

前言
只有掌握了 N-1 层的原理,才能精通第 N 层的抽象
-- 佚名
视工作类型而定,有时候想掌握 N-1 层的原理,可能还需要了解 N-2,N-3 ...
于前端程序员而言,第 N 层的抽象即 HTML/CSS/JS 语法,N+1 层是各种前端框架,N-1 层是语法的内部实现和浏览器的工作原理,N-2 层可能就是渲染引擎,JS 引擎,JS Runtime的实现。
你见过没有掌握 HTML/CSS/JS 却精通 React 框架的人么?
本文只谈 HTML ,要想真正的精通 HTML ,我们需要知道 HTML 的内部实现,通读 HTML 规范是最有效的方法之一
通过本文,我们想要达到的目的有:
- 了解 Web 平台的技术体系以及如何查找相关规范
- 了解 HTML 规范的整体结构,日后碰到疑难杂症可以快速排查原因
PS: 本文描述中的 “标准” 和 “规范” 指的是同一东西
PS2: 为什么要看 HTML 规范?通常 API 文档只告诉了我们要这么做,却没告诉我们为什么不能这样做,通过看规范,我们能对 API 理解更加深刻
查找规范
首先明确一点, MDN 不是规范文档,确切的说法是指南和开发教程,是对规范的二次解读。 相比规范,MDN 在行文格式和专业术语的运用上更容易让前端开发者接受。大部分情况下,MDN 已能够解决问题。当发现 MDN 上的解释不够清晰时,这时候就可以去看规范了。一般这种情况,都是比较深入底层的问题,毕竟,规范是用来给浏览器开发者看的。
Web 平台的浏览器相关技术众多,由不同的组织来确定规范。 早在之前,关于 HTML 和 DOM 标准, W3C 和 WHATWG 都有各种的规范,这严重阻碍了 HTML 的发展。
W3C 希望发布一个 finished 版本的 HTML5,而 WHATWG 想要不断维护该规范而不是将已知问题冻结在某个版本
不过如今两个组织已达成一致,HTML 和 DOM 标准由 WHATWG 维护。
关于一项技术,如何确定对应的规范并找到规范文档,这里推荐一个网站:The Web platform: Browser technologies 。 其列举了 Web 平台的浏览器相关技术的标准文档和协议规范地址,包括以下几大模块:
- HTML,DOM,ECMAScript等核心模块
- CSS
- Canvas,SVG 等图形模块
- 多媒体
- 平台交互,事件及消息传递
- 文件和存储
- 实时通信模块
- Web Components
- HTML 额外收录模块,如 Drag and drop
- 性能优化与分析
- 安全和隐私
- 其他核心平台额外收录模块,如 Mutation observers
- HTTP,Cookies 等基础模块
- 各种其他的...
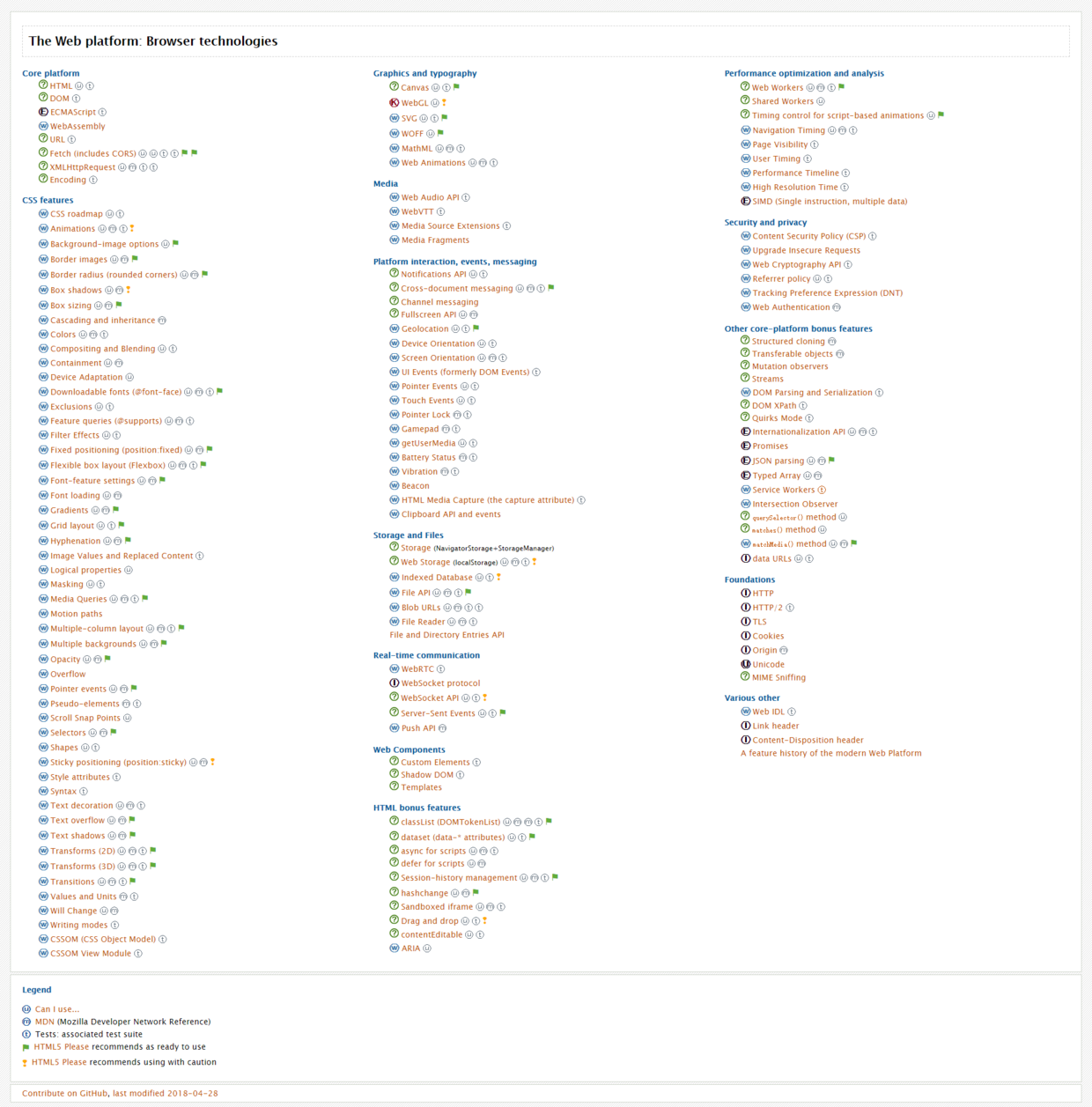
页面上用图标指出了各个技术规范的制定组织,以及在 caniuse 和 MDN 中的地址,同时给出了该项技术的使用建议--理解使用/谨慎使用
细心的同学可以发现,WebSocket API 等技术和 HTML 都是定义在同一规范文档 html.spec.whatwg.org/multipage/ 中,这个后文会说原因
当我们谈到 HTML 规范的时候,我们在说什么?
我们知道 html 是一种超文本标记语言,所以 HTML 规范指的是 html(包括文档,元素和语法) 的编码规范?
不是, HTML 规范 != HTML 编码规范 。HTML 规范是对包括 html 语言在内的多种技术的规范定义,是浏览器开发者必须遵循的标准,并提供上层接口供页面开发者使用。
HTML 规范是什么
The HTML Standard is a kitchen sink full of technologies for the web. It includes the core markup language for the web, HTML, as well as numerous APIs like Web Sockets, Web Workers, localStorage, etc.
HTML 规范是多种 Web 技术的集合。它包括用于 Web 的核心标记语言 HTML 以及 Web Sockets, Web Workers, localStorage 等众多API。相对于其他规范,它在 Web 平台的技术规范中的位置总结如下:

什么是 HTML5 ?
狭义上来说, HTML5 定义 HTML 标准的最新的版本,因此本文也可以说是 HTML5 标准
广义上来说, HTML5 泛指现代 Web 技术,包括本文所定义的标准外,还有其他如 Notifications API, WebRTC 等等
相关的还有 h5 这个名词,在国内偏向于指代移动端的 web 页面的解决方案
整体结构
本节介绍 HTML 规范的整体结构。
对于每一小节,会先介绍主体内容,然后列出相关技术点方便以后查找,可能还会给出注意事项
先上目录:
- 概述
- 通用基础结构
- HTML 文档的语义、结构及API
- HTML 元素
- Microdata
- 用户交互
- 页面加载
- Web 应用 API
- 通信
- Web workers
- Web 存储
- HTML 语法
- XML 语法
- 渲染
- 废弃的特性
- IANA 注意事项
需要重点看的有:7,8
1. 概述
介绍本规范的结构,提供阅读说明及排版。
简单介绍了跨站通信和html的编写以及常见的语法错误
提供了用于发现 HTML 错误的工具 -- HTML Conformance Checkers
2. 通用基础结构
提供了术语说明和依赖的定义
规则中依赖的其他规范的定义都会在本节做个概要描述
case-sensitive 表示区分大小写的字符串比较
定义了策略控制功能,如 autoplay, document-domain
定义了常见的 microsyntaxes ,一些语法类型的问题可以看这里
HTML 中有很多地方接受特定的数据类型,如日期和数字,本节描述了对应类型内容应符合的标准,以及如何解析
定义了 URL ,描述了解析过程,以及 base URLs 变动后的效果
仅表层介绍,具体的需要调整至 URL 规范中查看
定义了资源获取,包括同/跨域类型定义,资源类型确定,meta 元素字符编码提取过程,CORS 设置属性,referrer 属性,nonce 属性
定义了通用 DOM 接口,包括 IDL 属性获取和设置,HTMLCollection 等集合接口,DOMStringList 接口,Document 的垃圾回收
定义了结构化数据,包括可序列化对象和可传输对象等
这一小节属于比较底层了
3. HTML 文档的语义、结构及API
介绍了 HTML 文档的生命周期,一个 HTML 文档表现为一个 Document 对象,其上有各种属性如元数据管理,DOM 树访问器,动态标记插入,用户交互及 onreadystatechange
关于 Document, HTML 标准在 DOM 标准之上进行了拓展
enum DocumentReadyState { "loading", "interactive", "complete" };
typedef (HTMLScriptElement or SVGScriptElement) HTMLOrSVGScriptElement;
[OverrideBuiltins]
partial interface Document {
// resource metadata management 资源元数据管理
[PutForwards=href, Unforgeable] readonly attribute Location? location;
attribute USVString domain;
readonly attribute USVString referrer;
attribute USVString cookie;
readonly attribute DOMString lastModified;
readonly attribute DocumentReadyState readyState;
// DOM tree accessors DOM 树访问器
getter object (DOMString name);
[CEReactions] attribute DOMString title;
[CEReactions] attribute DOMString dir;
[CEReactions] attribute HTMLElement? body;
readonly attribute HTMLHeadElement? head;
[SameObject] readonly attribute HTMLCollection images;
[SameObject] readonly attribute HTMLCollection embeds;
[SameObject] readonly attribute HTMLCollection plugins;
[SameObject] readonly attribute HTMLCollection links;
[SameObject] readonly attribute HTMLCollection forms;
[SameObject] readonly attribute HTMLCollection scripts;
NodeList getElementsByName(DOMString elementName);
readonly attribute HTMLOrSVGScriptElement? currentScript; // classic scripts in a document tree only
// dynamic markup insertion 动态标记插入
[CEReactions] Document open(optional DOMString unused1, optional DOMString unused2); // both arguments are ignored
WindowProxy? open(USVString url, DOMString name, DOMString features);
[CEReactions] void close();
[CEReactions] void write(DOMString... text);
[CEReactions] void writeln(DOMString... text);
// user interaction 用户交互
readonly attribute WindowProxy? defaultView;
boolean hasFocus();
[CEReactions] attribute DOMString designMode;
[CEReactions] boolean execCommand(DOMString commandId, optional boolean showUI = false, optional DOMString value = "");
boolean queryCommandEnabled(DOMString commandId);
boolean queryCommandIndeterm(DOMString commandId);
boolean queryCommandState(DOMString commandId);
boolean queryCommandSupported(DOMString commandId);
DOMString queryCommandValue(DOMString commandId);
// special event handler IDL attributes that only apply to Document objects
// 只适用于 Document 对象的特殊事件处理器 IDL 属性
[LenientThis] attribute EventHandler onreadystatechange;
// also has obsolete members
};
Document includes GlobalEventHandlers;
Document includes DocumentAndElementEventHandlers;
通过了解这个,我们能更清楚的知道文档的组成,对 document 属性有疑问的都可以看本节
介绍了 HTML 元素,规则仅表示含义,不涉及呈现,因此各个浏览器呈现出来的特定元素效果可能不一样。
HTML 元素的基本接口
[Exposed=Window]
interface HTMLElement : Element {
[HTMLConstructor] constructor();
// metadata attributes 元数据属性
[CEReactions] attribute DOMString title;
[CEReactions] attribute DOMString lang;
[CEReactions] attribute boolean translate;
[CEReactions] attribute DOMString dir;
// user interaction 用户交互
[CEReactions] attribute boolean hidden;
void click();
[CEReactions] attribute DOMString accessKey;
readonly attribute DOMString accessKeyLabel;
[CEReactions] attribute boolean draggable;
[CEReactions] attribute boolean spellcheck;
[CEReactions] attribute DOMString autocapitalize;
[CEReactions] attribute [TreatNullAs=EmptyString] DOMString innerText;
ElementInternals attachInternals();
};
HTMLElement includes GlobalEventHandlers;
HTMLElement includes DocumentAndElementEventHandlers;
HTMLElement includes ElementContentEditable;
HTMLElement includes HTMLOrSVGElement;
[Exposed=Window]
interface HTMLUnknownElement : HTMLElement {
// Note: intentionally no [HTMLConstructor]
// 注意:有意没有 [HTMLConstructor]
};
介绍了 HTML 命名空间中名称为 name 的元素的元素接口的确认规则
举例: xmp 元素原型是什么? 答案是 HTMLPreElement (继承自 HTMLElement )
介绍了元素构造器用于实现自定义元素
定义了内容模型,即每个 HTML 元素的内容(其 DOM 中的子节点)必须符合内容模型的要求
举例
<p><object><param><ins><map><a href="/">Apples</a></map></ins></object></p>
为了检查 a 元素中是否允许 "Apples",要检查内容模型。 a 元素的内容模型是透明的,map 元素也是, ins 元素也是,object 元素中 ins 元素所在的部分也是。 object 元素位于 p 元素中,后者的内容模型是 短语内容。 因此 "Apples" 是允许的,因为文本是短语内容。
介绍了通用属性,所有 HTML 元素都可以使用,如 contenteditable,style,title,dir,lang
介绍了 innerText 的执行步骤
4. HTML 元素
每个元素都有一个预定义的含义,本章便解释了这些含义。 也给出了作者使用这些元素的规则,以及用户代理处理这些元素的要求。 这里包含了大量的 HTML 独有的特性,例如视频播放和副标题,表单控件和表单提交, 以及名为 HTML canvas 的 2D 图形 API。
有具体元素使用上的疑问可以在本章中查找
5. Microdata
本标准介绍了为文档增加机器可读注解的机制,这样工具可以从文档中抽取键值对的树。 这部分文档描述了该机制和用于将 HTML 文档转换为其他格式的一些算法。 这部分还为联系信息、日历事件和许可协议定义了一些示例的微数据词汇。
itemscope 上的使用有疑问,先看 MDN 再看本章
6. 用户交互
HTML Document 可以提供一些用户与内容交互以及用户修改内容的机制,在本章中给出了这些机制的描述。
提供了 hidden 属性的描述
display: block 可以覆盖 hidden 的效果
描述了惰性子树的概念
举个常见的例子,在A元素中 mouseDown 然后移动到 B 元素上并 mouseUp ,mouseMove 和 click 事件是在A元素上触发,B 是惰性的
描述了焦点的工作机制
这里的处理挺复杂的
描述了用于激活元素的指定快捷键 -- accesskey
描述了可编辑元素的相关接口和 API:contenteditable, designMode, execCommand, inputmode
描述了元素拖拽的相关接口和处理过程,其中部分章节是非规范的,所以浏览器间的实现会有差异
7. 页面加载
这部分定义了很多影响处理多页面环境的特性。要深入理解浏览器的运行过程,本章节需要细读。
描述了浏览上下文的定义和分类,包括嵌套浏览上下文(iframe)和辅助浏览上下文(window.opener)
描述了 Window, WindowProxy, 和 Location 对象的安全基础设施
这里介绍了 window.open 等方法的执行机制
介绍了 Origin 的定义和同源判断算法,以及 document.domain 赋值描述
介绍了沙盒机制(sandboxing)
介绍了会话历史和导航接口: history 和 location
描述了浏览上下文导航和页面加载处理模型
描述了离线应用缓存。
8. Web 应用 API
这部分介绍了 HTML 应用脚本的基本特性。也是需要重点细读的章节
介绍了脚本,包括 javascript: URL ,启用禁用脚本,脚本处理模型,Event Loops 和浏览器事件
Event Loops 一节还讲述了和渲染引擎的交互
介绍了 WindowOrWorkerGlobalScope mixin,描述了全局对象上公开的 API
typedef (DOMString or Function) TimerHandler;
interface mixin WindowOrWorkerGlobalScope {
[Replaceable] readonly attribute USVString origin;
// base64 工具方法
DOMString btoa(DOMString data);
ByteString atob(DOMString data);
// timers
long setTimeout(TimerHandler handler, optional long timeout = 0, any... arguments);
void clearTimeout(optional long handle = 0);
long setInterval(TimerHandler handler, optional long timeout = 0, any... arguments);
void clearInterval(optional long handle = 0);
// microtask queuing
void queueMicrotask(VoidFunction callback);
// ImageBitmap
Promise<ImageBitmap> createImageBitmap(ImageBitmapSource image, optional ImageBitmapOptions options);
Promise<ImageBitmap> createImageBitmap(ImageBitmapSource image, long sx, long sy, long sw, long sh, optional ImageBitmapOptions options);
};
Window includes WindowOrWorkerGlobalScope;
WorkerGlobalScope includes WindowOrWorkerGlobalScope;
其中介绍了 Base64 工具方法 , Timers 执行过程,microtask 和 ImageBitmap 处理
介绍了动态标记插入
万恶的 document.write
介绍了用户提示窗口方法: alert,confirm,prompt 的内部处理和 print 打印机提示方法
可以了解这些方法执行时再事件循环中的处理是怎样的
介绍了系统状态和功能 Navigator ,描述了基本功能接口和自定义方案处理程序
因此浏览器可以通过自定义方案处理程序拓展功能,如 geo , gamepads
最后介绍了动画帧,定义了 requestAnimationFrame 和 cancelAnimationFrame
9. 通信 API
这部分描述了 HTML 编写的应用可用来与同一客户端中的,不同域名的其他应用通信的一些机制。 也介绍了一个服务器推送事件流机制,称为 Server Sent Events 或 EventSource, 以及一个为脚本提供的双向全双工套接字协议,称为 Web Sockets。
首先介绍了继承自 Event 的 MessageEvent 接口,本章介绍的事件消息都是基于 MessageEvent 接口
介绍了服务器发送的事件,引入了 EventSource 接口定义和实现
介绍了 Web sockets 的组成和内部处理
引入了 postMessage 跨文档通信,用来解决非同源文档间通信问题,且不会造成跨站脚本攻击
介绍了 MessageChannel 通道用来实现不同浏览上下文之间代码通信
最后介绍了向其他浏览上下文广播的方案 BroadcastChannel
10. Web workers
这部分定义了 JavaScript 后台线程的 API。
描述了一些使用场景,如数字密集型计算,共享 worker
描述了作用域和事件循环
描述了可用的 API
11. Web storage
这部分定义了一个基于键值对的客户端存储机制。
定义了我们常用的 API: localStorage 和 sessionStorage 以及 storage 事件
两者的区别是 sessionStorage 在浏览器关闭后内容会消失
描述了 storage 的可用磁盘空间,不过标准没有给出具体值,只是建议每个域 5M 的限制(未压缩前)
描述了 storage 的隐私和安全问题
12. HTML 语法
本章描述有 HTML MIME type 标注的资源的语法规则
介绍了文档的组成部分,包括 DOCTYPE 和 Elements 类型。描述了标签和属性的解析规则
描述了 HTML 文档解析的处理模型,包括错误处理,输入字节流,解析状态,Tokenization 和树结构等
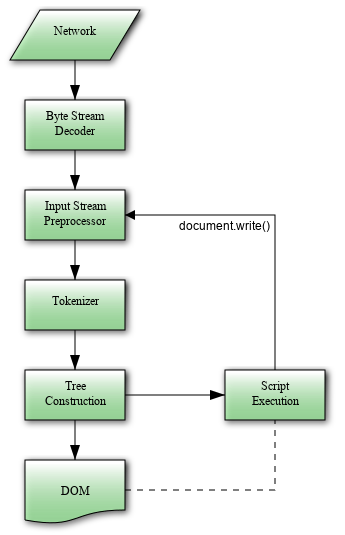
从图中也可看出 html 解析和脚本执行的关系
脚本执行会阻塞 DOM 的解析,试想下,不阻塞的话,脚本中修改了 DOM 那还得调整原来构建的 DOM 树
描述了 HTML 片段的序列化和解析
13. XML 语法
本章描述 XML 资源的语法规则,主要是描述 XML 文档的解析,以及 XML 片段的序列化和解析
14. 渲染
这部分定义了 Web 浏览器默认的渲染规则。
注意,本章仅是建议,没有要求浏览器必须这样实现
因此,各种渲染引擎的效果不一样是按规范来
本章更多的是讲元素的预期渲染效果,渲染引擎机制请看 Event Loops 一节
15. 废弃的特性
包括三部分
- 过时但仍可用的特征,如在 img 上指定 border 属性
- 不可用的特征,如使用 applet 元素(应该用 embed 代替)
- 一些元素,API 应该实现的接口
这部分内容比较针对浏览器开发者
16. IANA considerations
本章主要描述使用资源类型和协议时的一些注意事项
问题记录
Q1. 页面跳转和导航的代码执行问题
下面代码分别输出什么,为什么?请从浏览上下文和事件循环等角度分析。
function onClick1(){
window.open('https://www.baidu.com')
console.log("onClick1")
}
function onClick21(){
location.href = "https://www.baidu.com"
console.log("onClick21")
}
function onClick22(){
location.href = "https://www.baidu.com"
// 3s
let start = +new Date
while(+new Date - start< 3*1000){}
console.log("onClick22")
}
function onClick23(){
// 未能加载成功的网站
location.href = "https://sssss"
// 3s
let start = +new Date
while(+new Date - start< 3*1000){}
console.log("onClick23")
}
function onClick3(){
history.back()
// 3s
let start = +new Date
while(+new Date - start< 3*1000){}
console.log("onClick3")
}
Answer
onClick21 onClick23 onClick3 会输出
仅以 chrome 的实现为例,每个标签页都是独立的用户代理(user agent)
首先,页面 A 存在着(至少)一个浏览上下文,并对应着一个 Event Loop
考虑嵌套浏览上下文和辅助浏览上下文,所以这边用的是至少
页面 A 中执行了某段同步代码(一个Task),在其中调用了 window.open 方法,该方法是立即执行的
内部做了很多处理,可以点链接看看
执行完毕 ,此时会创建一个新的浏览上下文以及对应的 Event Loop
如果 页面 A 采用 opener 参数打开的页面 B,则页面 B 还有一个辅助浏览上下文,指向页面 A 的浏览上下文,共用同一个 Event loop??
如果要加载的文档是 html ,页面 B 的用户代理会排一个 Task 创建 Document 对象,标记为 HTML 文档,其后读取和解析文档。
location 跳转
location 是同步执行的,后台线程等解析完文档就会跳转,不会等后面的同步代码。通常我们后面的同步代码很快执行,所以会误以为 location 是异步执行的
详见 stackoverflow 和 设置location.href,为什么不会立即跳转? - 知乎
PS: 还没详细看规范,不知道是不是这样处理
history 跳转是一个 Task,因此它会在本次同步代码执行完毕后才执行
这个看运行时环境实现,可能其他任务还会先与该 Task 前执行
总结: window.open 和 location.href 不属于 Web API 的范畴,也就不走 event loop 那一套
未完待续...
