

Scala 简介
Scala 是一种有趣的语言,它一方面吸收继承了多种语言中的优秀特性,一方面又没有抛弃 Java 这个强大的平台,它运行在 Java 虚拟机(Java Virtual Machine)之上,轻松实现和丰富的 Java 类库互联互通。它即支持面向对象的编程方式,又支持函数式编程。它写出的程序像动态语言一样简洁,但事实上它却是严格意义上的静态语言。
目前大数据计算引擎 Spark 就是用 Scala 编写的,在 Spark 中把 Scala 的分布式、高并发、简洁等特性发挥的淋漓尽致。
Scala 基础知识
常量与变量
Scala 中常量以 val 定义,变量以 var 定义。val(value)表示常量,不可修改,但是在 REPL 可以重新赋值。var(variable)表示可变的,可以重新赋值或修改。定义变量时,可不显式指定数据类型,Scala 有很强类型自动推导功能,Scala 具有动态语言似的编写代码,但又有静态语言的编译时检查。
val a = 10 // 定义常量
val a = 11 // a 是常量,不可修改
var c = 80 // 定义变量
c = 100
基础数据类型
Scala 中基础数据类型有:Byte、Short、Int、Long、Float、Double、Boolean、Char、String。和 Java 中不同的是,Scala 中没有区分原生类型和装箱类型,如:int 和 Integer。它统一抽象成 Int 类型,这样在 Scala 中所有类型都是对象了。
Scala 中单引号和双引号包裹是有区别的,单引号用于字符,双引号用于字符串,而且双引号中特殊字符,需用转移字符 "\"。此外,还有多行字面量(如3个引号)和字符串内插等特性。
Scala 是基于 JVM 平台,默认使用 unicode,所以变量名可以直接使用中文。而在 Scala 中,中文也是直接显示的,
控制语句
Scala 内置的控制语言有 if、while、for、match case 四大主要控制语言。Scala 的控制语句都是表达式是有返回值的。
if 语句格式
if (Boolean express) express
if (Boolean express) express else express
while 语句格式
while (Boolean express) {
statement
}
for 语句格式
for (identifies <- iterator)[yield] [express]
关键字 yield 是可选的,如果表达式指定这个关键字,所有表达式的值将作为一个集合返回;如果没有指定这个关键字,则调用表达式,但不能访问其返回值。
Scala 中迭代器守卫(iterator guard)
if (identifies <- iterator if Boolean express)[yield] [express]
match case 语句格式
express match{
case pattern_match => express
[case statement]
}
Scala 中的 match case 称之为模式匹配,它是默认 break 的,只要其中一个 case 语句匹配,就终止之后的所有比较。且对应 case 语句的表达值的值将作为整个 match case 表达式的返回值。
常用集合
在 Scala 中常用集合有:Array、List、Tuple、Set、Map等。
Scala 中各集合间的层次结构如下:
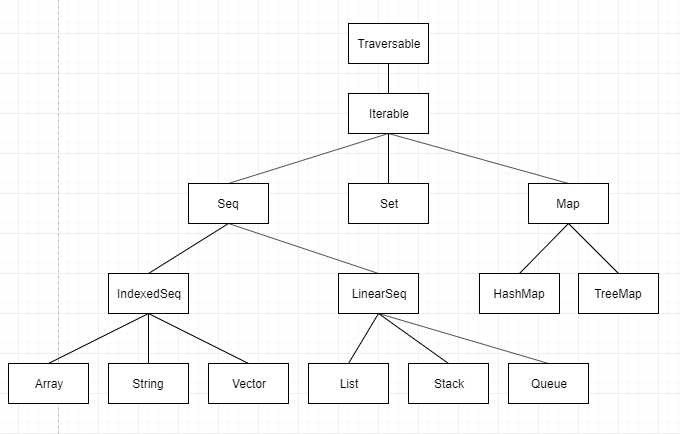
数组
数组 Array,下标从 0 开始,通过 () 来引用,成员可修改。
val array = Array("python", "java", "scala")
array(1) // 结果: java
array(1) = "spark" // array(1) 修改为 "spark"
列表
列表 List,下标从 0 开始,通过 () 来引用,成员可读,但不可修改,List 是 Iterable 的一个子类型。
val list = List(5, 10, 20)
list(2) // 结果:20
list(1) = 30 // 报错,成员不能修改
列表还可以通过 :: 操作符,将一个元素和列表连接起来,并把元素放在列表的开头。
1::list // List(1, 5, 10, 20)
列表常用的方法:
| 方法 | 示例 | 说明 |
|---|---|---|
| contains | List(1,2,3).contains(2) | 检查列表中是否包含某个元素 |
| exists | List(1,2,3).exists(_>2) | 检查列表中是否至少有一个满足条件的元素 |
| forall | List(1,2,3).forall(_>2) | 检查列表中所有元素都满足条件 |
| distinct | List(1,2,3,1,2).distinct | 去重复元素 |
| filter | List(1,2,3).filter(_>2) | 过滤是条件为 True 的元素 |
| flatten | List(List(1,2),List(3,4)).flatten | 将列表的列表变为元素列表 |
| map | List(1,2,3).map(_*10) | 将函数作用于遍历集合中每个元素得到新列表,有返回追 |
| foreach | List(1,2,3).foreach(x=>println(x)) | 将函数作用于遍历集合中每个元素,无返回值 |
| reduce | List(1,2,3).reduce(_+_) | 从列表第一个元素开始从左到右规约处理 |
| sortBy | List("abc"," cd", " efg") .sortBy(_.size) |
根据函数返回值进行排序 |
| take | List(1,2,3,4).take(2) | 取列表前 n 个元素 |
| size | List(1,2,3).size | 统计列表元素个数 |
| zip | List(1,2) zip List(3,4) | 将两个列表合并为一个元组列表,列表对应索引组成一个元组 |
元组
Scala 中采用小括号来定义元组 Tuple,下标从 1 开始,通过 _ 下标来访问成员,不能通过 ()来访问成员,元组最多支持 22 个元素。
val t = (2,5,1,4)
t._1 // 取元组第一个元素,结果:2
集合
Set 是一个不重复且无序的集合,初始化一个集合需要使用 Set 对象
val set = Set(1,2,2,3,4)
映射
Scala 中的 Map 是个可变的键/值库,创建 Map 时,指定 键-值 为元组,也可以使用关系操作(->)来指定键和值元组。与 Set、List 一样,Map 也是 Iterator 的一个子类型,支持与 List 相同操作。Map 默认是不可修改的,如果要变成可以修改的 Map,需要显式定义其类型,如 scala.collection.mutable.Map。
val map = Map(1->"python",2->"java",3->"scala")
map(3) // 结果:scala
map += (4->"C++") // 异常,map 默认是不可变的,故添加元素报错
val map = scala.collection.mutable.Map(1->"python",2->"java",3->"scala")
map += (4->"C++")
// map 遍历
for (key<-map.keys) print(s"${key}")
for (key<-map.values) print(s"${value}")
函数
函数是可重用的逻辑单位,在 Scala 中,函数是一等公民,函数式编程是 Scala 的一大特色。函数可以被赋值给一个变量,也可以作为一个函数的参数被传入,甚至还可以作为函数的返回值返回。
函数的定义
在 Scala 中使用 def 关键词来定义一个函数,定义函数一般需要确定函数的名称、参数和函数体,具体格式如下:
def <func_name>(<param>:<type>[,...]):type=<expression>
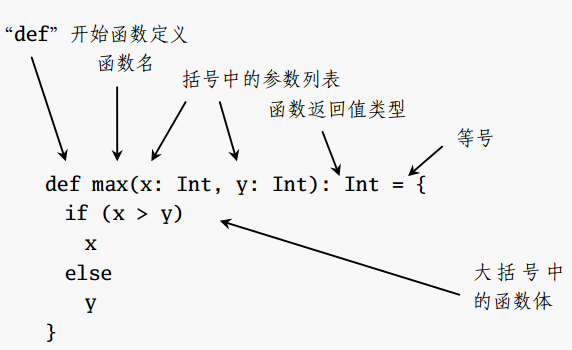
如果有参数,需要说明参数类型,如果函数不是递归,就不一定需要指明返回类型,Scala 在编译的时候可以根据等号右侧的表达式的类型推导出返回类型。
如果函数体有多条语句,可以放在 {} 中,最后一句的值为函数的返回值,有时需要用 return 显式指定返回值,并退出函数。
def fun1(x:Int) = if(x>0) x else -x // 不指明返回值类型
def fun2(x:Int):Int = if(x>0) x else -x // 指明返回值类型
def f1() = "hello"
def f2 = "ok"
def f3 = "scala"
匿名函数
在 Scala 中有匿名函数,匿名函数是 Scala 的重要特点之一,语法格式为:
([<param1>:<type>,...])=><expression>
示例:
var a = (x:Int)=> x+2
var y = a(10) // 结果:12
递归函数
函数也是对象,可以把它视为参数化表达式块,而表达式块是可以递归或嵌套,所以函数本身也可以递归或嵌套。
递归会造成堆栈的大量占用,可以使用尾递归进行优化。优化的方式是,在函数定义前加上@annotation.tailrec 这个注解来声明尾递归,当编译器检测一个函数调用是尾递归时,它就覆盖当前的活动记录而不是在栈中去创建一个新的,只有最后一个语句为递归调用的函数才能由 Scala 编译器完成尾递归优化,否则编译时将报错。
def fn(n:Int):Int={
if (n<=0) 1
else n*fn(n-1)
}
// 尾递归
@annotation.tailrec
def fn(n:Int, m:Int):Int={
if (n<=0) m
else fn(n-1, m*n)
}
有默认值参数的函数
在 Scala 中有带默认参数的函数,使用了默认参数,当在调用函数的过程中可以输入该参数,也可以不输入该参数,如果没有传递参数,则会调用它的默认参数值,如果传递了参数,则传递值会取代默认参数。
def addInt(x:Int,y:Int=0):Int = {
x+y
}
addInt(20) // 使用默认参数,结果:20
addInt(20,30) // 使用传递的参数,结果:50
变长参数的函数
在 Scala 中有变长参数函数,只需要在该函数参数类型后增加一个星号(*)
def sum(items:Int*):Int = {
var sum = 0
for(i <- items) sum += i
sum
}
sum(1,2,3)
sum(1,2,3,4)
可以在调用函数参数后面追加 :_*,:_* 操作符将高速编译器把序列(Array,List,Seq,Vector等)中的每个元素作为一个单独的参数传给函数。
val list = List(1,2,3,4,5)
sum(list:_*) // 结果:15
部分应用的函数
调用函数时,通常需要制定函数中的所有参数(函默认值的参数除外),如果参数较多,而且调用是希望保留部分参数值,而修改部分参数值,可以在原函数基础上定义一个部分应用函数即可。
def addItems(x:Int, y:Int):Int = x+y
val addItems10 = addItems(10, _:Int)
addItems10(30) // 结果:40
柯里化函数
实现部分应用函数,还有一种更简便的做法,采用多个参数表的函数,将一个参数表分成应用参数和非应用参数而是应用其中一个参数表的重参数,不用另一个参数表中的参数,这种技术称为柯里化(currying)。
def additems(x:Int)(y:Int):Int = x+y
val addItems10 = addItems(10)_
addItems10(30) // 结果:40

好文推荐:
