的目录找到该证书,安装成功。
安装证书步骤:
设置/安全/从SD卡安装证书
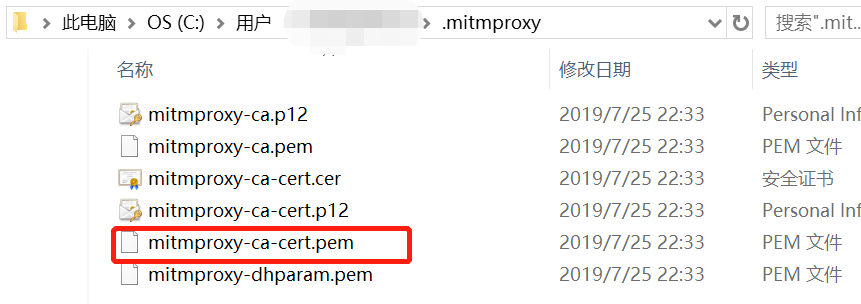
注意:一般mitmdump代理服务器安装成功后,可以在用户目录下找到.mitmproxy目录,然后找到mitmproxy-ca-cert.pem文件,把这个文件拖拽到模拟器即可。
3)设置pin码
安装完证书后,会弹窗提示,需要设置pin码。由于我这里已经安装证书了,不会弹窗提示,就不截图了。
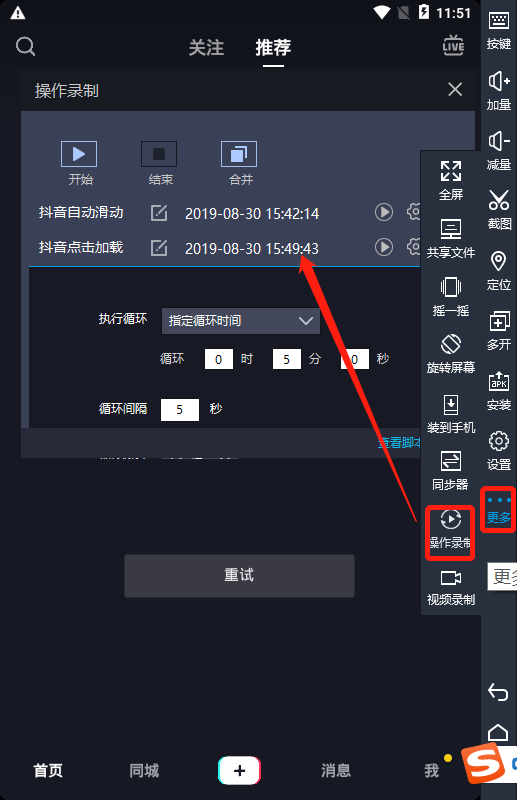
4)录制模拟器自动执行脚本
可以在如下位置,找到模拟器录制操作手势的入口。可以设置自动执行的时间或者次数,从而达到自动执行手势的目的。
三、python脚本
通过代理,我们可以拿到中转的所有request和response数据。而python脚本则是处理数据逻辑,例如判断关键字,数据入库等。
数据处理逻辑:
#导入需要使用到的数据模块(pandas模块这里引入有问题,不用!)
#import pandas as pd
#import pymysql
import json,os
import requests
import pymysql
#建立数据库连接
db = pymysql.connect('localhost','root','root','python_analysis')
#获取游标对象
cursor = db.cursor()
#插入数据语句
insert = """insert into monitor (
platform,
description,
video_url,
author,
create_time)
values (%s,%s,%s,%s,%s)"""
# SQL 查询语句
query = "SELECT * FROM configuration"
try:
# 执行SQL语句
cursor.execute(query)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
id = row[0]
head_match_url = row[1]
keywords = row[2]
# 打印结果
print('id:'+str(id))
print('head_match_url:'+head_match_url)
print('keywords:'+keywords)
except:
print ("Error: unable to fetch data")
#print('=======全局部分执行一次=======')
def response(flow):
#print('=======函数部分每次执行=======')
#首页视频
#url='https://aweme-eagle-hl.snssdk.com/aweme/v1/feed/'
url=head_match_url
#筛选出以上面url为开头的url
if flow.request.url.startswith(url):
text=flow.response.text
#将已编码的json字符串解码为python对象
data=json.loads(text)
video_url=data['aweme_list']
for each in video_url:
#关键字段 描述、视频地址、作者昵称、发布时间
desc=each['desc']
videoUrl=each['video']['play_addr']['url_list'][0]
author=each['author']['nickname']
createTime=each['create_time']
print('==============================================')
print('内容描述:'+desc)
print('视频地址:'+videoUrl)
print('作者昵称:'+author)
print('发布时间:'+str(createTime))
#python的+拼接后不会成为字符串,需用str包起来内容转成字符串。
#关键字分割
mkeywords = keywords.split(',');
for keyword in mkeywords:
#关键字匹配
if keyword in desc:
# 占位符
values = ('抖音', desc, videoUrl, author, createTime)
try:
# 执行sql语句
cursor.execute(insert, values)
# 执行sql语句
db.commit()
except:
# 发生错误时回滚
db.rollback()
#关闭游标,提交,关闭数据库连接<注意:由于这里程序是需要连续不断监控,所以游标和db都不关>
#cursor.close()
#db.commit()
#db.close()
print('==============================================')创建入库数据表:(我这里通过python脚本创建)
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","root","root","python_analysis" )
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL,如果表存在则删除<数据库自动会把表名转成小写>
cursor.execute("DROP TABLE IF EXISTS monitor")
# 使用预处理语句创建表<注意:desc、describe貌似撞中了关键字,换成其他的即可。>
# platform, description, video_url, author, create_time
# PLATTFORM, DESC, VIDEO_URL, AUTHOR, CREATE_TIME
sql = """CREATE TABLE monitor (
id int primary key AUTO_INCREMENT,
platform VARCHAR(255) COMMENT '平台',
description VARCHAR(255) COMMENT '描述',
video_url TEXT COMMENT '视频地址',
author VARCHAR(255) COMMENT '作者',
create_time VARCHAR(255) COMMENT '发布时间' )"""
#关闭游标,提交,关闭数据库连接
cursor.execute(sql)
db.commit()
db.close()注意:
1.这里需要引入py的requests模块、pymysql模块。
2.数据库已经安装并启动,有数据库连接的账户,在py脚本中需要用到。
3.截至2019年9月5号,抖音更新了新版本,最新版本的数据交互貌似使用了protocol buffer,在这里python处理数据的时候要注意。
