

本文来自OPPO互联网技术团队,是《剖析Spark数据分区》系列文章的第一篇,将重点分析Hadoop分片。本系列共三篇文章,敬请关注。
-
第一篇:主要分析Hadoop中的分片;
-
第二篇:主要分析Spark RDD的分区;
数据分析师通常会发出这样的疑问?我的任务之前通常半小时就能得出结果,现在要3个小时才能出结果。
为什么变慢了?我的SQL没有变更,是不是集群出问题了?
针对这种问题,大数据运维工程师通常会说,数据量不一样,在资源相同的条件下,数据量多的任务肯定要比数据量少的任务执行时间长,可以适当把资源调整一下。
Spark任务常用参数:

那么我们有没有其他方法能让计算任务在数据量很大的情况下也能轻松应对,执行时间不会有明显的提高?
答案就是合理分区即Partition,合理分区能够让任务的task数量随着数据量的增长而增大,提高任务的并发度。
下面OPPO互联网技术团队的工程师们将从源码层面解决解答数据分析师们的疑惑。
在这里,我们结合Hadoop, Spark, SparkStreaming + Kafka, Tispark源码详细的分析一下出现这种问题的原因。
本篇文章属于一个系列的一部分,该系列共分3篇文章,欢迎持续关注。
- 第一篇:主要分析Hadoop中的分片;
- 第二篇:主要分析Spark RDD的分区;
- 第三篇:主要分析Spark Streaming,TiSpark中的数据分区;
01 核心原理分析
我们先来看一下上述几个组件在整个Hadoop生态体系中的位置。
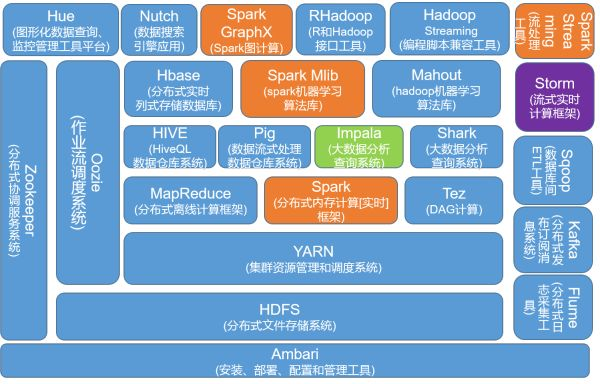
Yarn作为整个大数据集群的核心,也是任务调度,计算资源分配的核心,接下来了解一下Container。
Yarn Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。
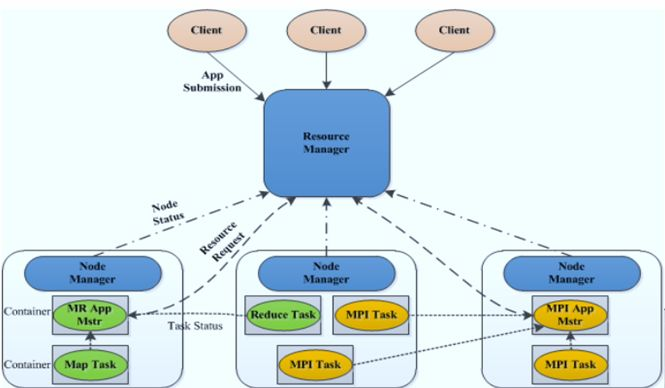
YARN会为每个任务分配Container,且该任务只能使用该Container中描述的资源。与MRv1中的slot不同的是,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。
实际上在spark任务中一个executor相当于一个运行中的container。
一个excution container就是一系列cpu资源,内存资源的JVM进程,task作为excution container的jvm进程中的一个线程执行,一个JVM进程可以有多个线程,一个excution container中可以运行多个task,而partition又决定了task数量。
我们将从Hdfs中的数据分片开始,逐步分析Partition。
Hadoop InputSplit
首先我们分析一下在HDFS中,数据的组织形式。
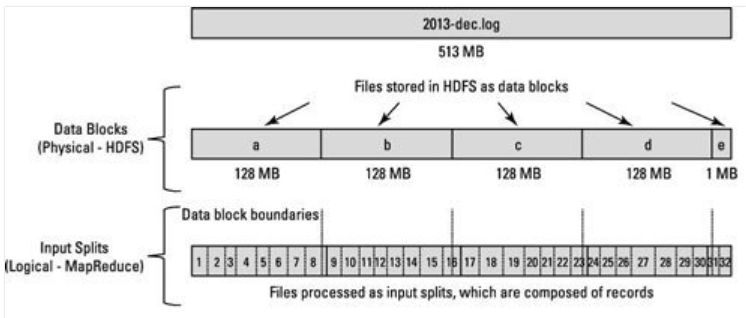
HDFS是以固定大小的Block为基本单位存储数据,Block块是以Block size进行切割,当前从2.7.3版本开始Block size的默认大小为128M,之前版本的默认值是64M, 可以通过修改hdfs-site.xml文件中的dfs.blocksize对应的值。
值得注意的是:在修改HDFS的数据块大小时,首先需要停掉集群hadoop的运行进程,修改完毕后重新启动。
假设逻辑记录大小分别是 100MB,100MB, 100MB。
那么第一条记录可以完全在一个块中,但是第二条记录不能完全在一个块中,第二条记录将同时出现在两个块中,从块1开始,溢出到块2中。
如果每个Map任务处理特定数据块中的所有记录,那怎么处理这种跨越边界的记录呢?
在这种情况下Mapper不能处理第二条记录,因为块1中没有完整的第二条记录,HDFS内部并不清楚一个记录什么时候可能溢出到另一个块。(Because HDFS has no conception of what’s inside the file blocks, it can’t gauge when a record might spill over into another block.)
InputSplit就是解决这种跨越边界记录的问题的。
InputSplit是一个逻辑概念,并没有对实际文件进行切分,它只是包含一些元数据信息,比如数据的起始位置,数据的长度,数据所在的节点等。然而InputSplit所作出的切分结果将会直接影响任务的并发度。
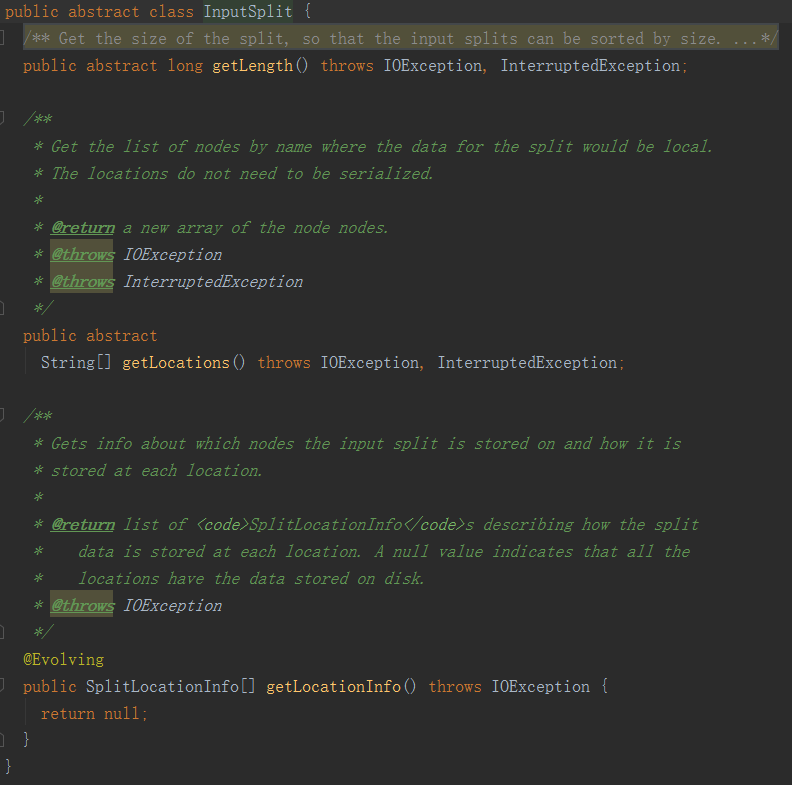
当Mapper尝试读取数据时,它清楚的知道从何处开始读取以及在哪里停止读取。InputSplit的开始位置可以在一个块中开始,在另一个块中结束。
InputSplit代表了逻辑记录边界,在MapReduce执行期间,Hadoop扫描块并创建InputSplits,并将每个InputSplit分配给一个Mapper处理,可以得出,一个InputSplit对应一个MapTask。
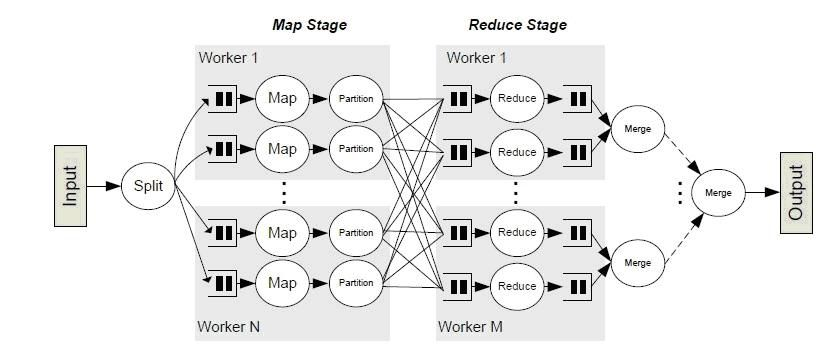
MapReduce
Map通过 RecordReader 读取Input的key/value对,Map根据用户自定义的任务,运行完毕后,产生另外一系列 key/value,并将其写入到Hadoop的内存缓冲取中,在内存缓冲区中的key/value对按key排序,此时会按照Reduce partition进行,分到不同partition中。
Reduce以 key 及对应的 value 列表作为输入,按照用户自己的程序逻辑,经合并 key 相同的 value 值后,产生另外一系列 key/value 对作为最终输出写入 HDFS。
Hadoop Partition
在MapReduce任务中,Partitioner 的作用是对 Mapper 产生的中间结果进行分片,以便将同一分组的数据交给同一个 Reducer 处理。
在MapReduce任务中默认的Partitioner是HashPartitioner,根据这个Partitioner将数据分发到不同的Reducer中。
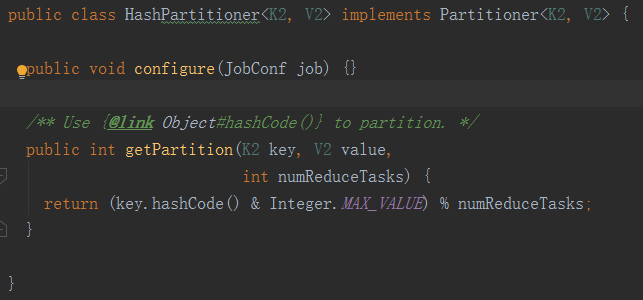
HashPartitioner使用hash方法(比如常见的:hash(key) mod R)进行分区,hash方法能够产生非常平衡的分区。
那么在MR任务中MapTask数量是怎么决定的呢?
由于一个Split对应一个map task,我们来分析一下FileInputFormat类getInputSplit切片逻辑。
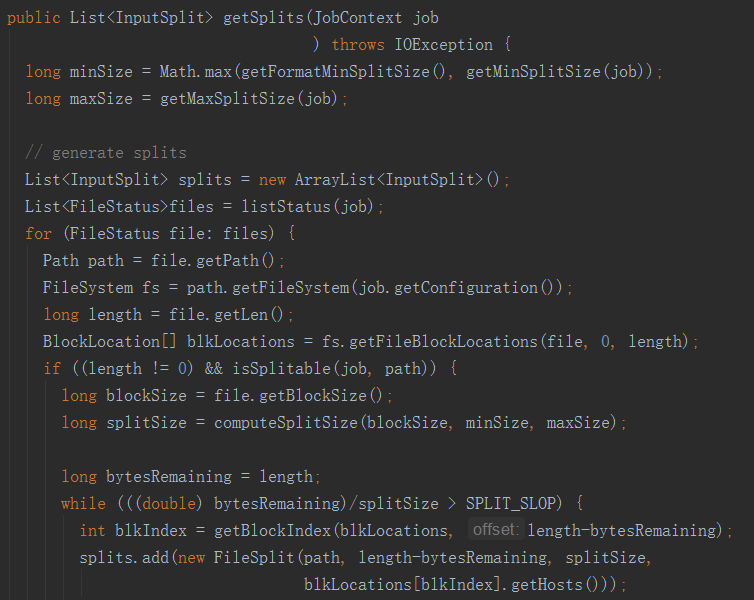
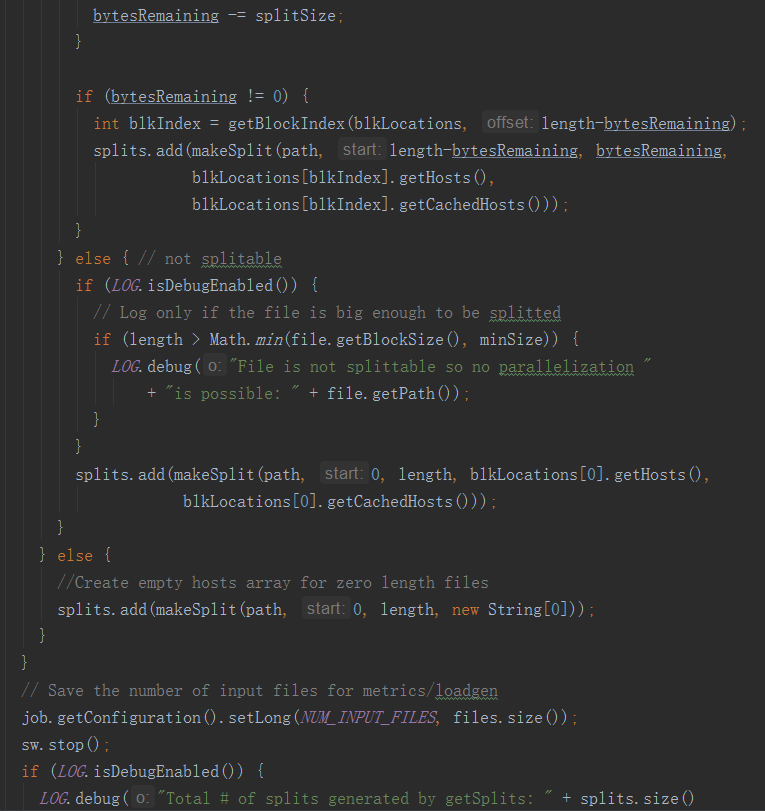
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:
Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定
minsize:
默认值:1
配置参数:
mapreduce.input.fileinputformat.split.minsize;
maxsize:
默认值:Long.MAXValue
配置参数:
mapreduce.input.fileinputformat.split.maxsize;
blocksize;
因此,默认情况下,切片大小=blocksize;
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值;
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大;
通过上述分析可知,可以通过调整
mapreduce.input.fileinputformat.split.minsize&
mapreduce.input.fileinputformat.split.maxsize
的大小来调整MapTask的数量。
02 结语
Hadoop作为当前主流大数据的基石,HDFS通常作为Spark任务的数据来源,要想深刻的理解Spark中的数据分区必须理解HDFS上的数据分片。
作为大数据工程师,理解原理,理解调优参数背后的逻辑并加以应用将使我们的任务跑的更快,使我们的大数据集群在相同的计算能力前提下能够运行更多的任务。
下一篇文章中,OPPO互联网技术团队将从源码层面重点分析Spark RDD的 Partition的实现原理与优化策略,敬请期待。

