

再快不能快基础,再烂不能烂语言!
【基础篇】-集合
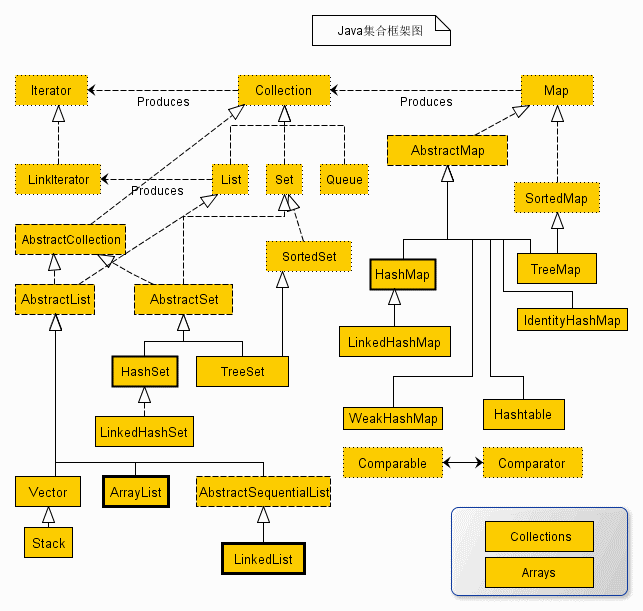
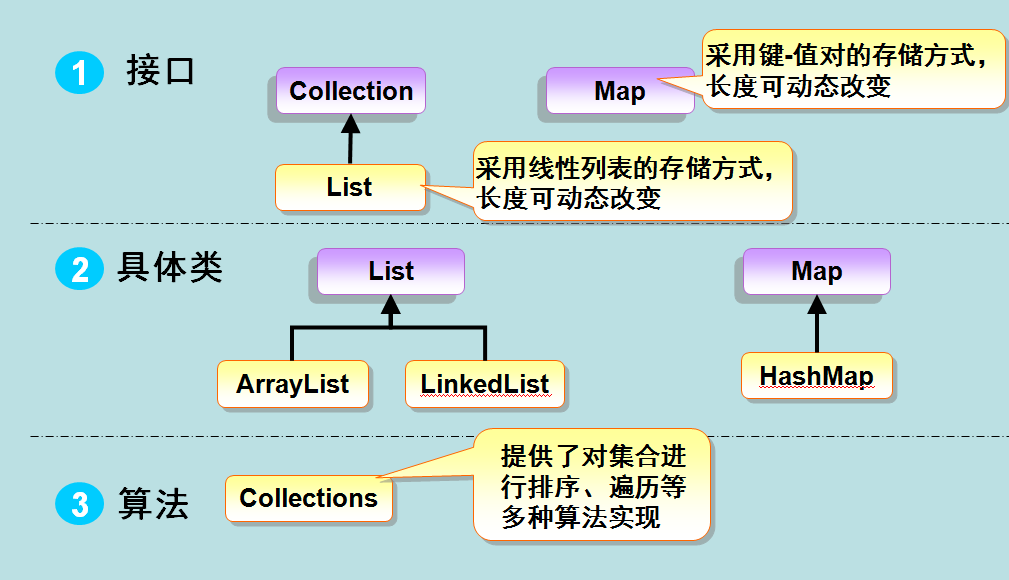
-
List 和 Set 区别
List,Set都是继承自Collection接口,List特点:有序可重复,Set特点:无序不可重复,重复元素会覆盖掉
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。<实现类有HashSet,TreeSet>
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。<实现类有ArrayList,LinkedList,Vector>
-
List 和 Map 区别
List是对象集合,允许对象重复。
Map是键值对的集合,不允许key重复。
-
Arraylist 与 LinkedList 区别
Arraylist:
优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景
缺点:因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
-
ArrayList 与 Vector 区别
public ArrayList(int initialCapacity)//构造一个具有指定初始容量的空列表。 public ArrayList()//构造一个初始容量为10的空列表。 public ArrayList(Collection<? extends E> c)//构造一个包含指定 collection 的元素的列表public Vector()//使用指定的初始容量和等于零的容量增量构造一个空向量。 public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。 public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量 public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量ArrayList和Vector都是用数组实现的,主要有这么三个区别:
-
Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
-
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
-
Vector可以设置增长因子,而ArrayList不可以。
-
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
适用场景分析:
-
Vector是线程同步的,所以它也是线程安全的,而ArrayList是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用ArrayList效率比较高。
-
如果集合中的元素的数目大于目前集合数组的长度时,在集合中使用数据量比较大的数据,用Vector有一定的优势。
-
-
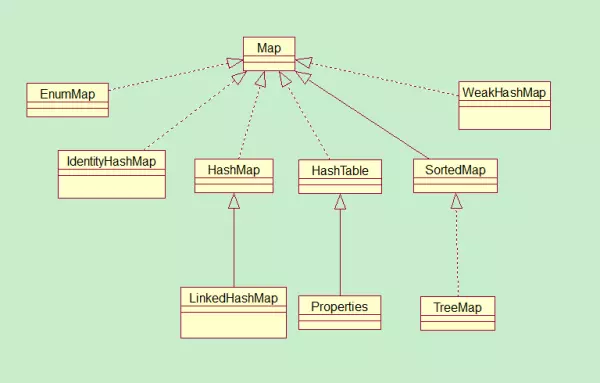
HashMap 和 Hashtable 的区别
-
hashMap去掉了HashTable 的contains方法,但是加上了containsValue()和containsKey()方法。
-
hashTable同步的,而HashMap是非同步的,效率上逼hashTable要高。
-
hashMap允许空键值,而hashTable不允许。
注意:
- TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
- Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
-
-
HashSet 和 HashMap 区别
set是线性结构,set中的值不能重复,hashset是set的hash实现,hashset中值不能重复是用hashmap的key来实现的。
map是键值对映射,可以空键空值。HashMap是Map接口的hash实现,key的唯一性是通过key值hash值的唯一来确定,value值是则是链表结构。
他们的共同点都是hash算法实现的唯一性,他们都不能持有基本类型,只能持有对象
-
HashMap 和 ConcurrentHashMap 的区别
ConcurrentHashMap是线程安全的HashMap的实现。
- ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的syn关键字锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。
- HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
-
HashMap 的工作原理及代码实现
-
ConcurrentHashMap 的工作原理及代码实现
HashTable里使用的是synchronized关键字,这其实是对对象加锁,锁住的都是对象整体,当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。
ConcurrentHashMap算是对上述问题的优化,其构造函数如下,默认传入的是16,0.75,16。
public ConcurrentHashMap(int paramInt1, float paramFloat, int paramInt2) { //… int i = 0; int j = 1; while (j < paramInt2) { ++i; j <<= 1; } this.segmentShift = (32 - i); this.segmentMask = (j - 1); this.segments = Segment.newArray(j); //… int k = paramInt1 / j; if (k * j < paramInt1) ++k; int l = 1; while (l < k) l <<= 1; for (int i1 = 0; i1 < this.segments.length; ++i1) this.segments[i1] = new Segment(l, paramFloat); } public V put(K paramK, V paramV) { if (paramV == null) throw new NullPointerException(); int i = hash(paramK.hashCode()); //这里的hash函数和HashMap中的不一样 return this.segments[(i >>> this.segmentShift & this.segmentMask)].put(paramK, i, paramV, false); }ConcurrentHashMap引入了分割(Segment),上面代码中的最后一行其实就可以理解为把一个大的Map拆分成N个小的HashTable,在put方法中,会根据hash(paramK.hashCode())来决定具体存放进哪个Segment,如果查看Segment的put操作,我们会发现内部使用的同步机制是基于lock操作的,这样就可以对Map的一部分(Segment)进行上锁,这样影响的只是将要放入同一个Segment的元素的put操作,保证同步的时候,锁住的不是整个Map(HashTable就是这么做的),相对于HashTable提高了多线程环境下的性能,因此HashTable已经被淘汰了。
更详细的面试总结链接请戳:👇👇
juejin.cn/post/684490…
| 【推荐篇】- 书籍内容整理笔记 | 链接地址 |
|---|---|
| 【推荐】【Java编程思想】【笔记】 | juejin.cn/post/684490… |
| 【推荐】【Java核心技术 卷Ⅰ】【笔记】 | juejin.cn/post/684490… |
若有错误或者理解不当的地方,欢迎留言指正,希望我们可以一起进步,一起加油!😜😜
