


K最近邻算法
- 橙子还是柚子
- 创建推荐系统
- 特征抽取
- 回归
- 挑选合适的特征
- 机器学习简介
- 小结
橙子还是柚子
我们在日常生活中如何区分是橙子还是柚子呢?我知道通常柚子比橙子更大、更黄。
我的思维过程类似于这样:
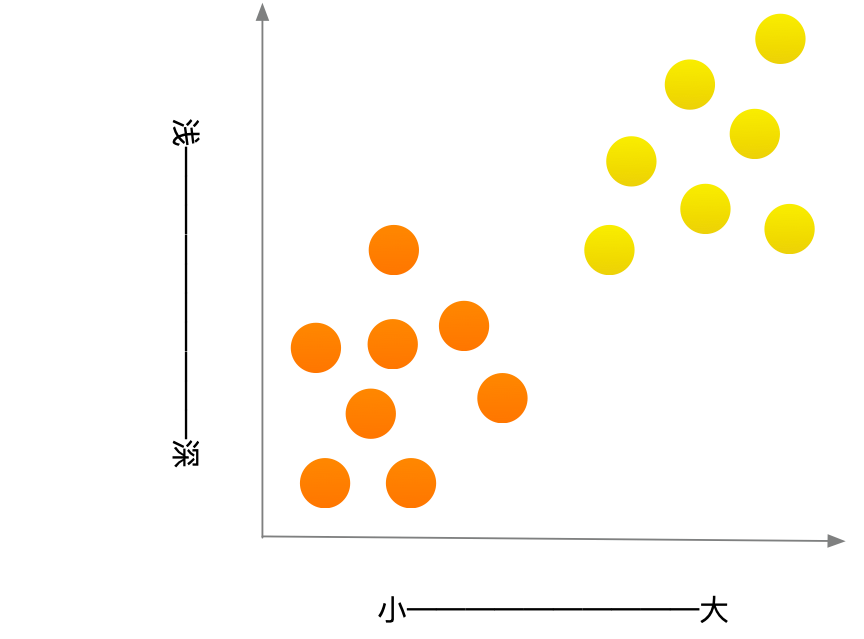
一般而言,柚子更大,颜色更浅。这个水果又大又红,因此很有可能是柚子。但下面这样的水果x呢?
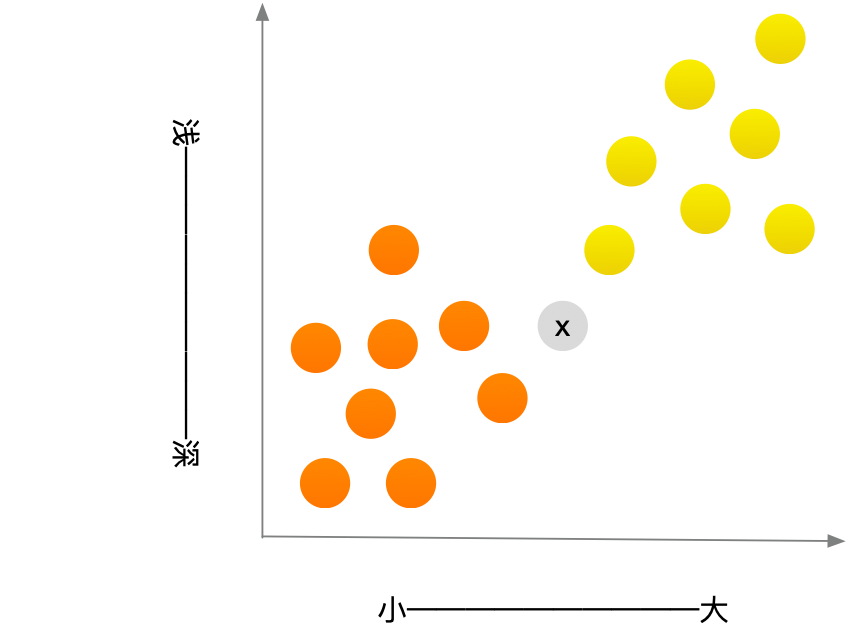
如何判断这个水果是橙子还是柚子呢?一种办法就是看它的邻居
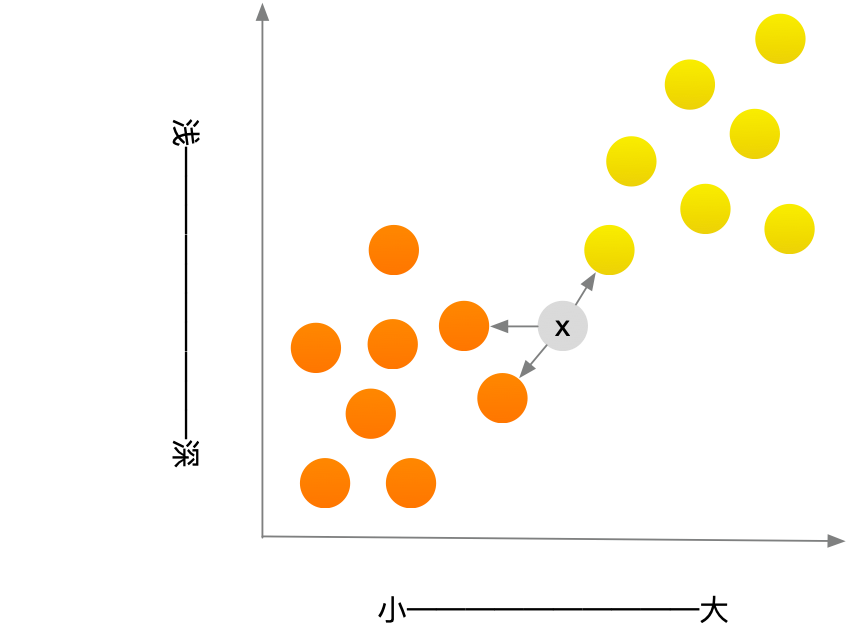
在这三个邻居中,橙子比柚子多,因此这个水果可能是橙子。祝贺你,你刚才就是使用K最近邻(k-nearest neighbours, KNN)算法进行了分类!这个算法非常简单吧!
KNN 算法虽然简单但却很有用!要对东西进行分类时,可首先尝试这种算法。下面来看一个更真实的例子。
创建推荐系统
假设你是小王,要为用户创建一个电影推荐系统,从本质上说,这类似于前面的水果的问题,你可以将全部用户放入一个图标中。
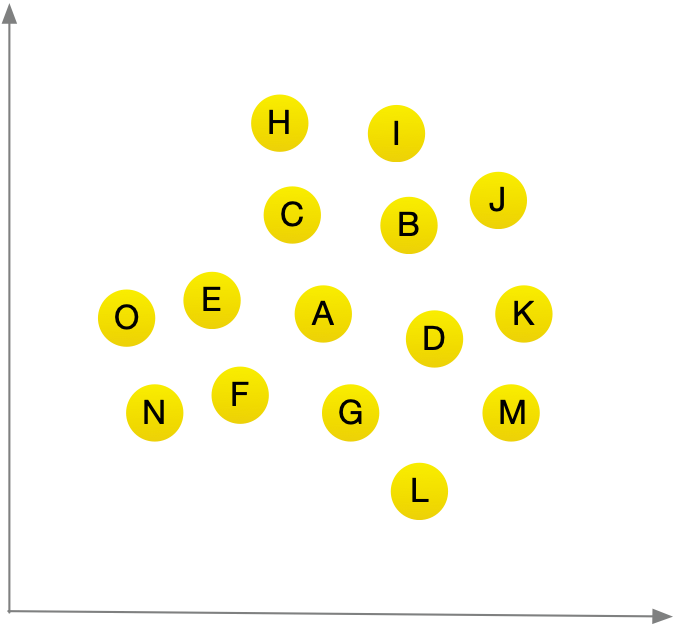
假设你要向A用户推荐电影,可以找出与他最近的用户
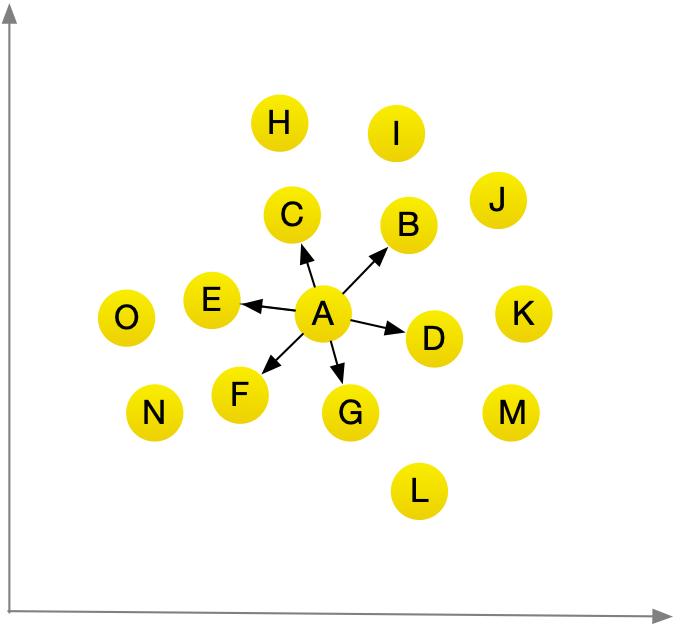
假在对电影喜好方面B,C,D,E,F,G 都与A用户差不多,因此他们喜欢的电影很可能是 A喜欢的电影。 有了这样的图标后,创建推荐系统就易如反掌了。
还有一个重要的问题没有解决,在前面的图标中,相似的用户距离较近,但如何确定两位用户的相似程度呢?
特征抽取
在前面的推荐系统中,是根据用户电影的喜好程度进行绘图的。对于每一位用户,都将获得一组数字!
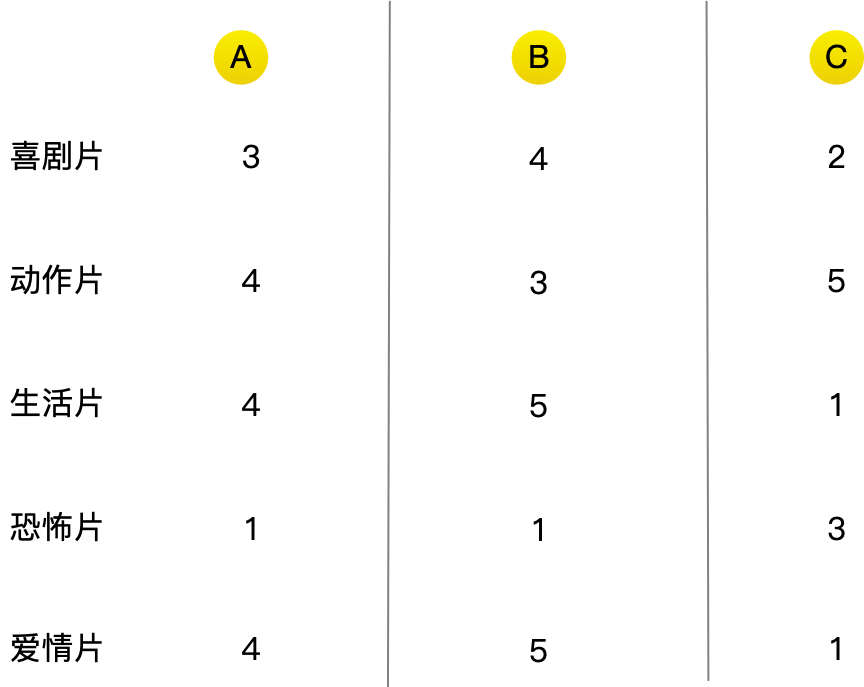
根据毕达哥拉斯公式
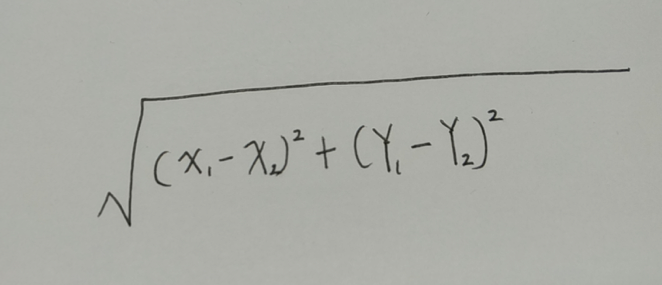
A和B 的相似度为
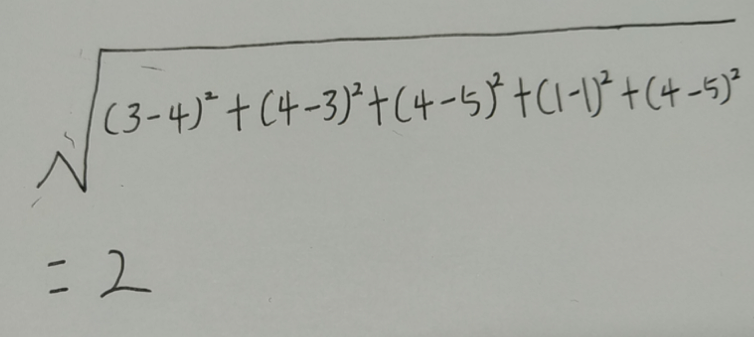
A和C 的相似度为
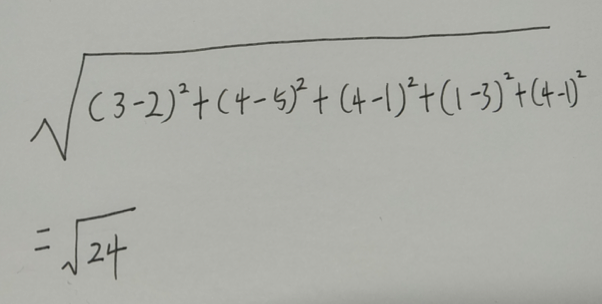
我们很容易发现A和B用户更为电影喜好程度更接近,只要是A用户喜欢的电影我们就可以推荐给B,反之亦然,你就创建了一个电影推荐系统。
回归
如果你不仅要向A用户推荐电影,还要预测他将给这部电影打多少分。为此,先找出与他最近的6人。
顺便说一句,其实并非一定要选取6个最近的邻居,也可以选择2个、10个或者10000个。
假设你要预测A用户会给电影打多少分,先看一下他的邻居都给这个电影打了多少分。
- B: 5
- C: 4
- D: 4
- E: 5
- F: 3
- G: 3
求这些人打的分的平均值:4,这就是回归。你将使用KNN来做两项基本工作——分类和回归:
- 分类就是分组
- 回归就是预测结果
回归很有用,假设你在伯克利开个小小的面包店,每天都会做新鲜的面包,需要根据如下特征预测当天该烤多少条面包:
-
天气指数1-5(1表示天气很糟糕,5表示天气非常好)
-
是不是周末或节假日(周末或节假日为1,否则为0)
-
有没有活动(1表示有,0表示没有) 你有一些历史数据,记录了在不同日子里售出的面包的数量。
-
A--(5,1,0) => 300
-
B--(3,1,1) => 225
-
C--(1,1,0) => 75
-
D--(4,0,1) => 200
-
E--(4,0,0) => 150
-
F--(2,0,0) => 50
今天是周末,天气不错。根据这些数据,预测你今天能售出多少条面包呢?我们来使用KNN算法,其中的K为4.首先,找出与今天最近的四个邻居。
(4,1,0)=> ?
根据毕达哥拉斯公式算出近似度
- A => 1
- B => 1.41
- C => 3
- D => 1.41
- E => 1
- F => 2.23
因此距离最近的邻居为A、B、D、E
将这些天的面包数平均,结果为218.75.
余弦相似度
前面计算两位用户的距离时,使用的都是距离公式。还有更合适的公式吗?在实际工作中,经常使用余弦相似度(cosine similarity).假设有两位品味类似的用户,但其中一位打分时更保守。他们都很喜欢 Manmohan Desai的电影 Amar Akbar Anthony, 但 用户A给了5星,而用户B只给了4星。如果你是用距离公式,这两位用户可能不是邻居,虽然他们品味很接近。
余弦相似度不计算两个矢量的距离,而比较他们的的角度,因此更适合处理前面所说的情况。在这里不讨论余弦相似度。但如果你要使用KNN,就一定要研究研究它。
挑选合适的特征
为推荐电影,你让用户指出他对各类电影的喜好程度,如果是让用户给一系列小猫图片打分呢?在这种情况下,你找出的是对小猫图片欣赏品味类似的用户。对电影推荐系统来说,这可能是一个糟糕的推荐引擎,因为你选择的特征与电影欣赏品味无多大关系。
又假设你只让用户给《玩具总动员》、《玩具总动员2》和《玩具总动员3》打分。这将难以让用户的电影欣赏品味显现出来!使用KNN时,挑选合适的特征进行比较至关重要。所谓合适的特征,就是:
- 与要推荐的电影紧密相关的特征
- 不偏不倚的特征(例如,如果只让用户给喜剧打分,就无法判断他们是否喜欢动作片)。
机器学习简介
KNN算法真的是很有用,堪称你进入神奇的机器学习领域的领路人!机器学习旨在让计算机更聪明。你见过一个机器学习的例子:创建推荐系统。下面再来看一些其他例子。
OCR
OCR指的是光学字符识别(optical character recognition),这意味着你可以拍摄印刷页面的照片,计算机将自动识别出其中的文字。Google使用OCR来实现图书数字化。OCR是如何工作的呢?我们来看一个例子。请看下面的数字。
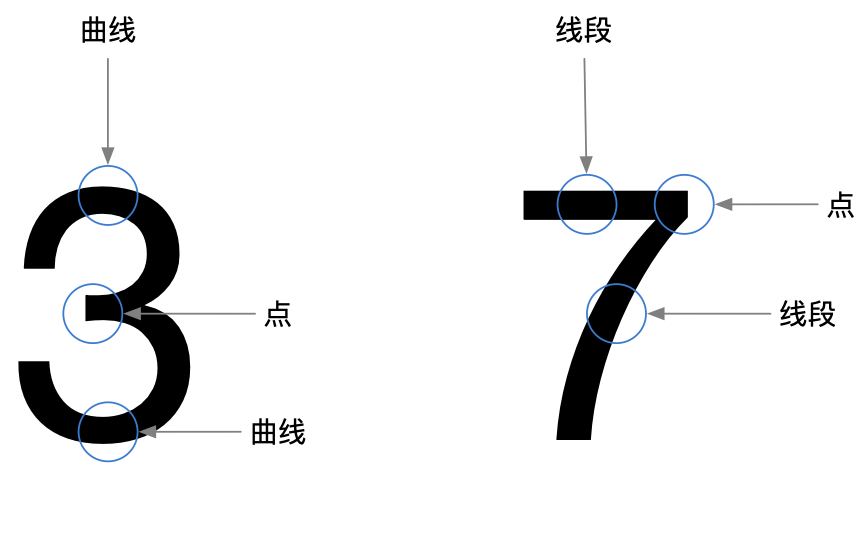
如何自动识别出这个数字是什么呢?
- 浏览大量的数字图像,将这些数字的特征提取出来,OCR算法提取线段、点、曲线等特征。
- 遇到新图像时,你提取该图像的特征,再找出它最近的邻居是谁!
与前面的水果示例相比,OCR中的特征提取要复杂的多,但再复杂的技术也是基于KNN等简单理念的。这些理念也可用于语音识别和人脸识别。你将照片上传到facebook时,它能够自动标出照片中的人物,这是机器学习在发挥作用!
OCR的第一步是查看大量的数字图像并提取特征,这被称为训练(training).大多数机器学习算法都包含训练的步骤:要让计算机完成任务,必须先训练它。
创建垃圾邮件过滤器
垃圾邮件分类使用一种简单算法--朴素贝叶斯分类器(Naive Bayes classifier),你首先需要使用一些数据对这个分类器进行训练。
| 主题 | 是不是垃圾邮件 |
|---|---|
| RESET YOUR PASSWORD | 不是 |
| YOU NAME WON 1 MILLION DOLLARS | 是 |
| SEND ME YOUR PASSWORD | 是 |
| HAPPY BIRTHDAY | 不是 |
假设你收到一封主题为 “collect you million dollars now!” 的邮件,这是垃圾邮件吗?你可以研究这个句子的每一个单词,看看它在垃圾邮件中出现的概率是多少。例如,使用这个非常简单的模型时,发现只有单词million在垃圾邮件中出现过。朴素贝叶斯分类器能计算出邮件为垃圾邮件的概率,其应用领域与KNN相似。
小结
希望大家通过阅读本文,你对KNN和机器学习的各种用途能有大致的认识!机器学习是个很有趣的领域,只要下定决心,你就能很深入地了解它。
- KNN用于分类和回归,需要考虑最近的邻居。
- 分类就是编组。
- 回归就是预测结果。
- 特征抽取意味着将物品(如水果或用户)转换为一系列可比较的数字。
- 能否挑选合适的特征事关KNN算法的成败。