

始
树形数据结构的组件似乎并不是前端组件库所必须的,不过一旦遇到相关需求,比如需要展示一个部门下的职称层级结构,就无可避免需要用到。虽然相关的组件涉及到算法,但不要担心,涉及到的都是最基础很简单的搜索算法。
理解本篇文章需要知道的知识点
- 递归
深度搜索和广度搜索- js的
引用类型与基本类型
理解后能收获的知识
- 树的
增删改查 - 树的
克隆以及一些小技巧 - 能更好地理解js对象的
深拷贝 - 对
ReactDiff算法更深的理解
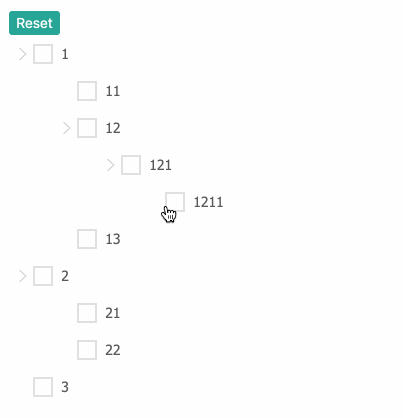
开始设计
以下例子均已React为例实现一个Tree组件以及一些周边辅助操作,用其他UI框架差别不大。
输入
我们的Tree组件接受树形数据结构的输入,一个普通的树形数据结构,其中的节点包含id,pid,children这几个基本信息。就像这样:
const Tree = {
id: 0,
ch: [{
pid: 0,
id: 1,
ch: [{
pid: 1,
id: 11
}, {
pid: 1,
id: 12,
ch: [{
pid: 12,
id: 121,
ch: [{
pid: 121,
id: 1211
}]
}]
}, {
pid: 1,
id: 13
}]
}]
};
渲染树(输出)
拿到这样的数据结构后,应该怎样渲染出来呢?这很好解决,React是支持组件自身递归调用自身这种情况的,只要在遍历树的过程中像这样去调用一下就ok了。
// 就是普通的递归遍历
// treeNode.jsx
class TreeNode extends Component{
render(){
const children = this.props.data.ch;
return <div>
{
children.map((item, index) => {
if (item.ch) {
{
this.props.item(item)
}
<TreeNode data={item}/>
}else{
return <div>
{
this.props.item(item)
}
</div>
}
}
}
</div>
}
}
效果:

出乎意料的顺利,到这里我们已经完成了Tree组件的基本功能了(即拿到数据之后,将树结构展示出来)。但仔细一想,仅仅有展示功能似乎作用不大,通常Tree组件都是有交互的,那怎么办呢?
查找节点
先从最基础的一个功能开始讲起,如果想要点选其中一个节点一个怎样做呢?同时这个功能通常会有一个附加要求,需要把沿途的节点也记录下来。
嗯没错,跟你想的一样,递归形式的深度搜索+一个栈结构就可以轻松解决这个问题。

Tree.getNodeRoute = (searchNode = {}, node = { id: 0 }) => {
const stack = [];
const dfs = (tree) => {
if (tree.ch) {
//通过Object.assign创建新对象同时合并旧对象属性
stack.push(Object.assign({}, { ...tree }, { ch: [] }));
//处理父节点
//如果找到该节点,就退出递归
//此时stack中的内容就是由从根节点出发,到该节点沿途所经过的节点组成。
if (tree.id == searchNode.id) {
return false;
}
const children = tree.ch;
for (let i = 0; i < children.length; i++) {
const child = children[i];
const flag = dfs(child);
if (!flag) {
return false;
}
}
} else {
stack.push(Object.assign({}, { ...tree }));
//处理叶子节点
if (tree.id == searchNode.id) {
return false;
}
}
stack.pop();
return true;
};
dfs(node);
return stack;
};
树结构扁平化和构建树
接下来介绍一个很重要也很实用的一个知识点,在list或者tree结构中如果要获取一个节点,需要一次次去遍历寻找相匹配的节点,这很麻烦,也不高效。我们可以先将list/tree结构的节点映射到一个对象中,这样就可以根据对象的下标直接找到对应的节点啦,就像这样。
//一棵扁平化的树
const nodeList=[{
id:0,
},{
pid:0,
id:1
},{
pid:1,
id:2
},{
pid:2,
id:3
},{
pid:0,
id:4
}]
Tree.getNodeList2Map = (nodeList = []) => {
const map = {};
//转化为Map结构
nodeList.forEach((item) => {
map[item.id] = item;
});
return map;
};
Tree.getNodeById = (id, node = { id: 0 }) => {
const map = Tree.getNodeList2Map(Tree.getTree2List(node));
return map[id] ? map[id] : undefined;
};
运用这个技巧在构建树的时候就很方便了。
//树的构建
Tree.buildTree = (nodeList = []) => {
//创建map,方便根据id/pid引用相关对象
if (nodeList && nodeList.length) {
const map = Tree.getNodeList2Map(nodeList);
for (let i = 0; i < nodeList.length; i++) {
const item = nodeList[i];
if (map[item.pid]) {
map[item.pid].ch ? map[item.pid].ch.push(item) : map[item.pid].ch = [item];
}
}
}
for (let i = 0; i < nodeList.length; i++) {
const item = nodeList[i];
if (!item.id) {
return nodeList[i];
}
}
return nodeList && nodeList[0];
};
//树的扁平化
Tree.getTree2List = (node, isDeep = false, attr = {}) => {
//isDeep用来标识是否同时克隆这个list,否则只复制其引用
//广度遍历目标树
const queue = [];
const stack = [];
queue.push(node);
while (queue.length) {
const item = queue.shift();
if (item.ch) {
isDeep ? stack.push(Object.assign({}, { ...item }, { ch: [], ...attr })) : stack.push(Object.assign(item, { ...attr }));
queue.unshift(...item.ch);
} else {
isDeep ? stack.push(Object.assign({}, { ...item }, { ...attr })) : stack.push(Object.assign(item, { ...attr }));
}
}
return stack;
};
//变更节点属性
Tree.addAttr2Tree = (node = { id: 0 }, attr = { checked: true }) => {
const nodeList = Tree.getTree2List(node, false, attr) || [];
return nodeList[0];
};
删除节点
删除功能也能用到这个技巧,这样我们只需要通过id就可以找到对应节点的父节点,然后通过父节点做删除操作。

Tree.delNode = (targetNode, tree = { id: 0 }) => {
const nodeList = Tree.getTree2List(tree);
const map = Tree.getNodeList2Map(nodeList);
const pNode = map[targetNode.pid];
if (pNode && pNode.ch) {
for (let i = 0; i < pNode.ch.length; i++) {
const elem = pNode.ch[i];
if (elem.id == targetNode.id) {
pNode.ch.splice(i, 1);
}
}
}
return tree;
}
克隆树
我们可以先将树扁平化成列表再clone,这样思路就转变为clone一个内容都是引用类型的数组,之后直接在新数组的基础上调用一下上面的buildTree就ok了。用这种方法有一个前提,这里的cloneTree与js中的clone一个对象是有很大不同的,cloneTree不考虑循环引用的情况,同时节点也只有一种类型。
Tree.cloneTree = (node = { id: 0 }, isDeep = true) => {
const nodeList = Tree.getTree2List(node, isDeep);
return Tree.buildTree(nodeList);
};
到目前为止,树的增删改查和其他的一些辅助操作都涉及到了,我们的Tree组件也逐渐完善,可以讲能够应付大部分的相关需求了。而且有了这些基础原料之后,我们就可以发挥想象力和创造力去写更多有趣的组件。
React Diff算法
不要急,React的Diff算法就是两棵节点树的比较算法。如果理解了以上树的相关操作,那么应用在React虚拟Dom中的Diff算法就非常好理解了。
举一个非常简单的例子。
class ChangeState extends Component{
constructor(){
super()
this.state={
open:true
}
}
render(
const { open } =this.state
return (
<div>
<button onClick={()=>this.setState({open:!open})>Trigger</button>
{
open?<span>say hello</span>:null
}
</div>
)
)
}
如果点击了按钮,这个span类型的Dom节点就会消失,那么React又是怎样感知到Dom结构的改变,从而使span节点消失的呢?用一句话来讲,这里state的改变首先会触发react维持在内存中的虚拟Dom树发生改变,然后再通过diff算法计算出最小变更,最后将这些变更更新到浏览器真实的Dom结构上,最终在视觉上我们就能感知都这个span节点消失了。
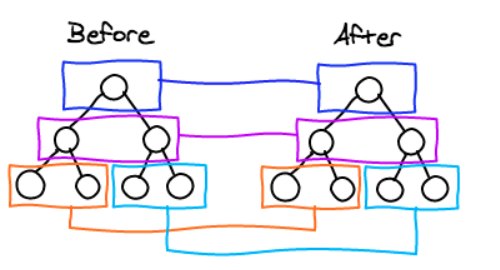
所以这个React的diff算法换成人话讲就是,如何用高效的方法去比较出两颗树的差异。最理想的方法是只需要遍历一次,就可以比较出所有的差异,算法复杂度为O(n)。那应该怎样做呢?先抛开列表索引等其他的优化手段不讲,这里单单讲同层比较,很明显,在遍历虚拟Dom树时,我们可以将真实Dom树同时传入,同时按同一顺序遍历两棵树,找到对应的节点进行比较,在最后生成一系列的‘更新包’应用到真实Dom上或者在更新的过程中直接对真实Dom进行修改,具体的细节可能有不同的地方,但大体思路是不变的。
//乞丐版
function diffNode(domnode, vnode) {
...
if (vnode.children && vnode.children.lenght > 0) {
...
//这里进行对比真实Dom与虚拟Dom
...
for (let i, i < vnode.children.lenght, i++) {
const vnodeChild = vnode.children[i]
const domChild = domnode.children[i]
diffNode(domChild, vnodeChild)
}
} else {
...
//遍历到叶子节点,进行对比真实Dom与虚拟Dom
...
return
}
}
推荐一个很好的学习项目,对细节的理解有很大帮助,simple-react
末
总结
需要注意的细节很多,尤其在处理引用类型的相关问题时,一不留神就可能会出错,将本篇文章讲的内容当做参考,自己动手去实现一下会有更深刻的体会。如果觉得这篇文章对你有帮助,不妨顺便点点赞哈哈。
Tree组件的故事就暂告一段落了,之后会写一下以Tree为基础的穿梭框和点选框组件,这些组件现已集成在SluckyUI For React中,SluckyUI的理念是打造一个组件库种子,让其他开发者能够进行快速二次开发,减少不必要的造轮子,但当中的编写任重而道远,还有很多尚不完善的地方,欢迎多多交流加入SluckyUI。
源码&在线Demo
Tree组件源码&&样式,可以在SluckyUI中的‘操作树&穿梭框’标签下查看在线Demo。
从零开始系列传送门
- 《Re从零开始的UI库编写生活之规范制定》
- 《Re从零开始的UI库编写生活之按钮》
- 《Re从零开始的UI库编写生活之表单》
- 《Re从零开始的UI库编写生活之表格组件》
- 《Re从零开始的UI库编写生活-步骤管理组件Steps》
- 《Re从零开始的后端学习之配置Ubuntu+Ngnix+Nodejs+Mysql环境》
- 《Re从零开始的后端学习之配置LAMP环境》
