

Java 8函数式编程
一、简介
1.2 什么是函数式编程
每个人对函数式编程的理解不近相同。但其核心是:在思考问题时,使用不可变值和函数,函数对一个值进行处理,映射成另外一个值。
二、lambda 表达式
匿名函数写法:
button.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent event){
System.out.println("button clicked");
}
}
使用lambda之后:
button.addActionListener(event -> System.out.println("button clicked");
和使用匿名内部类的另一处不同在于声明 event 参数的方式。使用匿名内部类时需要显式地声明参数类型 ActionEvent event,而在 Lambda 表达式中无需指定类型,程序依然可以编译。这是因为 javac 根据程序的上下(addActionListener 方法的签名)在后台推断出了参数 event 的类型。这意味着如果参数类型不言而明,则无需显式指定。
目标类型是指Lambda表达式所在上下文环境的类型。比如,将Lambda表达式赋值给一个局部变量,或转递给一个方法作为参数,局部变量或方法参数的类型就是Lambda表达式的目标类型。
String name = "张三";
// name = "lisi"; //;例 2-7 不能多次对name赋值,如果多次对name赋值,这 在lambda中引用name变量这会报错
Button btn = new Button();
btn.addActionListener(event -> System.out.println(name));
表2-1 Java中重要的函数接口
| 接口 | 参数 | 返回类型 | 示例 |
|---|---|---|---|
| Predicate | T | boolean | 这张唱片已经发行了吗 |
| Consumer | T | void | 输出一个值 |
| Function<T,R> | T | R | 获得Artist对象的名字 |
| Supplier | None | T | 工厂方法 |
| UnaryOperator | T | T | 逻辑非 |
| BinaryOperator | (T,T) | T | 求两个数的乘积(*) |
** 重要问题**
- ThreadLocal Lambda 表达式。Java 有一个 ThreadLocal 类,作为容器保存了当前线程里 局部变量的值。Java 8 为该类新加了一个工厂方法,接受一个 Lambda 表达式,并产生 一个新的 ThreadLocal 对象,而不用使用继承,语法上更加简洁。 a. 在 Javadoc 或集成开发环境(IDE)里找出该方法。 b. DateFormatter 类是非线程安全的。使用构造函数创建一个线程安全的 DateFormatter 对象,并输出日期,如“01-Jan-1970”。
三、流
建造者模式 使用一系列操作设置属性和配置,最后调用一个build方法,这时,对象才真正创建。
3.1 从外部迭代 到内部迭代
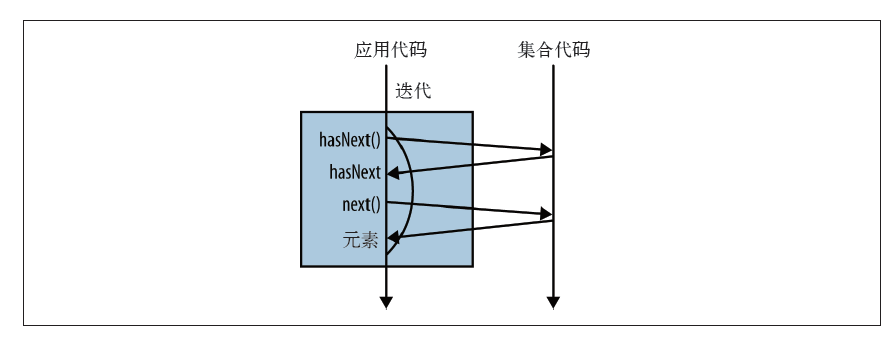
其实在我们平常写的代码中 ,ForEach循环遍历 其实是一个 外部迭代。
for循环其实是一个封装了迭代的语法糖。
工作原理:
首先调用iterator方法,产生一个新的Iterator对象,进而控制整个迭代过程,这就是 外部迭代
例 3-2 使用迭代计算来自伦敦的艺术家人数。
int count = 0;
Iterator<Artist> iterator = allArtists.iterator();
while(iterator.hasNext()) {
Artist artist = iterator.next();
if (artist.isFrom("London")) {
count++;
}
}
内部迭代
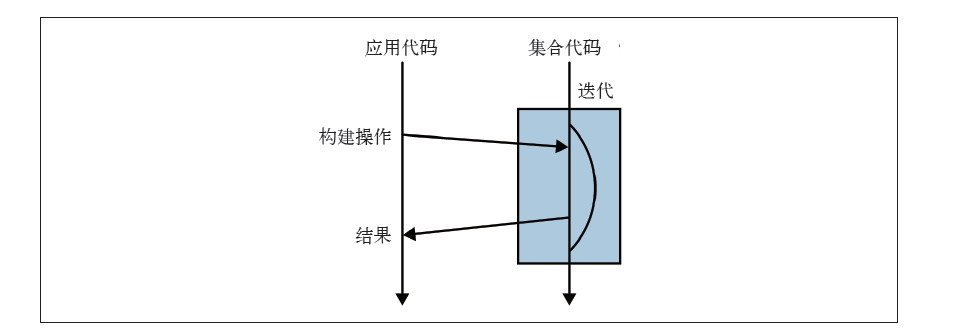
例 3-3 使用内部迭代计算来自伦敦的艺术家人数
logn count = allArtists.stream().filter(artist -> artist.isFrom("London")).count();
3.2 实现机制
例3-3 中,整个过程被分解为两种更简单的操作:过滤和计数,看似有化简为繁之嫌—— 例3-1 中只含一个for 循环,两种操作是否意味着需要两次循环?事实上,类库设计精妙, 只需对艺术家列表迭代一次。
例 3-4 只过滤,不计数
allArtists.stream().filter(artist -> artist.isFrom("London"));
这行代码并未做什么实际性的工作,filter只刻画出了Stream,但没有产生新的集合。 像filter这样只描述Stream,最终不产生新集合的方法 叫做 惰性求值方法;而像count这样最终会从Stream产生值的方法叫做及早求值方法
整个过程和建造者模式有共通之处。建造者模式使用一系列操作设置属性和配置,最后调用一个build方法,这时,对象才被真正创建。
3.3 常用的流操作
3.3.1 collect(toList())
collect(toList()) 方法 由Stream里的值生成一个列表,是一个及早求值操作。
List<String> collected = Stream.of("a", "b", "c") .collect(Collectors.toList());
Stream的of方法使用一组初始值生成新的stream。
四、类
4.3 重载解析
总而言之,Lambda表达式作为参数时,其类型由它的目标类型推导得出,推导过程遵循如下规则: 1.如果只有一个可能的目标类型,由相应函数接口里的参数类型推导得出。 2.如果有多个可能的目标类型,由最具体的类型推导得出。 3.如果有多个可能的目标类型且最具体的类型不明确,则需人为制定类型。
4.4 @FunctionalInterface
和Closeable 和 Comparable 接口不同。为了提高Stream对象可操作性而引入的各种新接口,都需要有Lambda表达式可以实现它。它们存在的意义在于讲代码块作为数据打包起来。因此,它们都添加了@FunctionInterface注释。
4.7
三定律
如果对默认方法的工作原理,特别是在多重继承(类实现多个接口)下的行为还没有把握,如下三条简单的定律可以帮助大家:
1.类胜于接口。如果在继承链中有方法体或抽象的方法说明,那么就可以忽略接口中定义的方法。
2.子类胜于父类。如果一个接口继承了另一个接口,且两个接口都定义了一个默认方法。那么子类中定义的方法胜出。
3.没有规则三。如果上面两条规则不适用,子类那么需要实现该方法,要么将方法声明为抽象方法。
其中第一条规则是为了让代码向后兼容。
4.9 接口的静态方法
Stream是个接口。Stream.of是接口的静态方法。这也是Java 8中添加的一个新的语言特性,旨在帮助编写类库的开发人员,但对于日常应用程序的开发人员也同样适用。
Stream和其他几个子类还包含另外几个静态方法。特别是range和iterate方法提高了产生Stream的其他方式。
4.10 Optional
reduce方法的一个重点尚未提及:reduce方法有两种形式,一种如前边出现的需要有一个初始值,另一种变式则不需要有初始值。在没有初始值的情况下,reduce的第一步使用Stream中前两个元素。有时,reduce操作不存在有意思的初始值,这样做就是有意义的。此时,reduce方法返回一个Optional对象。
Optional是为核心类库新设计的一个数据类型,用来替换null值。 开发人员常常使用null值表示值不存在,optional对象能更好的表达这个概念。使用null代表值不存在的最大问题在于NullPointerException。 一旦引用一个存储null值得变量,程序会立即崩溃。
使用Optional对象有两个目的:首先,Optional对象鼓励程序员适时检查变量是否为空,以避免代码缺陷;其次,它将一个类的API中可能为空的值文档化,这比阅读实现代码简单的多。
Optional的常用方法
of 和ofNullable
of和ofNullable是用于创建Optional对象的,of不能创建null对象,而ofNullable可以。
Optional<String> str = Optional.of("sss");
//of参数为空,抛nullPointException
//Optional<String> str1 = Optional.of(null);
//ofNullable,参数可以为空,为空则返回值为空
Optional<String> str1 = Optional.ofNullable(null);
isPresent和get
isPresent是用来判断对象是否为空,get获得该对象
if (str.isPresent()) {
System.out.println(str.get());
}
if (str1.isPresent()) {
System.out.println(str1.get());
}
orElse和orElseGet
orElse和orElseGet使用实现党Optional为空时,给对象赋值。orElse参数为赋值对象,orElseGet为Supplier函数接口。
//orElse
System.out.println(str.orElse("There is no value present!"));
System.out.println(str1.orElse("There is no value present!"));
//orElseGet,设置默认值
System.out.println(str.orElseGet(() -> "default value"));
System.out.println(str1.orElseGet(() -> "default value"));
orElseThrow
orElseThrow时当存在null时,抛出异常
try {
//orElseThrow
str1.orElseThrow(Exception::new);
} catch (Throwable ex) {
//输出: No value present in the Optional instance
System.out.println(ex.getMessage());
}
五、高级集合类和收集器
5.1 方法引用
Lambda表达式有一个常见的用法:Lambda表达式经常调用参数。比如想得到艺术家的姓名: Lambda表达式如下; artist -> artist.getName() 这种用法如此普遍。Java8为其提供了一个简写语法,叫做方法引用,帮助程序员重用已有方法。用方法引用重写上边面的Lambda表达式,代码如下: Artist::getName 标准语法为:Classname::methodName。 注意:方法名后边不需要添加括号
构造函数也有同样的缩写形式,如果你想使用Lambda表达式创建一个Person对象,可能如下代码
(name,age) -> new Person(name,age)
使用方法引用,上面代码可写为:
Person::new
也可以用这种方式来创建数组 String[]::new
5.2 元素顺序
5.3 收集器
5.3.1 转换成其他集合
可以转换成toList(),toSet() 等等。
例5-5 使用toCollection,用定制的集合收集元素
stream.collect(toCollection(TreeSet::new));
5.3.2 转换成值
例5-6 找出成员最多的乐队
public Optional<Artist> biggestGroup(Stream<Artist> artists){
Function<Artist,Long> getCount = artist -> artist.getMembers().count();
return artists.collect(Collectors.maxBy(comparing(getCount)));
}
minBy ,是用来找出最小值的。
例 5-7 找出一组专辑上曲目的平均数
public double averageNumberOfTracks(List<Album> albums){
return albums.stream().collect(Collectors.averagingInt(album -> album.getTrackList().size()));
}
第4章 介绍过一些特殊的流,如IntStream,为数值定义了一些额外的方法。事实上,Java 8 也提供了能完成类似功能的收集器。如:averageingInt。可以使用summingInt及其重载方法求和。SummaryStatistics也可以使用summingInt及其组合手机。
5.3.3 数据分块
收集器partitioningBy,它接受一个流,并将其分成两部分(如图所示)。它使用Predicate对象判断一个元素应该属于哪个部分,并根据布尔值翻一个Map到列表。因此,对于true List中的元素,Predicate返回true;对于其他List中的元素,Predicate返回false。
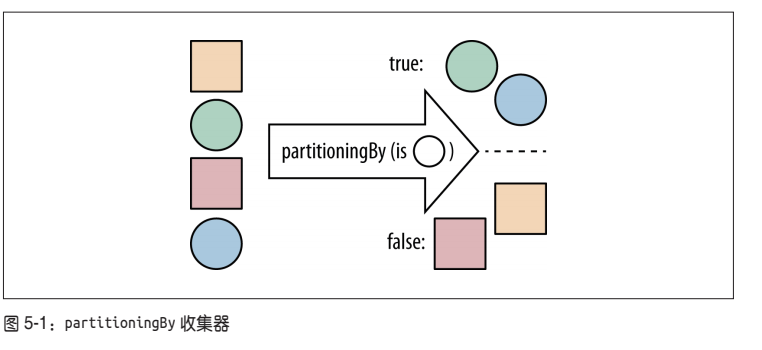
例 5-8 将艺术家组成的流分成乐队和独唱歌手两部分
public Map<Boolean, List<Artist>> bandsAndSolo(Stream<Artist> artists) {
return artists.collect(partitioningBy(artist -> artist.isSolo()));
}
** 5-9 使用方法引用将艺术家组成的 Stream 分成乐队和独唱歌手两部分 **
public Map<Boolean, List<Artist>> bandsAndSoloRef(Stream<Artist> artists) {
return artists.collect(partitioningBy(Artist::isSolo));
}
可以理解成 Oracle分析函数中 partition by
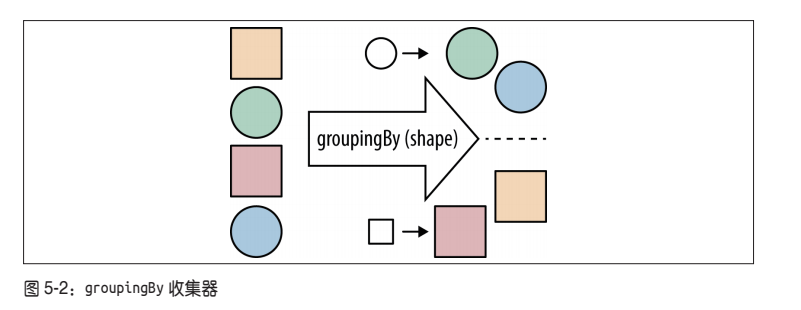
5.3.4 数据分组
数据分组是一种更自然的分割数据操作,与将数据分成 ture 和 false 两部分不同,可以使用任意值对数据分组。比如现在有一个由专辑组成的流,可以按专辑当中的主唱对专辑分组。
例 5-10 使用主唱对专辑分组
public Map<Artist, List<Album>> albumsByArtist(Stream<Album> albums) {
return albums.collect(groupingBy(album -> album.getMainMusician()));
}
groupingBy 收集器(如图5-2 所示)接受一个分类函数,用来对数据分组,就像 partitioningBy 一样,接受一个Predicate 对象将数据分成 ture 和 false 两部分。我们使用的分类器是一个Function 对象,和 map 操作用到的一样。
5.3.5 字符串
例 5-12 使用流和收集器格式化艺术家姓名
String result = artists.stream().map(Artist::getName).collect(Collectors.join(",","[","]"));
这里使用map操作提取艺术家的姓名,然后使用Collectors.joining收集流中的值,该方法可以方便地从一个流得到一个字符串,允许用户提供分隔符(用以分隔元素)、前缀和后缀。
5.3.6 组合收集器
现在来考虑如何计算一个艺术家的专辑数量。
一个简单的方案是使用前面的方法对专辑先分组后计数
例 5-13 计算每个艺术家专辑数的简单方式
Map<Artist,List<Album>> albumsByArtist = albums.collect(groupingBy(album -> album.getMainMusician()));
Map<Artist, Integer> numberOfAlbums = new HashMap<>();
for(Entry<Artist, List<Album>> entry : albumsByArtist.entrySet()) {
numberOfAlbums.put(entry.getKey(), entry.getValue().size());
}
这种方式看起来简单,但却有点杂乱无章。这段代码也是命令式的代码,不能自动适应并行化操作。
这里实际上需要另外一个收集器,告诉groupingBy不用为每个艺术家生成一个专辑列表,只需要对专辑技术就可以了。 核心类库已经提供了一个这样的收集器:counting。
例 5-14 使用收集器计算每个艺术家的专辑数
public Map<Artist,Long> numberOfAlbums(Stream<Album> albums){
return albums.collect(Collectors.groupingBy(album -> album.getMainMusician(),counting()));
}
groupingBy 先将元素分成块,每块都与分类函数getMainMusician提供的键值想关联。然后使用下游的另一个收集器手机每块中的元素,最好将结果映射为一个Map。
例 5-15 使用简单方式求每个艺术家的专辑名
public Map<Artist, List<String>> nameOfAlbumsDumb(Stream<Album> albums) {
Map<Artist, List<Album>> albumsByArtist =
albums.collect(groupingBy(album ->album.getMainMusician()));
Map<Artist, List<String>> nameOfAlbums = new HashMap<>();
for(Entry<Artist, List<Album>> entry : albumsByArtist.entrySet()) {
nameOfAlbums.put(entry.getKey(), entry.getValue()
.stream()
.map(Album::getName)
.collect(toList()));
}
return nameOfAlbums;
}
例 5-16 使用收集器求每个艺术家的专辑名
public Map<Artist, List<String>> nameOfAlbums(Stream<Album> albums) {
return albums.collect(groupingBy(Album::getMainMusician,
mapping(Album::getName, toList())));
}
这两个例子中我们都用到了第二个收集器,用以收集最终结果的一个子集,这些收集器叫做 下游收集器。收集器是生成最终结果的一剂配方,下游收集器则是生成部分结果的配方,主收集器中会用到下游收集器。这种组合使用收集器的方式,使得他们在Stream类库中的作用更加强大。
六、数据并行化
6.1 并行和并发
并发是两个任务共享时间段,并行则是两个任务在同一个时间发生,比如运行在多核CPU上。如果一个程序要运行两个任务,并且只有一个CPU给他们分配了不同的时间片,那么这是并发,不是并行。 两者区别如图:
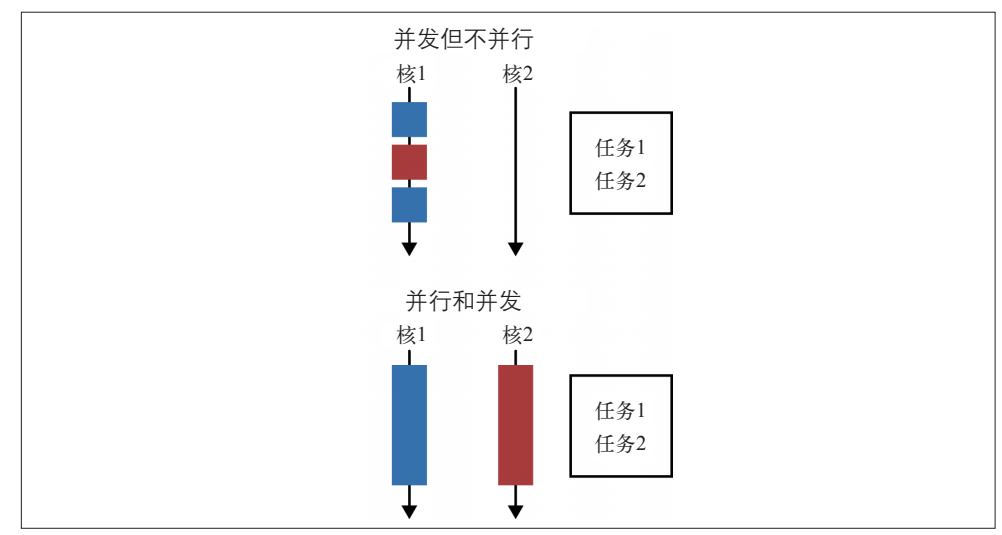
数据并行化:数据并行化是将数据分成块,为每块数据分配单独的处理单元。 当需要在大量数据上执行同样的操作时,数据并行化很管用,它将问题分解为可在多块数据上求解的形式,然后对每块数据执行运算,最后将各数据块上得到的结果汇总,从而得到最终结果。
阿姆达尔定律是一个简单规则,预测了搭载多核处理器的机器提升程序速度的理论最大值。
6.3 并行化流操作
以下方法可以获得一个拥有并行能力的流。
1.parallel() :Stream对象调用。 2.parallelStream() :集合对象调用,创建一个并行能力的流。
问题:并行化运行基于流的代码是否比串行化运行更快?
6.4 模拟系统
讨论***蒙特卡洛模拟法***。蒙特卡洛模拟法会重复相同的模拟很多次,每次模拟都使用随机生成的种子。每次模拟的结果都被记录下来,汇总得到一个对系统的全面模拟。蒙特卡洛模拟法被大量用在工程、金融和科学计算领域。
详细 请看代码。
6.5 限制
使用reduce限制1 恒等值
之前调用reduce方法,初始值可以为任意值,为了让其在并行化时能正常工作,初始值必须为组合函数的***恒等值*** 。拿恒等值和其他值做reduce操作时,其他值保持不变。 *eg:*使用reduce操作求和,组合函数(acc,element) -> acc + element,则其初始值必须为0。
使用reduce限制2 结合律。
reduce 操作的另一个限制是组合操作必须符合结合律。这意味着只要序列的值不变,组合操作的顺序不重要。
注意API中 :
prallel() :并行流
sequential() :串行流。
如果同时调用这两个方法,最后调用的起效。默认是串行的。
6.6 性能
影响并行流性能的主要因素有5个,如下:
① 数据大小
输入数据的大小会影响并行化处理对性能的提升。将问题分解之后并行化处理,再将结果合并会带来额外的开销。因此只有数据足够大,每个数据处理管道花费的时间足够多时,并行化处理才有意义。
② 源数据结构
每个管道的操作都基于一些初始数据源,通常是集合。将不同的数据源分隔相对容易,这里的开销硬性了在管道中并行处理数据时到底带来多少性能上的提升。
③ 装箱
处理基本类型比处理装箱类型要快。
④ 核的数量
极端情况下,只有一个核,因此完全没必要并行化。显然,拥有的核越多,获得潜在性能提升的幅度就越大。在实践中,核的数量不单指你的机器上有多少核,更是指运行时你的机器能使用多少核。这也就是说同时运行的其他进程,或者线程关联性(强制线程在某些核或 CPU 上运行)会影响性能。
⑤ 单元处理开销
必须数据大小,这是一场并行执行花费时间和分解合并操作开销之间的战争。花在流中每个元素身上的时间越长,并行操作带来的性能提升越明现。
来看一个具体的问题,看看如何分解和合并它。
例 6-6 并行求和
private int addIntegers(List<Integer> values){
return values.parallelStream().mapToInt(i -> i).sum();
}
在底层,并行流还是沿用了 fork/join 框架。fork 递归式地分解问题,然后每段并行执行,最终由 join 合并结果,返回最后的值。
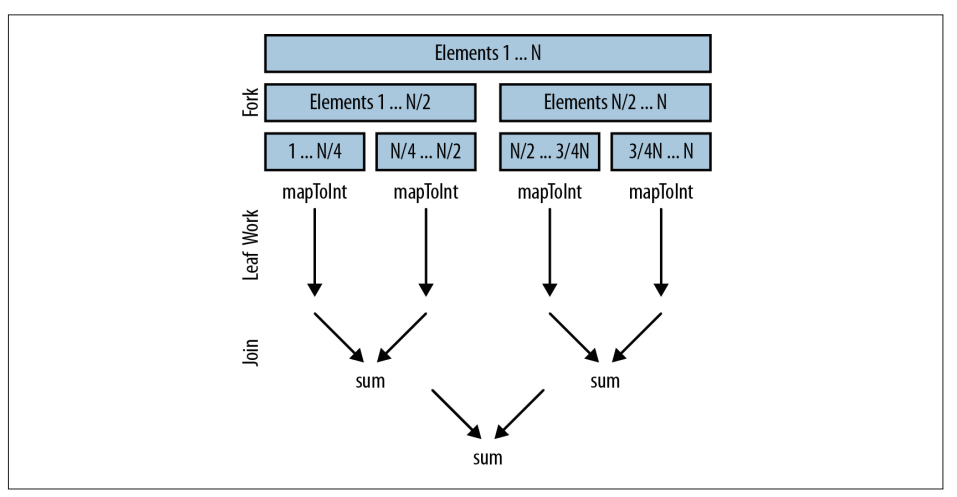
假设并行流将我们的工作分解开,在一个四核的机器上并行执行。
1.数据被分成四块
2.如6-6所示,计算工作在每个线程里并行执行。这包括将每个Integer对象映射为int值,然后在每个线程里将1/4的数字相加。理想情况下,我们希望在这里花的时间越多越好,因为这里是并行操作的最佳场合
3.然后合并结果。在例6-6中,就是sum操作,但这也可能是reduce、collect或其他终结操作。
数据结构对性能的影响:
性能好
ArrayList、数组或IntStream.range,这些数据结构支持随机读取,也就是它们能轻而易举的被任意分解。
性能一般
hashSet、TreeSet这些数据结构不易公平的被分解,但是大多时候是可能的。
性能差
有些数据结构难于分解。比如,可能要花O(N)的时间复杂度来分解问题。其中包括LinkedList,对半分解太难了。还有Streams.iterate和BufferedReader.lines。它们长度未知。因此很难预测改在哪里分解。
