

前言
最近想深入了解一下vue.js(后面简称vue)的核心原理,无意中看到了一个用于学习vue原理的项目。在深入了解之后,发现它短小精悍,对于渐进式地了解vue的核心原理的实现大有帮助,于是乎就正式开始了对它探索之旅。
概念
概念代表着人类意识上的共识。所以,要想通过沟通交流来产生一些成果,对同一个概念达成共识是十分必要,要不然就是鸡跟鸭讲,不知所云。在对vue原理的了解过程中,需要了解哪些概念呢?下面,我们一起来梳理一下。
DocumentFragment
准确来讲,DocumentFragment是一个web API。因为它几乎成为了高效地操作大批量dom节点的代名词,而vue在模板解析的实现里面也用到了它,所以我们有必要了解它。
The following interfaces all inherit from Node’s methods and properties: Document, Element, Attr, CharacterData (which Text, Comment, and CDATASection inherit), ProcessingInstruction, DocumentFragment, DocumentType, Notation, Entity, EntityReference
因为我们最常用的Element API 和DocumentFragment API都是继承自Node这个接口,所以,DocumentFragment对象与普通的Element对象拥有这相同的方法和属性。从这个角度来看,DocumentFragment对象跟普通的Element对象是“一样”的。
但是从全方位的角度来看,这两者是不一样的。从表象看来,DocumentFragment对象与Element对象有两个不同点:
- DocumentFragment对象没有
parent node。即使你将它append到文档中的一个element中去,这个element并不能成为它的parent node。 - 与Element对象不同的是,对DocumentFragment对象执行相关的DOM操作并不会马上反应到界面上,也即是说不会引起reflow和render(或者说layout和paint)。 下面我们一起来看看简单的示例代码:
const FG = document.createDocumentFragment();
const textNode = document.createTextNode('hello,documentFragment');
FG.appendChild(textNode) // 在这一步,界面并不会得到更新
document.body.appendChild(FG); // 直到把它append到真实的文档流,界面才会有反应
console.log(FG.parentNode) // 虽然FG插入到真实的文档中了,但是FG.parentNode仍然为null
上面说的是表面现象。那造成这种差异表象的本质原因是啥呢?答曰:“本质原因是DocumentFragment对象并不是真实文档流的一部分,它只常驻在内存当中的。”所以,我们可以这么理解:它只是dom节点的暂存器,当你把它(指的是DocumentFragment对象)append或者insert到真实文档流的时候,它把自己所有的一切都掏空,还给真实的文档流,然后自己功成告退。
基于这个DocumentFragment对象这个特质,很多类库用它进行大批量dom节点操作,vue也不例外。
模板
模板是将一个事物的结构规律予以固定化、标准化的成果,它体现的是结构形式的标准化。
在vue这个类库里面,模板有三种类型:
- DOM模板
- 字符串模板
- 单文件模板
无论是哪种类型“模版”,它本质上就是“HTML模板”-一堆由html标签和特殊占位字符组成的标记。这里的“html标签”代表着的就是一种固化的页面结构,而“特殊占位字符”组成就是一套“模板语法”。
“模板”都是要被解析(或者说编译)的,而解析的对象就是那些“特殊占位字符”。在vue里面,江湖人称之为“魔符”。最后,负责实现解析功能的那些代码我们称之为“模板引擎”。从jquery时代的mustache和handlerbar到现在的angular和vue,“模板”一直伴随我们左右。从使用者的角度来看,它们是不一样的。但是从实现者的角度来看,它们都是一样的,都是“模板语法” + “模板引擎”。
因为这个mvvm类库是用于学习vue的原理的,所以,我们得假设“模版语法”已经设计好了。我们需要思考的问题就是:“给定一套模板语法的前提下,我们该如何编程实现该模板的模板引擎呢?”。
注意:该学习库为代码的精简,实现上做了调整。
- 把属性绑定指令名中的“bind:”去掉了。也就是说原本的“v-bind:class”变为现在的 “v-class”。
- 只实现了几个最基本的属性绑定指令(“v-text”,“v-class”,“v-html”,“v-model”)和事件绑定指令(v-on:xxx)。
表达式
表达式(expression)是JavaScript中的一个短语,JavaScript解释器会将其计算(evaluate)出一个结果。
JavaScript犀牛书如是说。换而言之,一切能计算出值的语句都是表达式。
在vue模板里面,无论双重花括号里面的字符串还是属性绑定指令值,都是表达式。而表达式的核心要素就是[变量],这个变量就是对应于某个viewModel实例属性。如果A使用B,我们就说“A依赖B”的话,那么我们可以将上面的表述转化为这样结论:“在vue里面, [模板]依赖[表达式],[表达式]依赖[viewModel实例属性]”。其实,更深入地讲[表达式]依赖的是我们实例化vue对象时传入的data对象的属性。只不过,在后期,我们将data对象的属性代理到viewModel实例属性而已。
对表达式概念以及它在模板和viewModel实例之间的枢纽作用的理解是至关重要。因为这一点关系到你对mvvm模式中各个角色命名语义上的理解(比如,源码中“watcher”,“dependency”等等)。
数据代理
讲mvvm模式,自然是离不开数据代理了。那什么是数据代理呢?
数据代理其实就是变量读写的代理,换句话说就是把对原变量的[读和写]交由另外一个变量来完成。举个例子,有个对象,它层次很深:
const obj = {
a:{
b:{
c : 'xxx'
}
}
}
我们每次访问c属性都要通过obj.a.b.c来完成的话,如果次数多了就会显得很麻烦。我们可以将对obj.a.b.c的读写委托到到obj对象新的第一层属性上,也就是说我们写下这么一行代码时候:
obj.c = 'xxx'
js引擎在解析的过程中会帮助我们将读写操作转接到obj.a.b.c身上,实际执行的是一下语句:
obj.a.b.c = 'xxx'
简单的实现如下:
Object.defineProperty(obj,"c",{
get(){
return obj.a.b.c
},
set(value){
obj.a.b.c = value;
}
})
要理解“数据代理”这个概念,具体到这里例子就是要理解obj.a.b.c和obj.c的关系。
废话不多说,我们来总结一下这两者的关系。那就是:obj.a.b.c将自己的“读和写”业务委托给obj.c来完成了,obj.c是obj.a.b.c的代理。
vue2.x之前的数据代理是基于ES5的Object.defineProperty这个API来实现的,我相信这是人尽皆知的啦,这里就不展开说了(听说,3.x是基于原生接口Proxy来实现)。不过,我想强调的一点是,数据代理并不是mvvm模式的必要特征,它只是一个便利之举而已。具体为什么这么说,在分析源码的过程中,我再来解释这其中的理由。
数据绑定
我们天天提“数据绑定”,那么“数据绑定”到底是什么意思?简而言之,在mvvm模式的话题背景下,“数据绑定”就是指将viewModel实例属性绑定到HTML模板中,一旦属性值发生改变,界面就会“自动”更新。时刻注意,“自动”并是真的自动,“自动”是需要我们去用代码去实现的。
我们除了提“数据绑定”外,也经常提“数据单向绑定”和“数据双向绑定”。其实一般来说,“数据单向绑定”就是指我们上面所提到的“数据绑定”(viewModel实例属性 -》 HTML模板),而“数据双向绑定”就是在“数据单向绑定”的基础上增加另外一个方向(HTML模板 -》 viewModel实例属性)的绑定而已。一般来说,“数据双向绑定”只是针对表单元素input,select,textarea等等而已。通过监听这些元素的input事件,在类库的内部手动地给viewModel实例属性赋值就可以实现这个“双向数据绑定”。
时刻记住,“数据双向绑定”是建立在“数据单向绑定”之上的。等会我们在讲解代码实现的时候,我们会先讲如何实现“数据单向绑定”,再讲如何实现“数据双向绑定”就是这个理。
数据劫持
从因果的角度来看,“数据绑定”是一种结果,而数据劫持是达成这种结果的手段。它们两者的关系可以表述为数据绑定是通过数据劫持来实现的。
那么到底什么是“数据劫持”呢?“数据劫持”就是剥夺原变量读写方面的话语权。剥夺之后,我想干嘛就干嘛。具体的话,“数据劫持”还是通过Object.defineProperty这个API来实现的。
const obj = {
a:'xxx',
b:'yyy'
}
Object.defineProperty(obj,"a",{
get(){
// 劫持原属性的读的权利
// 目前我什么都不干
},
set(){
// 劫持原属性的写的权利
// 目前我什么都不干
}
})
console.log(obj.a) // undefined
obj.a = "zzz"
console.log(obj.a) // undefined
这个劫持是完完全全的。什么意思呢?就像上面这个例子那样,我劫持之后,我什么都不干,那就js引擎是不会为此搞个兼容降级的机制(比如说,js引擎一旦判断你getter返回undefined,它会帮你缺省地返回个原来的值“xxx”)。不,它不会这么干的。它是100%地放权给你。这就充分地体现了“劫持”这个词的语义了。
也许你会问:“数据代理和数据劫持都是通过Object.defineProperty这个API来实现的,感觉原理一样啊,它们有什么不同吗?”
答曰:“这两个概念还是不一样的。因为“数据代理”是在对象上产生一个新的属性,而“数据劫持”则是对对象已存在的属性进行重新定义。”刚开始我看源码的时候,也有类似的困惑,后面反复查看这两者的代码实现,才发现两者的不同。如果你有同样的疑问,不怪你,多看几次源码就好了。
到这里,我们将涉及的概念梳理得差不多了,下面我们接着介绍各个功能模块的实现流程。
总体流程
我画的细致化的流程图:

在这里,我把vue这个类库的代码生命周期分为两个阶段: 初始化阶段和运行时阶段。
而初始化阶段又细分为三个小阶段:
- 数据代理阶段
- 数据绑定阶段
- 模板解析阶段。
所以,如上图所示,总共加起来就四个阶段。下面,我们来探讨一下各个阶段的实现流程和原理。
1. 数据代理阶段
这个阶段其实没什么好讲的,其核心原理是Object.defineProperty这个API-即通过这个API来将vm._data的读写权代理到vm的实例属性上。在这里,值得注意的两点是:
- 数据代理并不是mvvm模式的必要特征,它只是一个便利之举而已。
- 数据代理相对数据劫持是不同的。不同点表现为:
- 不像数据劫持需要递归遍历到数据对象的所有层次,数据代理只是针对vm._data的第一层属性代理即可。
- 不像数据劫持是对原有的属性进行重新定义,数据代理是vm实例上生成新的属性。
下面,我们来具体探讨一下以上的两点。
针对第一点,我们来试验一下,看看禁掉数据代理,程序是否还能正常运行。怎么做呢?
第一步:把mvvm.js构造函数MVVM中的与实现数据代理相关的代码注释掉。
第二步:去到Watcher类的get方法里面,把对this.getter方法的调用传参时的第二个参数从“this.vm”替换为"this.vm._data"。
第三步:去到Compile类的bind方法里面,把对this._getVMVal方法的调用传参时的第一个参数从“vm”替换为“vm._data”。
最后,保存更新,刷新页面。你会发现,数据绑定功能并没有受到影响,程序正常运行。这也佐证了我的第一个观点。
只不过,现在你如果想要在改变data的值的时候,你就不能直接对vm实例进行操作了。也就是说,你不能这么写了:this.xxx = 'yyy'或者vm.xxx = 'yyy'。而是,要这么写::this._data.xxx = 'yyy'或者vm._data.xxx = 'yyy'。这么做,我们会面临一个问题。假如,我们要访问的属性处在很深的层次呢?比如:a.b.c, 那么你就得写this._data.a.b.c = 'yyy'或者vm._data.a.b.c = 'yyy'。一次还好,次数多了,就显得不够便利,而一个简单的数据代理就能帮助我们减少一个属性层次,从而让我们的数据访问更加直观。我想,这就是数据代理存在的意义吧。
至于第二点,我们细心地观察【数据代理】和【数据劫持】的实现代码就可以发现。
// 数据代理实现代码
// 这个data就是我们传递到Vue构造函数的的option对象的data字段
Object.keys(data).forEach(function(key) {
me._proxyData(key);
});
_proxyData: function(key, setter, getter) {
var me = this;
setter = setter ||
Object.defineProperty(me, key, {
configurable: false,
enumerable: true,
get: function proxyGetter() {
return me._data[key];
},
set: function proxySetter(newVal) {
me._data[key] = newVal;
}
});
}
// 数据劫持实现代码
Observer.prototype = {
walk: function(data) {
var me = this;
Object.keys(data).forEach(function(key) {
me.convert(key, data[key]);
});
},
convert: function(key, val) {
this.defineReactive(this.data, key, val);
},
defineReactive: function(data, key, val) {
var dep = new Dep();
var childObj = observe(val);
Object.defineProperty(data, key, {
enumerable: true, // 可枚举
configurable: false, // 不能再define
get: function() {
if (Dep.target) {
dep.depend();
}
return val;
},
set: function(newVal) {
if (newVal === val) {
return;
}
val = newVal;
// 新的值是object的话,进行监听
childObj = observe(newVal);
// 通知订阅者
dep.notify();
}
});
}
};
虽然数据代理和数据劫持都是通过Object.defineProperty这个API来实现的,但是两者针对的【对象】(也就是调用时,传递的第一个参数)明显是不一样的。
对于数据代理而言,我们的【对象】是vm实例,而定义的【属性】却是data对象的属性。我们从MVVM的构造函数来看,vm实例在此之前并没有定义这些属性,这些属性在调用Object.defineProperty()方法的时候是不存在的。所以,它们是vm实例的全新属性;而对于数据劫持而言,我们的【对象】是data对象,定义的【属性】还是data对象的属性,所以这是重新定义了。正是这个重新定义,才很好地呼应了“劫持”这个词的语义,不是吗?
至于数据代理和数据劫持所操作的对象属性层次数上差异,主要是体现在数据代理只是进行过一次Object.keys().forEach()调用来遍历data对象的第一层属性。而数据劫持则通过在defineReactive方法里面的var childObj = observe(val);调用,间接递归调用了多次Object.keys().forEach()来实现对data对象所有层次属性的劫持。
到这里,我们通过对比数据劫持特性的实现来将数据代理的实现细节梳理了一遍。可以这么说,数据代理只是mvvm模式的前菜,数据绑定才是它的核心部分,下面一起来瞧瞧它的实现过程。
2. 数据绑定阶段
正如在概念介绍部分所讲的,“数据绑定”是我们要实现的一个结果,它并不是重点。重点是,实现这个结果的手段-数据劫持。所以在这小节,与其说是讲“数据绑定 ”,不如说是讲“数据劫持”。
“数据劫持”的实现代码都放在了observer.js文件里面了。整个文件代码行数不多,但是因为这个类库的作者从vue源码中摘抄得恰到好处,所以显得短小精悍,十分利于阅读。
无论在概念介绍部分,还是上个阶段,我们都对数据劫持的过程简单地介绍了一遍。将这个过程简单地用一句来说,那就是:遍历我们传入data对象的每一层属性,对每一个属性设置相应的访问器(getter和setter)。尽管里面涉及到了稍微复杂一点的【间接递归调用】,但是这个过程还算简单直观,没啥好讲的。我们要讲就要讲在数据劫持过程中所设下的访问器,因为这里面隐藏着一条很重要的的关系链:
dep实例 -》 属性 -》 表达式 -》 watcher实例
纵观初始化阶段,这条关系链的建立分为四个阶段:
- 建立
属性 《-》 表达式的多对多关系(模板书写阶段) - 建立
属性 《-》 dep实例的一对一关系(数据绑定阶段) - 建立
表达式 《-》 watcher实例的一对一关系(模板解析阶段) - 建立
dep实例 《-》 watcher实例的多对多关系(模板解析阶段)
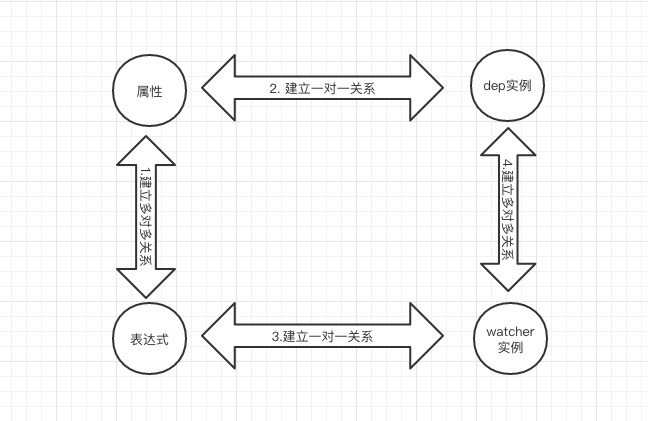
属性与表达式多对多的关系是在我们的模板书写阶段确立的。多对多关系,什么意思呢?意思就是:一个表达式有可能“依赖”或者“使用”多个属性,而同一个属性可以被多个表达式所使用。看具体的例子:
<div>
<div>第一个表达式:{{a.b.c}}</div>
<div>第二个表达式:{{a.b.c}}</div>
<div>第三个表达式:{{a.b.c}}</div>
</div>
我们先只看第一个表达式。因为这个表达式使用了三个属性,分别是“a”,"a.b"和“a.b.c”,所以我们说一个表达式有可能对应多个属性。然后,我们再看模板的全部。同一个属性“a.b.c”被三个表达式所使用,所以我们说一个属性有可能对应多个表达式。
综上所述,属性与表达式是“多对多”的关系。
在数据绑定阶段,之所以要分析属性与表达式的关系,是因为这个关系是整条关系链的根源,是[属性与dep实例的关系]的铺垫。好,现在我们已经讲完了。那么我们可以把重点聚焦到这个阶段所发生的属性与dep实例的关系建立。这个关系的建立是在劫持属性-定义访问器的时候发生的。那么,下面一起来看看相关代码:
Observer.prototype = {
walk: function(data) {
var me = this;
Object.keys(data).forEach(function(key) {
me.convert(key, data[key]);
});
},
convert: function(key, val) {
// 记住,this.data只是vm._data的一个引用
// 引用链是这样的: this.data -> vm.$option.data -> vm._data
this.defineReactive(this.data, key, val);
},
defineReactive: function(data, key, val) {
var dep = new Dep();
var childObj = observe(val);
Object.defineProperty(data, key, {
enumerable: true, // 可枚举
configurable: false, // 不能再define
// 这里通过闭包,将key所对应的dep实例以及对之间的对应关系保存在内存当中了
get: function() {
if (Dep.target) {
dep.depend();
}
return val;
},
set: function(newVal) {
if (newVal === val) {
return;
}
val = newVal;
// 新的值是object的话,进行监听
childObj = observe(newVal);
// 通知所有订阅者。这里的订阅者就是watcher实例
dep.notify();
}
});
}
}
我们时刻要记住,我们实例化vue传进去的data对象是按引用传递的,Object.defineProperty中的形参中的data对象就是我们传进去data对象。在defineReactive方法中,通过var childObj = observe(val);这条语句对defineReactive方法进行了间接递归调用,从而实现了对data对象所有层次中的遍历。而遍历过程中,它做的第一件事就是new一个Dep实例。但是到这里,属性和Dep实例一对一的关系还无法建立起来,因为如你所见,new一个Dep实例的时候,我们并没有传递任何跟该属性相关的数据给Dep实例。那它们之间的关系是怎么建立的呢?答曰:“闭包”。
在defineReactive方法中有两层词法作用域。第一层是defineReactive方法本身,第二层是该属性的getter和setter函数。因为这两层嵌套作用域都访问了dep这个变量,所以,我们的代码就形成了一个可见的闭包。当defineReactive方法在运行时被真正调用的时候,我们的代码就产生了一个闭包。就是这个闭包,将当前属性与当前dep实例的一一对应关系保存在内存当中,等待这我们后面的使用。
可以这么说,数据劫持阶段,完成了属性与dep实例之间一一对应关系的建立。不但如此,还为后面watcher实例与dep实例的关系建立埋下了伏笔。这个伏笔在哪里呢?对的,就在getter里面:
// ....此前省略了很多代码
get: function() {
// 对的,就是这三行简简单单的代码
if (Dep.target) {
dep.depend();
}
return val;
},
// ....此后省略了很多代码
当程序在下个阶段(模板解析阶段)进入我们刚刚提及的闭包,执行到dep.depend()这条语句时,watcher实例与dep实例关系的建立正式拉开帷幕。那行,我们一起进入下个阶段的流程分析吧。
3. 模板解析阶段
if (this.$el) {
this.$fragment = this.node2Fragment(this.$el);
this.init();
this.$el.appendChild(this.$fragment);
}
从该学习库的实现代码来看,模板解析又可以分为三个步骤:
- 从真实容器节点中,把所有的节点挪至DocumentFragment容器中。
- 在DocumentFragment容器中,完成所有的模板解析和DOM操作工作。
- 把DocumentFragment容器中的节点挪回到真实容器节点中去。
要想理解步骤1的实现代码,主要要理解好DocumentFragment对象和appendChild()这个API。对于DocumentFragment对象的理解,我们已经在“概念梳理”部分讲解过,这里就不再赘述了。而对于appendChild()这个API,最为关键的第一点是,要理解“每一个element node只能有一个父节点”这句话。如果你不理解这句话,那么你就对步骤1的核心实现代码有困惑:
node2Fragment: function(el) {
var fragment = document.createDocumentFragment(),
child;
// 将原生节点拷贝到fragment
while (child = el.firstChild) {
fragment.appendChild(child);
}
return fragment;
},
当你看到fragment.appendChild(child)这条语句的时候,你可能会想,append一个现存的节点到fragment对象之后,不用删除它吗?答曰:“不用”。这正是appendChild()这个API负责干的事。这个API还是要遵循“每一个element node只能有一个父节点”的原则。所以,一番循环下来,真实节点容器里面的节点都被转移到了fragment对象里面了。
步骤1讲完了,步骤2才是重中之重。下面我们来看看步骤2。
在这个步骤里面,我们主要承接着上个阶段还没讲到的两个关系来讲解:
- 建立
表达式 《-》 watcher实例的一对一关系(模板解析阶段) - 建立
dep实例 《-》 watcher实例的多对多关系(模板解析阶段)
正如我在上文中给出的细致化的流程图所描述那样,整个模板解析流程的最底部做了两件事情:
- 完成了界面的初始化显示
- 开始着手实例化watcher
换成专业的话说,就是compileElement()函数的调用栈的最顶部函数bind()做了两件事:
......
bind: function(node, vm, exp, dir) {
var updaterFn = updater[dir + 'Updater'];
// 1. 完成了界面的初始化显示
updaterFn && updaterFn(node, this._getVMVal(vm, exp));
// 2. 开始着手实例化watcher
new Watcher(vm, exp, function(value, oldValue) {
updaterFn && updaterFn(node, value, oldValue);
});
},
......
从上面实现代码中,我们很直观地看到了这两件事所对应的代码:
updaterFn && updaterFn(node, this._getVMVal(vm, exp));new Watcher(vm, exp, function(value, oldValue) { updaterFn && updaterFn(node, value, oldValue); });
第一件事的实现代码没啥好讲的,因为代码执行到了这里,DOM操作的三要素都确定了:节点(node),操作(updaterFn)和值(this._getVMVal(vm, exp)),所以接下来就是在特定的节点上对某个属性赋予某个值。
第二件事的实现代码才是模板解析阶段的精华之所在。
// 实例化Watcher类
new Watcher(vm, exp, function(value, oldValue) {
updaterFn && updaterFn(node, value, oldValue);
});
// Watcher类的构造函数
function Watcher(vm, expOrFn, cb) {
this.cb = cb;
this.vm = vm;
this.expOrFn = expOrFn;
this.depIds = {};
if (typeof expOrFn === 'function') {
this.getter = expOrFn;
} else {
this.getter = this.parseGetter(expOrFn.trim());
}
this.value = this.get();
}
无论是形参exp还是expOrFn,都是指代的是模板上的某个表达式。从new Watcher(vm, exp,...)到this.expOrFn = expOrFn;,我们可以很直观地看到了watcher实例与表达式已经建立一一对应关系了。
好,到目前为止,我们还剩下dep实例与watcher实例之间的关系没有分析到。要想搞清楚这两者之间的关系是如何建立的,我们得继续往watcher实例化所涉及的函数调用栈追查下去。
在追查之前,我们脑海里面得有个概念,那就是dep实例已经存在内存中了,它正在等待在watcher实例化过程中去点燃那根建立两者关系的导火索。
还记得我们在上一阶段所说的那个闭包吗?
当
defineReactive方法在运行时被真正调用的时候,我们的代码就产生了一个闭包。就是这个闭包,将当前属性与当前dep实例的一一对应关系保存在内存当中,等待这我们后面的使用。
显然,这个闭包的内层词法作用域就是getter函数。而我们所说的导火索就是getter函数里面的dep.depend();语句。既然导火索是在属性的getter函数中(也可以称之为属性访问器),顾名思义,那么一旦去读取该属性值的时候,我们就会“点燃”这个根导火索。那在watcher实例化过程中,哪里需要读取属性的值呢?
我们顺着watcher实例化所涉及的代码往下找,看到这么一条语句:
this.value = this.get();
没错,就是这里,就是这条语句(目的是计算当前watcher实例所对应表达式的值)点燃了watcher实例与dep实例关系建立的导火索。严谨地来说,在dep实例真正与watcher实例建立关系之前,其实要“敲开两道门”的。哪两道门呢?
第一道门是Dep.target,它就在属性的getter访问器里面:
if (Dep.target) {
dep.depend();
}
第二道门是this.depIds.hasOwnProperty(dep.id), 它就在watcher实例的addDep方法里面:
if (!this.depIds.hasOwnProperty(dep.id)) {
dep.addSub(this);
this.depIds[dep.id] = dep;
}
可以看出,只有Dep类的静态属性target的值不是falsy值的时候,第一道门才会打开;只有当前dep实例没有跟当前watcher实例建立过关系的前提下,第二道门才会打开。
好,首先我们来看看第一道门开关的状态。第一道门一开始是关闭的。对应的代码是observer.js文件里面的最后一行代码:
Dep.target = null;
那什么时候打开了呢?我们不妨回到this.value = this.get();这行代码里面,继续往this.get()函数调用栈的顶部追溯。果不其然,在watcher实例的get()方法的实现代码里面,我们看到这么一条语句:
Dep.target = this;
你没看错,第一道门已经打开了。紧接着的一条语句是this.getter.call(this.vm, this.vm);,对它的执行,程序会进入到属性的getter访问器里面,开始关系建立之旅。
我们可以把接下来的事情想象为一个电影片段。这个电影片段里面的第一个镜头就是一个人站在了一道门面前。这个人就叫做“(内存中的)dep实例”。只见dep实例轻轻地敲了敲watcher实例的“闺房门”,说:“亲爱的watcher实例儿,你终于开门啦,那我们建立关系吧”。watcher实例犹抱琵琶半遮面地说:“客官莫急,你还有第二道门要打开呢?”。
于是乎,dep实例来到了第二道门的门口。他一看,原来门是打开的(没有建立过关系之前,watcher实例的depIds属性当然没有当前dep实例的引用)。心里就寻思着想:“这娘们挺能装的,还骗我。门根本就没有关着”。于是,dep实例就单枪直入。镜头来到这里就完了.......
好了,现在dep实例已经通过了两道门,顺利进入watcher实例的闺房了。它们俩准备建立关系了。而负责建立双边关系的核心语句只有两行行代码,也就是:
dep.addSub(this);
this.depIds[dep.id] = dep;
最后,我们以回答“dep实例和watcher实例建立关系是啥意思呢?”这个问题来结束这个阶段的分析吧。
第一行代码的作用就是实现dep实例主动向watcher实例建立关系。用代码的语言来说就是,把当前watcher实例存放到dep实例的属性subs(subscriber)数组中,等待被通知(调用watcher实例的update()方法);
第二行代码的作用是实现watcher实例主动向dep实例建立关系。用代码的语言来说就是,在watcher实例属性depIds对象里面建立对应的key-value来保存当前dep实例的引用。这个作用相当于对dep实例的访问存根。当下一次再来建立关系的时候,发现这个dep实例已经有存根了,则可以将它拒之门外。
以上,我们算是梳理完了dep实例与watcher实例之间多对多关系建立的整个流程了。至于为什么是多对多呢?我们上面概念梳理阶段已经说过了,现在我们再来重复一遍。我们也要牢牢记住,因为表达式是可以由n个属性组成的。所以,读取某个表达式的值很有可能导致n次的属性值的读取 。n个属性则对应n个dep实例,而n次属性值的读取则意味着在一次的watcher实例化过程中发生n次的关系建立。而另外一个角度来看,一个模板可以有m个表达式,m个表达式则意味着m次的watcher实例化。m *n,最终, dep实例与watcher实例形成了多对多的关系。
好,到这里,这个阶段的流程分析已经完毕了。如果从是否干了实事的角度总结这个阶段,那么这个阶段只做了一件实事。那就是完成界面的初始化显示。其余的都是为运行期阶段做所的准备工作。行,我们一起来看看,这个阶段做的准备工作是如何接到到下个阶段的。
4. 运行期阶段
所谓的运行期说白了就是对属性进行赋值而触发相关代码执行这么的一个阶段。在vue里面,无论是在事件处理器还是在我们自定义的method,对于vue而言,其核心操作依然“对属性进行赋值”。这就这么一个简简单单地赋值,让我们对接上个阶段所做的一切准备工作。
其实在进入数据劫持属性的setter之前,是先经过数据代理所注册的getter,再经过数据劫持属性的getter,最后才进入数据劫持属性的setter的。但是,因为此时的Dep.target为null,所以,这种属性值读取是无法通过dep实例与watcher实例关系建立的第一道大门。因此,这种冲击到这里戛然而止了。我们只需要关注这段旅程(对属性进行赋值)的终点站就好-也就是数据劫持属性的setter访问器。下面来看具体的代码:
set: function(newVal) {
if (newVal === val) {
return;
}
val = newVal;
// 新的值是object的话,进行监听
childObj = observe(newVal);
// 通知订阅者
dep.notify();
}
其实,setter就做了三件事。
- 如果设置的新值跟老值相等,则什么都不做。
- 否则,对新值所包含的属性进行劫持。
- 最后,通知订阅了该dep实例的所有watcher实例。负责更新界面的updater在上一个阶段已经通过回调的方式关联到每个watcher实例身上了,所以到这里,watcher实例就能轻而易举地调用updater,实现界面的整体更新。
对vm实例赋值之所以能进入到数据劫持属性的setter,dep实例之所以能通知到watcher实例,watcher实例之所以能调用到updater,种种的一切,都是因为我们在上三个阶段做足了准备,所以才让这些事情的发生成为可能。
到此,四个阶段都分析完了。最大的重点就是dep实例与watcher实例的多对多关系的建立。其实“dep实例与watcher实例的多对多关系的建立”还有个另外一个叫法“依赖收集”。现在回过头来,我们可以这么理解“依赖收集”这个概念:如果说:“谁使用了谁,谁就依赖谁”的话。那么现在表达式使用了属性,我们就说:“表达式依赖了属性”。接下来,我们可以把dep实例看做是属性的经纪人,把watcher看做是表达式的管家。管家负责收集表达式的所有依赖的属性,当它逐一去找到对应属性的时候,这些属性跟watcher管家说:“有什么事,你跟我的经纪人dep实例说吧”。到最后,“依赖收集”变成了dep实例和watcher实例之间的事了。简而言之,“依赖收集”可以理解为“watcher实例代替表达式去收集后者所依赖属性的dep实例”。
小结
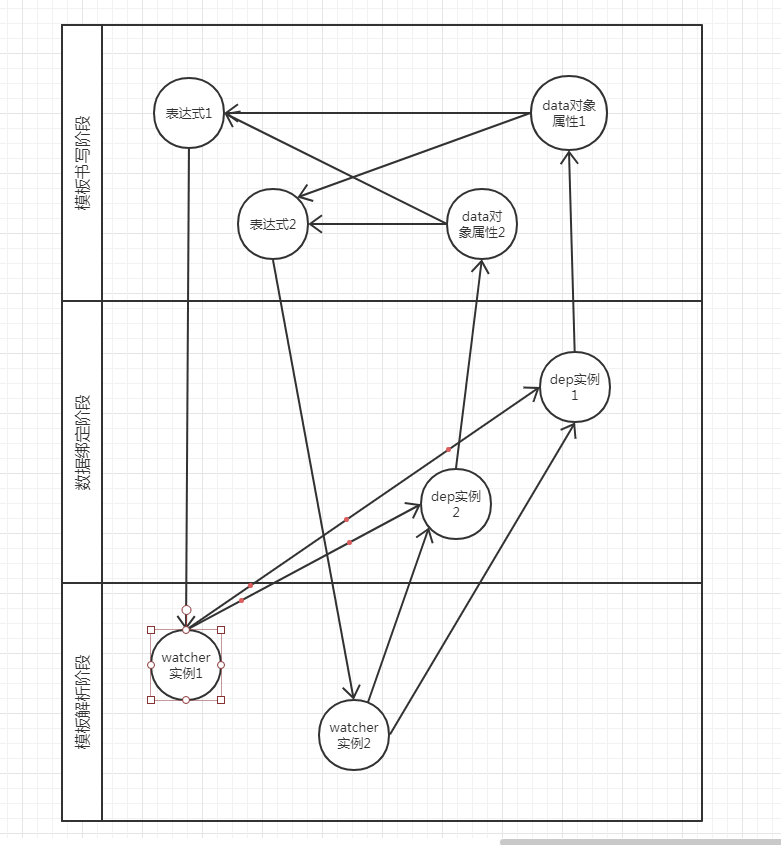
如果从data对象属性这个视角出发,我们能看到的属性,表达式,dep实例和watcher实例这四者之间的关系建立泳道图大概如下:
技术点
这个学习库涉及到了不少技术点的应用,下面做个简单的记录。
闭包
比较明显和重要的闭包有以下三个:
1.在被嵌套的词法作用域getter或者setter访问了嵌套词法作用域defineReactive的dep变量:
//在observer.js文件里面
defineReactive: function(data, key, val) {
var dep = new Dep();
var childObj = observe(val);
Object.defineProperty(data, key, {
enumerable: true, // 可枚举
configurable: false, // 不能再define
get: function() {
if (Dep.target) {
dep.depend();
}
return val;
},
set: function(newVal) {
if (newVal === val) {
return;
}
val = newVal;
// 新的值是object的话,进行监听
childObj = observe(newVal);
// 通知订阅者
dep.notify();
}
});
}
- 在被嵌套的词法作用域回调函数里面访问了嵌套词法作用域bind函数的updaterFn和node变量:
//在compile.js文件里面
bind: function(node, vm, exp, dir) {
var updaterFn = updater[dir + 'Updater'];
updaterFn && updaterFn(node, this._getVMVal(vm, exp));
new Watcher(vm, exp, function(value, oldValue) {
updaterFn && updaterFn(node, value, oldValue);
});
},
- 在被嵌套的词法作用域返回函数里面访问了嵌套词法作用域parseGetter函数的exps变量:
//在watcher.js文件里面
parseGetter: function(exp) {
if (/[^\w.$]/.test(exp)) return;
var exps = exp.split('.');
return function(obj) {
for (var i = 0, len = exps.length; i < len; i++) {
if (!obj) return;
obj = obj[exps[i]];
}
return obj;
}
}
递归
直接递归或者间接递归有两个:
- 通过observe(val)间接递归调用defineReactive()
//在observer.js文件里面
defineReactive: function(data, key, val) {
var dep = new Dep();
var childObj = observe(val);
Object.defineProperty(data, key, {
enumerable: true, // 可枚举
configurable: false, // 不能再define
get: function() {
if (Dep.target) {
dep.depend();
}
return val;
},
set: function(newVal) {
if (newVal === val) {
return;
}
val = newVal;
// 新的值是object的话,进行监听
childObj = observe(newVal);
// 通知订阅者
dep.notify();
}
});
}
- 在模板解析的过程中,对子节点遍历过程中,直接递归调用compileElement()
//在compile.js文件里面
compileElement: function(el) {
var childNodes = el.childNodes,
me = this;
[].slice.call(childNodes).forEach(function(node) {
var text = node.textContent;
var reg = /\{\{(.*)\}\}/;
if (me.isElementNode(node)) {
me.compile(node);
} else if (me.isTextNode(node) && reg.test(text)) {
me.compileText(node, RegExp.$1.trim());
}
if (node.childNodes && node.childNodes.length) {
me.compileElement(node);
}
});
},
引用传递
针对我们传入的option对象的data字段,有一条较长的引用传递链:
我们实例化传入的option对象 => mvvm实例的this.$options => mvvm实例的this.$options.data => mvvm实例的this._data => observe(data, this) => observer实例的this.data
所以,到了最后,数据劫持的对象就是我们实例化mvvm传递进去的data对象。
element节点只能有一个父节点
在compile.js文件中将真实容器节点的所有子节点“拷贝”到DocumentFragment对象中去时,使用了appendChild()这个API。从而佐证了这条在DOM世界里面的规则。
node2Fragment: function(el) {
var fragment = document.createDocumentFragment(),
child;
// 将原生节点拷贝到fragment
while (child = el.firstChild) {
fragment.appendChild(child);
}
return fragment;
},
类数组调用数组方法
在进行DOM操作的时候,我们避免不了要跟类数组(有些人称之为伪数组)打交道。
compileElement: function(el) {
var childNodes = el.childNodes,
me = this;
[].slice.call(childNodes).forEach(function(node) {
// ......
});
},
compile: function(node) {
var nodeAttrs = node.attributes,
me = this;
[].slice.call(nodeAttrs).forEach(function(attr) {
// ......
});
},
无论是[].slice.call()还是Array.prototype.slice.call()这种写法,都是达到借用真数组方法的目的。不过,个人觉得,理论上说,后者会更好。因为,后者省去了不必要的属性查找的次数,性能表现会更优。
总结
如果真的如这个学习库的作者所说的那样(大部分的代码是摘抄与vue的源码),那么我相信,我已经了解到了vue的核心原理了。至于后面那些叠加上来的,不太核心的特性,比如说:virtual DOM,componnet机制,各种扩展机制啊等等,我要深入到vue真正的源码去研究了。
整篇文章下来,几乎10000字,是为自己学习vue原理的阶段性总结之用。如有错误,望不吝指出,万般感激。
最后,谢谢阅读。
