

为了让前端工作更有效率,必须彻底掌握一些必要的调试技巧。平常在开发Node应用的过程中,最常使用的是本地调试,但是一旦你的代码到了生产环境,就必须采取其他策略进行追踪和解决问题。
在编程领域,有一个专门的术语“Post-mortem debugging",它的意思是在程序奔溃后再进行的调试工作。对于Node程序来说,如果你遇到了难以重现、线上环境无法调试等问题都可以采用这种方案进行操作。而且线上问题一般都是比较紧急的,所以我们一般都希望能最快定位到问题发生的代码。
那么我们具体要怎么做呢?下面举个简单的例子。
收集奔溃信息
假设现在你有这样一段代码:
const demo = (data) => {
const {id, profile} = person;
console.log(id);
console.log(profile.name);
}
demo({id: 1, profile: {age: 12}});
运行后它会报错并退出。这时候你需要做的是收集奔溃信息并对其做分析。Core Dump就是这样用来记录程序运行信息的一种工具,它包含了程序运行过程中的内存状态,调用栈等,能最真实地还原当时的“案发现场“。
那么,在Node.js中我们怎么获得Core Dump的文件呢?
首先,我们先设置一下系统中的内核限制:
ulimit -c unlimited
然后你需要在启动应用的时候,使用--abort-on-uncaught-exception这个flag来手动触发程序奔溃后写core文件的操作:
node --abort-on-uncaught-exception app.js
这样当程序突然奔溃的时候,就会在linux或mac系统的/cores目录下生成类似core.81371这样的一个文件。这个文件就是我们用来调试调查程序奔溃的核心。
如果你的程序正在执行过程中,我们也可以手动捕获core dump文件,类似于实时检查,主要用于程序假死等状态。
手动捕获的话需要使用Linux系统自带的 gcore 命令,具体用法是找出当前进程的pid(这里假设是123),然后执行命令:
gcore 123
生成对应的core dump文件。
另外一种方式是采用lldb调试工具,mac系统下使用该命令进行安装:
brew install --with-lldb --with-toolchain llvm
然后执行:
lldb --attach-pid <pid> -b -o 'process save-core' "core.<pid>"'
这样就能在不重启程序的情况下导出特定进程的core dump文件。
调试步骤
得到具体的core dump文件后,我们就要进入调试分析阶段了。
首先,需要使用选择顺手的分析工具。你可以选择mdb_v8或者llnode。这两个工具用起来都差不多。
这里以llnode为例,先介绍几个常用命令:
| 命令 | 意义 |
|---|---|
| v8 help | 查看帮助信息 |
| v8 bt | get stack trace at crash 查看堆栈信息 |
| v8 souce list | 显示stack frame的源码 |
| v8 inspect | 查看对应地址的对象内容 |
| frame select | 选择对应的stack frame |
在分析前,先需要用llnode加载core文件:
llnode -c /cores/core.81371
然后获取对应的堆栈信息:
// 查看堆栈信息
(llnode) v8 bt
// 根据堆栈信息找到可疑的地址,并查看对应的对象内容
(llnode) v8 inspect <address>
// 指定对应的stack frame
(llnode) frame select 6
// 查看源码
(llnode) v8 source list
最后通过结合堆栈信息和源码就能找到错误发生的原因了。
内存泄漏
除了程序奔溃,有时候你还会发现应用随着运行时间增长,速度开始变慢。这可能就是内存泄漏捣的鬼。
比如下面这段代码:
const requests = new Map();
app.get("/", (req, res) => {
requests.set(req.id, req);
res.status(200).send("hello")
})
通常来说,内存泄漏容易发生在闭包等场景下。针对内存泄漏的调试,可以使用如下命令:
node --trace_gc --trace_gc_verbose app.js
启动应用后,通过压测工具运行如下命令:
ab -k -c200 -n10000000 http://localhost:3000
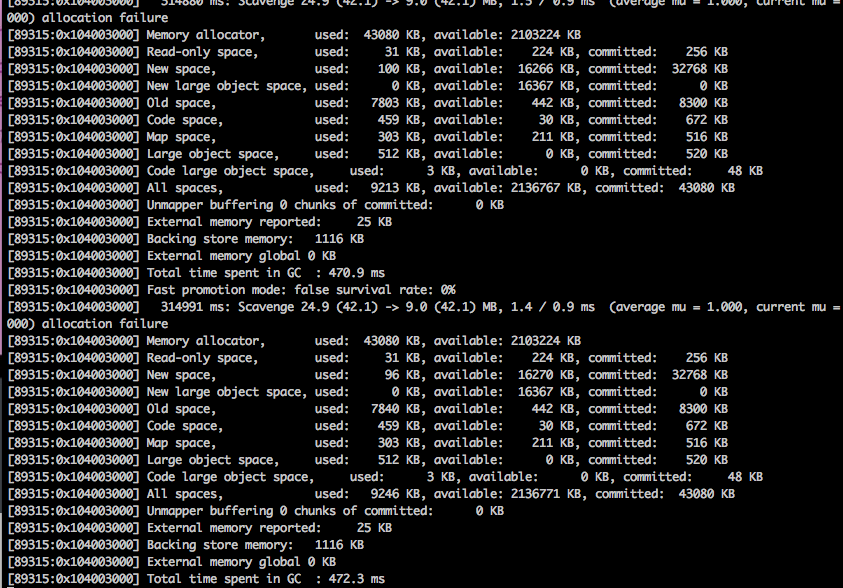
可以看到随着程序的运行,内存使用越来越大。
另外,我们还可以使用heap snapshot来获取快照信息:
process.on('SIGUSR2', () => {
const { writeHeapSnapshot } = require("v8");
console.log("Heap snapshot has written:", writeHeapSnapshot())
})
在命令行中执行:
kill -SIGUSR2 <pid>
就能够获得对应的快照文件,然后我们可以使用Chrome Devtools的Memory菜单加载对应的快照文件进行比对分析了。
如果是开发阶段,你也可以直接使用调试模式启动应用:
node --inspect app.js
然后使用菜单Devtools > Memory > take heap snapshot获得快照文件。
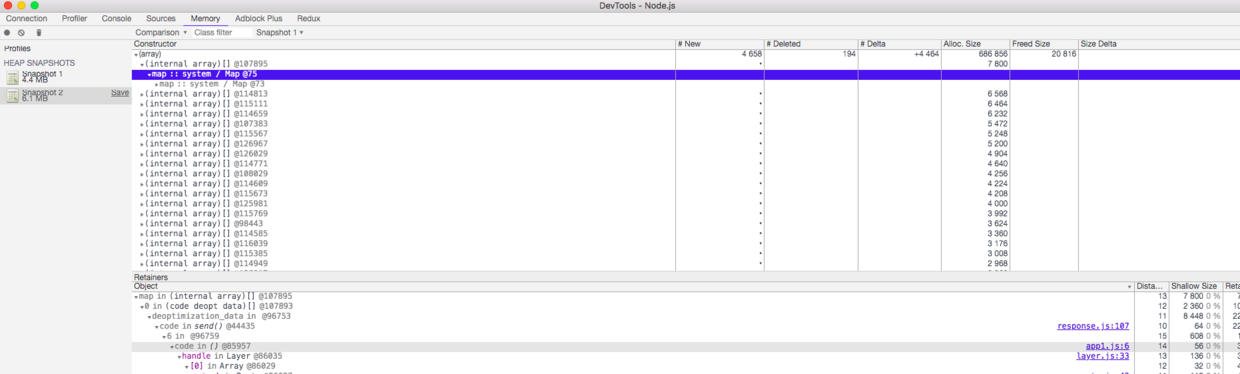
通过比较两个不同的内存快照,我们可以很快找到内存增长最快的那个对象,然后进而分析对应的源码就能知道问题出在了哪里。
除了采用Chrome浏览器,在linux主机上,我们还能使用万能的llnode调试器进行内存泄漏的分析。原理大致相同,也是通过分析core 文件,然后安装对象大小排序,针对可疑的对象进行源码查看。
(llnode) v8 findjsobjects
(llnode) v8 findjsinstances -d <Object>
(llnode) v8 inspect -m <address》
(llnode) v8 findrefs <address>
其它策略
另外一种收集报告的策略是使用参数,适用于13.0以上版本:
node \
--experimental-report \
--diagnostic-report-uncaught-exception \
--diagnostic-report-on-fatalerror \
app.js
这样在程序奔溃的时候,就能够获取到对应的报告。你还可以通过代码显式控制报告的输出文件名等:
process.report.writeReport('./foo.json');
更多说明可以参考官方文档: nodejs.org/api/report.…
——转载请注明出处———
微信扫描二维码,关注我的公众号

最后,欢迎大家关注我的公众号,一起学习交流。
参考资料
medium.com/netflix-tec… en.wikipedia.org/wiki/Debugg… www.bookstack.cn/read/node-i… github.com/bnoordhuis/…
