


前言
之前好友希望能介绍一下 webapck 相关的内容,所以最近花费了两个多月的准备,终于完成了 webapck 系列,它包括一下几部分:
- webapck 系列一:手写一个 JavaScript 打包器
- webpack 系列二:最佳配置指北
- webpack 系列三:优化 90% 打包速度
- webpack 系列四:优化包体积
- webapck 系列五:优化首屏加载时间与页面流畅度
- webapck 系列六:构建包分析
- webapck 系列七:详细配置
- webapck 系列八:手写一个 webapck 插件(模拟 HtmlWebpackPlugin 的实现)
- webapck 系列九:webapck4 核心源码解读
- webapck 系列十:webapck5 展望
所有的内容之后会陆续放出,如果你有任何想要了解的内容或者有任何疑问,关注公众号【前端瓶子君】回复【123】添加好友,我会解答你的疑问。
作为一个前端开发人员,我们花费大量的时间去处理 webpack、gulp 等打包工具,将高级 JavaScript 项目打包成更复杂、更难以解读的文件包,运行在浏览器中,那么理解 JavaScript 打包机制就很必要,它帮助你更好的调试项目、更快的定位问题产生的问题,并且帮助你更好的理解、使用 webpack 等打包工具。 在这章你将会深入理解 JavaScript 打包器是什么,它的打包机制是什么?解决了什么问题?如果你理解了这些,接下来的 webpack 优化就会很简单。
一、什么是模块
一个模块可以有很多定义,但我认为:模块是一组与特定功能相关的代码。它封装了实现细节,公开了一个公共API,并与其他模块结合以构建更大的应用程序。
所谓模块化,就是为了实现更高级别的抽象,它将一类或多种实现封装到一个模块中,我们不必考虑模块内是怎样的依赖关系,仅仅调用它暴露出来的 API 即可。
例如在一个项目中:
<html>
<script src="/src/man.js"></script>
<script src="/src/person.js"></script>
</html>
其中 person.js 中依赖 man.js ,在引用时如果你把它们的引用顺序颠倒就会报错。在大型项目中,这种依赖关系就显得尤其重要,而且极难维护,除此之外,它还有以下问题:
- 一切都加载到全局上下文中,导致名称冲突和覆盖
- 涉及开发人员的大量手动工作,以找出依赖关系和包含顺序
所以,模块就尤其重要。
由于前后端 JavaScript 分别搁置在 HTTP 的两端,它们扮演的角色不同,侧重点也不一样。 浏览器端的 JavaScript 需要经历从一个服务器端分发到多个客户端执行,而服务器端 JS 则是相同的代码需要多次执行。前者的瓶颈在于宽带,后者的瓶颈则在于 CPU 等内存资源。前者需要通过网络加载代码,后者则需要从磁盘中加载, 两者的加载速度也不是在一个数量级上的。 所以前后端的模块定义不是一致的,其中服务器端的模块定义为:
- CJS(CommonJS):旨在用于服务器端 JavaScript 的同步定义,Node 的模块系统实际上基于 CJS;
但 CommonJS 是以同步方式导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大,但在浏览器端,如果在 UI 加载的过程中需要花费很多时间来等待脚本加载完成,这会造成用户体验的很大问题。 鉴于网络的原因, CommonJS 为后端 JavaScript 制定的规范并不完全适合与前端的应用场景,下面来介绍 JavaScript 前端的规范。
- AMD(异步模块定义):被定义为用于浏览器中模块的异步模型,RequireJS 是 AMD 最受欢迎的实现;
- UMD(通用模块定义):它本质上一段 JavaScript 代码,放置在库的顶部,可让任何加载程序、任何环境加载它们;
- ES2015(ES6):定义了异步导入和导出模块的语义,会编译成
require/exports来执行的,这也是我们现今最常用的模块定义;
二、什么是打包器
所谓打包器,就是前端开发人员用来将 JavaScript 模块打包到一个可以在浏览器中运行的优化的 JavaScript 文件的工具,例如 webapck、rollup、gulp 等。
举个例子,你在一个 html 文件中引入多个 JavaScript 文件:
<html>
<script src="/src/entry.js"></script>
<script src="/src/message.js"></script>
<script src="/src/hello.js"></script>
<script src="/src/name.js"></script>
</html>
这四个引入文件之间存在如下依赖关系:
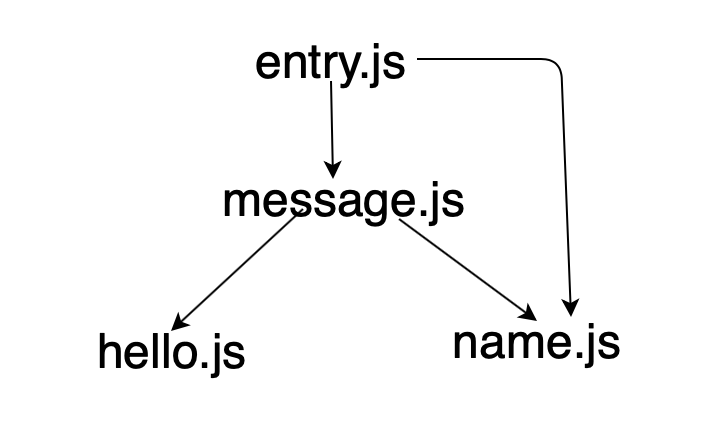
1. 模块化
在 HTML 引入时,我们需要注意这 4 个文件的引入顺序(如果顺序出错,项目就会报错),如果将其扩展到具有实际功能的可用的 web 项目中,那么可能需要引入几十个文件,依赖关系更是复杂。
所以,我们需要将每个依赖项模块化,让打包器帮助我们管理这些依赖项,让每个依赖项能够在正确的时间、正确的地点被正确的引用。
2. 捆绑
另外,当浏览器打开该网页时,每个 js 文件都需要一个单独的 http 请求,即 4 个往返请求,才能正确的启动你的项目。
我们知道浏览器加载模块很慢,即使是 HTTP/2 支持有效的加载许多小文件,但其性能都不如加载一个更加有效(即使不做任何优化)。
因此,最好将所有 4 个文件合并为1个:
<html>
<script src="/dist/bundle.js"></script>
</html>
这样只需要一次 http 请求即可。
所以,模块化与捆绑是打包器需要实现的两个最主要功能。
三、如何打包
如何打包到一个文件喃?它通常有一个入口文件,从入口文件开始,获取所有的依赖项,并打包到一个文件 bundle.js 中。例如上例,我们可以以 /src/entry.js 作为入口文件,进行合并其余的 3 个 JavaScript 文件。
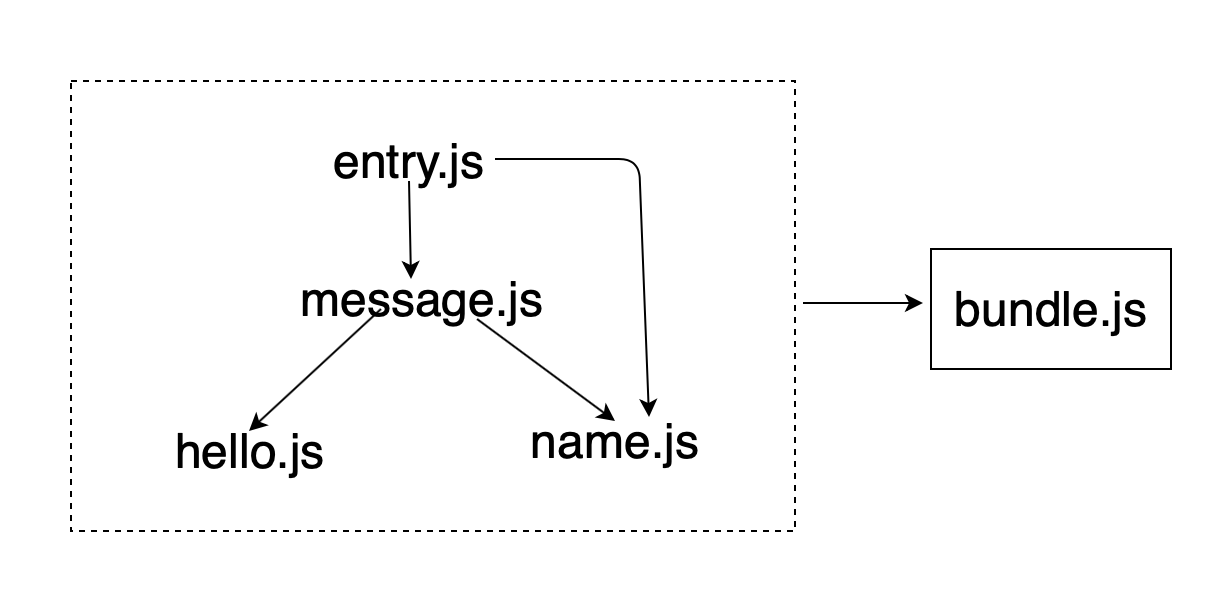
当然合并不能是简单的将 4 个文件所有内容放入一个 bundle.js 中。我们先思考一下,它具体该怎么实现喃?
1. 解析入口文件,获取所有的依赖项
首先我们唯一确定的是入口文件的地址,通过入口文件的地址可以
- 获取其文件内容
- 获取其依赖模块的相对地址
由于依赖模块的引入是通过相对路径(import './message.js'),所以,我们需要保存入口文件的路径,结合依赖模块的相对地址,就可以确定依赖模块绝对地址,读取它的内容。
如何在依赖关系中去表示一个模块,以方便在依赖图中引用
所以我们可以模块表示为:
- code: 文件解析内容,注意解析后代码能够在当前以及旧浏览器或环境中运行;
- dependencies: 依赖数组,为所有依赖模块路径(相对)路径;
- filename: 文件绝对路径,当
import依赖模块为相对路径,结合当前绝对路径,获取依赖模块路径;
其中 filename(绝对路径) 可以作为每个模块的唯一标识符,通过 key: value 形式,直接获取文件的内容一依赖模块:
// 模块
'src/entry': {
code: '', // 文件解析后内容
dependencies: ["./message.js"], // 依赖项
}
2. 递归解析所有的依赖项,生成一个依赖关系图
我们已经确定了模块的表示,那怎么才能将这所有的模块关联起来,生成一个依赖关系图,通过这个依赖关系可以直接获取所有模块的依赖模块、依赖模块的代码、依赖模块的来源、依赖模块的依赖模块。
如何去维护依赖文件间的关系
现在对于每一个模块,可以唯一表示的就是 filename ,而我们在由入口文件递归解析时,我们可以获取到每个文件的依赖数组 dependencies ,也就是每个依赖项的相对路径,所以我们需要定义一个:
// 关联关系
let mapping = {}
用来在运行代码时,由 import 相对路径映射到 import 绝对路径。
所以我们模块可以定义为[filename: {}]:
// 模块
'src/entry': {
code: '', // 文件解析后内容
dependencies: ["./message.js"], // 依赖项
mapping:{
"./message.js": "src/message.js"
}
}
则依赖关系图为:
// graph 依赖关系图
let graph = {
// entry 模块
"src/entry.js": {
code: '',
dependencies: ["./src/message.js"],
mapping:{
"./message.js": "src/message.js"
}
},
// message 模块
"src/message.js": {
code: '',
dependencies: [],
mapping:{},
}
}
当项目运行时,通过入口文件成功获取入口文件代码内容,运行其代码,当遇到 import 依赖模块时,通过 mapping 映射其为绝对路径,就可以成功读取模块内容。
并且每个模块的绝对路径 filename 是唯一的,当我们将模块接入到依赖图 graph 时,仅仅需要判断 graph[filename] 是否存在,如果存在就不需要二次加入,剔除掉了模块的重复打包。
3. 使用依赖图,返回一个可以在浏览器运行的 JavaScript 文件
现今,可立即执行的代码形式,最流行的就是 IIFE(立即执行函数),它同时能够解决全局变量污染的问题。
IIFE
所谓 IIFE,就是在声明市被直接调用的匿名函数,由于 JavaScript 变量的作用域仅限于函数内部,所以你不必考虑它会污染全局变量。
(function(man){
function log(name) {
console.log(`hello ${name}`);
}
log(man.name)
})({name: 'bottle'});
// hello bottle
4. 输出到 dist/bundle.js
fs.writeFile 写入 dist/bundle.js 即可。
至此,打包流程与实现方案已确定,接下来就实践一遍吧!
四、创建一个minipack项目
新建一个 minipack 文件夹,并 npm init ,创建以下文件:
- src
- - entry.js // 入口 js
- - message.js // 依赖项
- - hello.js // 依赖项
- - name.js // 依赖项
- index.js // 打包 js
- minipack.config.js // minipack 打包配置文件
- package.json
- .gitignore
其中 entry.js :
import message from './message.js'
import {name} from './name.js'
message()
console.log('----name-----: ', name)
message.js :
import {hello} from './hello.js'
import {name} from './name.js'
export default function message() {
console.log(`${hello} ${name}!`)
}
hello.js :
export const hello = 'hello'
name.js :
export const name = 'bottle'
minipack.config.js :
const path = require('path')
module.exports = {
entry: 'src/entry.js',
output: {
filename: "bundle.js",
path: path.resolve(__dirname, './dist'),
}
}
并安装文件
npm install @babel/core @babel/parser @babel/preset-env @babel/traverse --save-dev
至此,整个项目创建完成。接下来就是打包了:
- 解析入口文件,遍历所有依赖项
- 递归解析所有的依赖项,生成一个依赖关系图
- 使用依赖图,返回一个可以在浏览器运行的 JavaScript 文件
- 输出到
/dist/bundle.js
五、解析入口文件,遍历所有依赖项
1. @babel/parser 解析入口文件,获取 AST
在 ./index.js 文件中,我们创建一个打包器,首先解析入口文件,我们使用 @babel/parser 解析器进行解析:
步骤一:读取入口文件内容
// 获取配置文件
const config = require('./minipack.config');
// 入口
const entry = config.entry;
const content = fs.readFileSync(entry, 'utf-8');
步骤二:使用 @babel/parser(JavaScript解析器)解析代码,生成 ast(抽象语法树)
const babelParser = require('@babel/parser')
const ast = babelParser.parse(content, {
sourceType: "module"
})
其中,sourceType 指示代码应解析的模式。可以是"script", "module"或 "unambiguous" 之一,其中 "unambiguous" 是让 @babel/parser 去猜测,如果使用 ES6 import 或 export 的话就是 "module" ,否则为 "script" 。这里使用 ES6 import 或 export ,所以就是 "module" 。
由于 ast 树较复杂,所以这里我们可以通过 astexplorer.net/ 查看:
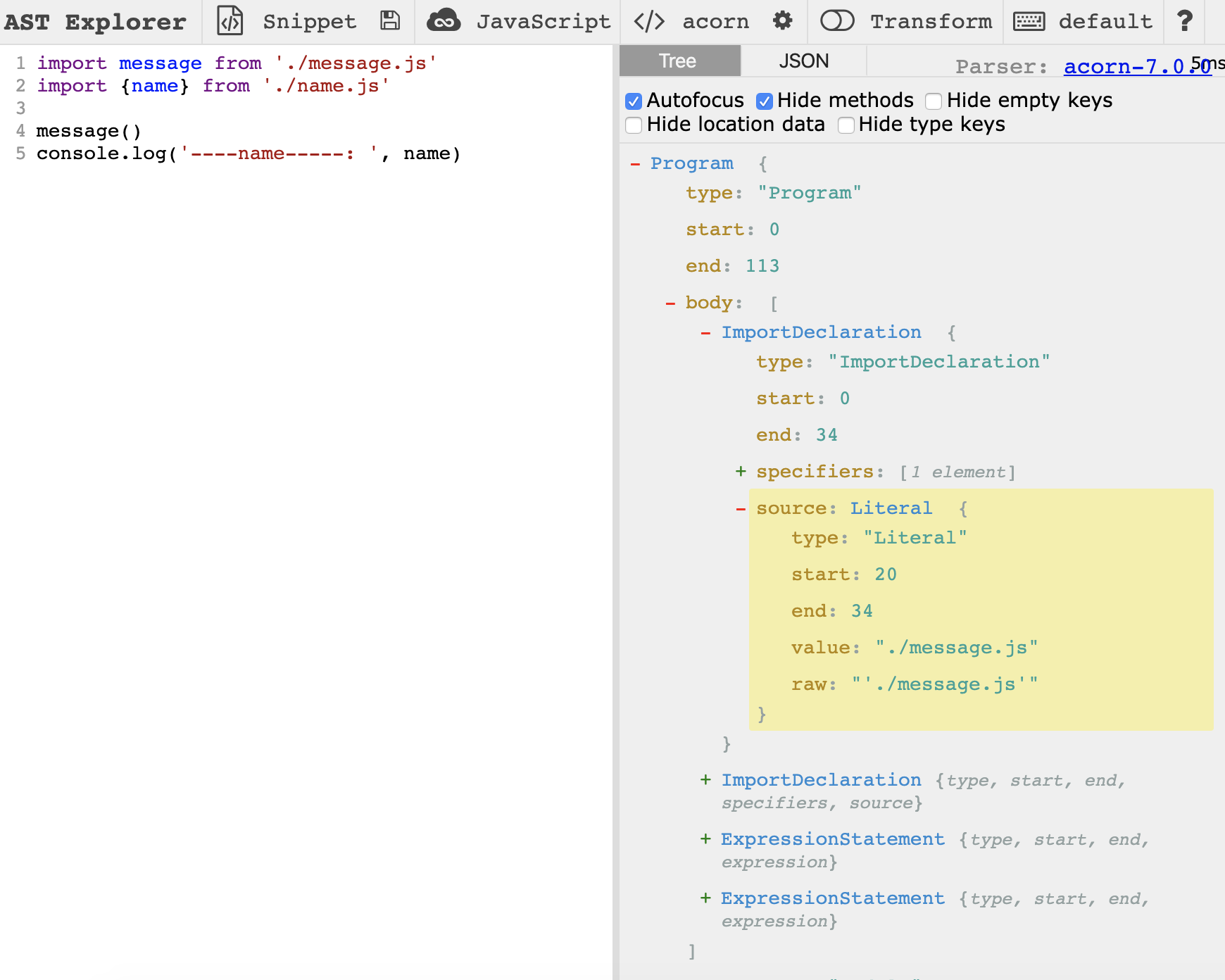
我们已经获取了入口文件所有的 ast,接下来我们要做什么喃?
- 解析 ast,解析入口文件内容(可在当前和旧浏览器或环境中向后兼容的 JavaScript 版本)
- 获取它所有的依赖模块
dependencies
2. 获取入口文件内容
我们已经知道了入口文件的 ast,可以通过 @babel/core 的 transformFromAst 方法,来解析入口文件内容:
const {transformFromAst} = require('@babel/core');
const {code} = transformFromAst(ast, null, {
presets: ['@babel/preset-env'],
})
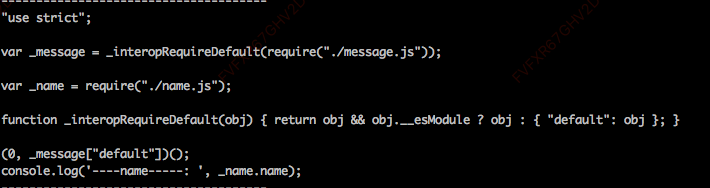
3. 获取它所有的依赖模块
就需要通过 ast 获取所有的依赖模块,也就是我们需要获取 ast 中所有的 node.source.value ,也就是 import 模块的相对路径,通过这个相对路径可以寻找到依赖模块。
步骤一:定义一个依赖数组,用来存放 ast 中解析出的所有依赖
const dependencies = []
步骤二:使用 @babel/traverse ,它和 babel 解析器配合使用,可以用来遍历及更新每一个子节点
traverse 函数是一个遍历 AST 的方法,由 babel-traverse 提供,他的遍历模式是经典的 visitor 模式 ,visitor 模式就是定义一系列的 visitor ,当碰到 AST 的 type === visitor 名字时,就会进入这个 visitor 的函数。类型为 ImportDeclaration 的 AST 节点,其实就是我们的 import xxx from xxxx,最后将地址 push 到 dependencies 中.
const traverse = require('@babel/traverse').default
traverse(ast, {
// 遍历所有的 import 模块,并将相对路径放入 dependencies
ImportDeclaration: ({node}) => {
dependencies.push(node.source.value)
}
})
3. 有效返回
{
dependencies,
code,
}
完整代码:
/**
* 解析文件内容及其依赖,
* 期望返回:
* dependencies: 文件依赖模块
* code: 文件解析内容
* @param {string} filename 文件路径
*/
function createAsset(filename) {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8')
// 使用 @babel/parser(JavaScript解析器)解析代码,生成 ast(抽象语法树)
const ast = babelParser.parse(content, {
sourceType: "module"
})
// 从 ast 中获取所有依赖模块(import),并放入 dependencies 中
const dependencies = []
traverse(ast, {
// 遍历所有的 import 模块,并将相对路径放入 dependencies
ImportDeclaration: ({
node
}) => {
dependencies.push(node.source.value)
}
})
// 获取文件内容
const {
code
} = transformFromAst(ast, null, {
presets: ['@babel/preset-env'],
})
// 返回结果
return {
dependencies,
code,
}
}

六、递归解析所有的依赖项,生成一个依赖关系图
步骤一:获取入口文件:
const mainAssert = createAsset(entry)
步骤二:创建依赖关系图:
由于每个模块都是 key: value 形式,所以定义依赖图为:
// entry: 入口文件绝对地址
const graph = {
[entry]: mainAssert
}
步骤三:递归搜索所有的依赖模块,加入到依赖关系图中:
定义一个递归搜索函数:
/**
* 递归遍历,获取所有的依赖
* @param {*} assert 入口文件
*/
function recursionDep(filename, assert) {
// 跟踪所有依赖文件(模块唯一标识符)
assert.mapping = {}
// 由于所有依赖模块的 import 路径为相对路径,所以获取当前绝对路径
const dirname = path.dirname(filename)
assert.dependencies.forEach(relativePath => {
// 获取绝对路径,以便于 createAsset 读取文件
const absolutePath = path.join(dirname, relativePath)
// 与当前 assert 关联
assert.mapping[relativePath] = absolutePath
// 依赖文件没有加入到依赖图中,才让其加入,避免模块重复打包
if (!queue[absolutePath]) {
// 获取依赖模块内容
const child = createAsset(absolutePath)
// 将依赖放入 queue,以便于继续调用 recursionDep 解析依赖资源的依赖,
// 直到所有依赖解析完成,这就构成了一个从入口文件开始的依赖图
queue[absolutePath] = child
if(child.dependencies.length > 0) {
// 继续递归
recursionDep(absolutePath, child)
}
}
})
}
从入口文件开始递归:
// 遍历 queue,获取每一个 asset 及其所以依赖模块并将其加入到队列中,直至所有依赖模块遍历完成
for (let filename in queue) {
let assert = queue[filename]
recursionDep(filename, assert)
}
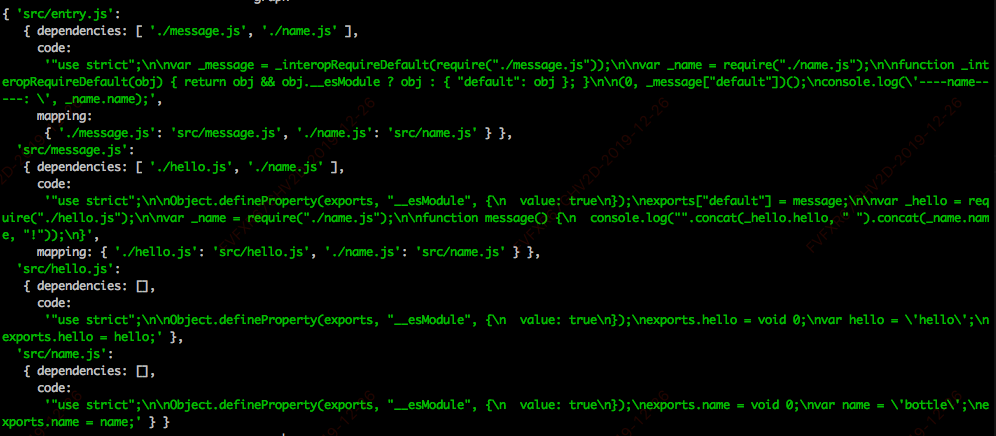
七、使用依赖图,返回一个可以在浏览器运行的 JavaScript 文件
步骤一:创建一个了立即执行函数,用于在浏览器上直接运行
const result = `
(function() {
})()
`
步骤二:将依赖关系图作为参数传递给立即执行函数
定义传递参数 modules:
let modules = ''
遍历 graph,将每个 mod 以 key: value, 的方式加入到 modules,
注意:由于依赖关系图要传入以上立即执行函数中,然后写入到 dist/bundle.js 运行,所以,code 需要放在 function(require, module, exports){${mod.code}} 中,避免污染全局变量或其它模块,同时,代码在转换成 code 后,使用的是 commonJS 系统,而浏览器不支持 commonJS(浏览器没有 module 、exports、require、global),所以这里我们需要实现它们,并注入到包装器函数内。
for (let filename in graph) {
let mod = graph[filename]
modules += `'${filename}': [
function(require, module, exports) {
${mod.code}
},
${JSON.stringify(mod.mapping)},
],`
}
步骤三:将参数传入立即执行函数,并立即执行入口文件:
首先实现一个 require 函数,require('${entry}') 执行入口文件,entry 为入口文件绝对路径,也为模块唯一标识符
const result = `
(function(modules) {
require('${entry}')
})({${modules}})
`
注意:modules 是一组 key: value,,所以我们将它放入 {} 中
步骤四:重写浏览器 require 方法,当代码运行 require('./message.js') 转换成 require(src/message.js)
const result = `
(function(modules) {
function require(moduleId) {
const [fn, mapping] = modules[moduleId]
function localRequire(name) {
return require(mapping[name])
}
const module = {exports: {}}
fn(localRequire, module, module.exports)
return module.exports
}
require('${entry}')
})({${modules}})
`
注意:
moduleId为传入的filename,为模块的唯一标识符- 通过解构
const [fn, mapping] = modules[id]来获得我们的函数包装(function(require, module, exports) {${mod.code}})和mappings对象 - 由于一般情况下
require都是require相对路径,而不是绝对路径,所以重写fn的require方法,将require相对路径转换成require绝对路径,即localRequire函数 - 将
module.exports传入到fn中,将依赖模块内容需要输出给其它模块使用时,当require某一依赖模块时,就可以直接通过module.exports将结果返回
八、输出到 dist/bundle.js
// 打包
const result = bundle(graph)
// 写入 ./dist/bundle.js
fs.writeFile(`${output.path}/${output.filename}`, result, (err) => {
if (err) throw err;
console.log('文件已被保存');
})
九、总结及源码
本来想简单的写写,结果修修改改又那么多🤦♀️🤦♀️🤦♀️,但总要吃透才好。
参考了minipack,解决了它会出现模块被重复打包的问题,同时借鉴了webpack以filename为唯一标识符进行模块定义。
想看往期更过系列文章,点击前往 github 博客主页
十、走在最后
-
❤️玩得开心,不断学习,并始终保持编码。👨💻
-
如有任何问题或更独特的见解,欢迎评论或直接联系瓶子君(公众号回复 123 即可)!👀👇
-
👇欢迎关注:前端瓶子君,每日更新!👇

