



原创不易,希望能关注下我们,再顺手点个赞~~
本文首发于政采云前端团队博客: 自动化 Web 性能分析之 Puppeteer 爬虫实践

通过上篇文章《自动化 Web 性能优化分析方案》的分享想必大家对“百策系统”有了初步的了解。本文将向大家介绍自动化性能分析使用的核心库——Puppeteer,并结合页面登录场景,介绍 Puppeteer 在百策系统中的应用。
Puppeteer 简介
Puppeteer 是一个 Node 库,它提供了一整套高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。正如其翻译为“操纵木偶的人”一样, 你可以通过 Puppeteer 的提供的 API 直接控制 Chrome,模拟大部分用户操作来进行 UI 测试或者作为爬虫访问页面来收集数据。
Puppeteer 用途
- 生成页面的屏幕截图和 PDF。
- 爬取 SPA 应用,并生成预渲染内容(即 SSR 服务端渲染)。
- 自动执行表单提交、UI测试、键盘输入等。
- 创建最新的自动化测试环境,使用最新的 JavaScript 和浏览器功能,直接在最新版本的 Chrome 中运行测试。
- 捕获页面的时间轴来帮助诊断性能问题。
- 测试 Chrome 扩展程序。
- 从页面抓取所需要的内容。
Puppeteer 安装
阅读 Puppeteer 的 官方 API 你会发现满屏的 async、await ,这些都是 ES7 的规范,所以你需要:
-
Node.js 的版本不能低于 v7.6.0,因为需要支持
async、await; -
需要最新的 Chrome Driver, 这个你在通过 npm 安装 Puppeteer 的时候系统会自动下载的。
# 配置淘宝的 Puppeteer下载源,用于安装 Chromium
# 国内环境若不配置,会卡在下载 Chromium ,你可以这样切换 npm 源
npm config set registry registry.npm.taobao.org
export PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors
npm i puppeteer
初探 Puppeteer:从页面截图开始
实现页面截图,首先我们需要创建一个浏览器实例,然后打开一个页面,加载指定的 URL,在打开的页面上触发截图操作,最后再将浏览器关闭。因此,我们需要用到以下 API:
puppeteer.launch([options])启动浏览器实例browser.newPage()创建一个Page对象page.goto(url[,options])跳转至指定页面page.screenshot([options])进行页面截图browser.close()关闭 Chromium 及其所有页面
实现代码如下:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
// 是否运行浏览器无头模式(boolean)
headless: false,
// 是否自动打开调试工具(boolean),若此值为true,headless自动置为fasle
devtools: true,
// 设置超时时间(number),若此值为0,则禁用超时
timeout: 20000,
});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
await page.screenshot({
// 截图保存路径(string)
path: './one.png',
// 是否保存完整页面(boolean)
fullPage: true
});
await browser.close();
})();
执行完以上代码,我们就可以在当前路径找到 one.png,我们打开就可以看到如下截图:
又探 Puppeteer:自动测试页面性能
我们知道 Web Performance 接口允许页面中的 JavaScript 代码可以通过具体的函数测量当前网页页面或者 Web 应用的性能。为能在页面执行 JavaScript 从而来检测页面性能,我们就需要用到以下 API:
page.evaluate(pageFunction[, ...args])在浏览器中执行此函数,返回一个 Promise 对象
const puppeteer = require('puppeteer');
// 检测页面url
const url = 'https://www.zhengcaiyun.cn';
// 检测次数
const times = 5;
const record = [];
(async () => {
for (let i = 0; i < times; i++) {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto(url);
// 等待保证页面加载完成
await page.waitFor(5000);
// 获取页面的 window.performance 属性
const timing = JSON.parse(await page.evaluate(
() => JSON.stringify(window.performance.timing)
));
record.push(calculate(timing));
await browser.close();
}
let whiteScreenTime = 0, requestTime = 0;
for (let item of record) {
whiteScreenTime += item.whiteScreenTime;
requestTime += item.requestTime;
}
// 检测计算结果
const result = [];
result.push(url);
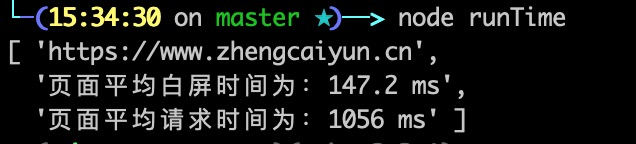
result.push(`页面平均白屏时间为:${whiteScreenTime / times} ms`);
result.push(`页面平均请求时间为:${requestTime / times} ms`);
console.log(result);
function calculate(timing) {
const result = {};
// 白屏时间
result.whiteScreenTime = timing.responseStart - timing.navigationStart;
// 请求时间
result.requestTime = timing.responseEnd - timing.responseStart;
return result;
}
})();
执行完以上代码,我们就可以在终端看到检测页面的基本性能信息:
双探 Puppeteer:爬取苏宁易购的商品信息
打开电商首页,输入想要的商品名称,点击搜索按钮,跳转至相应的商品列表页,然后一页页浏览,从而找到心仪的商品,这大概就是我们平时网购的样子。那么如何让浏览器自动执行以上步骤,同时还能抽空爬取每页的商品信息,顺便将信息导出至文件呢?为此,我们需要用到以下 API:
page.title()获取页面标题page.type(selector, text[, options])获取输入框焦点并输入内容page.click(selector[, options])点击要选择的元素page.waitForNavigation([options])等待页面跳转page.waitFor(selectorOrFunctionOrTimeout[, options[, ...args]])页面等待时间fs.createWriteStream对文件流进行写入window.scrollBy(xnum, ynum)页面向右、向下滑动的像素值
const fs = require('fs');
const puppeteer = require('puppeteer');
// 本次模拟获取苏宁易购的数据,来抓取在售的所有笔记本电脑信息~
(async () => {
const browser = await (puppeteer.launch({ headless: false }));
const page = await browser.newPage();
// 进入页面
// await page.goto('https://search.suning.com/笔记本电脑/');
await page.goto('https://www.suning.com');
// 获取页面标题
let title = await page.title();
console.log(title);
// 点击搜索框拟人输入“笔记本电脑”
await page.type('#searchKeywords', '笔记本电脑', { delay: 500 });
// 点击搜索按钮
await page.click('.search-btn');
// await page.click('#searchKeywords');
// await page.type('#searchKeywords', String.fromCharCode(13));
// 等待页面跳转,注意:如果 click() 触发了一个跳转,会有一个独立的 page.waitForNavigation()对象需要等待
await page.waitForNavigation();
// 获取当前搜索项商品最大页数,为节约爬取时间,暂只爬取前5页数据
// const maxPage = await page.evaluate(() => {
// return Number($('#bottomPage').attr('max'));
// })
const maxPage = 5;
let allInfo = [];
for (let i = 0; i < maxPage; i++) {
// 因为苏宁页面的商品信息用了懒加载,所以需要把页面滑动到最底部,保证所有商品数据都加载出来
await autoScroll(page);
// 保证每个商品信息都加载出来
await page.waitFor(5000);
// 获取每个
const SHOP_LIST_SELECTOR = 'ul.general.clearfix';
const shopList = await page.evaluate((sel) => {
const shopBoxs = Array.from($(sel).find('li div.res-info'));
const item = shopBoxs.map(v => {
// 获取每个商品的名称、品牌、价格
const title = $(v).find('div.title-selling-point').text().trim();
const brand = $(v).find('b.highlight').text().trim();
const price = $(v).find('span.def-price').text().trim();
return {
title,
brand,
price,
};
});
return item;
}, SHOP_LIST_SELECTOR);
allInfo = [...allInfo, ...shopList];
// 当当前页面并非最大页的时候,跳转到下一页
if (i < maxPage - 1) {
const nextPageUrl = await page.evaluate(() => {
const url = $('#nextPage').get(0).href;
return url;
});
await page.goto(nextPageUrl, { waitUntil:'networkidle0' });
// waitUntil对应的参数如下:
// load - 页面的load事件触发时
// domcontentloaded - 页面的 DOMContentLoaded 事件触发时
// networkidle0 - 不再有网络连接时触发(至少500毫秒后)
// networkidle2 - 只有2个网络连接时触发(至少500毫秒后)
}
}
console.log(`共获取到${allInfo.length}台笔记本电脑信息`);
// 将笔记本电脑信息写入文件
writerStream = fs.createWriteStream('notebook.json');
writerStream.write(JSON.stringify(allInfo, undefined, 2), 'UTF8');
writerStream.end();
browser.close();
// 滑动屏幕,滚至页面底部
function autoScroll(page) {
return page.evaluate(() => {
return new Promise((resolve) => {
var totalHeight = 0;
var distance = 100;
// 每200毫秒让页面下滑100像素的距离
var timer = setInterval(() => {
var scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 200);
})
});
}
})();
执行完以上代码,我们就可以在终端看到爬取的笔记本电脑总数:

同时我们可以在当前路径找到 notebook.json 文件,打开可以看到所有爬取的笔记本电脑信息:

叒探 Puppeteer:“百策系统”实现模拟登录
以下内容是对上次“百策系统”的分享《自动化 Web 性能优化分析方案》内容的后续补充,要是不了解“百策系统”的同学可以先补补课哈。
当“百策系统”分析需要登录的页面时,如何模拟用户的登录行为呢?比如检测我们政采云的后台页面,我们就需要先分辨出当前页面处于哪个环境,其次跳转至对应环境的登录页面,之后再输入账号密码,待登录完成后,跳转至后台页面的 URL,再进行页面后续的操作。那么如何实现以上功能呢,这里就需要用到以下 API:
browser.createIncognitoBrowserContext()创建一个匿名浏览器上下文,这将不会与其他浏览器上下文分享 cookies/cachepage.waitForSelector(selector[, options])等待指定的选择器匹配的元素出现在页面中page.$eval(selector, pageFunction[, ...args])此方法在页面内执行document.querySelector,然后把匹配到的元素作为第一个参数传给pageFunction。
const puppeteer = require('puppeteer');
// 根据不同环境的页面,返回对应环境下登录的 url
const getLoginPath = target => {
if (target.includes('-staging.zcygov.cn')) {
return 'https://login-staging.zcygov.cn/user-login/';
} else if (target.includes('test.zcygov.cn')) {
return 'http://login.test.zcygov.cn/user-login/';
} else {
return 'https://login.zcygov.cn/user-login/';
}
};
async function loginSimulation(url, options) {
const browser = await puppeteer.launch();
// 创建一个匿名的浏览器上下文,这将不会与其他浏览器上下文分享 cookies/cache。
const context = await browser.createIncognitoBrowserContext();
const page = await context.newPage();
// waitUntil对应的参数如下:
// load - 页面的load事件触发时
// domcontentloaded - 页面的 DOMContentLoaded 事件触发时
// networkidle0 - 不再有网络连接时触发(至少500毫秒后)
// networkidle2 - 只有2个网络连接时触发(至少500毫秒后)
// 若参数中有用户名密码,则先到登录页面进行登录再进行性能检测
if (options.username && options.password) {
// 跳转至相应的登录页面
await page.goto(getLoginPath(url), { waitUntil: 'networkidle0' });
// 输入用户账号
await page.type('.login-form #username', options.username);
// 输入用户密码
await page.type('.login-form #password', options.password);
// 点击登录按钮
await page.click('.login-form .password-login');
// 等待页面跳转,注意:如果 click() 触发了一个跳转,会有一个独立的 page.waitForNavigation()对象需要等待
await page.waitForNavigation();
// 若跳转之后的页面仍处在登录页,说明登录出错
const pUrl = await page.url();
if (pUrl.includes('login')) {
await page.waitForSelector('.form-content > .error-text > .text');
// 获取错误信息内容
const errorText = await page.$eval('.form-content > .error-text > .text', el => el.textContent.trim());
// 报出错误信息
throw new Error(`政采云登录失败,${errorText}`);
}
}
};
叕探 Puppeteer:搞定滑动解锁
目前有许多站点的登录页面都添加了滑动解锁校验,这无疑对页面信息的爬取增加了难度,但是技术都是在互相碰撞中进步的。我们不仅要直面这座大山,还要想着跨越过去,为此,我们需要用到以下 API:
CanvasRenderingContext2D.getImageData()返回一个ImageData对象,用来描述 canvas 区域隐含的像素数据page.$(selector)此方法在页面内执行document.querySelectorpage.mouse.down([options])触发一个mousedown事件page.mouse.move([options])触发一个mousemove事件page.mouse.up([options])触发一个mouseup事件
const puppeteer = require('puppeteer');
(async function run() {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: {
width: 1200,
height: 600
}
});
page = await browser.newPage();
// 1.打开 bilibili 登录页面
await page.goto('https://passport.bilibili.com/login');
await page.waitFor(3000);
// 3.输入账号密码
await page.type('input#login-username','你的账号', { delay: 50 });
await page.type('input#login-passwd','你的密码', { delay: 50 });
// 4.点登陆按钮
await page.click('.btn.btn-login');
// 保证滑动弹窗加载出
await page.waitFor(3000);
// 获取像素差较大的最左侧横坐标
const diffX = await page.evaluate(() => {
const fullbg = document.querySelector('.geetest_canvas_fullbg'); // 完成图片
const bg = document.querySelector('.geetest_canvas_bg'); // 带缺口图片
const diffPixel = 40; // 像素差
// 滑动解锁的背景图片的尺寸为 260*160
// 拼图右侧离背景最左侧距离为 46px,故从 47px 的位置开始检测
for(let i = 47; i < 260; i++) {
for(let j = 1; j < 160; j++) {
const fullbgData = fullbg.getContext("2d").getImageData(i, j, 1, 1).data;
const bgData = bg.getContext("2d").getImageData(i, j, 1, 1).data;
const red = Math.abs(fullbgData[0] - bgData[0]);
const green = Math.abs(fullbgData[1] - bgData[1]);
const blue = Math.abs(fullbgData[2] - bgData[2]);
// 若找到两张图片在同样像素点中,red、green、blue 有一个值相差较大,即可视为缺口图片中缺口的最左侧横坐标位置
if(red > diffPixel || green > diffPixel || blue > diffPixel) {
return i;
}
}
}
});
// 获取滑动按钮在页面中的坐标
const dragButton = await page.$('.geetest_slider_button');
const box = await dragButton.boundingBox();
// 获取滑动按钮中心点位置
const x = box.x + (box.width / 2);
const y = box.y + (box.height / 2);
// 鼠标滑动至滑动按钮中心点
await page.mouse.move(x, y);
// 按下鼠标
await page.mouse.down();
// 慢慢滑动至缺口位置,因起始位置有约 7px 的偏差,故终点值为 x + diffX - 7
for (let i = x; i < x + diffX - 7; i = i + 5) {
// 滑动鼠标
await page.mouse.move(i, y);
}
// 假装有个停顿,看起来更像是人为操作
await page.waitFor(200);
// 放开鼠标
await page.mouse.up();
await page.waitFor(5000);
await browser.close();
})();
执行完以上代码,来看下实现效果:
结语
当然, Puppeteer 的强大不止于此,我们可以通过 Puppeteer 实现更多有意思的功能,比如使用 Puppeteer 来检测页面图片是否使用懒加载,后续我们会对其功能的实现进行的分享,也请持续关注我们微信公众号“政采云前端团队”以及关注我们掘金账号。
引用资料
- Puppeteer 官方文档:www.npmjs.com/package/pup…
- Puppeteer 中文 API:zhaoqize.github.io/puppeteer-a…
招贤纳士
招人,前端,隶属政采云前端大团队(ZooTeam),50 余个小伙伴正等你加入一起浪~ 如果你想改变一直被事折腾,希望开始能折腾事;如果你想改变一直被告诫需要多些想法,却无从破局;如果你想改变你有能力去做成那个结果,却不需要你;如果你想改变你想做成的事需要一个团队去支撑,但没你带人的位置;如果你想改变“5年工作时间3年工作经验”;如果你想改变本来悟性不错,但总是有那一层窗户纸的模糊… 如果你相信相信的力量,相信平凡人能成就非凡事,相信能遇到更好的自己。如果你希望参与到随着业务腾飞的过程,亲手参与一个有着深入的业务理解、完善的技术体系、技术创造价值、影响力外溢的前端团队的成长历程,我觉得我们该聊聊。任何时间,等着你写点什么,发给ZooTeam@cai-inc.com

