

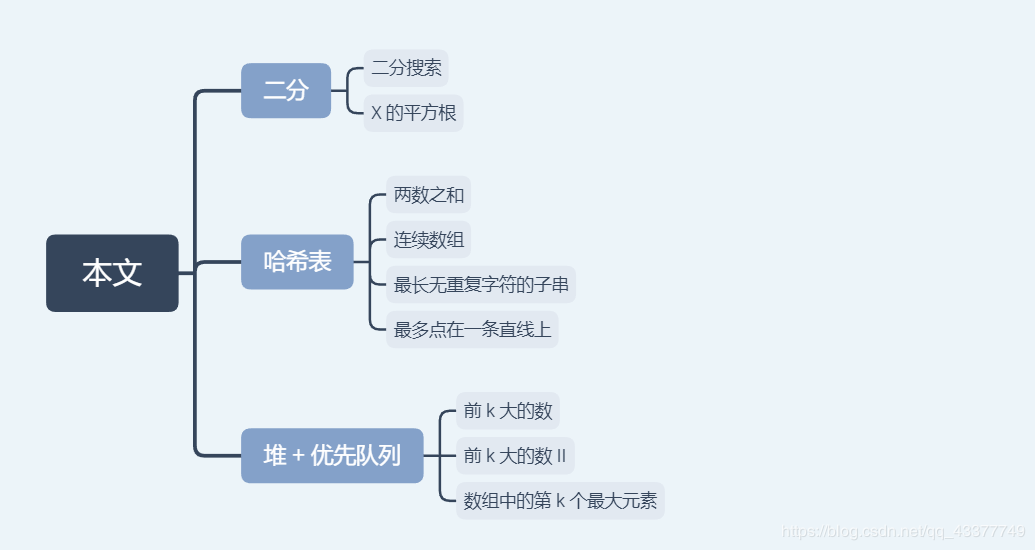
🔥 面试必备:高频算法题汇总「图文解析 + 教学视频 + 范例代码」之 二分 + 哈希表 + 堆 + 优先队列 合集 🔥
本文将覆盖 二分 + 哈希表 + 堆 + 优先队列 方面的面试算法题,文中我将给出:
- 面试中的题目
- 解题的思路
- 特定问题的技巧和注意事项
- 考察的知识点及其概念
- 详细的代码和解析 在开始之前,我们先看下会有哪些重点内容:
为了方便大家跟进学习,我在 GitHub 建立了一个仓库
仓库地址:超级干货!精心归纳视频、归类、总结,各位路过的老铁支持一下!给个 Star !
现在就让我们开始吧!
二分
-
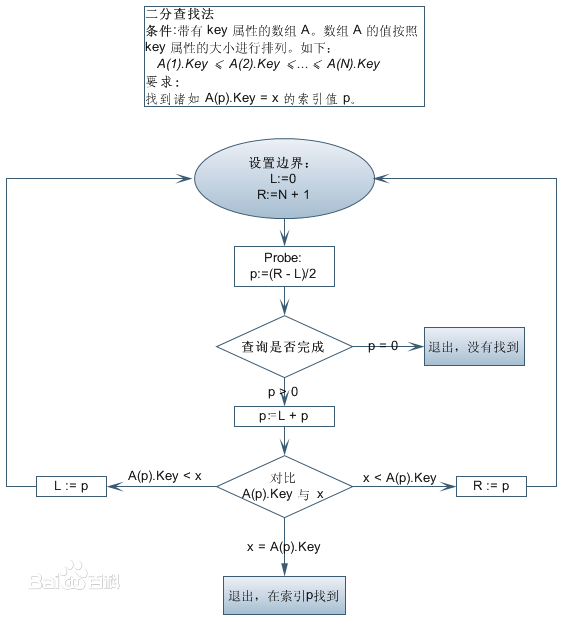
概念: 二分查找也称
折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。 -
基本思路:
- 首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较
- 如果两者相等,则查找成功
- 否则利用中间位置记录将表分成前、后两个子表
- 如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表
- 否则进一步查找后一子表
- 重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
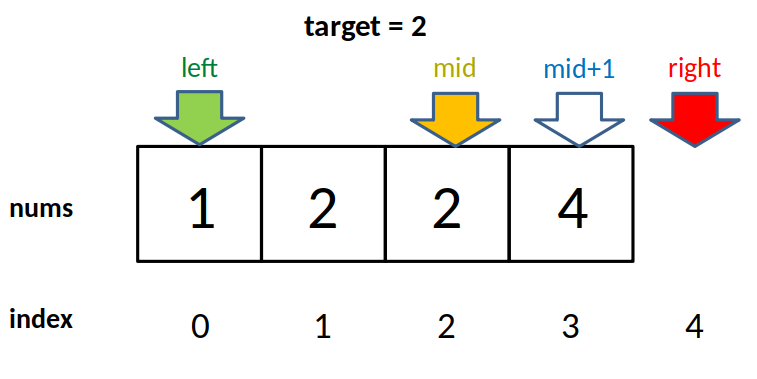
二分搜索
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4
技巧:
分析二分查找的一个技巧是:
- 不要出现 else,而是把所有情况用
if/else if写清楚 - 这样可以清楚地展现所有细节。
这里我们以递归和非递归方式,解决面试中的二分搜索题
递归
思路很简单:
- 判断起始点是否大于终止点
- 比较
nums[mid]与目标值大小 - 如果
nums[mid]大,说明目标值 target 在前面 - 反之如果
nums[mid]小,说明目标值 target 在前面后面 - 如果既不大也不小,说明相等,则返回
当前位置
class Solution {
public int search(int[] nums, int target) {
return binarySearch(nums, 0, nums.length - 1, target);
}
private int binarySearch(int[] nums, int start, int end, int target) {
if(start > end) {
return -1;
}
int mid = (end + start) / 2;
if(nums[mid] < target) {
return binarySearch(nums, mid + 1, end, target);
}
if(nums[mid] > target) {
return binarySearch(nums, start, mid - 1, target);
}
return mid;
}
}
非递归
这个场景是最简单的:
- 搜索一个数
- 如果存在, 返回其索引
- 否则返回 -1
int binarySearch(int[] nums, int target) {
int left = 0;
// 注意减 1
int right = nums.length - 1;
while(left <= right) {
int mid = (right + left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
相关视频
X的平方根
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 2:
输入: 8 输出: 2 说明: 8 的平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
解题思路
使用二分法搜索平方根的思想很简单:
- 就类似于小时候我们看的电视节目中的“猜价格”游戏
- 高了就往低了猜
- 低了就往高了猜
- 范围越来越小。
注:一个数的平方根最多不会超过它的一半,例如 8 的平方根,8 的一半是 4,如果这个数越大越是如此
注意:
对于判断条件:
- 比如说:我们很容易想当然觉得
mid == x / mid和mid * mid == x是等价的,实际却不然- 比如 mid = 2,x = 5
- 对于
mid == x / mid就是:2 == 2 返回 true - 而对于
mid * mid == x就是:4 == 5 返回 false
对于边界条件有个坑:
- 要注意此处耍了一下小技巧,在二分左值和右值相差为1的时候就停止查找;因为在这里,有个对中值取整数的操作,在取整后始终有
start==mid==end则会死循环。
取整操作的误差为1,故而在这里限制条件改成包含1在内的范围start + 1 < end ; 这里减一很精髓
public int sqrt(int x) {
if (x < 0) {
throw new IllegalArgumentException();
} else if (x <= 1) {
return x;
}
int start = 1, end = x;
// 直接对答案可能存在的区间进行二分 => 二分答案
while (start + 1 < end) {
int mid = start + (end - start) / 2;
if (mid == x / mid) {
return mid;
} else if (mid < x / mid) {
start = mid;
} else {
end = mid;
}
}
if (end > x / end) {
return start;
}
return end;
}
哈希表
-
概念 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
-
数据结构 给定表
M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
两数之和
给一个整数数组,找到两个数使得他们的和等于一个给定的数 target。需要实现的函数 twoSum 需要返回这两个数的下标。
示例:
给定
nums = [2, 7, 11, 15], target = 9因为
nums[0] + nums[1] = 2 + 7 = 9所以返回[0, 1]
解题思路
- 用一个
hashmap来记录 key记录target - numbers[i]的值,value记录numbers[i]的i的值- 如果碰到一个
numbers[j]在hashmap中存在 - 那么说明前面的某个
numbers[i]和numbers[j]的和为target - 那么当前的
i和j即为答案
public int[] twoSum(int[] numbers, int target) {
HashMap<Integer,Integer> map = new HashMap<>();
for (int i = 0; i < numbers.length; i++) {
// 判断 map 中是否有需要该值的项
if (map.containsKey(numbers[i])) {
return new int[]{map.get(numbers[i]), i};
}
// 意思可理解为第 i 项,需要 target - numbers[i]
map.put(target - numbers[i], i);
}
return new int[]{};
}
连续数组
给一个二进制数组,找到 0 和 1 数量相等的子数组的最大长度
示例 2:
输入: [0,1,0] 输出: 2 说明: [0, 1] (或 [1, 0]) 是具有相同数量0和1的最长连续子数组。
步骤
-
使用一个数字
sum维护到i为止1的数量与0的数量的差值 -
在
loop i的同时维护sum并将其插入hashmap中 -
对于某一个sum值,若hashmap中已有这个值
-
则当前的
i与sum上一次出现的位置之间的序列0的数量与1的数量相同
public int findMaxLength(int[] nums) {
Map<Integer, Integer> prefix = new HashMap<>();
int sum = 0;
int max = 0;
// 因为在开始时 0 、 1 的数量都为 0 ,所以必须先存 0
// 否则第一次为 0 的时候,<- i - prefix.get(sum) -> 找不到 prefix.get(0)
prefix.put(0, -1);
// 当第一个 0 1 数量相等的情况出现时,数组下标减去-1得到正确的长度
for (int i = 0; i < nums.length; i++) {
int num = nums[i];
if (num == 0) {
sum--;
} else {
sum++;
}
// 判断是否已存在 sum 值
// 存在则说明之前存过
if (prefix.containsKey(sum)) {
// 只做判断,不做存储
max = Math.max(max, i - prefix.get(sum));
} else {
prefix.put(sum, i);
}
}
return max;
}
最长无重复字符的子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
输入: "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
解题思路
用HashMap记录每一个字母出现的位置:
- 设定一个
左边界,到当前枚举到的位置之间的字符串为不含重复字符的子串。 - 若新碰到的字符的上一次的位置在左边界右边, 则需要向右移动左边界。
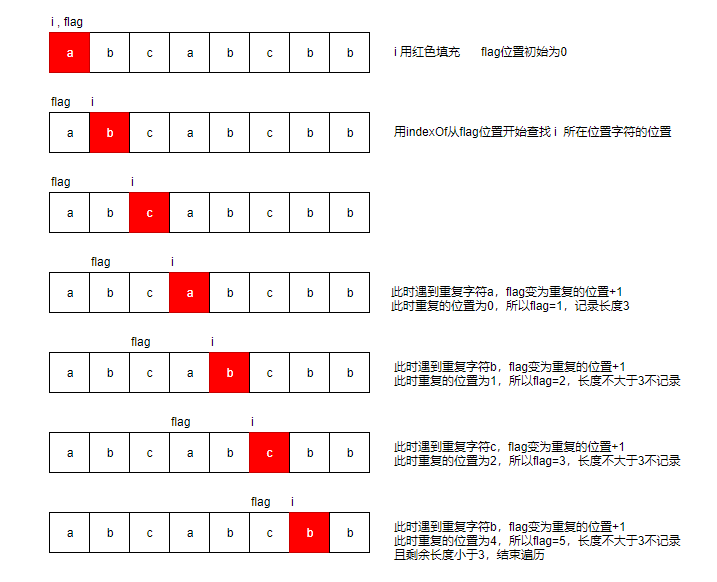
视频
public int lengthOfLongestSubstring(String s) {
if (s == null || s.length() == 0) {
return 0;
}
HashMap<Character, Integer> map = new HashMap<>();
int max = Integer.MIN_VALUE;
// 计算无重复字符子串开始的位置
int start = -1;
int current = 0;
for (int i = 0; i < s.length(); i++) {
if (map.containsKey(s.charAt(i))) {
int tmp = map.get(s.charAt(i));
// 上一次的位置在左边界右边, 则需要向右移动左边界
if (tmp >= start) {
start = tmp;
}
}
map.put(s.charAt(i), i);
max = Math.max(max, i - start);
}
return max;
}
最多点在一条直线上
给出二维平面上的n个点,求最多有多少点在同一条直线上
首先点的定义如下
class Point { int x; int y; Point() { x = 0; y = 0; } Point(int a, int b) { x = a; y = b; } }示例 :
输入: [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]] 输出: 4 解释: ^ | | o | o o | o | o o +-------------------> 0 1 2 3 4 5 6
解题思路
提示:我们会发现,其实只需要考虑当前点之后出现的点i + 1 .. N - 1即可,因为通过点 i-2 的直线已经在搜索点 i-2 的过程中考虑过了。
-
画一条通过点 i 和
之后出现的点的直线,在哈希表中存储这条边并计数为2= 当前这条直线上有两个点。 -
存储时,以斜率来区分线与线之间的关系
-
假设现在
i<i + k<i + l这三个点在同一条直线上,当画出一条通过 i 和 i+l 的直线会发现已经记录过了,因此对更新这条边对应的计数:count++。
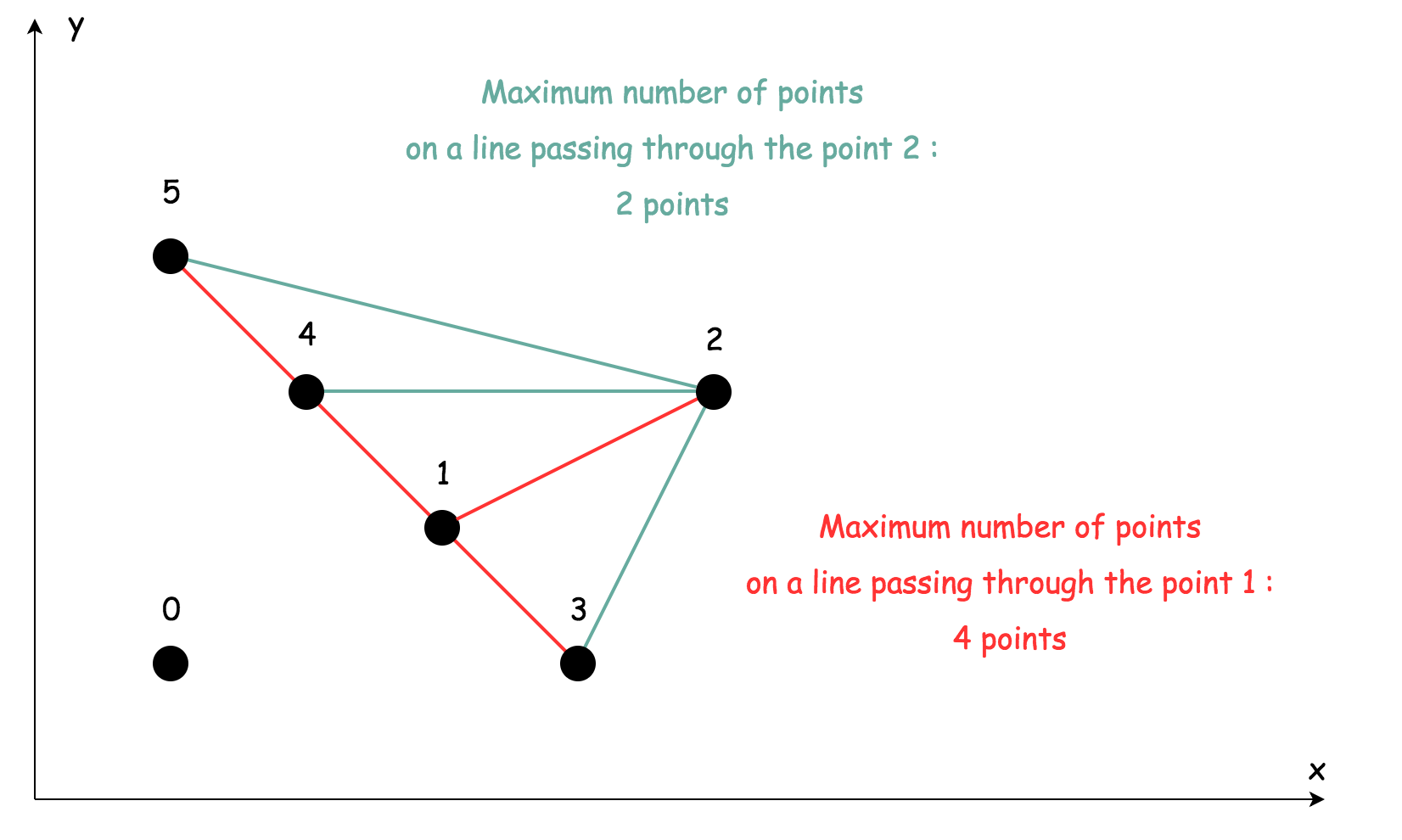
通过 HashMap 记录下两个点之间的斜率相同出现的次数,注意考虑点重合的情况
public int maxPoints(int[][] points) {
if (points == null) {
return 0;
}
int max = 0;
for (int i = 0; i < points.length; i++) {
Map<String, Integer> map = new HashMap<>();
int maxPoints = 0;
int overlap = 0;
for (int j = i + 1; j < points.length; j++) {
int dy = points[i][1] - points[j][1];
int dx = points[i][0] - points[j][0];
// 两个点重合的情况记录下来
if (dy == 0 && dx == 0) {
overlap++;
continue;
}
// 防止 x 相同 y 不同,但 rate 都为 0
// 防止 y 相同 x 不同,但 rate 都为 0
// 以及超大数约等于 0 的情况:[[0,0],[94911151,94911150],[94911152,94911151]]
String rate = "";
if(dy == 0)
rate = "yy";
else if (dx == 0)
rate = "xx";
else
rate = ((dy * 1.0) / dx) + "";
map.put(rate, map.getOrDefault(rate, 0) + 1);
maxPoints = Math.max(maxPoints, map.get(rate));
}
max = Math.max(max, overlap + maxPoints + 1);
}
return max;
}
堆 / 优先队列
- 堆(英语:heap)是计算机科学中一类特殊的数据结构的统称。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
如下图这是一个最大堆,,因为每一个父节点的值都比其子节点要大。10 比 7 和 2 都大。7 比 5 和 1都大。
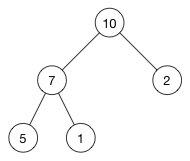
- 优先队列(priority queue) 优先队列是一种抽象数据类型,它是一种排序的机制,它有两个核心操作:找出键值最大(优先级最高)的元素、插入新的元素,效果就是他在维护一个动态的队列。可以收集一些元素,并快速取出键值最大的元素,对其操作后移出队列,然后再收集更多的元素,再处理当前键值最大的元素,如此这般。
- 例如,我们有一台能够运行多个程序的计算机。计算机通过给每个应用一个优先级属性,将应用根据优先级进行排列,计算机总是处理下一个优先级最高的元素。
前K大的数
PriorityQueue 优先队列:Java 的优先队列,保证了每次取最小元素
// 维护一个 PriorityQueue,以返回前K大的数
public int[] topk(int[] nums, int k) {
int[] result = new int[k];
if (nums == null || nums.length < k) {
return result;
}
Queue<Integer> pq = new PriorityQueue<>();
for (int num : nums) {
pq.add(num);
if (pq.size() > k) {
// poll() 方法用于检索或获取和删除队列的第一个元素或队列头部的元素
pq.poll();
}
}
for (int i = k - 1; i >= 0; i--) {
result[i] = pq.poll();
}
return result;
}
前K大的数II
实现一个数据结构,提供下面两个接口:
- add(number) 添加一个元素
- topk() 返回前K大的数
public class Solution {
private int maxSize;
private Queue<Integer> minheap;
public Solution(int k) {
minheap = new PriorityQueue<>();
maxSize = k;
}
public void add(int num) {
if (minheap.size() < maxSize) {
// add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素
// 只是Queue接口规定二者对插入失败时的处理不同
// 前者在插入失败时抛出异常,后则则会返回false
minheap.offer(num);
return;
}
if (num > minheap.peek()) {
minheap.poll();
minheap.offer(num);
}
}
public List<Integer> topk() {
// 将队列中的数存到数组中
Iterator it = minheap.iterator();
List<Integer> result = new ArrayList<Integer>();
while (it.hasNext()) {
result.add((Integer) it.next());
}
// 调用数组排序法后返回
Collections.sort(result, Collections.reverseOrder());
return result;
}
}
数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 输出: 4
我的第一个想法:暴力法
public int findKthLargest(int[] nums, int k) {
Queue<Integer> que = new PriorityQueue<>();
for(int num : nums) {
if(que.size() < k) {
que.offer(num);
} else {
if(que.peek() < num) {
que.poll();
que.offer(num);
}
}
}
return que.peek();
}
这里举个无关的算法:
使用快速排序,思路极其简单:
- 首先对数组进行快速排序
- 最后返回
第 k 个数即可

public int kthLargestElement(int k, int[] nums) {
if (nums == null || nums.length == 0 || k < 1 || k > nums.length){
return -1;
}
return partition(nums, 0, nums.length - 1, nums.length - k);
}
private int partition(int[] nums, int start, int end, int k) {
if (start >= end) {
return nums[k];
}
int left = start, right = end;
int pivot = nums[(start + end) / 2];
while (left <= right) {
while (left <= right && nums[left] < pivot) {
left++;
}
while (left <= right && nums[right] > pivot) {
right--;
}
if (left <= right) {
swap(nums, left, right);
left++;
right--;
}
}
if (k <= right) {
return partition(nums, start, right, k);
}
if (k >= left) {
return partition(nums, left, end, k);
}
return nums[k];
}
private void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
Attention
为了提高文章质量,防止冗长乏味
下一部分算法题
-
本片文章篇幅总结越长。我一直觉得,一片过长的文章,就像一场超长的 会议/课堂,体验很不好,所以打算再开一篇文章来总结其余的考点
-
在后续文章中,我将继续针对
链表栈队列堆动态规划矩阵位运算等近百种,面试高频算法题,及其图文解析 + 教学视频 + 范例代码,进行深入剖析有兴趣可以继续关注 _yuanhao 的编程世界 -
不求快,只求优质,每篇文章将以 2 ~ 3 天的周期进行更新,力求保持高质量输出
相关文章
欢迎关注_yuanhao的掘金!
请点赞!因为你的鼓励是我写作的最大动力!
为了方便大家跟进学习,我在 GitHub 建立了一个仓库
仓库地址:超级干货!精心归纳视频、归类、总结,各位路过的老铁支持一下!给个 Star !
