

在中文的语言环境里,身为程序员的我们一定会遇到过中文乱码的情况,究其原因就是字符编码的问题。在没有深入理解其原理之前,会觉得中文编码问题比较谜,莫名其妙地乱码,又稀里糊涂地好了。
字符编码是计算机技术的基石,本文希望帮助大家彻底梳理清楚字符编码问题,不仅知其然,还知其所以然,摆脱被中文乱码支配的感觉。
在讲解中文编码问题之前,我们需要先讲讲英语编码,其解决方案是ASCII。
ASCII
ASCII的英文全称是American Standard Code for Information Interchange,中文意思是美国信息交换标准代码,是基于拉丁字母的一套计算机编码系统,使用8位二进制表示字符。
在计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此8个二进制位就可以组合出256种状态,这被称为一个字节(byte)。
换句话说,一个字节可以表示256种不同的状态,每一个状态对应一个符号,也就是256个符号,从0000 0000到1111 1111,其数量计算公式:。
列举一部分ASCII码表,如下所示:
| 二进制 | 十六进制 | 图形 |
|---|---|---|
| 0010 0000 | 20 | (space) |
| 0010 0001 | 21 | ! |
| 0011 0001 | 31 | 1 |
| 0011 1101 | 3D | = |
| 0100 0100 | 41 | A |
| 0110 0001 | 61 | a |
英语是由26个基本拉丁字母、阿拉伯数字和英式标点符号组成,因此用128个符号就足够l了,但ASCII码对于其他一些复杂的语言,就力不从心了,比如:汉字大约将近10万个(虽然没有准确的数字,但日常使用汉字也有几千字)。
一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。为了正确显示中文字符,在1981年5月1日,由中国国家标准总局发布了《信息交换用汉字编码字符·基本集》,通常简称GB。
GB类
中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312是简体中文常见的编码方式,使用两个字节表示一个汉字,所以最多可以表示个符号。
GB2312标准共收录6763个汉字,其中一级汉字(常用字)3755个,二级汉字(较不常用)3008个,同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
GB2312基本满足了计算机处理简体汉字的需求,所收录的汉字覆盖了99.75%的使用频率,但对于罕见字和繁体字,GB2312就不能处理了。因此发明了后来的GBK和GB18030。
它们之间的关系如下图所示:

GBK编码是GB2312编码的超集,向下完全兼容GB2312,兼容的含义是不仅字符兼容,而且相同字符的编码也相同。而GB18030编码向下兼容GBK和GB2312,GB18030编码是变长编码。
但很多像GB类的编码方式都有一个共同的问题,允许计算机处理双语环境,即拉丁字母和本地语言,却无法同时支持多语言环境,即多种语言混合的情况。Unicode就是为了解决这个问题而诞生的方案。
Unicode
世界上存在着多种语言,比如:西班牙语、韩语、俄语等等,它们也都分别有各自的编码方式,所以同一个二进制数字可以被解释成不同的符号。如果想要正确的打开一个文本文件,就必须知道它的编码方式,否则就会出现乱码。
假如有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,一种所有符号的编码。

Unicode伴随着通用字符集的标准而发展,当前最新的版本为2019年5月公布的12.1.0,已经收录超过13万个字符。Unicode涵盖的数据除了视觉上的字形、编码方式、标准的字符编码外,还包含了字符特性,如大小写字母。
然而,Unicode只是一个符号集,不代表计算机里的编码,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
因此,导致了两个问题:
- 计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 英文字母只用一个字节表示就够了,但按照Unicode规定,每个符号要用3个或4个字节表示,那么英语文本的存储空间将扩大3到4倍,是极大的浪费。
随着互联网的发展,不同国家的信息越来越多地在网络中传播,强烈需要一种统一的编码方式,UTF-8就是在互联网上被广泛使用的一种Unicode实现方式。
UTF-8
再次强调一下,UTF-8是Unicode的实现方式之一,并不是唯一,也不等同于Unicode。除了UTF-8,还有UTF-16和UTF-32,只是很少被使用。
UTF-8的特点是对不同范围的字符使用不同长度的编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
其编码规则很简单:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10,剩下的没有提及的二进制位,全部为这个符号的Unicode码。
Unicode与UTF-8的字节对应关系:
| Unicode范围 | UTF-8 |
|---|---|
| U+0000~U+007F | 0xxxxxxx |
| U+0080~U+07FF | 110xxxxx 10xxxxxx |
| U+0800~U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| U+010000~U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
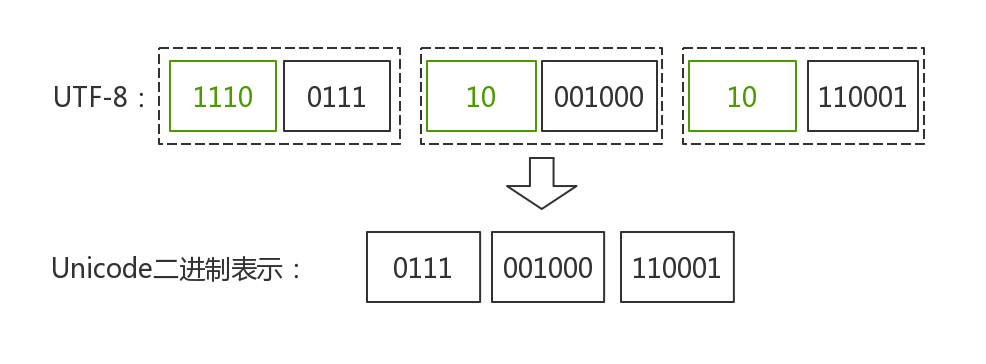
以“爱”为例,其的Unicode是U+7231,是在U+0800~U+FFFF范围内,所以采用3个字节进行编码,其二进制为01110010 00110001。
那么用UTF-8表示,则如下图所示:
后记
计算机操作系统中的编码:
- Windows下中文的默认编码是GBK(GB2312)
- Linux下中文的默认编码是UTF-8
如果使用的是Linux系统,可以通过如下命令,查看系统中文编码:
echo $LANG
en_US.UTF-8
如果想要查看文件的原始编码,并且转换编码,可以使用enca命令,可以通过apt-get install enca进行安装。
enca -L zh_CN <file> # 查看文件的编码
enca -L zh_CN -x UTF-8 <file> # 将文件编码转换为UTF-8编码
enca -L zh_CN -x UTF-8 <file_1> <file_2> # 保留原始文件
字符编码选择建议:
- 只有英文,选择ASCII
- 主要存中文,对存储大小比较敏感,选择GB2312
- 通用性第一,处理简单,选择UTF-8
最后,安利大家一本我写的掘金小册《深入理解NLP的中文分词:从原理到实践》,让你从零开始掌握中文分词技术,踏入NLP的大门。如果以上内容对你有所帮助,希望你能够点赞、转发、评论,多谢多谢!
