

- 原文地址:GraphQL Concepts Visualized
- 原文作者:Dhaivat Pandya
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Jessica
- 校对者:江五渣,Baddyo
将 GraphQL 概念可视化
我们将用图解来可视化 GraphQL 思维模型
GraphQL 通常被我们解释为“用于访问不同来源的数据的统一接口”。虽然这个解释是对的,但它并没有揭示 GraphQL 背后的本质和动机,以及它被称为 “GraphQL” 的原因 —— 这就像,你看到了星星和夜空,并不等于你看到了“星月夜”(画家梵·高的代表作之一)。
我认为 GraphQL 真正的核心在于应用数据图。在本文中,我将介绍应用数据图,讨论 GraphQL 如何在应用数据图上进行查询操作,以及如何利用 GraphQL 查询的树形结构来缓存其查询结果。
更新于 2/7/2017:现在你可以在下面这个视频里看到这篇文章的内容了(译者注:视频源自 Youtube 需要翻墙)
GraphQL 的思维模型 — Dhaivat Pandya
应用数据图
现代应用中的很多数据都可以使用带有节点和边的图来表示,其中节点表示对象,边表示对象之间的关系。
例如,我们正在为图书馆建立一个图书目录系统。简单来说,我们的目录中有一堆书和作者,每本书至少有一个作者。除此之外,还有合作作者,作者与其他人共同合作写了一本书或多本书。
如果我们以图的形式可视化这些关系,它们看起来是这样的:
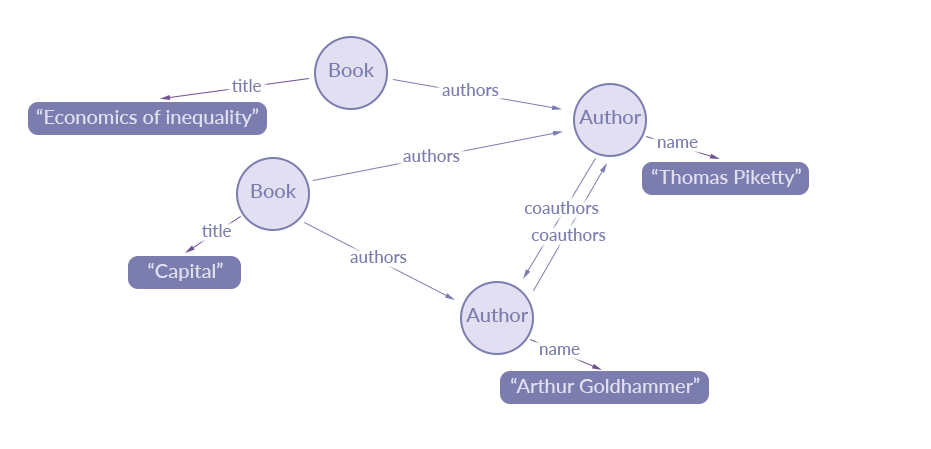
该图表示了我们的各种数据片段与我们试图表示的实体(例如 Book 和 Author)之间的关系。几乎所有的应用都是在这种图上运行的:它们从图中读取数据并对其进行写操作。这个图就是 GraphQL 的用武之地。
在 GraphQL 中,我们可以从应用数据图中提取出一棵树。
听到这你可能很会感到疑惑,但让我们来解释一下它的意思。根本上来说,树是一个有起点(根)和属性的图。其中它的属性是不能用手指沿着节点的边追溯,然后回到同一个节点的,也就是说,它没有循环。
使用 GraphQL 遍历应用数据图
让我们来看一个 GraphQL 查询示例,从而理解它是如何从应用数据图中“提取树”的。这是对应我们上面那张图书目录系统应用数据图的 GraphQL 查询代码,如下所示:
query {
book(isbn: "9780674430006") {
title
authors {
name
}
}
}
一旦服务器解析了查询,它将返回此查询结果:
{
book: {
title: “Capital in the Twenty First Century”,
authors: [
{ name: ‘Thomas Piketty’ },
{ name: ‘Arthur Goldhammer’ },
]
}
}
这是用应用数据图表示的样子:
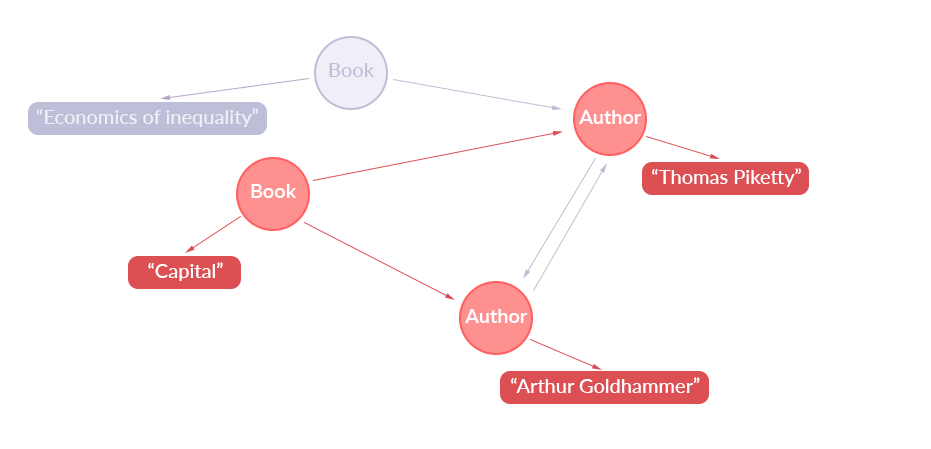
查询路径
让我们来看看这些数据是如何通过 GraphQL 查询从图中提取出来的。
在 GraphQL 中,我们可以定义根查询类型(我们将其称为 RootQuery),该类型定义了遍历应用数据图时 GraphQL 查询应在何处开始。在我们的例子中,我们从一个 “Book” 节点开始,该节点是使用其 ISBN 号也就是查询字段 “book(isbn: …)” 选择的。然后,GraphQL 查询通过跟踪每个嵌套字段标记的边来遍历图。在我们的查询中,它通过查询中的 “title” 字段从 “Book” 节点跳到包含书的标题字符串的节点。它还通过跟踪 “Book” 节点上标有 “authors” 字段的边获取 Author 节点,并获取每个作者的“name”。
要查看这个结果如何构造出一棵树,只需移动节点使其看起来更像一棵树:
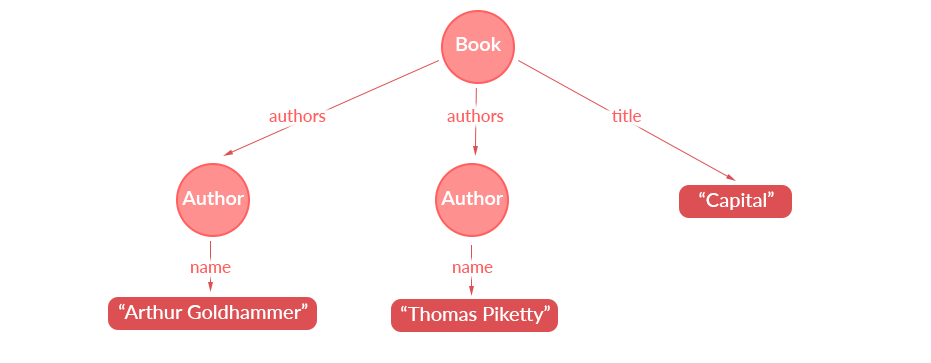
对于查询返回的每条信息,有一个与之关联的查询路径。该路径由 GraphQL 查询中的字段组成,我们按照该字段来获取该数据。例如,图书的标题 “Capital” 的查询路径如下:
RootQuery → book(isbn: “9780674430006”) → title
我们 GraphQL 查询中的字段(即 book、authors、name)指定了应用数据图中应该选择哪些边来获得我们想要的结果。这就是 GraphQL 名称的由来:GraphQL 是一种查询语言,它遍历数据图以生成查询结果树。
缓存 GraphQL 结果
要构建一个真正快速、流畅的应用,使用户不会浪费大量时间在等待加载的加载动画上,我们希望使用缓存来减少客户端与服务器之间的请求。事实证明,GraphQL 的树形结构非常适合客户端缓存。
举一个简单的例子,假设您的页面上有一些代码可以获取到以下 GraphQL 查询结果:
query {
author(id: "8") {
name
}
}
稍后,页面的其他部分将再次请求这个相同的查询。除非我们完全需要最新的数据,否则可以使用我们已有的数据来响应第二个查询!这意味着缓存需要能够在不将查询发送到服务器的情况下解决查询,从而使我们的应用运行得更快。但是,仅仅是缓存我们之前获取的准确查询还不够,我们还可以做得更好。
让我们来看看 Apollo Client 缓存 GraphQL 结果的方法。从根本上讲,GraphQL 查询结果是从服务器端数据图中形成的信息树。为了避免每次我们再次需要它们时都重新加载它们,我们希望能够缓存这些结果树。为此,我们先做出一个关键假设:
Apollo Client 假设应用数据图中的每个路径(由 GraphQL 查询指定)都指向一个稳定的信息块。
如果在某些不成立的情况下(例如,当特定查询路径指向的信息非常频繁地更改时),我们可以用对象标识符的概念来防止 Apollo Client 做出这样的假设,稍后我们将介绍这个概念。但是,一般来说,当涉及到缓存时,这是一个合理的假设。
路径相同,对象相同
这个最后介绍的“路径相同,对象相同”假设是极其有用的。例如,假设我们有两个查询,一个接一个地触发:
query particularAuthor {
author(name: "Thomas Piketty") {
name
age
}
}
query authorAndBook {
book(isbn: "9780674430006") {
title
}
author(name: "Thomas Piketty") {
name
age
}
}
只需查看查询就可以看到,第二个查询不需要到服务器获取作者的姓名。此信息可以在缓存中从上一个查询的结果中找到。
Apollo Client 使用这种逻辑来根据缓存中已有的数据去掉部分查询。它能支持这种对比查询是因为路径假设。它假设路径 RootQuery→author(id: 6)→name 在两个查询中获取了相同的信息。当然,如果您不希望使用这个假设,您可以使用 forceFetch 选项,缓存将被完全覆盖。
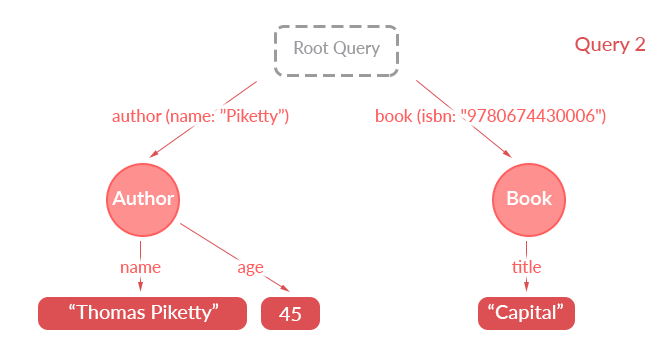
这个假设非常有用,因为查询路径中还包括我们在 GraphQL 中使用的参数。例如:
RootQuery → author(id: 3) → name
就不等同于
RootQuery → author(id: 6) → name
因此 Apollo Client 不会假设它们代表相同的信息,并尝试将其中一个与另一个的结果合并。
当路径假设不够时,使用对象标识符
事实证明,除了从根开始跟踪查询路径以外,我们还可以做得更好。有时,您可能通过两个完全不同的查询访问到同一个对象,从而为该对象提供两个不同的查询路径。
例如,假设我们的每个作者都有一些共同作者,那么我们最终可以通过该字段访问一些 “Author” 对象:
query {
author(name: "Arthur Goldhammer") {
coauthors {
name
id
}
}
}
但我们也可以直接从根节点访问到一个作者:
query {
author(id: "5") {
name
id
}
}
假设名为 “Arthur Goldhammer” 的作者和 ID 为 5 的作者是某本书的合作作者。然后,我们将在缓存中两次保存相同的信息(即关于 ID 为 5 的作者,Thomas Piketty 的信息)。
那么,缓存中的树形缓存结构就像是这样:
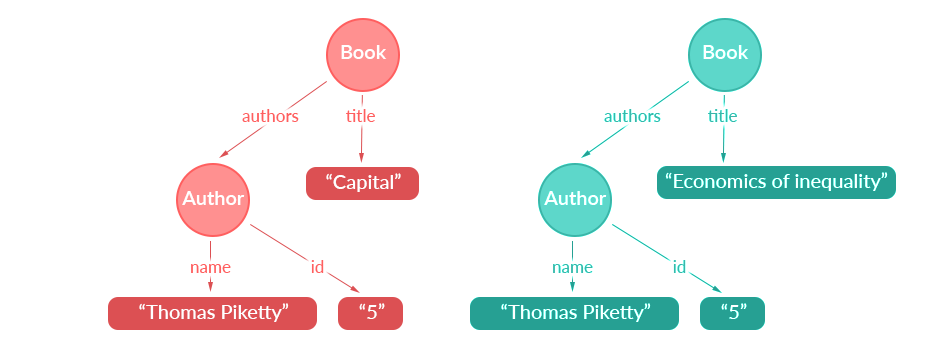
现在的问题是,这两个查询都引用了应用程序数据图中的同一条信息,但是 Apollo Client 还并不知道这件事。为了解决该问题,Apollo Client 提出了第二个概念:对象标识符。基本上,您可以为查询的任何对象指定惟一标识符。然后,Apollo Client 会认为所有具有相同对象标识符的对象表示相同的信息。
一旦 Apollo Client 知道了这一点,它就可以以更好的方式重新安排缓存:
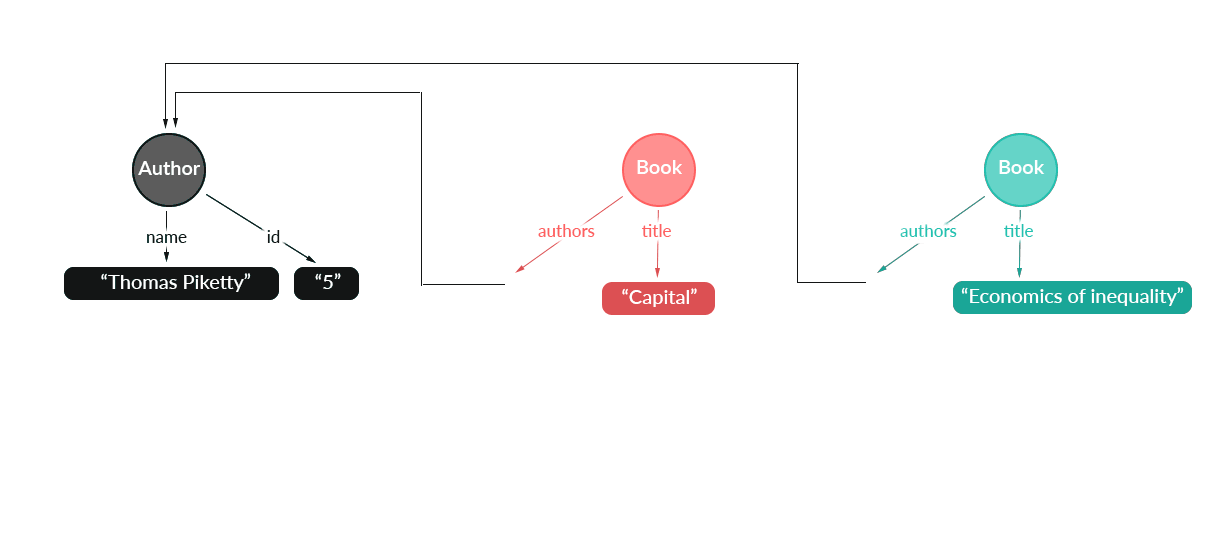
这意味着对象标识符在整个应用中必须是唯一的。因此,您不能直接使用 SQL ID,因为这样一来,作者的 SQL ID 可能是 5,图书的 SQL ID 也可能是 5。但这很容易解决:要生成唯一的对象标识符,只需将 GraphQL 返回的 __typename 附加到后端生成的 ID 即可。因此,一个 SQL ID 为 5 的作者可以有一个 Author:5 或类似的对象标识符。
保持查询结果一致
继续我们刚才处理的最后两个查询,让我们考虑一下如果某些数据发生更改会发生什么。例如,如果您获取其他查询时发现 ID 为 5 的作者更改了姓名,该怎么办?同时,这个 ID 为 5 的作者使用的旧名称的 UI 部分会发生什么情况?
重头戏来了:它们会自动更新。这就引出了 Apollo Client 提供的另一个功能:如果所观察的查询树的任何节点的值发生变化,查询将使用新的结果进行更新。
因此,在本例中,我们有两个查询都依赖于作者,其对象标识符为“Author:5”。由于这两个查询树都引用了作者这个属性,所以对作者信息的任何更新都将传播到这两个查询:
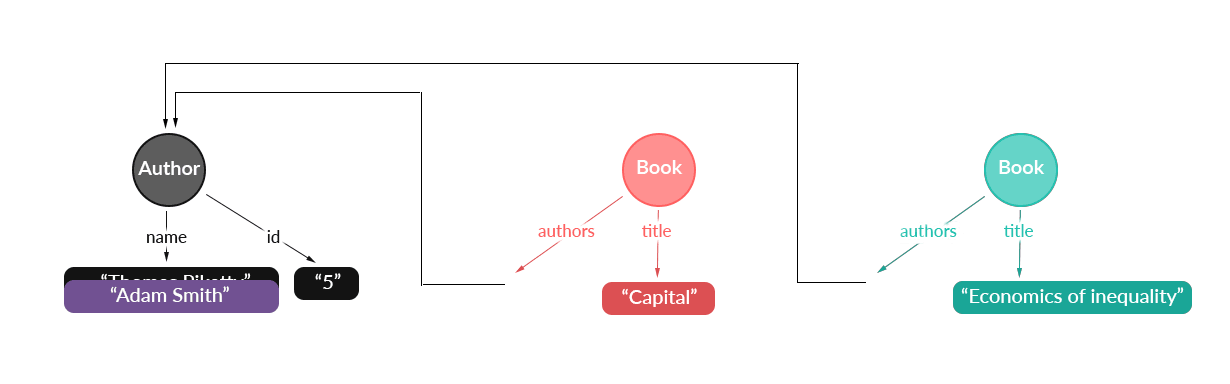
如果您在 Apollo Client 中使用 react-apollo 或 angular2-apollo 这样的视图集成包,就无需为此进行设置:您的组件将直接获得新数据并自动重新渲染。如果您没有使用视图集成包,那么核心方法 watchQuery 也可以做到,它为您提供一个观察者对象,每当存储更改时它将进行更新。
有时,对于您的应用来说,在所有内容上都使用对象标识符是不合理的,或者您可能不想直接在代码中处理它们,但仍需要更新缓存中的特定信息。我们提供方便而强大的 API 可以解决这个问题,例如 updateQueries 或 fetchMore,可以使您通过非常精细的控制将新信息合并到这些查询树中。
总结
任何应用程序的主干部分都位于应用数据图中。在过去,当我们必须将自己的 HTTP 请求送到 REST 端点以将数据导入和导出到应用程序数据图时,在客户端上进行缓存是非常困难的,因为数据获取是特定于客户端应用的。而现在,GraphQL 为我们提供了大量信息,我们还可以利用这些信息自动缓存数据。
如果你理解了这 5 个简单的概念,您就能理解在 Apollo Client 中的反应和缓存(即所有使您的应用快速而流畅的魔术)是如何工作的。这里,我们再重复一遍:
- GraphQL 查询意味着从应用数据图中获取树的方法。我们将这些树称为查询结果树。
- Apollo Client 缓存了查询结果树。为此,它应用了两个假设:
- 路径相同,对象相同 —— 相同的查询路径通常指向相同的信息。
- 当路径假设不够时,使用对象标识符 —— 如果两个查询结果被赋予相同的对象标识符,则它们表示相同的节点或者信息。
- 如果查询结果树中的任何缓存节点被更新,Apollo Client 将使用新结果更新查询。
一般来说,了解以上的内容,就足够使您成为 Apollo Client 和 GraphQL 缓存方面的专家了。觉得这篇文章信息量太大了?别担心 —— 如果可以的话,我们将继续发布更多类似这样的概念信息,以便每个人都能理解 GraphQL 背后的目的、它的名称的由来,以及如何清楚地解释 GraphQL 结果缓存的各个方面。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
