

前言
最近做完12月份版本需求,有一些思考不够深入的代码,因此写一下总结,希望大家日常写代码多点思考,多点总结,加油!同时哪里有不对的,也望指出。
github 地址
一、复杂的逻辑条件,是否可以调整顺序,让程序更高效呢。
假设业务需求是这样:会员,第一次登陆时,需要发一条感谢短信。如果没有经过思考,代码直接这样写了
if(isUserVip && isFirstLogin){
sendMsg();
}
假设总共有5个请求,isUserVip通过的有3个请求,isFirstLogin通过的有1个请求。 那么以上代码,isUserVip执行的次数为5次,isFirstLogin执行的次数也是3次,如下:

如果调整一下isUserVip和isFirstLogin的顺序呢?
if(isFirstLogin && isUserVip ){
sendMsg();
}
isFirstLogin执行的次数是5次,isUserVip执行的次数是1次,如下:
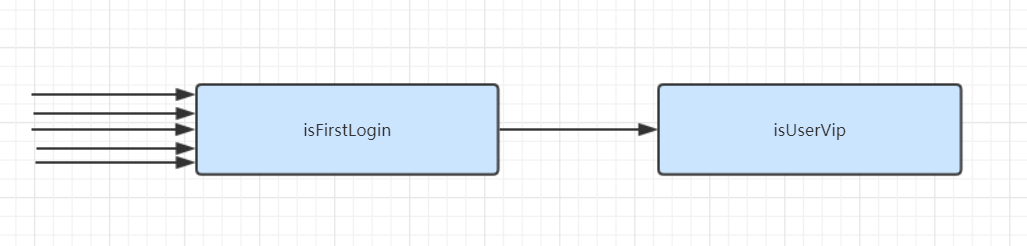
酱紫你的程序是否更高效呢?
二、你的程序是否不经意间创建了不必要的对象。
举个粟子吧,判断用户会员是否处于有效期,通常有以下类似代码:
//判断用户会员是否在有效期
public boolean isUserVIPValid() {
Date now = new Date();
Calendar gmtCal = Calendar.getInstance();
gmtCal.set(2019, Calendar.JANUARY, 1, 0, 0, 0);
Date beginTime = gmtCal.getTime();
gmtCal.set(2020, Calendar.JANUARY, 1, 0, 0, 0);
Date endTime= gmtCal.getTime();
return now.compareTo(beginTime) >= 0 && now.compareTo(endTime) <= 0;
}
但是呢,每次调用isUserVIPValid方法,都会创建Calendar和Date对象。其实吧,除了New Date,其他对象都是不变的,我们可以抽出全局变量,避免创建了不必要的对象,从而提高程序效率,如下:
public class Test {
private static final Date BEGIN_TIME;
private static final Date END_TIME;
static {
Calendar gmtCal = Calendar.getInstance();
gmtCal.set(2019, Calendar.JANUARY, 1, 0, 0, 0);
BEGIN_TIME = gmtCal.getTime();
gmtCal.set(2020, Calendar.JANUARY, 1, 0, 0, 0);
END_TIME = gmtCal.getTime();
}
//判断用户会员是否在有效期
public boolean isUserVIPValid() {
Date now = new Date();
return now.compareTo(BEGIN_TIME) >= 0 && now.compareTo(END_TIME) <= 0;
}
}
三、查询数据库时,你有没有查多了数据?
大家都知道,查库是比较耗时的操作,尤其数据量大的时候。所以,查询DB时,我们取所需就好,没有必要大包大揽。
假设业务场景是这样:查询某个用户是否是会员。曾经看过实现代码是这样。。。
List<Long> userIds = sqlMap.queryList("select userId from user where vip=1");
boolean isVip = userIds.contains(userId);
为什么先把所有会有查出来,再判断是否包含这个useId,来确定useId是否是会员呢?直接把userId传进sql,它不香吗?如下:
Long userId = sqlMap.queryObject("select userId from user where userId='userId' and vip='1' ")
boolean isVip = userId!=null;
实际上,我们除了把查询条件都传过去,避免数据库查多余的数据回来,还可以通过select 具体字段代替select *,从而使程序更高效。
四、加了一行通知类的代码,总不能影响到主要流程吧。
假设业务流程这样:需要在用户登陆时,添加个短信通知它的粉丝。 很容易想到的实现流程如下:
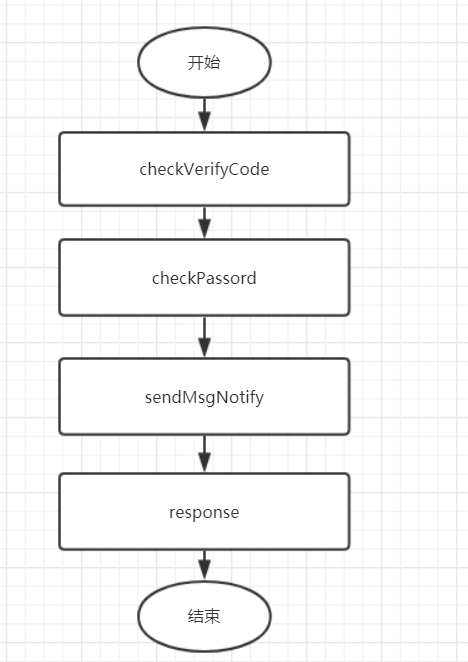
假设提供sendMsgNotify服务的系统挂了,或者调用sendMsgNotify失败了,那么用户登陆就失败了。。。
一个通知功能导致了登陆主流程不可用,明显的捡了芝麻丢西瓜。那么有没有鱼鱼熊掌兼得的方法呢?有的,给发短信接口捕获异常处理,或者另开线程异步处理,如下:
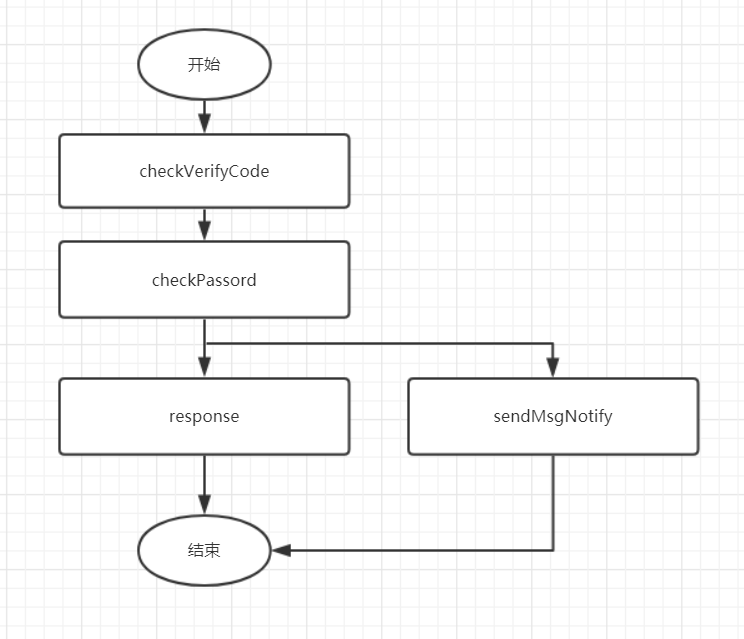
因此,我们添加通知类等不是非主要,可降级的接口时,应该静下心来考虑是否会影响主要流程,思考怎么处理最好。
五、对空指针保持嗅觉,如使用equals比较时,常量或确定值放左边。
NullPointException在Java世界早已司空见惯,我们在写代码时,可以三思而后写,尽量避免低级的空指针问题。
比如有以下业务场景,判断用户是否是会员,经常可见如下代码:
boolean isVip = user.getUserFlag().equals("1");
如果让这个行代码上生产环境,待君蓦然回首,可能那空指针bug,就在灯火阑珊处。显然,这样可能会产生空指针异常,因为user.getUserFlag()可能是null。
怎样避免空指针问题呢?把常量1放到左边就可以啦,如下:
boolean isVip = "1".equals(user.getUserFlag());
六、你的关键业务代码是否有日志保驾护航?
关键业务代码无论身处何地,都应该有足够的日志保驾护航。
比如:你实现转账业务,转个几百万,然后转失败了,接着客户投诉,然后你还没有打印到日志,想想那种水深火热的困境下,你却毫无办法。。。
那么,你的转账业务都需要那些日志信息呢?至少,方法调用前,入参需要打印需要吧,接口调用后,需要捕获一下异常吧,同时打印异常相关日志吧,如下:
public void transfer(TransferDTO transferDTO){
log.info("invoke tranfer begin");
//打印入参
log.info("invoke tranfer,paramters:{}",transferDTO);
try {
res= transferService.transfer(transferDTO);
}catch(Exception e){
log.error("transfer fail,cifno:{},account:{}",transferDTO.getCifno(),
transferDTO.getaccount())
log.error("transfer fail,exception:{}",e);
}
log.info("invoke tranfer end");
}
除了打印足够的日志,我们还需要注意一点是,日志级别别混淆使用,别本该打印info的日志,你却打印成error级别,告警半夜三更催你起来排查问题就不好了。
七、对于行数比较多的函数,是否可以划分小函数来优化呢?
我们在维护老代码的时候,经常会见到一坨坨的代码,有些函数几百行甚至上千行,阅读起来比较吃力。
假设现在有以下代码
public class Test {
private String name;
private Vector<Order> orders = new Vector<Order>();
public void printOwing() {
//print banner
System.out.println("****************");
System.out.println("*****customer Owes *****");
System.out.println("****************");
//calculate totalAmount
Enumeration env = orders.elements();
double totalAmount = 0.0;
while (env.hasMoreElements()) {
Order order = (Order) env.nextElement();
totalAmount += order.getAmout();
}
//print details
System.out.println("name:" + name);
System.out.println("amount:" + totalAmount);
}
}
划分为功能单一的小函数后:
public class Test {
private String name;
private Vector<Order> orders = new Vector<Order>();
public void printOwing() {
//print banner
printBanner();
//calculate totalAmount
double totalAmount = getTotalAmount();
//print details
printDetail(totalAmount);
}
void printBanner(){
System.out.println("****************");
System.out.println("*****customer Owes *****");
System.out.println("****************");
}
double getTotalAmount(){
Enumeration env = orders.elements();
double totalAmount = 0.0;
while (env.hasMoreElements()) {
Order order = (Order) env.nextElement();
totalAmount += order.getAmout();
}
return totalAmount;
}
void printDetail(double totalAmount){
System.out.println("name:" + name);
System.out.println("amount:" + totalAmount);
}
}
一个过于冗长的函数或者一段需要注释才能让人理解用途的代码,可以考虑把它切分成一个功能明确的函数单元,并定义清晰简短的函数名,这样会让代码变得更加优雅。
八、某些可变因素,如红包皮肤等等,做成配置化是否会更好呢。
假如产品提了个红包需求,圣诞节的时候,红包皮肤为圣诞节相关的,春节的时候,红包皮肤等。
如果在代码写死控制,可有类似以下代码:
if(duringChristmas){
img = redPacketChristmasSkin;
}else if(duringSpringFestival){
img = redSpringFestivalSkin;
}
......
如果到了元宵节的时候,运营小姐姐突然又有想法,红包皮肤换成灯笼相关的,这时候,是不是要去修改代码了,重新发布了?
从一开始,实现一张红包皮肤的配置表,将红包皮肤做成配置化呢?更换红包皮肤,只需修改一下表数据就好了。
九、多余的import 类,局部变量,没引用是不是应该删除
如果看到代码存在没使用的import 类,没被使用到的局部变量等,就删掉吧,如下这些:
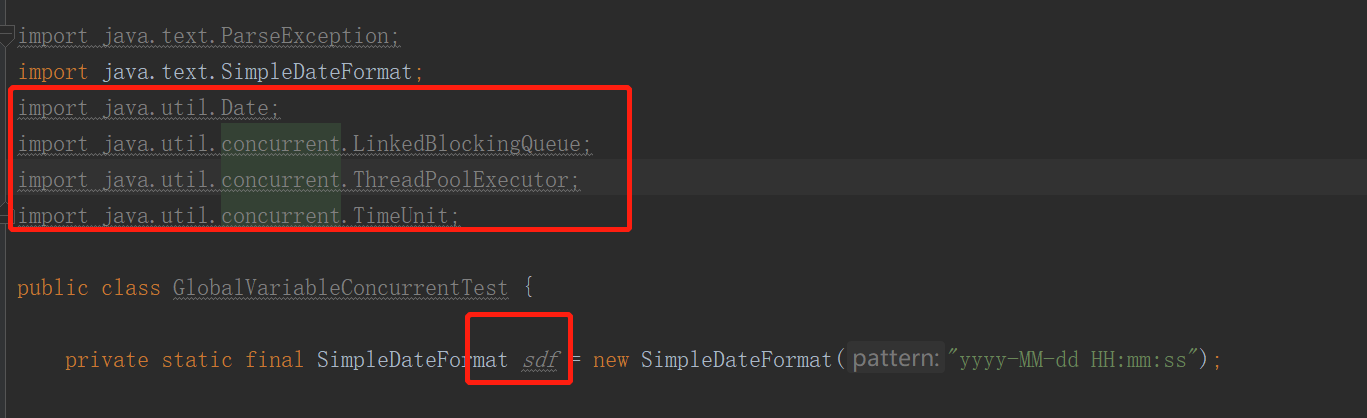
这些没被引用的局部变量,如果没被使用到,就删掉吧,它又不是陈年的女儿红,留着会越发醇香。它还是会一起被编译的,就是说它还是耗着资源的呢。
十、查询大表时,是否加了索引,你的sql走了索引嘛。
查询数据量比较大的表时,我们需要确认三点:
- 你的表是否建了索引
- 你的查询sql是否命中索引
- 你的sql是否还有优化余地
一般情况下,数据量超过10万的表,就要考虑给表加索引了。哪些情况下,索引会失效呢?like通配符、索引列运算等会导致索引失效。有兴趣的朋友可以看一下我这篇文章。 后端程序员必备:索引失效的十大杂症
十一、你的方法到底应该返回空集合还是 null呢?
如果返回null,调用方在忘记检测的时候,可能会抛出空指针异常。返回一个空集合呢,就省去该问题了。
mybatis查询的时候,如果返回一个集合,结果为空时也会返回一个空集合,而不是null。
正例
public static List<UserResult> getUserResultList(){
return Collections.EMPTY_LIST;
}
十二、初始化集合时尽量指定其大小
阿里开发手册推荐了这一点

假设你的map要存储的元素个数是15个左右,最优写法如下
//initialCapacity = 15/0.75+1=21
Map map = new HashMap(21);
又因为hashMap的容量跟2的幂有关,所以可以取32的容量
Map map = new HashMap(32);
十三、查询数据库时,如果数据返回过多,考虑分批进行。
假设你的订单表有10万数据要更新状态,不能一次性查询所有未更新的订单,要分批。
反例:
List<Order> list = sqlMap.queryList("select * from Order where status='0'");
for(Order order:list){
order.setStatus(1);
sqlMap.update(order);
}
正例:
Integer count = sqlMap.queryCount(select count(1) from Order where status ='0');
while(true){
int size=sqlMap.batchUpdate(params);
if(size<500){
break;
}
}
十四、你的接口是否考虑到幂等性,并发情况呢?
幂等性是什么? 一次和多次请求某一个资源对于资源本身应该具有同样的结果。就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
为什么需要幂等性?
- 用户在APP上连续点击了多次提交订单,总不能生成多个订单吧
- 用户因为网络卡了,连续点击发送消息,接受者总不能收到重复的同一条消息吧。
假设有业务场景:
用户点击下载按钮,系统开始下载文件,用户再次点击下载,会提示文件正在下载中。
有一部分人会这样实现:
Integer count = sqlMap.selectCount("select count(1) from excel where state=1");
if(count<=0){
Excel.setStatus(1);
updateExcelStatus();
downLoadExcel();
}else{
"文件正在下载中"
}
我们可以看一下,两个请求过来可能会有什么问题?
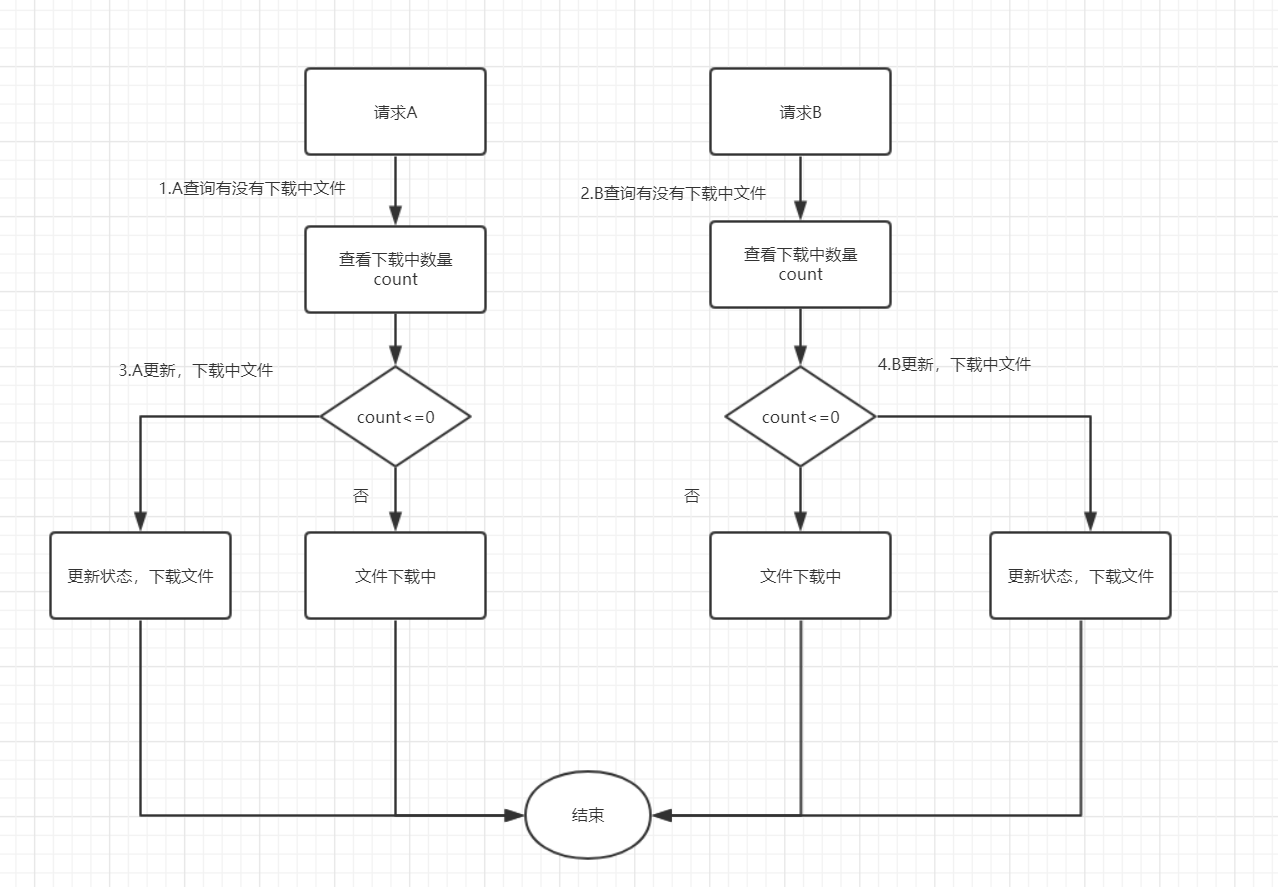
执行流程:
- 第一步,A查询没有下载中的文件。
- 第二步,B查询没有下载中的文件。
- 第三步,A开始下载文件
- 第四部,B 开始下载文件
显然,这样有问题,同时两个文件在下载了。正确的实现方式呢?
if(updateExcelStatus(1){
downLoadExcel();
}else{
"文件正在下载中"
}
十五、用一个私有构造器强化你的工具类,此不美哉?
工具类的方法都是静态方法,通过类来直接调用即可。但是有些调用方可能会先实例化,再用对象去调用,而这就不好了。怎么避免这种情况,让你的工具类到达可控状态呢,添加私有构造器
public class StringUtis{
private StringUtis(){} ///私有构造类,防止意外实例出现
public static bool validataString(String str){
}
}
十六、基本不变的用户数据,缓存起来,性能是否有所提升呢
假设你的接口需要查询很多次数据库,获取到各中数据,然后再根据这些数据进行各种排序等等操作,这一系列猛如虎的操作下来,接口性能肯定不好。典型应用场景比如:直播列表这些。
那么,怎么优化呢?剖析你排序的各部分数据,实时变的数据,继续查DB,不变的数据,如用户年龄这些,搞个定时任务,把它们从DB拉取到缓存,直接走缓存。
因此,这个点的思考就是,在恰当地时机,适当的使用缓存。
待补充...
个人公众号

- 如果你是个爱学习的好孩子,可以关注我公众号,一起学习讨论。
- 如果你觉得本文有哪些不正确的地方,可以评论,也可以关注我公众号,私聊我,大家一起学习进步哈。
- github地址:github.com/whx123/Java…
