

现在更新文章的速度越来越慢了......😄,就是太懒了......
前言:
因为最近项目正好涉及到音乐播放器的音频缓存,当然我们要做的第一步当然是百度或者谷歌常用的缓存库,起码我是不愿意自己写的,多麻烦!!! 百度以后:
出来的结果都是关于这个库的,恩,那就直接用这个库了: AndroidVideoCache
当然我们虽然不去自己写,简单使用,但是我们还是要懂原理,这个可不能偷懒,而且看了源码也方便我们自己去针对性定制化。
我们先来看简单的使用:
//'一般我们会在Application里面初始化,
主要的目的是为了通过单例模式使用HttpProxyCacheServer:'
public class App extends Application {
private HttpProxyCacheServer proxy;
public static HttpProxyCacheServer getProxy(Context context) {
App app = (App) context.getApplicationContext();
return app.proxy == null ? (app.proxy = app.newProxy()) : app.proxy;
}
private HttpProxyCacheServer newProxy() {
//'我们实例化HttpProxyCacheServer的对象'
return new HttpProxyCacheServer(this);
}
}
//'然后业务代码中使用,把原始的url传入,获得到经过代理的url'
HttpProxyCacheServer proxy = getProxy();
String proxyUrl = proxy.getProxyUrl(url);
//'把代理url给你的代码使用:'
//比如给exoplayer使用
MediaSource mediaSource = buildMediaSource(Uri.parse(proxyUrl));
mExoPlayer.prepare(mediaSource);
//比如给videoView使用
videoView.setVideoPath(proxyUrl);
没错,就是这么简单,你只要传的url每次都是一样的,就可以直接去获取本地缓存文件,然后去播放,不需要再去浪费流量请求了。
需要定制化的地方:
但是我们可以看到我们只传入了一个url,说明内部是把url作为Key去获取对应的内容的。一般的歌曲都没问题,比如你要播放XXX歌,获取你们公司的服务器的某个内容,url一般不会改变,但是我们公司和和其他公司音乐CP方合作,所以获取具体的音乐的url每次获取都会改变,就是同一首歌,相隔一秒请求,请求的播放歌曲的url也会改变,比如http://歌曲id号/23213213213123/xxxx.mp3,比如中间的数字是根据请求的时间的时间戳拼接返回的,所以每次都会不同,这时候你直接使用这个库,就会出问题,你会发现缓存没有任何软用。
所以针对这种情况:
- 比较完美的就是根据歌曲id作为key去拿本地缓存会更好,因为一个歌曲的id是一定不会变的。
- 我们也可以本地缓存文件的文件名是通过前面url的中间不会变的那段去命名( 比如只取这一段:
http://歌曲id号),这样去比较本地是否有缓存文件的时候,就不会有问题了。
不管用哪种,我们都可以借机去了解源码。
正文:
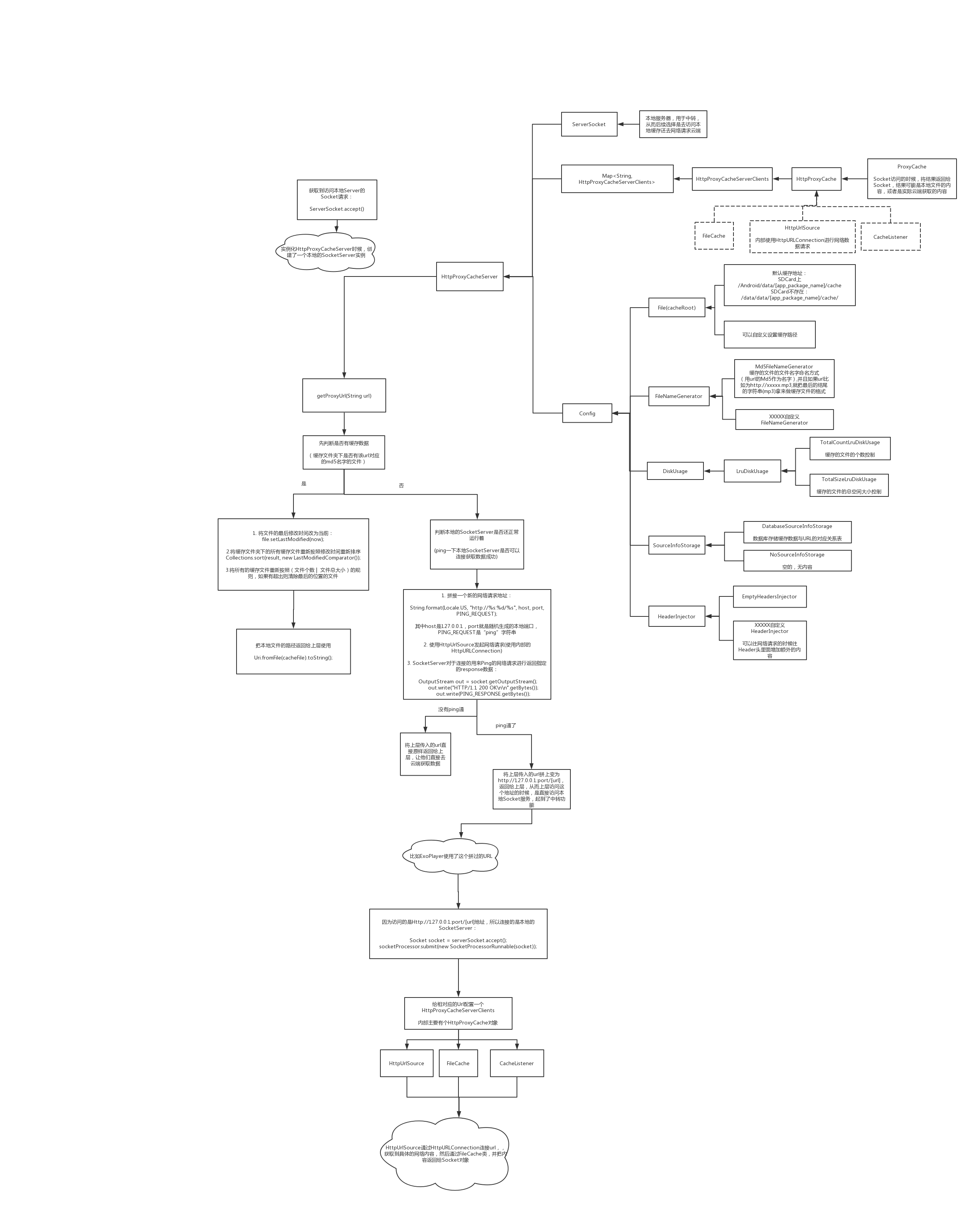
1. 初步使用HttpProxyCacheServer分析
1.1 HttpProxyCacheServer实例化对象:
我们看到了我们要使用这个库,其实就是实例化这个HttpProxyCacheServer类,然后使用它的getProxyUrl方法获取代理url即可。
那我们就知道了这个是代理总的管理类了。我们看下实例化它对象的时候,内部有什么:
public HttpProxyCacheServer(Context context) {
//'默认使用特定的Config配置'
this(new Builder(context).buildConfig());
}
private HttpProxyCacheServer(Config config) {
//'Config配置'
this.config = checkNotNull(config);
try {
//'创建了本地的ServerSocket,作为中转作用'
InetAddress inetAddress = InetAddress.getByName(PROXY_HOST);
this.serverSocket = new ServerSocket(0, 8, inetAddress);
this.port = serverSocket.getLocalPort();
//'创建代理选择器,从而如果是其他网络请求,继续经过原来的代理,如果是自己设置的ServerSocker,则不经过代理'
IgnoreHostProxySelector.install(PROXY_HOST, port);
CountDownLatch startSignal = new CountDownLatch(1);
//'启动了本地的ServerSocket,开启接受外部访问的Socket'
this.waitConnectionThread = new Thread(new WaitRequestsRunnable(startSignal));
this.waitConnectionThread.start();
startSignal.await(); // freeze thread, wait for server starts
//'自定义的Pinger类主要用来等会模拟访问本地ServerSocket请求,确保请求网络没问题'
this.pinger = new Pinger(PROXY_HOST, port);
LOG.info("Proxy cache server started. Is it alive? " + isAlive());
} catch (IOException | InterruptedException e) {
socketProcessor.shutdown();
throw new IllegalStateException("Error starting local proxy server", e);
}
}

题外话开始!!:
很多人和可能对于ServerSocket , ProxySelector等都比较迷糊,因为很多人网络请求直接使用了Okhttp等直接封装好的东西,所以对于Socket,Proxy/ProxySelector等反而比较模糊。
对于网络基础可以看我以前写的文章:
Android技能树 — 网络小结(3)之HTTP/HTTPS
Android技能树 — 网络小结(4)之socket/websocket/webservice
相关网络知识点小结- cookie/session/token(待写)
Android技能树 — 网络小结(6)之 OkHttp超超超超超超超详细解析
Android技能树 — 网络小结(7)之 Retrofit源码详细解析
当前简单的想知道 Socket和ServerSocket和二者的使用,也可以看下面这篇:
其中代理相关的Proxy和ProxySelector,可以看下面这篇:
代理服务器:Proxy(代理连接)、ProxySelector(自动代理选择器)、默认代理选择器
题外话结束!!

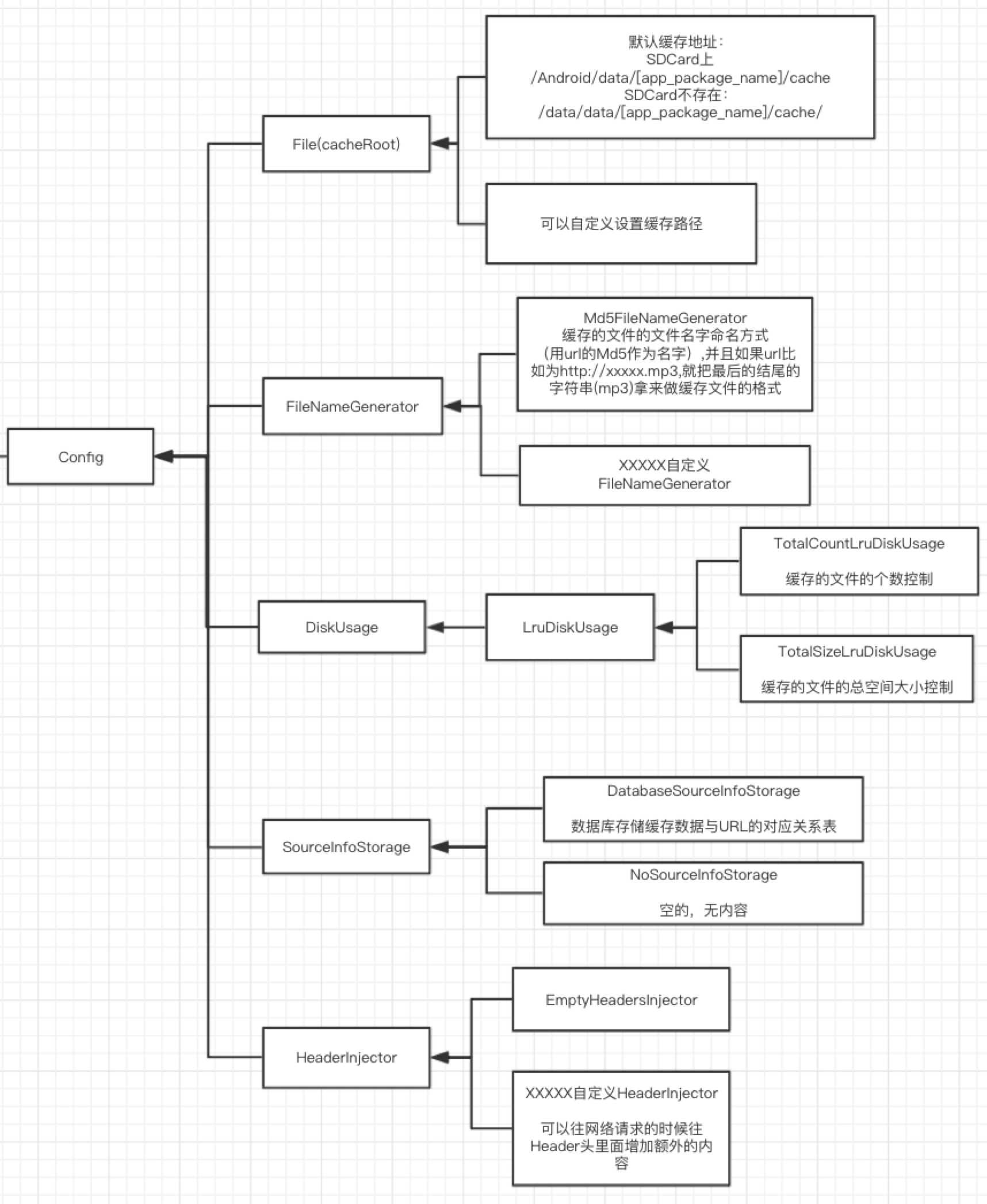
我们来看下Config都包含了什么:
class Config {
//缓存文件的目录
public final File cacheRoot;
//缓存文件的命名
public final FileNameGenerator fileNameGenerator;
//磁盘使用统计类(比如设置的缓存文件数还是缓存文件空间)
public final DiskUsage diskUsage;
//存了资源的相关信息:url/length/mime
public final SourceInfoStorage sourceInfoStorage;
//网络请求,可以插入Header信息
public final HeaderInjector headerInjector;
......
......
......
}
1.2 调用getProxyUrl方法
我们看了实例化对象,接下去就是通过调用getProxyUrl获取代理url了,我们看下具体做了什么事。
public String getProxyUrl(String url) {
return getProxyUrl(url, true);
}
public String getProxyUrl(String url, boolean allowCachedFileUri) {
//'Boolean参数是否允许缓存 && isCached判断传入的url是否已经有缓存了'
if (allowCachedFileUri && isCached(url)) {
//'获取缓存文件'
File cacheFile = getCacheFile(url);
//'因为取了这个缓存文件,所以把这个缓存文件的修改时间改为当前时间,'
//'同时对所有的缓存文件重新根据修改时间进行排序'
touchFileSafely(cacheFile);
//'把本地文件的url返回给上层使用'
return Uri.fromFile(cacheFile).toString();
}
//'isAlive()的作用是创建http://127.0.0.1:port/ping 网络请求,判断本地的ServerSocket是否还能连接访问,
//如果可以连接,就把传进来的url变为代理服务器ServerSokcet的url (http://127.0.0.1:port/[url]),
//如果本地ServerSocket已经挂了,就直接把原来的url返回给上层'
return isAlive() ? appendToProxyUrl(url) : url;
}
这里要注意一个小细节,就是
appendToProxyUrl里面不是单纯的把我们实际的url拼接在http://127.0.0.1:port后面。比如我们的实际url是http://xxxxxx.mp3,不是拼接成:http://127.0.0.1:port/http://xxxxx.mp3,这样一看这个网址就是有问题的。而是把我们的实际url先通过utf-8转移成其他字符:URLEncoder.encode(url, "utf-8");然后拼接上去,最后结果为:http://127.0.0.1:50544/http%3A%2F%2Fxxxxxx.mp3。要使用实际url的时候,拿出来再反过来解析就行:URLDecoder.decode(url, "utf-8");
那我们肯定着重看下第二种情况,也就是本地没有缓冲,你这个url是第一次传进来的时候的情况。
2. 访问HttpProxyCacheServer.getProxyUrl返回到额Url
我们上面已经通过getProxyUrl获取到了新的并且过的url: http://127.0.0.1:port/[实际访问的url],
这时候我们用ExoPlayer 或者VideoView等去访问这个网址的时候,变成了访问本地服务器ServerSocket了(本地ServerSocket就是创建的127.0.0.1)。
我们来详细看ServerSocket接受请求的相关代码:
private void waitForRequest() {
try {
while (!Thread.currentThread().isInterrupted()) {
//'我们拿到的proxyUrl访问后,ServerSocket接受到了我们的请求Socket'
Socket socket = serverSocket.accept();
//'我们可以看到拿着我们的请求Socket去执行Runnable'
socketProcessor.submit(new SocketProcessorRunnable(socket));
}
} catch (IOException e) {
onError(new ProxyCacheException("Error during waiting connection", e));
}
}
我们来看这个Runaable做了什么:
private final class SocketProcessorRunnable implements Runnable {
private final Socket socket;
public SocketProcessorRunnable(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
//'这个Runnable执行了下面的processSocket方法'
processSocket(socket);
}
}
private void processSocket(Socket socket) {
try {
//'获取我们的Socket的InputStream,然后传入获取GetRequest对象'
GetRequest request = GetRequest.read(socket.getInputStream());
//'获取到我们的Socket请求的url: http://127.0.0.1:port/[实际访问的url]'
String url = ProxyCacheUtils.decode(request.uri);
//'这个url是否是用来ping的请求地址
(是否记得我们前面isAlive()方法,ping一下本地ServerSocket,看是否存活)'
if (pinger.isPingRequest(url)) {
//'如果只是简单的ping的请求,就简单的处理回复'
pinger.responseToPing(socket);
} else {
//'进入这里,说明这个url是http://127.0.0.1:port/[实际访问的url],
我们根据url来获取HttpProxyCacheServerClients对象,然后执行接下去的步骤'
HttpProxyCacheServerClients clients = getClients(url);
clients.processRequest(request, socket);
}
} catch (SocketException e) {
......
......
} catch (ProxyCacheException | IOException e) {
......
......
} finally {
//'释放我们的请求Socket'
releaseSocket(socket);
}
}
我们分步来看上面的操作后,肯定有这些疑问:
- 获取GetRequest对象,这个对象的作用是什么??
- 根据传入的url获取HttpProxyCacheServerClients对象,这个对象的作用是什么???
在分析接下去流程之前,我们先来看看这二个类是做什么的。
2.1 GetRequest对象:
'假设实际的网络请求是 http://xxxxxx.mp3
代理后的是http://127.0.0.1:50544/http%3A%2F%2Fxxxxxx.mp3'
//'类的代码很少,其实就是我们的Socket请求本地ServerSocket的时候,
//获取到的请求Socket的InputStream中可以读取到以下的请求内容():
GET /http%3A%2F%2Fxxxxxx.mp3 HTTP/1.1
(PS:前面我们还记得alive()方法来进行ping的时候,那么这里的就会是GET /ping HTTP/1.1)
User-Agent: Dalvik/2.1.0 (Linux; U; Android 6.0.1; MuMu Build/V417IR)
Host: 127.0.0.1:50276
Connection: Keep-Alive
Accept-Encoding: gzip
(Range: bytes=0-10 如果网络请求有range,这里就会有该内容,比如分段下载时候,参考:https://www.cnblogs.com/1995hxt/p/5692050.html)
'
class GetRequest {
private static final Pattern RANGE_HEADER_PATTERN = Pattern.compile("[R,r]ange:[ ]?bytes=(\\d*)-");
private static final Pattern URL_PATTERN = Pattern.compile("GET /(.*) HTTP");
public final String uri;
public final long rangeOffset;
public final boolean partial;
public GetRequest(String request) {
checkNotNull(request);
long offset = findRangeOffset(request);
this.rangeOffset = Math.max(0, offset);
this.partial = offset >= 0;
this.uri = findUri(request);
}
public static GetRequest read(InputStream inputStream) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, "UTF-8"));
StringBuilder stringRequest = new StringBuilder();
String line;
while (!TextUtils.isEmpty(line = reader.readLine())) { // until new line (headers ending)
stringRequest.append(line).append('\n');
}
return new GetRequest(stringRequest.toString());
}
private long findRangeOffset(String request) {
//'获取range值'
Matcher matcher = RANGE_HEADER_PATTERN.matcher(request);
if (matcher.find()) {
String rangeValue = matcher.group(1);
return Long.parseLong(rangeValue);
}
return -1;
}
private String findUri(String request) {
//'通过Matcher匹配,获取GET /http%3A%2F%2Fxxxxxx.mp3 HTTP/1.1 里面的中间的http%3A%2F%2Fxxxxxx.mp3'
Matcher matcher = URL_PATTERN.matcher(request);
if (matcher.find()) {
return matcher.group(1);
}
throw new IllegalArgumentException("Invalid request `" + request + "`: url not found!");
}
@Override
public String toString() {
return "GetRequest{" +
"rangeOffset=" + rangeOffset +
", partial=" + partial +
", uri='" + uri + '\'' +
'}';
}
}
所以该类的作用就是把本次发送到本地ServerSocket的请求中,拿到相关的请求里面的参数,所以该类里面包含了下面参数:
- 后面真实的url值(如果是ping这个字符串,说明是做ping请求测试),
- range值,如果有range值并且大于0,则说明是分段请求,partial也为true。
2.2 HttpProxyCacheServerClients对象:
我们再看看看这个类:
final class HttpProxyCacheServerClients {
private final AtomicInteger clientsCount = new AtomicInteger(0);
//'我们看到了url: http://127.0.0.1:port/[实际url]'
private final String url;
//'看到了HttpProxyCache这个类,这个类是做什么的????从字面意思是网络代理缓存类,后续继续细看'
private volatile HttpProxyCache proxyCache;
//'看到了一系列的监听器,从字面意思就知道是缓存监听器,当注册了这块的缓存监听,后续缓存好了可以通知'
private final List<CacheListener> listeners = new CopyOnWriteArrayList<>();
private final CacheListener uiCacheListener;
//'这个前面说过,我们的Config配置,包括缓存路径等'
private final Config config;
public HttpProxyCacheServerClients(String url, Config config) {
this.url = checkNotNull(url);
this.config = checkNotNull(config);
this.uiCacheListener = new UiListenerHandler(url, listeners);
}
//'进行请求'
public void processRequest(GetRequest request, Socket socket) throws ProxyCacheException, IOException {
//'实例化一个HttpProxyCache对象'
startProcessRequest();
try {
clientsCount.incrementAndGet();
//'使用HttpProxyCache对象拿着GetRequest和Socket对象,进行下一步操作'
proxyCache.processRequest(request, socket);
} finally {
finishProcessRequest();
}
}
private synchronized void startProcessRequest() throws ProxyCacheException {
proxyCache = proxyCache == null ? newHttpProxyCache() : proxyCache;
}
private HttpProxyCache newHttpProxyCache() throws ProxyCacheException {
HttpUrlSource source = new HttpUrlSource(url, config.sourceInfoStorage);
FileCache cache = new FileCache(config.generateCacheFile(url), config.diskUsage);
//'我们可以看到实例化HttpProxyCache对象,需要传入HttpUrlSource对象和FileCache对象'
HttpProxyCache httpProxyCache = new HttpProxyCache(source, cache);
httpProxyCache.registerCacheListener(uiCacheListener);
return httpProxyCache;
}
......
......
......
}
所以简单的显示就是这样:
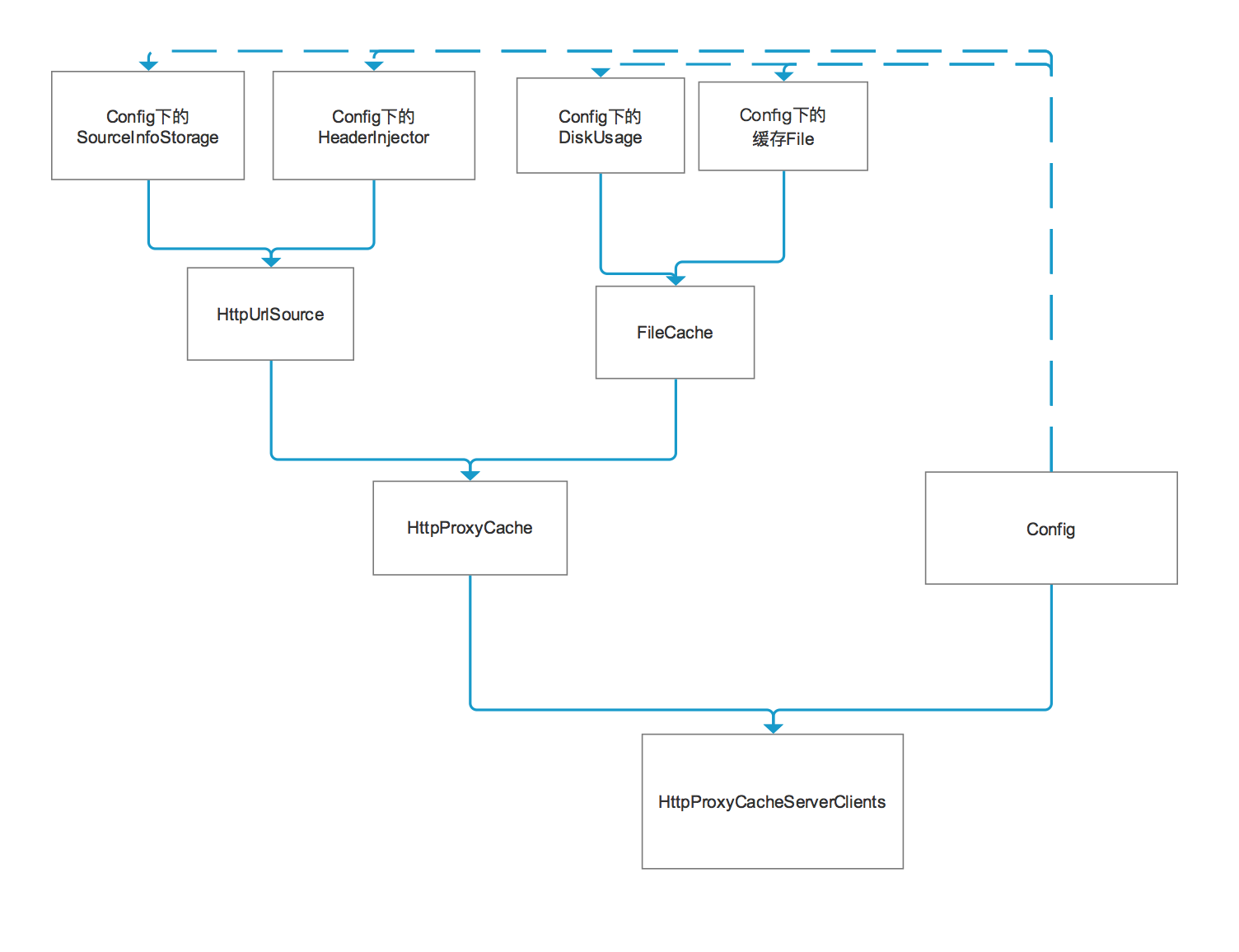
所以我们就知道了HttpProxyCacheServerSocket的作用了,一个url对应了一个HttpProxyCacheServerSocket,也就对应了:
FileCache管理了存储空间地址,存储状态的判断(比如是否存储空间满了)HttpUrlSource管理了相关的网络请求模块并把数据下载到FileCache处,
所以我们具体一个个来看。
2.3 FileCache :
public class FileCache implements Cache {
......
......
......
}
'我们可以看到它是实现了Cache类,所以我们只要看接口定义了哪些方法,就知道了FileCache的具体功能'
public interface Cache {
//'返回当前文件的大小:file.getLength();'
long available() throws ProxyCacheException;
//'因为使用的是RandomAccessFile,所以可以跳到File中的某一段在读取,而不是一定要从头开始'
//'offset偏移值,length读取长度'
int read(byte[] buffer, long offset, int length) throws ProxyCacheException;
//'一边云端获取数据,一边往文件后续继续添加内容(下载完就不往后面添加)'
//'data传入的数据 , length 当前文件的内容长度'
void append(byte[] data, int length) throws ProxyCacheException;
//'下载完后需要做的操作,1.文件数据流关闭,2.使用DisUsage对缓存文件进行重新排序,清除不需要的缓存文件'
void close() throws ProxyCacheException;
//'下载完成后,把文件的后缀名.download改为真正的文件后缀名,比如mp3'
//'(这个后缀名是根据传入的url里面拿的,一般比如http://xxxxxxxx.mp3,就拿到了mp3后缀)'
void complete() throws ProxyCacheException;
//'判断是否是临时文件,根据文件后缀名是不是.download判断'
//'(就像我们平常下东西,下的时候是xxxx.yyyyy某个临时文件,下载完后才是正确的格式,比如是xxxx.mp3)'
boolean isCompleted();
}
所以总体来说是把云端的数据缓存到本地等一系列操作。
2.3 HttpUrlSource :
我们来看它的代码:
public class HttpUrlSource implements Source {
......
......
......
}
public interface Source {
//'打开网络连接,获得了HttpURLConnection对象'
void open(long offset) throws ProxyCacheException;
//'获取网络资源的内容长度'
long length() throws ProxyCacheException;
//'使用HttpURLConnection读取相应的返回内容'
int read(byte[] buffer) throws ProxyCacheException;
//'关闭HttpURLConnection'
void close() throws ProxyCacheException;
}
是不是看着就很清晰了,该类用来进行网络连接,然后读取网络数据暴露给外部。
这里要注意一个小细节:
而HttpUrlSource中网络请求回来的数据后面有二种方式提供:
- 直接给 暴露出去最后读取后给FileCache使用,进行数据缓存,再进行本地文件读取数据给Socket;
- 如果不进行缓存就直接给发起访问的Socket的OutPutStream使用,直接输出内容
也就是HttpProxyCache类里面的这段代码:
public void processRequest(GetRequest request, Socket socket) throws IOException, ProxyCacheException {
OutputStream out = new BufferedOutputStream(socket.getOutputStream());
String responseHeaders = newResponseHeaders(request);
out.write(responseHeaders.getBytes("UTF-8"));
long offset = request.rangeOffset;
if (isUseCache(request)) {
//把云端拿到的数据缓存下来再使用
responseWithCache(out, offset);
} else {
//直接将云端读取的内容返回给Socket
responseWithoutCache(out, offset);
}
}
3. 云端数据读取,缓存,返回给Socket具体分析流程
我们肯定是具体想看的是缓存读取的流程。所以我们上面大致的代码已经写过了,现在再回头看看具体每一步是怎么实现的。
3.1 云端数据读取:
我们已经知道是在HttpUrlSource里面:
@Override
public void open(long offset) throws ProxyCacheException {
try {
//'openConnection打开网络连接'
connection = openConnection(offset, -1);
//'获取当前访问的数据类型格式'
String mime = connection.getContentType();
//'获取当前连接的输出流'
inputStream = new BufferedInputStream(connection.getInputStream(), DEFAULT_BUFFER_SIZE);
//'获取当前返回数据的总长度'
long length = readSourceAvailableBytes(connection, offset, connection.getResponseCode());
//'获取到的内容都使用SourceInfo来进行存储管理'
this.sourceInfo = new SourceInfo(sourceInfo.url, length, mime);
this.sourceInfoStorage.put(sourceInfo.url, sourceInfo);
} catch (IOException e) {
throw new ProxyCacheException("Error opening connection for " + sourceInfo.url + " with offset " + offset, e);
}
}
//'网络连接就是使用基础的HttpURLConnection来进行连接'
private HttpURLConnection openConnection(long offset, int timeout) throws IOException, ProxyCacheException {
HttpURLConnection connection;
boolean redirected;
int redirectCount = 0;
String url = this.sourceInfo.url;
do {
LOG.debug("Open connection " + (offset > 0 ? " with offset " + offset : "") + " to " + url);
connection = (HttpURLConnection) new URL(url).openConnection();
injectCustomHeaders(connection, url);
if (offset > 0) {
connection.setRequestProperty("Range", "bytes=" + offset + "-");
}
if (timeout > 0) {
connection.setConnectTimeout(timeout);
connection.setReadTimeout(timeout);
}
int code = connection.getResponseCode();
redirected = code == HTTP_MOVED_PERM || code == HTTP_MOVED_TEMP || code == HTTP_SEE_OTHER;
if (redirected) {
url = connection.getHeaderField("Location");
redirectCount++;
connection.disconnect();
}
if (redirectCount > MAX_REDIRECTS) {
throw new ProxyCacheException("Too many redirects: " + redirectCount);
}
} while (redirected);
return connection;
}
//'暴露给外部的数据读取方法实际上就是用上面获取到的输出流来读取内容'
@Override
public int read(byte[] buffer) throws ProxyCacheException {
if (inputStream == null) {
throw new ProxyCacheException("Error reading data from " + sourceInfo.url + ": connection is absent!");
}
try {
return inputStream.read(buffer, 0, buffer.length);
} catch (InterruptedIOException e) {
throw new InterruptedProxyCacheException("Reading source " + sourceInfo.url + " is interrupted", e);
} catch (IOException e) {
throw new ProxyCacheException("Error reading data from " + sourceInfo.url, e);
}
}
3.2 数据缓存:
我们来看HttpProxyCache里面的代码:
//'咋一眼看和responseWithoutCache不是长的一模一样么关键就是在于读取数据的地方做了中间处理'
private void responseWithCache(OutputStream out, long offset) throws ProxyCacheException, IOException {
byte[] buffer = new byte[DEFAULT_BUFFER_SIZE];
int readBytes;
//'这边read读取的时候,其实已经做了缓存,而实际返回的已经是本地数据'
while ((readBytes = read(buffer, offset, buffer.length)) != -1) {
out.write(buffer, 0, readBytes);
offset += readBytes;
}
out.flush();
}
我们具体看看这个read方法:
public int read(byte[] buffer, long offset, int length) throws ProxyCacheException {
ProxyCacheUtils.assertBuffer(buffer, offset, length);
while (!cache.isCompleted() && cache.available() < (offset + length) && !stopped) {
//进行网络连接,获取云端数据数据,写入本地缓存
readSourceAsync();
//等待一秒钟
waitForSourceData();
//检测读取失败次数
checkReadSourceErrorsCount();
}
//'可以看到我们最终返回的是缓存中的数据'
int read = cache.read(buffer, offset, length);
if (cache.isCompleted() && percentsAvailable != 100) {
percentsAvailable = 100;
//回调通知缓存程度
onCachePercentsAvailableChanged(100);
}
return read;
}
所以具体的其实就在readSourceAsync();方法里面:
private synchronized void readSourceAsync() throws ProxyCacheException {
boolean readingInProgress = sourceReaderThread != null && sourceReaderThread.getState() != Thread.State.TERMINATED;
if (!stopped && !cache.isCompleted() && !readingInProgress) {
sourceReaderThread = new Thread(new SourceReaderRunnable(), "Source reader for " + source);
sourceReaderThread.start();
}
}
private class SourceReaderRunnable implements Runnable {
@Override
public void run() {
readSource();
}
}
//'实际的方法:'
private void readSource() {
long sourceAvailable = -1;
long offset = 0;
try {
offset = cache.available();
//'前面介绍过HttpUrlSource的,open大家应该知道了。连接网络请求'
source.open(offset);
sourceAvailable = source.length();
byte[] buffer = new byte[ProxyCacheUtils.DEFAULT_BUFFER_SIZE];
int readBytes;
//'循环读取网络数据'
while ((readBytes = source.read(buffer)) != -1) {
synchronized (stopLock) {
if (isStopped()) {
return;
}
//'然后不停的写入本地缓存文件中'
cache.append(buffer, readBytes);
}
offset += readBytes;
notifyNewCacheDataAvailable(offset, sourceAvailable);
}
tryComplete();
onSourceRead();
} catch (Throwable e) {
readSourceErrorsCount.incrementAndGet();
onError(e);
} finally {
closeSource();
notifyNewCacheDataAvailable(offset, sourceAvailable);
}
}
所以整个流程就清楚了.......
其他:
回到我们刚开始的问题:
1.我们可以自定义FileNameGenerator
public class ATFileNameGenerator implements FileNameGenerator {
比如http://aaaaaaa.com/905_xxxxxxxxxxxx.mp3
一般来说网址里面带了这首歌的id值(比如这里的905),可能后面拼接了其他时间戳等。我们只要取出来核心的地方就行了:
public String generate(String url) {
// 只有爱听url会变化
if (url.contains("aaaaaa.com")) {
//然后通过你们对应的规则,取出来中间的id值,
//然后用id。来作为文件名字,找的时候也通过这个规则找文件即可。
return musicId;
}
Md5FileNameGenerator md5FileNameGenerator = new Md5FileNameGenerator();
return md5FileNameGenerator.generate(url);
}
}
- 我们完全可以自定义Key来进行存储,比如CP方+歌曲ID。变动源码存储这块的MAP key值。这样以后的url没规则,也可以应付(你去请求对应url的时候,肯定是知道CP和id去请求对应的播放地址)
结语:
写的烂轻点喷即可.......
