


在线体验地址:hksite.cn/prjs/christ…
写在开头
叮叮当,叮叮当,吊儿个郎当,一年一度的圣诞节到咯,我不由的回想起了前两年票圈被圣诞帽支配的恐惧。打开票圈全是各种@官方求帽子的:
票圈头像也瞬间被圣诞帽攻陷:
在那段时间,你没一顶圣诞帽还真不好意思发票圈

各种戴帽子的软件也如雨后春笋般浮现出来,不管是小程序还是美图软件无一例外的都增加了戴圣诞帽的功能。但是对于懒人的我来说,自己调整一个圣诞帽子佩戴还是太麻烦了。于是我就想了,有没有什么办法能让我的头像自动佩戴上圣诞帽呢?
还真给我想到了,这就是今天的主题,用纯前端的方式给你做一个自动佩戴圣诞帽的网站。
有了这个网站,你就能顺利在票圈装 13 了,不仅如此,你还可能因此邂逅一段完美的爱情!试想一下,当你发了这个网站在票圈后,女神看到了就会为你的技术所折服,然后主动把照片给你,让你帮她给头像戴上圣诞帽,然后你就顺利的得到了和女神搭讪的机会,然后赢取白富美,走向人生巅峰,想想还有点小激动呢。

给头像戴上圣诞帽需要几步
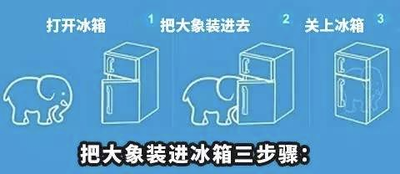
给头像佩戴上圣诞帽需要几个步骤呢?很简单,跟大象装进冰箱一样,只需要三个步骤:
- 打开头像
- 戴上圣诞帽
- 下载图片
其中第一步和最后一步看起来好像都不是什么难事,关键是这第二点,如何给头像戴上圣诞帽?
首先你必须要懂的,当我在说:戴上圣诞帽的时候,我在说什么?让我来翻译以下:
将圣诞帽的图片素材绘制在头像图片的合适位置,使之变成一张图片
所以我们今天的重点来了:如何能确定圣诞帽的位置,并将它和头像合成为一张图片。
首先让我们来聊聊如何确定圣诞帽的位置。
确定圣诞帽的位置
通过手动的方式,我们是很容易确定圣诞帽应该放在什么位置的,那机器如何能确定呢?有人可能想到了那不就是人脸识别技术?是的,这就是我们今天需要用到的技术。
早在 2017 年之前,纯前端说想实现人脸识别还有点天方夜谭的感觉,但是 Tensorflow.js 的出现让这一切成为了可能:

它是 Google 推出的第一个基于 TensorFlow 的前端深度学习框架。它允许你在浏览器上训练模型,或以推断模式运行预训练的模型。TensorFlow.js 不仅可以提供低级的机器学习构建模块,还可以提供高级的类似 Keras 的 API 来构建神经网络。
Tensorflow.js 是我第一个想到的可以应用的库,但是当我打开官方文档,看到如 Tensors (张量)、Layers (图层)、Optimizers (优化器)……各种陌生概念扑面而来,砸的人生疼,现学感觉是来不及了,那有什么办法能在我不了解各种概念的情况下也能快速上手人脸识别呢?
答案当然有,那就是:face-api.js。
face-api.js
face-api.js 是大神 Vincent Mühler 的最新力作,他为人所知的开源项目还有 opencv4nodejs ,face-recognize(NodeJs 的人脸识别包,不过现在 face-api.js 已经支持 Node 端了,他推荐直接使用 face-api)
face-api.js 是一个建立在 Tensorflow.js 内核上的 Javascript 模块,它实现了三种卷积神经网络(CNN)架构,用于完成人脸检测、识别和特征点检测任务。简而言之,借助它,前端也能很轻松的完成人脸识别的工作。
原理简析
想看实现的童鞋请直接略过这一段,直接开始上手操作。
我们知道机器学习有几个基本要素:数据,模型,算法。他们之间的关系如下:
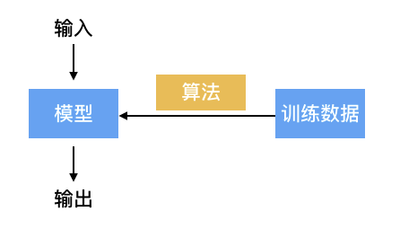
- 训练数据: 训练数据就是一系列打过标签的数据,比如一系列人脸和不是人脸的图片数据。
- 模型(这里我们主要指监督学习模型): 模型你可以简单理解为是一个预测函数(f(x) = y),简单来说就是根据输入的数据,能给出结果。
- 算法: 算法就是教机器如何获得最优的模型(损失最小)。比如当机器通过当前模型识别到一张训练图片为人脸,但是标签是「非人脸」,此时就需要根据算法对模型进行调整。常见的算法有例如:梯度下降法(Gradient Descent),共轭梯度法(Conjugate Gradient),牛顿法和拟牛顿法,模拟退火法(Simulated Annealing)……
所以,我们可以这么说,只要有了一个训练好的预测模型,我们就可以对未知数据进行分析预测了。
face-api 的原理
首先,为了在图片中识别出人脸,我们需要告诉机器什么样的脸是人脸,因此我们需要大量的人脸照片,并且标明里面的各种脸部特征数据,让机器去学习:

face-api.js 针对人脸检测工作实现了一个 SSD(Single Shot Multibox Detector)算法,它本质上是一个基于 MobileNetV1 的卷积神经网络(CNN),同时在网络的顶层加入了一些人脸边框预测层。
然后 face-api.js 会通过该算法让机器不断的学习并优化,从而训练出模型,通过该模型可以识别出所有的人脸边界框

光识别出人脸还远远不够,我们的很多应用都需要找到人脸的特征点(眉毛,鼻子,嘴巴这些的)。因此 face-api.js 会从图片中抽取出每个边界框中的人脸居中的图像,接着将其再次作为输入传给人脸识别网络,让其学习。
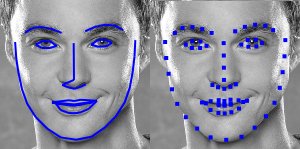
为了实现特征点识别这个目标,face-api.js 又实现了一个简单的卷积神经网络,它可以返回给定图像的 68 个人脸特征点:
通过该算法,face-api.js 训练了一系列的模型,通过使用这些已经训练好的模型,我们可以快速实现我们想要的功能。
face-api.js 的使用方法
引入方式
如果你不使用打包工具的话,可以直接导入 face-api.js 的脚本:dist/face-api.js 获得最新的版本,或者从 dist/face-api.min.js 获得缩减版,并且导入脚本:
<script src="face-api.js"></script>
如果你使用 npm 包管理工具,可以输入如下指令:
npm i face-api.js
初始化
我们之前说过,face-api 它实现了一系列的卷积神经网络,并针对网络和移动设备进行了优化。所有的神经网络实例在 faceapi.nets中获取到
var nets = {
ssdMobilenetv1: new SsdMobilenetv1(), // ssdMobilenetv1 目标检测
tinyFaceDetector: new TinyFaceDetector(), // 人脸识别(精简版)
tinyYolov2: new TinyYolov2(), // Yolov2 目标检测(精简版)
mtcnn: new Mtcnn(), // MTCNN
faceLandmark68Net: new FaceLandmark68Net(), // 面部 68 点特征识别
faceLandmark68TinyNet: new FaceLandmark68TinyNet(), // 面部 68 点特征识别(精简版)
faceRecognitionNet: new FaceRecognitionNet(), // 面部识别
faceExpressionNet: new FaceExpressionNet(), // 表情识别
ageGenderNet: new AgeGenderNet() // 年龄识别
};
其中 MobileNets 和 yolov2 是业内比较有名的目标检测算法,有兴趣的可以点击链接去看论文(我是看不懂),这篇文章 简要介绍了这些算法,大概就是说他们的检测速度和检测效率都不错。这里你可以根据自己的需要选择不同的算法,加载不同的模型。
官方推荐使用ssdMobilenetv1,因为它的识别精度比较高,但是检索速度相对较慢,如果是实时检测的场景,它的检索速度可能会成为问题,因此,今年下半年作者把 MTCNN 算法也引入了,如果想用实时人脸检测的场景,可以试试 MTCNN。(可以看看作者 这篇文章)
模型加载
通过之前的介绍我们也可以知道,模型才是重中之重,有了训练好的模型,我们就可以跳过训练的阶段,直接使用来做人脸识别了。
这也就是国外一个机器学习的布道者 Dan Shiffman 在 视频 中一直所强调的:并不是所有的机器学习入门都应该从学习算法入手,毕竟术业有专攻,目前已经有很多人建立了很多成熟的模型(图形检测,文本识别,图像分类……),我们可以站在巨人的肩膀上去做更多有意思的事情。
face-api 本身也提供了一系列的模型数据(/weights),可以开箱即用:
await faceapi.nets.ssdMobilenetv1.load('/weights')
其中 /weights 是放了 manifest.json 和 shard 文件的目录,建议把官方的 weights 目录直接拷贝下来,因为经常你需要几个模型同时使用。
识别
face-api 提供了很多高级的方法可以使用,其中最方便的就是detectAllFaces / detectSingleFace(input, options) , 注意:它默认是使用SSD Mobilenet V1 ,如果要使用Tiny FaceDetector,需要手动指定:
const detections1 = await faceapi.detectAllFaces(input, new faceapi.SsdMobilenetv1Options())
const detections2 = await faceapi.detectAllFaces(input, new faceapi.TinyFaceDetectorOptions())
其中 detect 系方法都支持链式调用,因此你可以这样用:
await faceapi.detectAllFaces(input)
await faceapi.detectAllFaces(input).withFaceExpressions()
await faceapi.detectAllFaces(input).withFaceLandmarks()
await faceapi.detectAllFaces(input).withFaceLandmarks().withFaceExpressions()
获取识别数据
进行识别操作后,返回的数据是什么样的呢?
如果你是进行的全脸识别,那么数据是一个数组,其中 detection 是默认会有的属性,它提供了一个人脸部的盒子信息
[{detection:{
box: {
x: 156.22306283064717
y: 76.60605907440186
width: 163.41096172182577
height: 182.21931457519534
left: 156.22306283064717
top: 76.60605907440186
right: 319.63402455247297
bottom: 258.82537364959717
area: 29776.633439024576
topLeft: Point
topRight: Point
bottomLeft: Point
bottomRight: Point
}
……
}]
如果你进行了链式操作,比如 withFaceLandmarks() 那这个对象会增加一个landmarks的属性,以此类推。
[{detection, landmarks, ……}]
其中landmarks提供了获取脸部各种特征点的方法:
const landmarkPositions = landmarks.positions // 获取全部 68 个点
const jawOutline = landmarks.getJawOutline() // 下巴轮廓
const nose = landmarks.getNose() // 鼻子
const mouth = landmarks.getMouth() // 嘴巴
const leftEye = landmarks.getLeftEye() // 左眼
const rightEye = landmarks.getRightEye() // 右眼
const leftEyeBbrow = landmarks.getLeftEyeBrow() // 左眉毛
const rightEyeBrow = landmarks.getRightEyeBrow() // 右眉毛
处理识别数据
要知道,你拿到的数据是根据图片的真实数据来处理的,但我们在网页展示的图片通常不会是 1:1 的实际图片,也就是说图片会进行缩放/扩大处理。比如一张图片是 1000x1000 的,图片上的人脸嘴巴可能在(600,500)这个位置,但是我们实际展示的是 600x600 的图片,如果根据(600,500)这个坐标去画,那早就在画布外了。
因此如果我想要在图片上做一点事情,我们需要把当前的数据进行一个转换,让它的数据匹配特定的大小,这里,可以用它提供的 matchDimensions(canvas, displaySize) 和resizeResults(result, displaySize) 方法:
// 把 canvas 固定到 displaySize 的大小
faceapi.matchDimensions(canvas, displaySize)
// 把数据根据 displaySize 做转换
const resizedResults = faceapi.resizeResults(detectionsWithLandmarks, displaySize)
其中 displaySize 是一个拥有{ width, height }的对象,所以你也可以直接传入带 width 和 height 的 DOM 元素,如 <canvas />,<img />。
根据数据绘制图形
光拿到数据可没用,我们主要目的是为了绘制图形,在绘制这一块 face-api 也是提供了一系列高级方法,比如:
faceapi.draw.drawDetections(canvas, resizedDetections) // 直接在识别区域画个框
faceapi.draw.drawFaceLandmarks(canvas, resizedResults) // 直接画出识别的的特征点
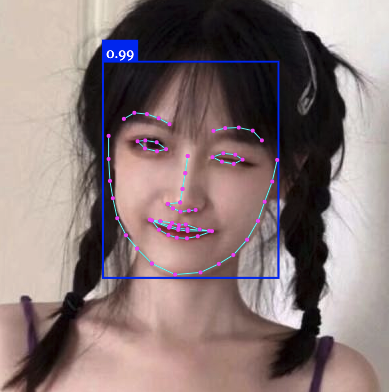
(以下测试图片均是采用从百度搜「女生头像」搜到的小姐姐,如有侵权,请告知)
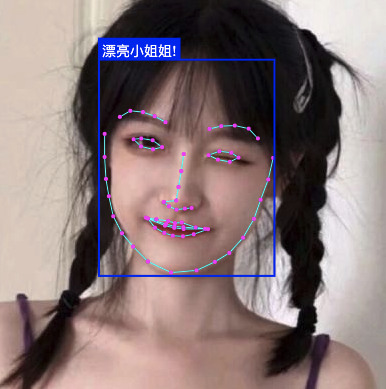
当然你还可以在特定位置画个框或文字,具体用法可以参考:DrawBox,DrawTextField
const drawOptions = {
label: 'Hello I am a box!',
lineWidth: 2
}
const drawBox = new faceapi.draw.DrawBox(resizedResults[0].detection.box, drawOptions)
drawBox.draw(canvas)
圣诞帽的绘制
说了这么多,突然发现还没到我们的主题,画圣诞帽!让我们赶紧回来。
确定圣诞帽的位置
现在假定我现在拥有了所有的面部数据,我应该如何确定圣诞帽的正确位置?首先,我们必须明确一点,圣诞帽应该是要戴在头顶的,应该没有人把圣诞帽戴在眉毛上吧?(好吧当我没说)

但是人脸识别的数据中一般是不包含头顶的,这可咋办?还好我小学一年级学过半个学期的素描,在素描中有个很重要的概念叫三庭五眼
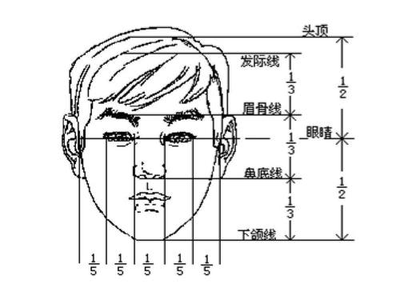
也是说正常人的发际线到眉骨的距离是眉骨到下颌距离的一半(作为程序猿的我表示,该规则可能已经不适用了)。
因此我们可以通过获取眉毛的坐标和下颌的坐标来计算出头顶的位置:
/**
* 获取头顶的坐标
* @param {*} midPos 眉心点坐标
* @param {*} jawPos 下巴底点坐标
*/
const getHeadPos = (midPos, jawPos) => {
// 获取线的 k 值
const k = getK(midPos, jawPos);
// 获取眉心到下颌的距离
const distanceOfEye2Jaw = getDistance(midPos, jawPos);
return getPos(k, distanceOfEye2Jaw / 2, midPos);
};
在这里让我们复习几个解析几何的公式:
- 两点之间距离公式:
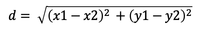
-
根据两点确定斜率:
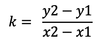
-
点到直线的距离公式:
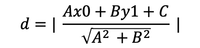
- 相互垂直的直线,斜率之积为-1
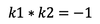
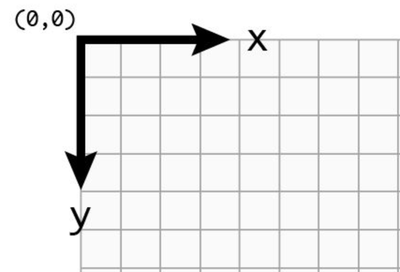
要特别注意的是,由于 Canvas 默认的坐标系的结构和我们之前数学课上学的不太一样,我们把它逆时针旋转 90 度可以发现它的 x,y 轴跟我们认识的是反的,因此为了方便,我们通常在代入公式计算的时候把 x,y 进行一下调换。
/**
* 获取 K 值
* @param {*} a
* @param {*} b
*/
const getK = (a, b) => (a.x - b.x) / (a.y - b.y)
/**
* 获取两点之间距离
* @param {*} a
* @param {*} b
*/
const getDistance = (a, b) => Math.sqrt(Math.pow(a.x - b.x, 2) + Math.pow(a.y - b.y, 2));
因此目前已知眉心的坐标,下颌坐标,可以计算出这条直线的斜率,然后根据眉心到头顶的距离(眉心到下巴的一半),可以算出头顶的坐标:
/**
* 已知 K,d, 点,求另一个点
* @param {*} k 值
* @param {*} d 距离
* @param {*} point 一个基础点
*/
const getPos = (k, d, point) => {
// 取 y 变小的那一边
let y = -Math.sqrt((d * d) / (1 + k * k)) + point.y;
let x = k * (y - point.y) + point.x;
return { x, y };
};
图片合成
当我们已经知道了圣诞帽子的位置了,那接下的问题就是如何把圣诞帽合成到头像上去了,这里我们采用 Canvas 来实现 ,原理很简单:首先把头像绘制到 Canvas 上,然后再继续绘制圣诞帽就行了。
由于图片中可能不止一个面部数据,可能需要绘制多个帽子:
/**
* 获取图片
* @param {*} src 图片地址
* @param {*} callback
*/
function getImg(src, callback) {
const img = new Image();
img.setAttribute('crossOrigin', 'anonymous');
img.src = src;
img.onload = () => callback(img);
}
/**
* 绘制主流程
* @param {*} canvas
* @param {*} options
*/
function drawing(canvas, options) {
const { info, width = 200, height = 200, imgSrc = 'images/default.jpg' } = options;
const ctx = canvas.getContext('2d');
// 重置
ctx.clearRect(0, 0, width, height);
// 先把图片绘制上去
getImg(imgSrc, img => ctx.drawImage(img, 0, 0, width, height));
// 循环把帽子画到对应的点上(由于图片中可能不止一个面部数据,可能需要绘制多个帽子)
for(let i = 0, len=info.length;i < len;i++) {
const { headPos } = info[i];
getImg('images/hat.png', img => ctx.drawImage(img, headPos.x, headPos.y, 200, 120));
}
}
我们可以看到帽子已经绘制上去了,但是位置有点奇怪:

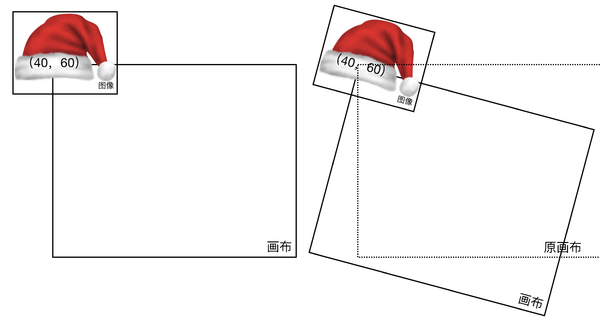
这是因为绘制图片的时候是按图片的左上角为原点绘制的,因此我们在实际绘制帽子的时候需要对坐标进行一个偏移:
/**
* 根据我当前的圣诞帽元素进行一些偏移(我的图片大小是 200*130), 圣诞帽可佩戴部分的中心 (60,60)
* @param {*} x
* @param {*} y
*/
const translateHat = (x, y) => {
return {
x: x - 60,
y: y - 60,
};
};
function drawing(canvas, options) {
……
const {x, y} = translateHat(headPos.x, headPos.y);
getImg('images/hat.png', img => ctx.drawImage(img, x, y, 200, 120));
……
}

这么看起来好多了,感觉自己棒棒哒!

优化
但是有小伙伴可以会发现,这样的结果还是有点问题:
- 帽子大小是固定的,但是头像的上的面孔可大可小,大脸放小帽子显然有点不合适。
- 帽子的朝向是固定的,如果有人的头像是偏着的呢,帽子是不是也应该偏过来?
因此我们还需要继续做优化:
圣诞帽的大小
圣诞帽的大小我们可以根据识别出的脸的大小来确定,通常来说,帽子可戴的宽度等于脸宽就行了(考虑到展示效果可以略大),我这里强调可戴宽度是因为一个圣诞帽的图片中只有一部分是可戴区域

// 0.7 为可戴区域占总区域的比重(为了让帽子更大一点,选择 0.6),0.65 是图片的宽高比
const picSize = { width: faceWidth / 0.6, height: (faceWidth * 0.65) / 0.6 };
而面部的大小可以通过 jawOutlinePoints的起始点距离来计算
/**
* 获取脸的宽度(即帽子宽度)
* @param {*} outlinePoints
*/
const getFaceWith = outlinePoints => getDistance(outlinePoints[0], outlinePoints[outlinePoints.length - 1])
圣诞帽的角度
圣诞帽的角度该如何计算呢?其实也很简单,知道头的偏转角度就行了,而头的偏转角度,直接用脸中线(眉心到下颌)和 y 轴的夹角就行了(直接用 atan2 算出来的是补角,需要用 180 度减),这里考虑到后续使用方便直接用的弧度。
/**
* 获取脸的倾斜弧度
* @param {*} jawPos
* @param {*} midPointOfEyebrows
*/
const getFaceRadian = (jawPos, midPointOfEyebrows) =>
Math.PI - Math.atan2(jawPos.x - midPointOfEyebrows.x, jawPos.y - midPointOfEyebrows.y); //弧度 0.9272952180016122
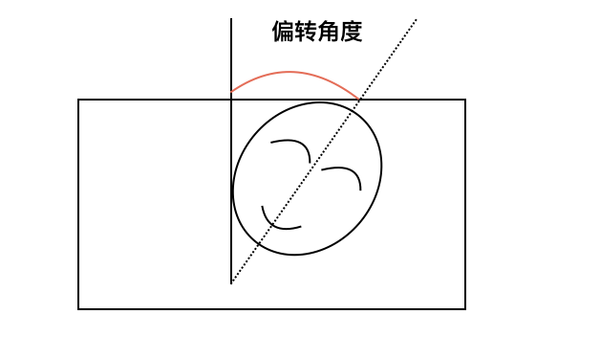
Canvas 中图片旋转
注意,在 Canvas 中没办法直接旋转图片,只能旋转画布,而且画布是按照原点旋转的,这点会特别坑。
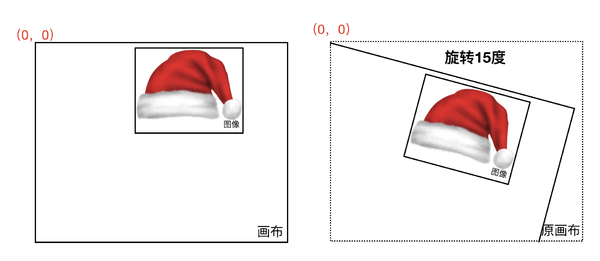
这里,我们只想让图片按照中心旋转怎么办?我们可以先让 Canvas 把原点平移到帽子的位置,然后再通过帽子的内部偏移使得帽子中心刚好在原点,此时再旋转画布把帽子画上就只影响这一个帽子图片了。
/**
* 绘制帽子
* @param {*} ctx 画布实例
* @param {{}} config 配置
*/
function drawHat(ctx, config) {
const { headPos, angle, faceWidth } = config;
getImg('images/hat.png?imageView&thumbnail=400x400', img => {
// 保存画布
ctx.save();
// 画布原点移动到画帽子的地方
ctx.translate(headPos.x, headPos.y);
// 旋转画布到特定角度
ctx.rotate(angle);
// 偏移图片,使帽子中心刚好在原点
const { x, y, width, height } = translateHat(faceWidth, 0, 0);
// 我的圣诞帽子实际佩戴部分长度只有 0.75 倍整个图片长度
ctx.drawImage(img, x, y, width, height);
// 还原画布
ctx.restore();
});
}
这样整个绘制的主流程大概就是这样:
function drawing(canvas, options) {
const { info, width = 200, height = 200, imgSrc = 'images/default.jpg'} = options;
const ctx = canvas.getContext('2d');
// 重置
ctx.clearRect(0, 0, width, height);
// 先把图片绘制上去
getImg(imgSrc, img => ctx.drawImage(img, 0, 0, width, height));
// 循环把帽子画到对应的点上
for (let i = 0, len = info.length; i < len; i++) {
drawHat(ctx, info[i]);
}
}
成品展示
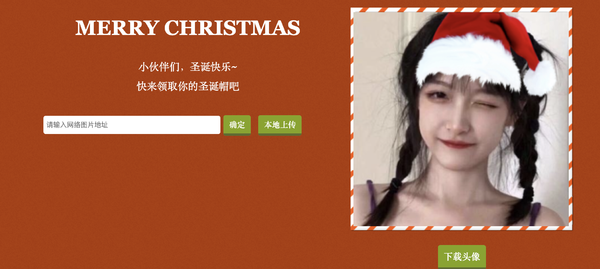
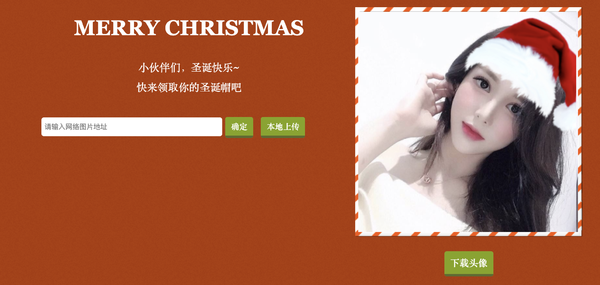
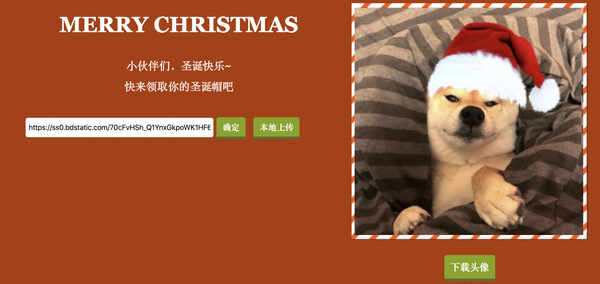
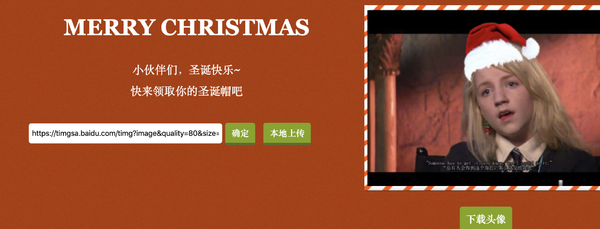
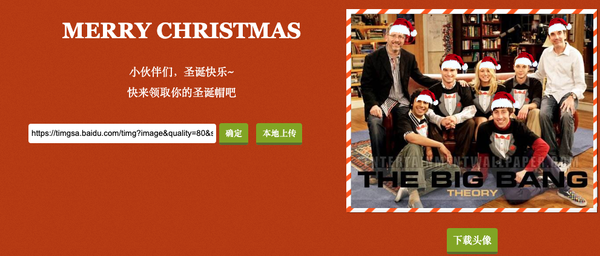
是不是感觉已经很完美了?目前已经能实现对各种大小的脸,不同朝向的脸进行适配了。甚至连狗狗的头像也能识别出来,这都得利于 face-api.js 提供的模型中也有狗狗的脸训练数据。
当然,这个例子实际上还是很不完善,因为当你测试的图片多的时候就会发现,对侧脸头像的识别还是有问题:

这是因为脸的大小用之前的方法计算的其实是不准确的,实际上还应该根据双边眼睛的比例知道用户现在是侧脸还是正面,从而继续调整帽子的大小和位置。但是这里就不继续优化了,感兴趣的小伙伴可以自己去琢磨琢磨如何修改。
写在最后
通过上面这个小例子,我们可以发现前端利用机器学习也可以实现很多不可思议的有趣玩意,再结合 VR,AR,webRTC,我们甚至可以做一个纯前端的互动小游戏。
当然就算在这个例子上,你也可以进行扩展,比如绘制圣诞胡须,化妆……
如果你想继续深入学习机器学习的相关知识,可以去看看 Coursea 的 机器学习入门课程,如果你想深入学习一下 Tensorflow,可以去看看 Tensorflow.js 的 官方文档。
虽然之前有吐槽 Tensorflow.js 知识点太多的问题,但是不得不说 Google 的文档写的还是不错的,提供了很多案例,手把手教你如何实现一些简单的功能:手写数字识别,预测,图片分类器……所以对 Tensorflow.js 感兴趣的童鞋不妨去它的官方文档中逛逛。
不过毕竟 Tensorflow.js 还是很底层的库,如果你只是想用机器学习做一些有趣的事情,不妨尝试一下 ml5.js,这里有一套学习视频。
最后,祝大家圣诞快乐!
参考
face-api.js — JavaScript API for Face Recognition in the Browser with tensorflow.js
tensorflow.google.cn/js/tutorial…
本文发布自 网易云音乐前端团队,文章未经授权禁止任何形式的转载。我们一直在招人,如果你恰好准备换工作,又恰好喜欢云音乐,那就 加入我们!
