

本译文原地址:juejin.im/editor/post…
译在最前
本文是Charles Scalfani大神在Medium上发布的人气非常高的So You Want to be a Functional Programmer系列文章,这个系列一共由六篇文章组成,我将其全部合成了一篇,篇幅有点长,但是是一个非常好的函数式编程的入门教程,特别是对于Web开发工程师来说,因为文章里面绝大部分的例子都是用Javascript代码来举例,非常容易理解。如果你花时间耐心看完绝对会觉得非常值得。每一部分的文章我都会在开头贴出原文链接,有兴趣的读者可以点进去查看,另外文章中的一些外链需要翻墙才能访问。
在函数式编程上迈出第一步是很重要往往也是最难的。但不代表一定要这么难,如果你能跟随我的脚步来阅读本文。
心态调整
学习驾驶

我们用父母的车来练车的时候你一定不敢开到高速上,除非我们已经在家旁边的街道里面练的非常熟练了。
伴随着所有我们爸妈终将会忘掉的各种练车时的危险时刻,我们就学会了驾驶以及拿到驾照。
(解释一下国外学车基本是自己跟爸妈学的,学完以后去考试拿驾照,不像国内那样在专门的教练场学习)
当我们驾照拿到手以后,每当有机会的时候我们都会小心地将车开出去,随着驾驶次数的增多我们会变得更加熟练以及自信。然后到了某一天,我们将会去开一部别人的车或者是家里换新以后空出来的旧车。
当我们拿着别人的车的方向盘时候是什么感觉?会不会觉得非常陌生呢?其实并不会像我们第一次接触方向盘时那么的陌生了。以前我们都是坐乘客位,现在换成了驾驶位。
但是当我们在开一辆新车的时候,脑子里会自动地演示一些基本的操作,例如怎么插钥匙,怎么打灯,怎样调整后视镜的角度等等。
所有的这些以后,一切都水到渠成。但是为什么这次比第一次开车时变得简单了?
因为开车所需的基础准备基本一致,并且新旧两辆车其实本质也还是车。
而其中可能有一些不一样的小功能的时候,我们并不会在第一次接触的时候就会去使用它们,甚至第二次也不会。最后,我们慢慢学会了所有的新功能,至少那些我们感兴趣的。
好了,学习编程语言其实和这个过程大同小异。第一步是最难的(指的是学会开第一辆车),但当你有了经验以后,接下来所有东西都会变得简单很多。
当你第一次学习第二门新的编程语言时,你会问诸如 “怎么创建一个类”, “怎么在数组中做搜索”, “怎么在函数中传递参数” 等等的问题。
你非常确信你可以会学会这门新的语言因为你可以从会旧语言中汲取经验去解决在学习新语言时候所遇到的问题。
第一辆太空飞船

尽管你已经有足够丰富的驾驶车辆的经验了,想象一下,现在让你来开太空飞船。
如果你是要在太空中行驶,你不太能指望在公路上驾驶的经验能给你带来很大的帮助,你将必须要从零开始。
当你开始接收训练以后你会发现在宇宙中飞行与大路上开车对比起来真的相差甚远。
这和学习函数式编程是同一回事,它与你以前所学有非常大的区别,你应该要有心理准备。你所知道的大部分编程经验在函数式编程面前可能并不是简单的转换这么简单。
编程其实算是一种思维方式,函数式编程就是教会你如何用完全不同的方式去思考。甚至有可能,你永远没有办法回到以前的思维模式里面。
忘记所有你所学吧
很多人喜欢说这句话,但我觉得并不是完全对的。—— 函数式编程更像是从头开始。 不是重头开始,但其实也差不多。 这里面其实有很多你已经知道并熟悉的概念,但是如果你能做好从头开始学的心理准备那就再好不过了。
因为合理的期待催生正确的学习态度,而正确的学习态度会让你那么容易放弃,在遇到困难的时候。
有很多事情你以前可以做的,在函数式编程里面就不可以用了。
就像在你的车里面,你可以在通过后退来离开主干道,但是在太空驾驶飞船的时候,是没有后退的。或许你会想“啥玩意,没有后退那到底要怎么驾驶呢?”
然后,你就会发现在太空中不需要后退是因为这是在一个三维的空间里面。一旦你理解了这些,你就不再需要后退了。更有可能是在未来的某一天,你会发现原来以前在公路上驾驶是有这么多的局限性。
学习函数式编程是需要花时间的,所以需要有足够的耐心
让我们离开冰冷的传统编程世界,接受温暖的函数式编程世界的怀抱吧。
下面我会分章节先介绍一些函数式编程的基本概念并教你写出第一段属于你自己的函数式编程代码。或者你已经熟悉这些概念,但你同样可以跟我一起过一遍来巩固这些基础概念。
先不要着急,从现在开始慢慢阅读并且理解下面的代码例子。你甚至可以在读取一部分章节以后停下来思考一阵子,然后在返回来阅读剩下的内容。
最重要的东西是你要学会去理解它们。
函数式编程特性
纯函数

纯函数就是非常简单的函数,它们只会处理传入给它们的参数。
这是一个用Javascript实现的纯函数例子
var z = 10;
function add(x, y) {
return x + y;
}
要注意的是这个add函数并不会对全局变量z进行读或者写操作。它只会去读取传入的参数x和y,并且返回x,y相加的值。
这就是一个纯函数,如果add碰触了z,那它就不再是一个纯函数了。
这是另一个例子
function justTen() {
return 10;
}
如果justTen是纯函数这个假设是成立的话,那它仅仅只可以返回一个常量10,为什么?
因为我们没有给它任何传入任何的参数,因此它也是一个纯函数,因为他不能获取任何除了传入参数以外的任何值,它只能返回一个常量。
但因为纯函数如果不接收传参的话仅仅只能返回一个常量,所以其实没有很大的实际用途。这种情况你往往可以直接定义一个const justTen = 10的常量。
一个有意义的纯函数必须接收一个以上的参数
看一下下面这个例子:
function addNoReturn(x, y) {
var z = x + y
}
可以看到这个函数没有任何返回值,仅仅是把x和y的相加结果赋值给z但是没有返回。
这也是一个纯函数因为他仅仅访问传入给它的参数,但因为没有返回任何东西所以也是没有实际意义的。
所有有意义的纯函数都必须有返回值
我们接着看
function add(x, y) {
return x + y;
}
console.log(add(1, 2)); // prints 3
console.log(add(1, 2)); // still prints 3
console.log(add(1, 2)); // WILL ALWAYS print 3
可以留意到add(1,2)返回值永远是3。如果add函数内部使用了外部的变量,那你可能就无法能够准确预知它的返回值了,因为外部变量会在你不知情的情况下被改变。
纯函数在给定相同的传入时候永远返回相同的结果
由于纯函数不可以修改外部变量,所以下面这些函数并不是纯函数
writeFile(fileName);
updateDatabaseTable(sqlCmd);
sendAjaxRequest(ajaxRequest);
openSocket(ipAddress);
所有这些函数都会带来副作用。当你调用他们的时候他们会修改文件或者数据库记录,或者往服务端发送数据或者是调用操作系统底层的socket接口等等。他们不仅仅是操作了传入的参数以及返回结果这么简单。因此,这些函数你永远无法准备地预知他们会返回什么东西。这种我们不确定函数运行结果的情况我们称之为副作用。
纯函数是没有副作用的
在交互式的编程语言如Javascript,Java c#里面,副作用是常有的事情。这无疑加大了debug的难度,因为变量可以被任何一个地方修改成不同的值。所以如果你有一个bug是因为变量被改成了一个错误的值的时候,你要怎么办?所有代码都查看一遍吗?显然也并不是一个好主意。
所以这时你可能会想“那我到底能用纯函数来干啥子?”
在函数式编程里面,你不仅仅是编写纯函数。
函数式编程并不能消除副作用,他们仅仅是可以控制它们。由于编程是面向真实世界的,所以有一部分的程序代码一定不是纯净的。我们的目的只是去让这些不纯净的代码尽可能的少并且从我们的程序里面分离出来。
不可变性

var x = 1;
x = x + 1;
不管你还记不记得上学时的数学老师是谁,但是依照数学课本里面的知识你知道,x是永远不可能等于x+1的。
但因为这个是一个交互式语言的编程,意味着,这是先获取x当前的值,然后往上加1,然后再将结果赋值回给x。
好了。在函数式编程里面, x=x+1是非法的。
在函数式编程里面没有变量
存储值得地方我们依然称之为变量但主要是因为延续历史,实际上,他们应该是不变的,是常量。一旦x变成了另一个值,那x变量的生命周期也就结束了,占用的内存会被操作系统所回收。
不要担心,x往往是一个函数内部的本地变量,它的生命周期本来就很短。但是只要它没有被回收,那么它的值都不能发生变化。
这一个用Elm编写常量的例子,Elm是一个给Web工程师的函数式编程语言。
addOneToSum y z =
let
x = 1
in
x + y + z
如果你不熟悉这种ML风格的语法的话,让我来给你解释,addOneToSum这个函数,它接收两个参数y和z。
在里面的let代码块中,x绑定的值是1。在它被销毁前,他的值都只能是1。在函数执行完成退出时x会被销毁,如果更精确地说当let代码块执行完成以后它就被销毁了。
在in代码块中,运行计算包含let代码块中的变量,即x。返回x+y+z的计算结果,更准确地说是返回1+y+z的结果,因为x=1。
再来,我能猜到你会说“如果没有了变量我到底还能做什么?”
让我们来思考一下我们平时会变量的比较常出现的两个场景。多值的变化(改变一个对象或数组中的某一个值)和单个值得变化(循环遍历计数器)。
函数式编程在处理需要改变某个记录中的具体值时通过对这个记录进行复制从而改变对应的值。这是一个高效的方法,但也必须通过一些特殊的数据结构来实现。
函数式编程解决单值修改的问题,也是采用同样的,对其进行复制。
对了,函数式编程中是没有循环遍历的。
“先是没有变量,现在还不能遍历?还能不能好好玩耍了”
先别着急,并不是说我们不能循环遍历,而是没有我们常所理解的特定的循环操作符,像for, while, do, repeat这样的罢了
函数式编程使用递归来实现循环遍历
这里有两种方法在javascript中做循环遍历
// simple loop construct
var acc = 0;
for (var i = 1; i <= 10; ++i)
acc += i;
console.log(acc); // prints 55
// without loop construct or variables (recursion)
function sumRange(start, end, acc) {
if (start > end)
return acc;
return sumRange(start + 1, end, acc + start)
}
console.log(sumRange(1, 10, 0)); // prints 55
我们可以注意到,递归是通过调用函数自身的方法来实现与for相同的功能,这并不会修改原本的变量,相反他是从老变量中计算获得新变量。
不幸的是,在Javascript中这样的代码并不常见,有两个原因,Javascript的语法写递归并不是十分的方便。第二个原因是,你根本不会想需要用递归去实现一次循环遍历。
在Elm里面,有更加易读的写法
sumRange start end acc =
if start > end then
acc
else
sumRange (start + 1) end (acc + start)
运行的结果
sumRange 1 10 0 = -- sumRange (1 + 1) 10 (0 + 1)
sumRange 2 10 1 = -- sumRange (2 + 1) 10 (1 + 2)
sumRange 3 10 3 = -- sumRange (3 + 1) 10 (3 + 3)
sumRange 4 10 6 = -- sumRange (4 + 1) 10 (6 + 4)
sumRange 5 10 10 = -- sumRange (5 + 1) 10 (10 + 5)
sumRange 6 10 15 = -- sumRange (6 + 1) 10 (15 + 6)
sumRange 7 10 21 = -- sumRange (7 + 1) 10 (21 + 7)
sumRange 8 10 28 = -- sumRange (8 + 1) 10 (28 + 8)
sumRange 9 10 36 = -- sumRange (9 + 1) 10 (36 + 9)
sumRange 10 10 45 = -- sumRange (10 + 1) 10 (45 + 10)
sumRange 11 10 55 = -- 11 > 10 => 55
55
你或许会认为for更加容易理解,这个问题其实是值得商榷的,因为这很大程度跟你的熟悉程度有关系。非递归的遍历需要改变变量的值,这在我们看来是很糟糕的。
我并没有完全解释不变性的好处,你可以查看这篇文件来看到更多为什么编程需要有限制
其中一个明显的好处是,当你需要获取所有程序中的变量的时候,你也仅有只读权限,意味着没有人可以改变他们的值,即使是你自己。这样的话就不会出现因为修改了变量而带来的风险。
并且,如果你的程序是多线程的,那它也是线程安全的,因为没有其他人可以修改它的值。一旦有线程希望去修改它,那这个线程也必须通过这个值来计算得出新的值而不是直接去修改它。
回到90世纪中旬,我为(Vreate Crunch)[www.youtube.com/watch?v=uIO…]写了一个游戏引擎然后有一个非常大的漏洞就是由多线程引起的。我多么希望我那时就能知道不变性这个概念,但那时候的我只是在关心两倍或者四倍CD-ROM的差异对游戏性能的影响而已。
不变性让代码更加简单以及安全
友情提示

在阅读代码的时候放慢一下脚步,确保你已经明白然后再往下看。每个章节都是基于前一个章节的。如果你阅读得太快可能会错过一些为了后面章节做铺垫的细微知识。
重构

function validateSsn(ssn) {
if (/^\d{3}-\d{2}-\d{4}$/.exec(ssn))
console.log('Valid SSN');
else
console.log('Invalid SSN');
}
function validatePhone(phone) {
if (/^\(\d{3}\)\d{3}-\d{4}$/.exec(phone))
console.log('Valid Phone Number');
else
console.log('Invalid Phone Number');
}
这些代码我们已经写过无数次了,其实这两个函数的行为是非常像的,亦一样的地方非常少。
与其直接复制validateSsn的代码修改一下变成另一个新函数validatePhone,我们更倾向于创建一个独立的函数,将它们不一样的地方作为参数传递进去。
在这个例子里,我们会创建三个参数value,regular expression,message
重构后的代码长这样
function validateValue(value, regex, type) {
if (regex.exec(value))
console.log('Invalid ' + type);
else
console.log('Valid ' + type);
}
旧的参数ssn和phone现在已由value来替代。
正则表达式 /^\d{3}-\d{2}-\d{4}$/和 /^\(\d{3}\)\d{3}-\d{4}$/由参数regex替代。
最后 “SSN” 和 “Phone Number” 由参数type替代。
写一个函数比写两个要好得多,当然,比写三个,四个甚至十个函数会更加好。这会让你的代码更加干净和容易维护。
但如果碰到下面这个情况呢?
function validateAddress(address) {
if (parseAddress(address))
console.log('Valid Address');
else
console.log('Invalid Address');
}
function validateName(name) {
if (parseFullName(name))
console.log('Valid Name');
else
console.log('Invalid Name');
}
这里面还涉及两个函数parseAddress和parseFullName,它们接受一个字符串并返回一个布尔值。
我们应该怎样去重构它?
我们可以像之前一样用value替代address和name,用type来替代 “Address” 和 “Name” ,但这里我们原本的正则表达式变成了一个函数。
除非我们能将函数作为参数进行传递。
高阶函数

有一些语言并不能将函数作为参数进行传递,有一些可以,但是并没有很简单的写法
在函数式编程里面,函数是一等公民,换言之,函数也仅仅是一个值而已。
因为函数只是一个值,所以我们可以将其作为参数进行传递。
虽然Javascript不是一门纯函数编程语言,但它是支持将函数作为参数进行传递的。所以我们可以将那两个函数重构成如下:
function validateValueWithFunc(value, parseFunc, type) {
if (parseFunc(value))
console.log('Invalid ' + type);
else
console.log('Valid ' + type);
}
这个接受函数作为参数的新函数我们称之为高阶函数。
接下来我们可以将我们的高阶函数来表示之前的4个函数。
validateValueWithFunc('123-45-6789', /^\d{3}-\d{2}-\d{4}$/.exec, 'SSN');
validateValueWithFunc('(123)456-7890', /^\(\d{3}\)\d{3}-\d{4}$/.exec, 'Phone');
validateValueWithFunc('123 Main St.', parseAddress, 'Address');
validateValueWithFunc('Joe Mama', parseName, 'Name');
这样写比我们写四个功能几乎相同的函数要好看得多。
但是注意到这里的正则表达式,他们看起来有点冗长,让我们继续重构一下
var parseSsn = /^\d{3}-\d{2}-\d{4}$/.exec;
var parsePhone = /^\(\d{3}\)\d{3}-\d{4}$/.exec;
validateValueWithFunc('123-45-6789', parseSsn, 'SSN');
validateValueWithFunc('(123)456-7890', parsePhone, 'Phone');
validateValueWithFunc('123 Main St.', parseAddress, 'Address');
validateValueWithFunc('Joe Mama', parseName, 'Name');
这样看上去就好看很多了。现在当我们需要解析一个电话号码的时候,我们不再需要将解析的正则重新复制一份。
但是试想一下,我们如果有更多的正则表达式而不仅仅是parseSsn和 parsePhone的时候,每次我们都要创建一个新的函数表达式解析器,并且我们还需要加上**.exec**后缀。你相信我,这是很容易被忽视而漏写的。
我们可以通过创建一个高阶函数来返回一个带有**.exec**后缀的函数
function makeRegexParser(regex) {
return regex.exec;
}
var parseSsn = makeRegexParser(/^\d{3}-\d{2}-\d{4}$/);
var parsePhone = makeRegexParser(/^\(\d{3}\)\d{3}-\d{4}$/);
validateValueWithFunc('123-45-6789', parseSsn, 'SSN');
validateValueWithFunc('(123)456-7890', parsePhone, 'Phone');
validateValueWithFunc('123 Main St.', parseAddress, 'Address');
validateValueWithFunc('Joe Mama', parseName, 'Name');
这里makeRegexParser的作用是接受一个正则表达式然后返回exec函数,它接受一个字符串作为参数。validateValueWithFunc内部会将字符串传递给它,然后执行。
parseSsn和parsePhone和以前的正则的exec函数具有一样的功能。
诚然这只是一个微小的改动,但已经很好地诠释了什么是高阶函数。
然而,你可以想象当makeRegexParser变得更加复杂的时候,你能从中获得很多好处,因为你只需要修改一个地方就可以了。
这里是另一个高阶函数返回值是函数的例子:
function makeAdder(constantValue) {
return function adder(value) {
return constantValue + value;
};
}
makeAdder函数接受constantValue作为参数并且返回一个将返回其接受的参数与constantValue相加为结果的adder函数
我们会这样去使用它:
var add10 = makeAdder(10);
console.log(add10(20)); // prints 30
console.log(add10(30)); // prints 40
console.log(add10(40)); // prints 50
我们创建了一个add10的函数,通过传递一个10的常量给makeAdder,它会返回一个函数,这个函数会返回其接受的参数与10相加的结果。
注意到这个adder函数是可以访问constantValue的,即使makeAdder函数已经返回了。因为创建adder时constantValue是在其作用域内的。
这是一个非常重要的特性,如果没有了它,函数返回函数其实就没有多大的意义了。所以我们去理解它是如何工作是一件很重要的事情。
我们称这种行为叫做闭包
闭包
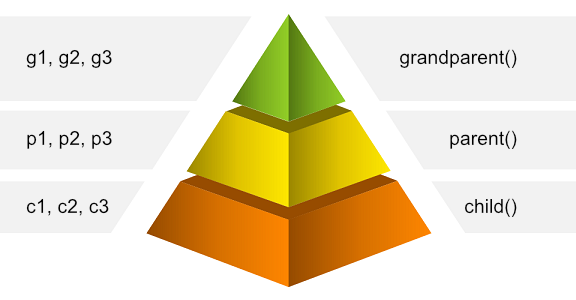
我们有一个比较明显的闭包的例子:
function grandParent(g1, g2) {
var g3 = 3;
return function parent(p1, p2) {
var p3 = 33;
return function child(c1, c2) {
var c3 = 333;
return g1 + g2 + g3 + p1 + p2 + p3 + c1 + c2 + c3;
};
};
}
在这个例子里面,child函数都可以获得自身的参数以及父级parent的变量以及祖父级grandParent的变量。
parent可以访问其父级grandParent的变量。
grandParent只能访问其自己的变量。
这里是一个使用的例子
var parentFunc = grandParent(1, 2); // returns parent()
var childFunc = parentFunc(11, 22); // returns child()
console.log(childFunc(111, 222)); // prints 738
// 1 + 2 + 3 + 11 + 22 + 33 + 111 + 222 + 333 == 738
这里parentFunc让parent的作用域依然存活,因为grandParent返回了parent。
同样的childFunc让child的作用域存活,因为parentFunc返回了parent,parent返回了child。
当一个函数被创建时,所有其作用域里面的变量的整个生命周期就是能被访问的。只要存在对这个函数的引用,这个函数就不会被回收。举个例子,这里的chid函数的作用域一直存在,只要childFunc一直在引用它。
闭包是指一个函数通过被另一个函数引用使其作用域能一直处于存活状态。
请注意,在Javascript中,闭包是有问题的,因为变量是可变的,即,即使它作用域所在的函数已经退出以后,它的值依然能被改变。这是很混乱的。
值得庆幸的是,变量在函数式编程语言里面是不可变的,从而消除了因此而造成的bug和混乱。
函数模块化

作为一个编程人员,我们往往是很懒的,我们不想去写新功能,不想写测试,也不想部署我们的代码一遍又一遍重复这些工作。
我们总会想方设法尽可能让工作只做一遍,然后下次再要做的时候直接复用就可以了。
代码复用挺起来很棒但实际实施起来是有难度的。如果代码太过特殊,你没有办法复用。如果代码太过简单,就会让使用者在使用的时候非常困难。
所以我们需要在这之间拿捏一个平衡,能寻求一个方法去构建体积更小,更容易复用的代码块,然后我们再将他们一块块组建起来去完成复杂的功能。
在函数式编程里面,函数就是我们的代码块。我们构建他们去完成完成特定的小块功能,然后我们会将他们像乐高一样组件在一起来完成更加复杂的功能。
这就是函数模块化
那它具体是如何工作的呢?我们来写两个Javascript的函数
var add10 = function(value) {
return value + 10;
};
var mult5 = function(value) {
return value * 5;
};
还有另一种用箭头函数实现的简洁写法
var add10 = value => value + 10;
var mult5 = value => value * 5;
这样看上去更好看一些,现在来想象一下同样的我们只用一个函数来计算value加上10的和乘以5,我们会这样写
var mult5AfterAdd10 = value => 5 * (value + 10)
虽然这已经是一个很简单的函数,但我们仍然希望可以不用从头去写它。
首先,我们偶尔会犯下一些错误,例如忘记写括号。
其次,我们已经有了一个函数实现加10功能,以及另一个函数实现乘5功能的,这相当于我们将我们已经有的代码又重新写了一遍。
所以取而代之,我们用add10和mult5这两个函数来构建我们的新函数
var mult5AfterAdd10 = value => mult5(add10(value));
这是一个更好的写法。
在数学上,我们称f∘g为函数组合,读作 “由g构成的f” ,或更常见的说法是 “g先于f” ,因此 (f∘g)(x) 等效于以调用以x为参的g函数作为参数来调用f,或简单地写成f(g(x))。
在我们的例子里面,我们有一个mult5∘add10 或者是 “add10先于mult5”,因此我们用这个来命名我们的函数为mult5AfterAdd10
这正是我们需要的,我们调用mult5以后调用传入value的add10,或简单点表示为mult5(add10(value))。
由于Javascript没有原生的函数模块化功能,我们来看看用Elm如何实现:
add10 value =
value + 10
mult5 value =
value * 5
mult5AfterAdd10 value =
(mult5 << add10) value
<< 运算符是我们在Elm中编写函数模块化的方式。 它使我们对数据流向有更直观的认识。 首先,将值传递给add10,然后将其结果传递给mult5。
注意到mult5AfterAdd10中的括号,即**(mult5 << add10),它确保了函数在接受value**前先组合起来。
你可以用你喜欢的方式来组合多个函数,如下
f x =
(g << h << s << r << t) x
因此x是作为参数传给t,t(x) 的结果传给r,以此类推。如果你用Javascript的写法就是g(h(s(r(t(x))))),看上去就是一场噩梦。
Point-Free风格

在函数式编程中,这种不需要特定指明或表示函数参数的代码风格叫做Point-Free Notation。一开始你会觉得这种风格非常的奇怪,但当你做得多以后你会觉得其实相当的惊艳。
在函数mult5AfterAdd10里面,我们注意到了value这个变量我们写了两次,一次是表示作为参数传入,第二次是在被调用的时候。
-- This is a function that expects 1 parameter
mult5AfterAdd10 value =
(mult5 << add10) value
但是这不是必须的,因为add10的最右边期待一个和传入值一样的玩意,所以下面是point-free版本的写法
-- This is also a function that expects 1 parameter
mult5AfterAdd10 =
(mult5 << add10)
我们能从这种代码风格中得到一些好处。
首先,我们不需要特别地多此一举地将传参和调用的value再写一遍。这也意味着我不用给他去想一个合适的单词去表示他。
其次,这让人更容易阅读,并且让代码看起来不那么冗余。不过这只是一个最基本的例子,想象一下如果参数是多个的情况要怎么办?
天堂的烦恼

到目前为止我们看到了函数模块化是如何工作的,并且我们如何写出Point-free风格的代码让其看起来更加简洁,清晰与富有弹性。
现在,我们开始在一些不同的场景下去试着运用它们,然后来看看它们的价值。想象一下我们用add来代替add10
add x y =
x + y
mult5 value =
value * 5
有了这两个函数以后我们如何来编写mult5After10呢?
想一会,别着急,你先试着自己先想一下。
。
。
。
。
。
。
。
。
。
。
好了,如果你已经花了一些时间自己做了思考以后,你或许会想出来下面的方法
-- This is wrong !!!!
mult5AfterAdd10 =
(mult5 << add) 10
它并不好使,为什么?因为add需要接受两个参数。
如果你觉得看Elm代码不够明显,我们来看看Javascript的版本
var mult5AfterAdd10 = mult5(add(10)); // this doesn't work
这个代码是错的,为什么?
因为add函数需要接受两个参数,但这里只传入了1个,所以会导致运算错误。
事实上,在Elm中,编译器甚至不会允许你写出这样传参错误的代码,它会在你编译时候就报错。(这也是Elm非常好的一点,对比起来Javascript是直到这段代码被执行的时候才会抛出错误,意味着你并不能及时发现它)
我们来再写一个版本
var mult5AfterAdd10 = y => mult5(add(10, y)); // not point-free
这并不是point-free风格的写法,但也是勉强可以接受的。现在我们如果不再单单地组成这两个函数。如果我写一个新的函数,也是需要接受多个参数,那无疑会让事情变得非常复杂。因为当我需要组合mult5AfterAdd10和这个新函数的时候,会遇到一些麻烦。
由于我们不能将这两个函数结合使用,因此函数模块化的用途似乎有局限性。 太糟糕了,因为它是如此强大。
那么我们能够解决这些问题么?有没有什么办法可以消除这些麻烦?
有一个设想是,如果我们能有方法提前先给add函数传入一个参数然后在mult5AfterAdd10被调用时候给它传另一个参数,就能解决这个问题。
我们称这种传参的方法为柯里化,我们会在下面做介绍。
柯里化

我们在组合mult5和add时候遇到的问题,是因为mult5接收一个参数而add要接受两个参数。
试想一下如果所有组件函数都只接受一个参数,那么是否就不会有这个问题了。
我们可以将我们的add函数写成接受两个参数,但是每次调用只会得到其中一个,这就是柯里化在做的事情。
所有的柯里化函数都是每次只接受一个参数的函数。
这就可以允许我们在与mult5组合前先给定add一个参数。然后当mult5AfterAdd10被调用时,add会被传入第二个参数。
在Javascript里面我们可以改写成这个样子
var add = x => y => x + y
这就是add先接受一个参数,然后再接受第二个参数的写法。
更详细地说,add函数只接受一个x参数,然后返回一个接受另一个参数y的函数,所以最后返回的就是x与y的相加结果。
现在我们用这个版本来重构我们的mult5AfterAdd10
var compose = (f, g) => x => f(g(x));
var mult5AfterAdd10 = compose(mult5, add(10));
这个compose函数接受两个参数,f和g,然后返回一个接受一个参数x的**f(g(x))**函数。
这是在干嘛?这样其实我们就将我们的add函数转换成了一个柯里化的版本。这可以使得add更加有弹性,由于第一个参数10可以先被传入到add中,然后等mult5AfterAdd10被调用时再传入第二个参数。
你可能会好奇使用Elm的话如何改写add函数。你会发现,你并不需要。在Elm或者其他函数式编程语言里面,所有函数都是自动柯里化的。
所以add函数还是这个样子:
add x y =
x + y
然后将mult5AfterAdd10改写成这个样子就可以了:
mult5AfterAdd10 =
(mult5 << add 10)
坦白地说,Elm能打败像Javascript这样的交互式编程语言主要原因是它原生就集成了很多函数式编程的东西,例如柯里化与模块化。
柯里化与重构

一个很突出的优点是,你可以将一个原本接收很多参数的函数重构成接收更少参数的函数版本。
例如,当我们有以下两个函数,分别需要返回一个将字符串用花括号或者双花括号括起来作为返回值的时候:
bracket str =
"{" ++ str ++ "}"
doubleBracket str =
"{{" ++ str ++ "}}"
这是我们的用法:
bracketedJoe =
bracket "Joe"
doubleBracketedJoe =
doubleBracket "Joe"
我们可以将他们重写成
generalBracket prefix str suffix =
prefix ++ str ++ suffix
但是现在我们每次使用generalBracket的时候,我们都需要将花括号作为参数传入
bracketedJoe =
generalBracket "{" "Joe" "}"
doubleBracketedJoe =
generalBracket "{{" "Joe" "}}"
有没有更加简洁的方法?
这时如果我们重新将generalBracket的参数的位置调换一下,我们可以通过函数柯里化的方式创建bracket以及doubleBracket函数。
generalBracket prefix suffix str =
prefix ++ str ++ suffix
bracket =
generalBracket "{" "}"
doubleBracket =
generalBracket "{{" "}}"
我们会认为拼接字符串的花括号基本是固定的,像是前缀和后缀,所以放到参数最前面 ,然后将会改变的参数str作为函数的最后一个参数,我们就可以轻松的创建一个generalBracket的Point-free版本的代码了。
参数的位置对于对于是否能够充分使用柯里化是很重要的
同样的我们注意到bracket和doubleBracket使用了Point-free风格的写法 —— 参数str被隐藏了。bracket和doubleBracket函数都等待着最后一个参数str的传入。
现在我们就可以像之前那样调用这两个函数了。
bracketedJoe =
bracket "Joe"
doubleBracketedJoe =
doubleBracket "Joe"
但区别就是这两个函数是我们运用了函数柯里化的方式编写的,由generalBracket生成。
常见的函数式编程例子
首先,我们先看看一下的Javascript代码
for (var i = 0; i < something.length; ++i) {
// do stuff
}
这部分代码有一个很严重的问题,不是bug。而是我们每次需要写循环遍历的时候,都需要将这部分代码重新写一遍,一遍又一遍。
如果你是使用交互式编程语言如Java,c#,Javascript, PHP, Python等等的编程者的话,你会发现你已经写了这段代码不下百遍。
这就是问题所在,我们不希望每次都要将它再书写一遍。
让我们来改变这个现状。我们将其放在一个函数(或多个函数)里面,就不再需要再自己手动来写一遍for了。或者说起码能少写几次。
var things = [1, 2, 3, 4];
for (var i = 0; i < things.length; ++i) {
things[i] = things[i] * 10; // MUTATION ALERT !!!!
}
console.log(things); // [10, 20, 30, 40]
我们看到things被改变了,这是我们不期望的。违反了不变性。
我们来再换个写法,这样我们就不会改变任何变量。
var things = [1, 2, 3, 4];
var newThings = [];
for (var i = 0; i < things.length; ++i) {
newThings[i] = things[i] * 10;
}
console.log(newThings); // [10, 20, 30, 40]
现在我们就不会修改things的值,但是其实严格来说,我们改变了newThings的值。我们先忽略这点,毕竟我们用的是Javascript。当我们换成使用编程式语言,那我们才不可以真正地修改任何变量。
这里只是想说明函数是怎么帮助我们减写一些冗余的代码的。
我们打算将我们常用的map也放到一个函数里面
var map = (f, array) => {
var newArray = [];
for (var i = 0; i < array.length; ++i) {
newArray[i] = f(array[i]);
}
return newArray;
};
我们注意到了这里面接收一个f作为参数,这样我们的map函数就能将array处理成我们希望他变成的样子了。
我们来调用一下
var things = [1, 2, 3, 4];
var newThings = map(v => v * 10, things);
看出来我们没有添加任何循环遍历的代码,因为在map中已经实现了,但至少我们不需要再重复编写那段for循环的代码了。
我们来写另一个常用的filter
var filter = (pred, array) => {
var newArray = [];
for (var i = 0; i < array.length; ++i) {
if (pred(array[i]))
newArray[newArray.length] = array[i];
}
return newArray;
};
注意到里面的pred是一个函数,返回一个布尔值。如果是TRUE我们就将其项放入新数组中,反之跳过。
我们这样去使用它
var isOdd = x => x % 2 !== 0;
var numbers = [1, 2, 3, 4, 5];
var oddNumbers = filter(isOdd, numbers);
console.log(oddNumbers); // [1, 3, 5]
相比for风格的代码,这个filter要简洁很多。
最后我们来写reduce函数。它会接收一个数组然后将其减少成一个单一的值,但当然他还可以做更多其他事情。
reduce在函数式编程语言里面叫做fold
var reduce = (f, start, array) => {
var acc = start;
for (var i = 0; i < array.length; ++i)
acc = f(array[i], acc); // f() takes 2 parameters
return acc;
});
reduce接收一个f函数,以及start值和array作为参数、
注意到f这个函数接收两个参数,当前遍历的array子项以及累加器acc。每次迭代时,它将使用当前的子项来产生一个新的累加器结果。最后返回最后一次迭代的累加器结果。
下面是一个使用的例子
var add = (x, y) => x + y;
var values = [1, 2, 3, 4, 5];
var sumOfValues = reduce(add, 0, values);
console.log(sumOfValues); // 15
我们注意到add函数接收两个参数并将其相加,我们reduce函数也期望一个接收两个参数的函数作为参数传入。
我们以start值为0开始,将array,values,相加的结果作为参数。在reduce函数内部,sum是累加器计算的结果,这个最后的累加器返回的值就是sumOfValues
map,filter和reduce这三个函数允许我们对数组执行常见的操作,而不必编写for循环。
但在函数式编程语言里面,这三个函数显得非常有用,因为函数式编程语言不支持循环遍历的语法而仅仅只有递归。迭代函数不仅仅有用而且十分必要。
透明引用

你有以下一个代数公式
y = x + 10
然后我们说
x = 3
那就等价于
y = 3 + 10
注意到这里的等号依然是生效的,我们在纯函数中也可以做一样的事情
quote str =
"'" ++ str ++ "'"
我们会这样使用它
findError key =
"Unable to find " ++ (quote key)
这里findError是用来构建一个当查找key不成功时的错误消息的。
由于quote函数是一个纯函数,所以我们可以简单地替换成以下写法
findError key =
"Unable to find " ++ ("'" ++ str ++ "'")
这个就是我所说的反向重构(我觉得这个名字更好理解),一个可以被使用在编程或者项目中来让你更好地去推断代码的方法。
这在我们推导递归函数的时候尤其有用。
执行顺序

所以为什么我们会很自然地按照执行顺序来书写我们的代码,如下:
1. 拿出面包
2. 往吐司机中放入两块面包
3. 调节吐司机档位
4. 按下开关
5. 等待吐司跳出来
6. 拿走吐司机
7. 拿出黄油
8. 拿黄油刀
9. 将黄油弄到吐司上
在这个例子里面,有两个完全相互独立的操作,拿黄油和烤面包。他们仅在步骤9中相互依赖。
现实生活中,我们可以让步骤7和8,以及步骤1-6同时进行,因为他们是相互独立的。
用计算机操作表达就是:
线程 1
--------
1. 拿出面包
2. 往吐司机中放入两块面包
3. 调节吐司机档位
4. 按下开关
5. 等待吐司跳出来
6. 拿走吐司机
线程 2
--------
1. 拿出黄油
2. 拿黄油刀
3. 等待线程1完成
4. 将黄油弄到吐司上
那如果线程1执行失败了的时候线程2会怎样?是什么机制来协同两个线程呢?到底吐司在谁手上,线程1还是线程2还是各有一份?
如果是单线程的情况很显然我们就不需要考虑这么多问题了。
但是由于无疑多线程能更高效地利用计算机资源,所以我们需要花时间去好好研究它。
多线程所面临的两个主要问题:
第一,多线程程序不容易编写,阅读,理解,测试以及debug。
第二,一些语言,如Javascript,并不支持多线程,虽然有一些第三方的工具能让其实现多线程但是效果并不太能让人满意。
但是如果代码并不是按顺序执行并且所有东西都是并行执行的话呢?
虽然这看起来挺让人觉得难以置信,但是实际其实并没有你想象中的那么混乱,我们来看看Elm怎么诠释
buildMessage message value =
let
upperMessage =
String.toUpper message
quotedValue =
"'" ++ value ++ "'"
in
upperMessage ++ ": " ++ quotedValue
这里buildMessage接受message和value然后返回一个大写化的message,一个冒号以及用单引号引起来的value。
注意到upperMessage和quotedValue两个操作其实是相互独立的。
怎样可以称之为相互独立呢?
第一,它们必须是纯函数。这一点很重要因为纯函数不受执行顺序的影响。如果不具有纯净度的话,我们永远不知道他们是否真正的相互独立,也就是说我们必须依赖它的执行顺序。而这就是交互式编程语言的特点之一。
第二,一个函数的输出不作为另一个函数的输入,不然的话,我们就必须去等待前者执行完以后才能执行后者。
而很明显,upperMessage和quotedValue都是纯函数并且不依赖对方的输出。所以这两个函数可以以任意的顺序执行。
而这是编译器会去做的事情,不需要程序员自己去担心。不过乱序执行只可能在函数式编程语言中实现,因为在其他编程语言中,如果乱序执行,很难(甚至是不可能)去确定副作用的所产生的影响到底是什么。
函数式编程语言中,代码的执行顺序是由编译器决定的。
这是一个非常大的优势,因为考虑到现在CPU的处理速度是固定并且已经到了一个瓶颈。所以为了加快CPU的处理速度,芯片制造商只能增加越来越多的CPU核数来提升速度。而这意味着我们的代码在硬件层面其实是并行执行的。
但不幸的是,交互式编程语言中。除非是在非常底层的层面去实现,否则我们并不能充分地利用CPU的内核。但是一旦突破这个问题的话,我们的得益是非常巨大的。
而有了纯函数编程语言以后,我们在非常上层就有了能充分利用CPU多内核的潜力了,并且无需修改任何代码。
代码风格

在静态语言中,数据类型是需要写明的。下面是Java的代码
public static String quote(String str) {
return "'" + str + "'";
}
注意到将类型也标明在函数定义的时候,如果参数足够多的时候看起来会非常糟糕
private final Map<Integer, String> getPerson(Map<String, String> people, Integer personId) {
// ...
}
它们很容易干扰你阅读这个函数,所以你需要很仔细地去读取各个参数的名字。
动态语言就没有这个问题,Javascript如下
var getPerson = function(people, personId) {
// ...
};
在没有了众多定义妨碍的情况下读起来非常的容易,唯一的问题是我们同时也放弃了类型的安全性校验。我们可以随意传递任何数据类型的参数进去,例如给people传一个数字,给personId传一个对象等等。
而这些传参错误是直到我们代码运动的时候才会发现的,所以有可能当我将代码发布到生产环境一个月以后才会被发现。而在Java中就不会存在这种情况,因为编译的时候就会报错。
我们有没有方法能两个好处都同时得到,Javascript的简洁以及Java的类型安全检查呢?
其实是可以的,下面是一个带有类型声明的Elm写法
add : Int -> Int -> Int
add x y =
x + y
这里类型声明信息是在另一行的。这个分行让代码看起来清晰了许多。
现在你或许会觉得这段代码有拼写错误,我第一次看的时候也这么认为,我认为第一个 -> 应该是个逗号才对(因为是**x****,**y两个参数)。但其实并不是这样。
我加个括号或许看起来会更加清晰
add : Int -> (Int -> Int)
我们称之为,add是一个函数,接受一个Int类型的参数,然后返回一个函数,其接收一个Int类型的参数,并返回一个Int类型的结果。
这是另一个代码风格的例子
doSomething : String -> (Int -> (String -> String))
doSomething prefix value suffix =
prefix ++ (toString value) ++ suffix
这里说的是doSomething是一个接受一个String类型作为参数的函数,它返回一个接受一个Int类型参数的函数,然后这个返回的参数接受一个String类型的参数并返回一个String类型的结果。
注意到所有都是接受一个参数。这是因为Elm中所有的函数都是柯里化的。 所以默认情况括号永远是括着右边参数的,所以我们可以省略不写,如下
takes2Params : Int -> Int -> String
takes2Params num1 num2 =
-- do something
这个和下面是完全两回事
takes1Param : (Int -> Int) -> String
takes1Param f =
-- do something
上面写法的意思是,takes1Param是一个接收两个Int类型为参数的函数,而takes2Params是接受一个Int为参数的函数,返回一个接收Int为参数的函数。
下面是一个map的指明类型写法
map : (a -> b) -> List a -> List b
map f list =
// ...
这里的括号是不可以省略的因为f的类型是**(a -> b),即一个函数接受一个a**类型的参数,返回一个****b类型的结果。
这里的a可以是任何类型。当类型是大写开头的时候,是一个明确的类型,如Int,String。当时小写时候它可以代表任何类型,这里的a可以是String也可以是Int。
如果你看到**(a->a)**这意味着传入类型和输出类型必须是一致的。和他们具体的值是什么没有关系,但数据类型必须相同。
在map中我们有**(a->b)**。意味着这里允许返回与传入参数不一样的数据类型的结果,当然也允许返回相同类型了。
但是一旦a的类型是确定的时候,那所有a的地方都必须是相同的类型
(Int -> String) -> List Int -> List String
这里的所有a都被替换成了Int,所有的b都被替换成了String
List Int类型的意思是这个是个以Int为子项的链表,List String同理。这跟Java或者其他编程语言中的概念是一样的。
接下来路在何方?

现在你已经知道所有函数式编程的好处了,你或许会想,“那接下来要怎样呢?我该如何才能将这些运用到我日常的工作中?”
这其实取决于你自己。如果你可以用Elm或者Haskell这样的纯函数式编程语言的话,你就可以利用本学所学到的内容了。这些语言都能轻松实现。
但是如果你只能用交互式编程语言如Javascript来做日常开发,我相信大部分人都是,你依然可以使用一小部门本文所讲到的内容,但需要记住一些原则。
Javascript函数式编程

Javascript其实有很多功能让你做到函数式编程。虽然不能做到具有百分百的纯净度但至少可以通过其语言特性或者第三方库去实现不变性。
这不是最理想的情况,但如果你必须使用它的时候,为什么不去享受函数式编程带来的好处呢?
不变性
第一个需要考虑的就是不变性,在ES2015(ES6)中有一个关键字const。它表示常量,即一旦被声明就不可被改变。
const a = 1;
a = 2; // this will throw a TypeError in Chrome, Firefox or Node
// but not in Safari (circa 10/2016)
这就是一个例子,a定义好以后重新赋值会抛错。
问题就是const在javascript中并不是执行得足够严格,看下面的例子
const a = {
x: 1,
y: 2
};
a.x = 2; // NO EXCEPTION!
a = {}; // this will throw a TypeError
当你执行a.x = 2依然能成功而不会抛错。它只能在a被重新赋值的时候抛错,也就是a所指向的内存不可被修改。
这其实是有点让人觉得有点失望的,因为const原本其实能让Javascript在函数式编程的道路上走得更远。
那我们如何用javascript实现不变性?
遗憾的是。我们只能通过一个第三方的库Immutable.js来实现,但是最后写出来的代码看起来更像Java而不是Javascript了。
柯里化与模块化
之前我们讲到函数柯里化,下面有个更加复杂一些的例子
const f = a => b => c => d => a + b + c + d
当我们调用时
console.log(f(1)(2)(3)(4)); // prints 10
这么多的参数足以让Lisp程序员当场大哭。
有一些第三方的库会让这些变得更简单,我个人最喜欢的是Ramda
const f = R.curry((a, b, c, d) => a + b + c + d);
console.log(f(1, 2, 3, 4)); // prints 10
console.log(f(1, 2)(3, 4)); // also prints 10
console.log(f(1)(2)(3, 4)); // also prints 10
虽然这个函数定义没有好太多,但是起码我们消除了对那些括号的需要。并且注意到f函数可以以各种形式接收参数。
通过使用Ramda我们改写一下之前提到的mult5AfterAdd10
const add = R.curry((x, y) => x + y);
const mult5 = value => value * 5;
const mult5AfterAdd10 = R.compose(mult5, add(10));
我们会发现Ramda还有许多很有帮助的函数去适应不同的场景,例如R.add和R.multiply,意味着我们可以写更简洁的代码
const mult5AfterAdd10 = R.compose(R.multiply(5), R.add(10));
Map, Filter 和 Reduce
Ramda同样提供map,filter和reduce的函数。虽然这些在原生的Javascript的Array.prototype中,不过Ramda的版本是柯里化的。
const isOdd = R.flip(R.modulo)(2);
const onlyOdd = R.filter(isOdd);
const isEven = R.complement(isOdd);
const onlyEven = R.filter(isEven);
const numbers = [1, 2, 3, 4, 5, 6, 7, 8];
console.log(onlyEven(numbers)); // prints [2, 4, 6, 8]
console.log(onlyOdd(numbers)); // prints [1, 3, 5, 7]
这里面R.modulo接收两个参数,第一个是要被分割的内容,第二个参数是分隔符。
isOdd函数是将剩余部分一直与2相除,如果最后结果是0则返回false,非奇数。如果是最后结果是1则返回true,非偶数。我们用R.flip调换了R.modulo第一和第二个参数的位置所以能够在最后能接受一个2作为分隔符的参数生成isOdd函数。
ieEven的原理和isOdd一样。
onlyOdd函数是一个filter函数,通过传入的函数去判断奇偶。它等待它的最后一个参数,数组的传入,然后执行。
onlyEven是一个使用isEven为筛选条件的filter函数。
当我们将数字类型的参数传递给onlyEven和onlyOdd的时候,isEven和isOdd会得到这个参数并且执行返回我们期待的结果。
Javascript的缺陷

Javascript伴随着所有的第三方库与语言的增加走到今天,证明一个事实是,我们希望用交互式的编程语言解决所有的问题。
大部分前端开发工程师在基于浏览器的原因被迫使用Javascript,因为这几乎是他们至今为止唯一的选择。但是也有很多开发人员已经放弃直接使用Javascript来开发。
相反的,他们使用不同的编程语言与编译器,或者更加准确地说,他们选择了Javascript的过渡语言。
CoffeeScript就是第一个这种语言的例子。而现在Typescript已经可以直接被Angular2识别。当然,Babel也是一个很好的将其转换成Javascript的办法。
已经有很多人正在他们的生产环境使用上述语言。
但是这些语言其实还是基于Javascript的,所以只是表面上看上去稍微好一些。那为什么我们不将一门纯函数式编程的语言转化成Javascript呢?
安利一波Elm

在这篇文章里面我们一直用Elm来帮助大家理解函数式编程。
那么Elm到底是什么?我是怎么使用它的?
Elm是一个纯函数式编程语言并且能编译成Javascript所以你可以使用它来做Web应用的开发通过The Elm Architecture,也就是TEA(这种架构启发了Redux的开发)
Elm程序没有任何运行时的错误。
并且已经有一些公司在他们的生产环境使用Elm,比如NoRedInk,是Elm创始人 Evan Czapliki现在工作的地方。(他之前任职于Prezi)
这边由Richard Feldman创作的视频有详细介绍Elm在生产环境中的6个月。
那我必须将我所有的Javascript替换成Elm吗?
不是的,你可以逐步地替换。这篇文件有介绍更多。如何在工作中使用Elm。
译者:这些文章和视频需要翻墙才能打开
为什么我要学习Elm?
-
用纯函数编程语言是自由但又有限制的。它会限制你只可以做什么(大部分限制是为了让你不给自己挖坑),而与此同时,它能让你在很多bug以及坏的设计习惯中解放出来,因为所有的Elm项目都遵循Elm体系架构的,我们称这种架构为Functionally Reactive Model。
-
函数式编程会让你成为一个更加出色的代码工程师。本文中提到的一些函数式编程的好处只是冰山一角。你如果真切将其用到你项目上你会发现你的程序会变得更小同时又更加稳定
-
Javascript是用10天构建出来的并且用了20年的演变成了现在一部分函数式编程,一部分面向对象变成并且它是一门完全的交互式编程语言。而Elm是从过去30年Haskell社区的成长经验中总结而来。Haskell过去十年在机器学习与计算机科学领域有非常杰出的贡献。Elm的体系架构(TEA)是多年来不断设计与完善的结果,基于Evan在函数式编程领域的论文,查看视频Controlling Time and Space有详细介绍。
-
Elm是专门为前端工程师设计的,目标是为了让我们的工作更加的容易。可以查看视频Let’s Be Mainstream来更好的理解这个目标。
未来

我们不能确定未来是怎样,但是我们能做一些推测,下面是我的一些猜想
其他语言编程成Javascript
函数式编程这个40年前的就提出来的概念会被我们重新利用起来解决目前复杂的工程问题
硬件层面上,GB级别的的廉价内存和高速处理器就能以让人满意的表现运行函数式编程编写的程序
CPU不会再变得更加快但是核数会越来越多
可变的状态会被人们认为是一个复杂系统中最大的问题
我写了这个系列的文章是因为我相信函数式编程是未来所需,也因为在过去几个年的时间我花了很多时间去学习它并且依然在学习中。
我的目标是帮助更多的人更容易地去里面这些概念,来让他们在未来的工作中变得更加出色。
虽然未来是不确定的,但我始终相信Elm是一门非常出色的语言,并且函数式编程与Elm在未来肯定会占有很重要的位置。
我希望你读完这系列文章以后,你能对自己函数式编程的理解以及能力变得更加的自信。
也希望你能给我一个小心心来鼓励我继续写更多好的文章。
如果你希望加入函数式编程的Web开发社区学习并且帮助更多的Web开发人员去学习使用Elm进行函数式编程,你可以关注facebook小组,Learn Elm Programming
作者Twitter:@cscalfani
