

月: 听说你这次分享 jq
我: 恩,是了
月:这有啥好分享的,现在大家都用 react/vue 了
我: ......
我: 给你官网链接 github.com/stedolan/jq
月: 原来是命令行下的 json 美化工具,好像也没啥可分享的
我: ......
我: 可以用它分析 nginx 的日志,比如用 json 表示 nginx 的日志
月: 线上的ELK它不好用吗?还是分布式的,又有索引,还快,就连查询语句都有自动补全
我: 好像有点道理...
我: 我还可以用它做爬虫!!!
谨以此篇文章讲述 jq 的实际使用案例,如果能提高你使用命令行的乐趣那更再好不过了。关于 jq 的用法可以参考我以前的文章: jq命令详解及示例
- 原文地址: 使用 jq 与 sed 制作掘金面试文章榜单
- 系列文章: 个人服务器运维指南
预览
使用以下命令,可以直接获取前端面试榜单
$ curl -s 'https://web-api.juejin.im/query' -H 'Content-Type: application/json' -H 'X-Agent: Juejin/Web' --data-binary '{"operationName":"","query":"","variables":{"tags":["55979fe6e4b08a686ce562fe"],"category":"5562b415e4b00c57d9b94ac8","first":100,"after":"","order":"HOTTEST"},"extensions":{"query":{"id":"653b587c5c7c8a00ddf67fc66f989d42"}}}' --compressed | \
jq -c '.data.articleFeed.items.edges | .[].node | { likeCount, title, originalUrl } | select(.likeCount > 600) ' | jq -cs '. | sort_by(-.likeCount) | .[] | "+ 【👍 \(.likeCount)】[\(.title)](\(.originalUrl))"' | sed s/\"//g
+ 【👍 5059】[一个合格(优秀)的前端都应该阅读这些文章](https://juejin.cn/post/6844903896637259784)
+ 【👍 4695】[2018前端面试总结,看完弄懂,工资少说加3K | 掘金技术征文](https://juejin.cn/post/6844903673009553416)
+ 【👍 4425】[中高级前端大厂面试秘籍,为你保驾护航金三银四,直通大厂(上)](https://juejin.cn/post/6844903776512393224)
+ 【👍 3013】[2018春招前端面试: 闯关记(精排精校) | 掘金技术征文](https://juejin.cn/post/6844903570001625102)
+ 【👍 2493】[前端面试考点多?看这些文章就够了(2019年6月更新版)](https://juejin.cn/post/6844903577220349959)
获取掘金列表接口
先来看看 http 的 url: https://web-api.juejin.im/query,用的 POST
再看看 body:
{
"operationName": "",
"query": "",
"variables": {
"first": 20,
"after": "1.0168277174789",
"order": "POPULAR"
},
"extensions": {
"query": {
"id": "21207e9ddb1de777adeaca7a2fb38030"
}
}
}
最后再看看 http 的 response:
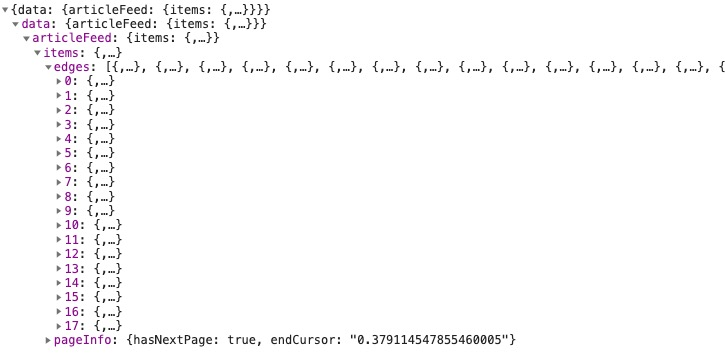
眼前一亮,多么熟悉的数据结构!!!
这不是 graphql 吗,我上个月(2019/10)还写了一系列文章介绍它: 使用 graphql 构建 web 应用,一年前(2018)还用 graphql 写了一套诗词的前后端: shfshanyue/shici 与 shfshanyue/shici-server
怎么看出来是 graphql 的呢?
/query这是统一的入口extensions.query.id这是APQ,为了缓存gql,减少传输体积,减短网络时延,有利于缓存,当然也减少了安全性问题variables这是graphql variablesdata.items[].edges这是graphql典型的分页 (虽然我不太喜欢,嵌套数据太多...)
恩,好像跑偏了
总之,拿到了数据--关于前端面试的数据
$ curl -s 'https://web-api.juejin.im/query' -H 'Content-Type: application/json' -H 'X-Agent: Juejin/Web' --data-binary '{"operationName":"","query":"","variables":{"tags":["55979fe6e4b08a686ce562fe"],"category":"5562b415e4b00c57d9b94ac8","first":100,"after":"","order":"HOTTEST"},"extensions":{"query":{"id":"653b587c5c7c8a00ddf67fc66f989d42"}}}' --compressed
ETL
还是 etl 这个词高大上啊
先用 jq 取几个数吧: 标题与点赞数。更多用法可以参考我以前的文章: jq命令详解及示例
为了更容易看到 jq 的用法,把 jq 另起一行,其中
-c: 一整行显示.[]: json-array to jsonl{}: 类似于lodash.pick
我们此时根据命令获取到所有高赞文章,但它此时是无序的
$ curl -s 'https://web-api.juejin.im/query' -H 'Content-Type: application/json' -H 'X-Agent: Juejin/Web' --data-binary '{"operationName":"","query":"","variables":{"tags":["55979fe6e4b08a686ce562fe"],"category":"5562b415e4b00c57d9b94ac8","first":100,"after":"","order":"HOTTEST"},"extensions":{"query":{"id":"653b587c5c7c8a00ddf67fc66f989d42"}}}' --compressed | \
jq -c '.data.articleFeed.items.edges | .[].node | {title, likeCount}'
{"title":"中高级前端大厂面试秘籍,为你保驾护航金三银四,直通大厂(上)","likeCount":4423}
{"title":"2018前端面试总结,看完弄懂,工资少说加3K | 掘金技术征文","likeCount":4690}
{"title":"一个合格(优秀)的前端都应该阅读这些文章","likeCount":5052}
{"title":"前端面试考点多?看这些文章就够了(2019年6月更新版)","likeCount":2492}
{"title":"2018春招前端面试: 闯关记(精排精校) | 掘金技术征文","likeCount":3013}

数据筛选与排序
再来筛选下点赞数大于 600 的
select(.likeCount > 600)
再来倒排个序
jq -s '. | sort_by(-.likeCount) | .[]'
搞定,此时榜单上全是点赞数大于600且排好序的
$ curl -s 'https://web-api.juejin.im/query' -H 'Content-Type: application/json' -H 'X-Agent: Juejin/Web' --data-binary '{"operationName":"","query":"","variables":{"tags":["55979fe6e4b08a686ce562fe"],"category":"5562b415e4b00c57d9b94ac8","first":100,"after":"","order":"HOTTEST"},"extensions":{"query":{"id":"653b587c5c7c8a00ddf67fc66f989d42"}}}' --compressed | \
jq -c '.data.articleFeed.items.edges | .[].node | {title, likeCount, originalUrl } | select(.likeCount > 600) ' | jq -s '. | sort_by(-.likeCount) | .[]'
{
"title": "一个合格(优秀)的前端都应该阅读这些文章",
"likeCount": 5052,
"originalUrl": "https://juejin.cn/post/6844903896637259784"
}
{
"title": "2018前端面试总结,看完弄懂,工资少说加3K | 掘金技术征文",
"likeCount": 4690,
"originalUrl": "https://juejin.cn/post/6844903673009553416"
}
{
"title": "中高级前端大厂面试秘籍,为你保驾护航金三银四,直通大厂(上)",
"likeCount": 4423,
"originalUrl": "https://juejin.cn/post/6844903776512393224"
}

使用 sed 处理生成 markdown
我们此时已经生成了结构化的数据,如果我们使用 react 渲染数据的话,json 自然不错。但我们现在需要生成 markdown,所以再处理处理
先使用 jq 生成链接样式
"+ 【👍 \(.likeCount)】[\(.title)](\(.originalUrl))"
在使用 sed 删除全部双引号,关于 sed,可以参考我的文章: sed 命令详解及示例
sed s/\"//g
此时,成功生成了 markdown 数据
$ curl -s 'https://web-api.juejin.im/query' -H 'Content-Type: application/json' -H 'X-Agent: Juejin/Web' --data-binary '{"operationName":"","query":"","variables":{"tags":["55979fe6e4b08a686ce562fe"],"category":"5562b415e4b00c57d9b94ac8","first":100,"after":"","order":"HOTTEST"},"extensions":{"query":{"id":"653b587c5c7c8a00ddf67fc66f989d42"}}}' --compressed | \
jq -c '.data.articleFeed.items.edges | .[].node | { likeCount, title, originalUrl } | select(.likeCount > 600) ' | jq -cs '. | sort_by(-.likeCount) | .[] | "+ 【👍 \(.likeCount)】[\(.title)](\(.originalUrl))"' | sed s/\"//g
+ 【👍 5059】[一个合格(优秀)的前端都应该阅读这些文章](https://juejin.cn/post/6844903896637259784)
+ 【👍 4695】[2018前端面试总结,看完弄懂,工资少说加3K | 掘金技术征文](https://juejin.cn/post/6844903673009553416)
+ 【👍 4425】[中高级前端大厂面试秘籍,为你保驾护航金三银四,直通大厂(上)](https://juejin.cn/post/6844903776512393224)
+ 【👍 3013】[2018春招前端面试: 闯关记(精排精校) | 掘金技术征文](https://juejin.cn/post/6844903570001625102)
+ 【👍 2493】[前端面试考点多?看这些文章就够了(2019年6月更新版)](https://juejin.cn/post/6844903577220349959)
+ 【👍 2359】[「中高级前端面试」JavaScript手写代码无敌秘籍](https://juejin.cn/post/6844903809206976520)
我是山月,一个喜欢跑步与爬山的程序员,我会定期分享全栈文章在个人公众号中。如果你对全栈面试,前端工程化,graphql,devops,个人服务器运维以及微服务感兴趣的话,可以关注我

