


本文是《数据库系统概念》一书的阅读笔记,会侧重于数据原理,并且会忽略掉很多细节的知识。
第三章:SQL
大部分情况下用到的SQL语句也就是增删查改,后面部分涉及的数据库原理部分大部分只和数据增删查改有关:
INSERT INTO ... VALUES(...)DELETE FROM ... WHERE ...SELECT ... FROM ... WHERE ...UPDATE ... SET ... WHERE ...
除了数据上的增删查改之外,还有权限、索引、模式方面的增删改。不同的数据库对于SQL会存在不一样的实现,常用的MySQL的SQL用法可以参考《MySQL教程》。
第十一章:索引和哈希
本章主要关注如何组织记录来支持增删查改。
顺序索引
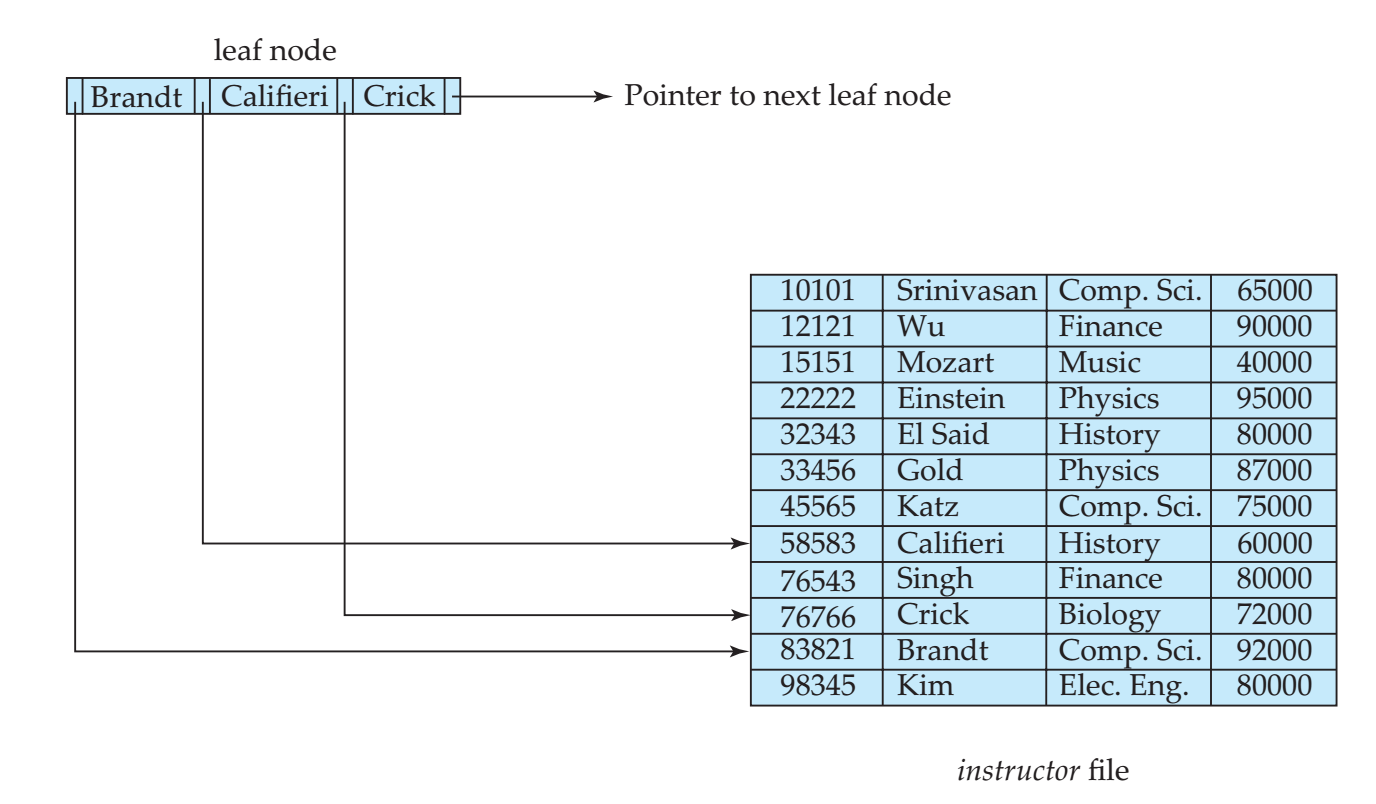
能想到最简单的记录组织方法就是将记录按照某个键(通常是主键)按顺序保存在文件中。
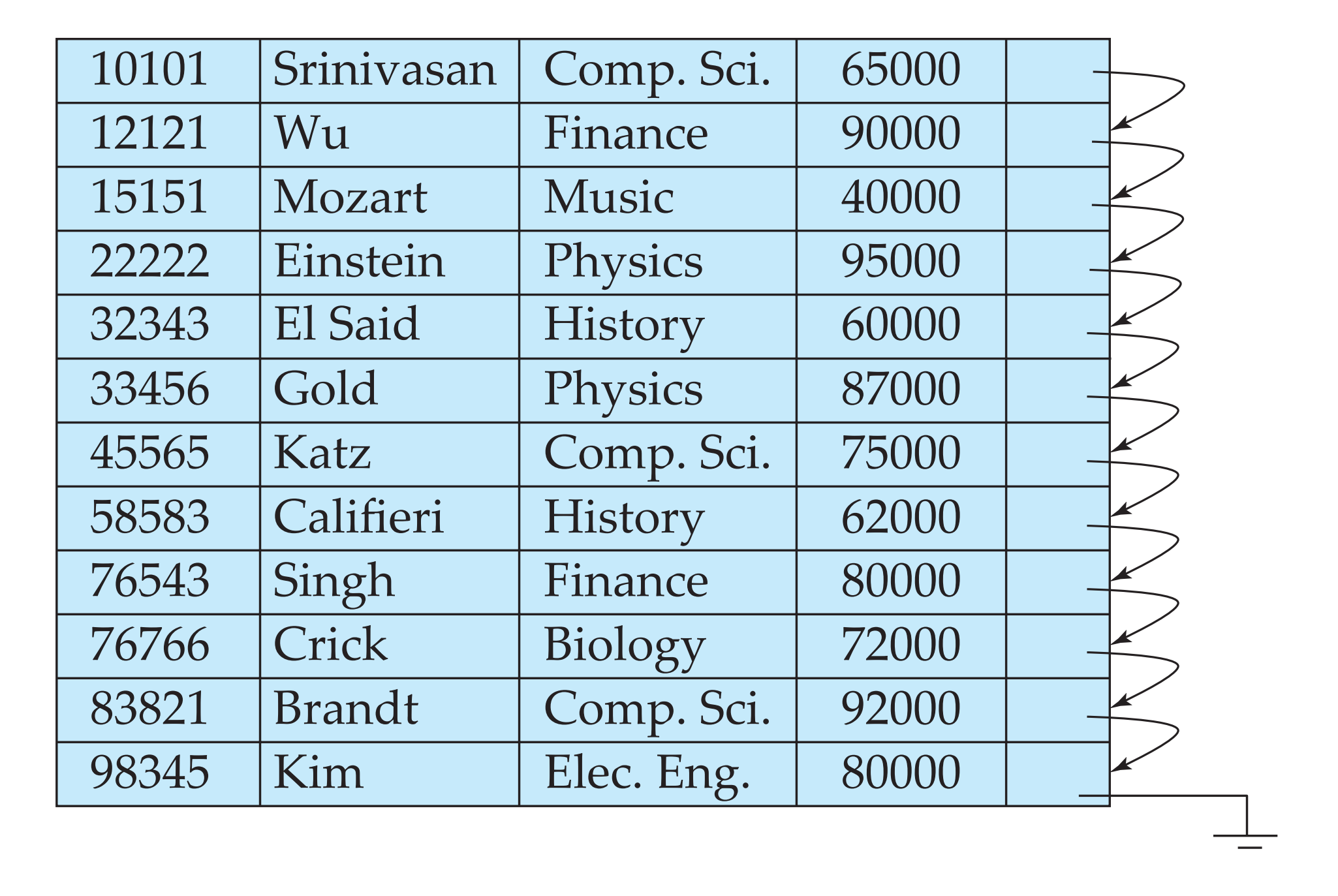
上图是文件,而索引一般用于根据搜索码找到相关记录在文件中的位置,顺序索引通常有以下几种方法
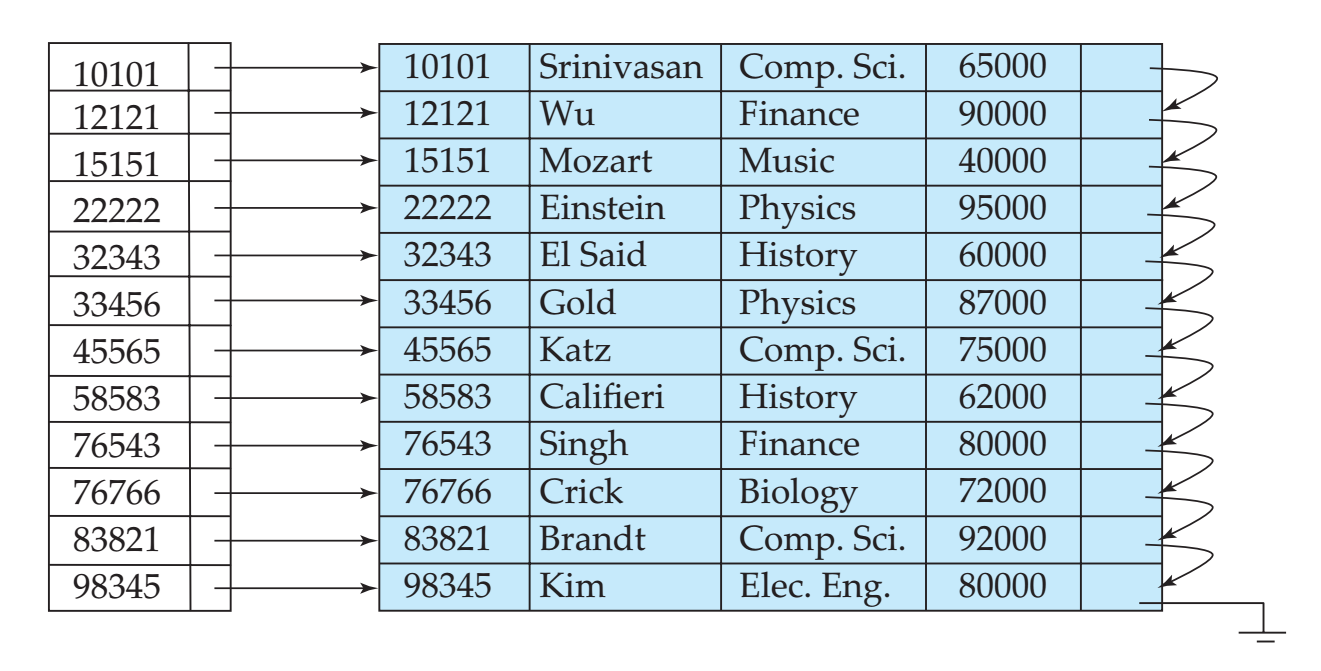
- 稠密索引:每一个搜索码有对应的指向对应记录位置的指针。
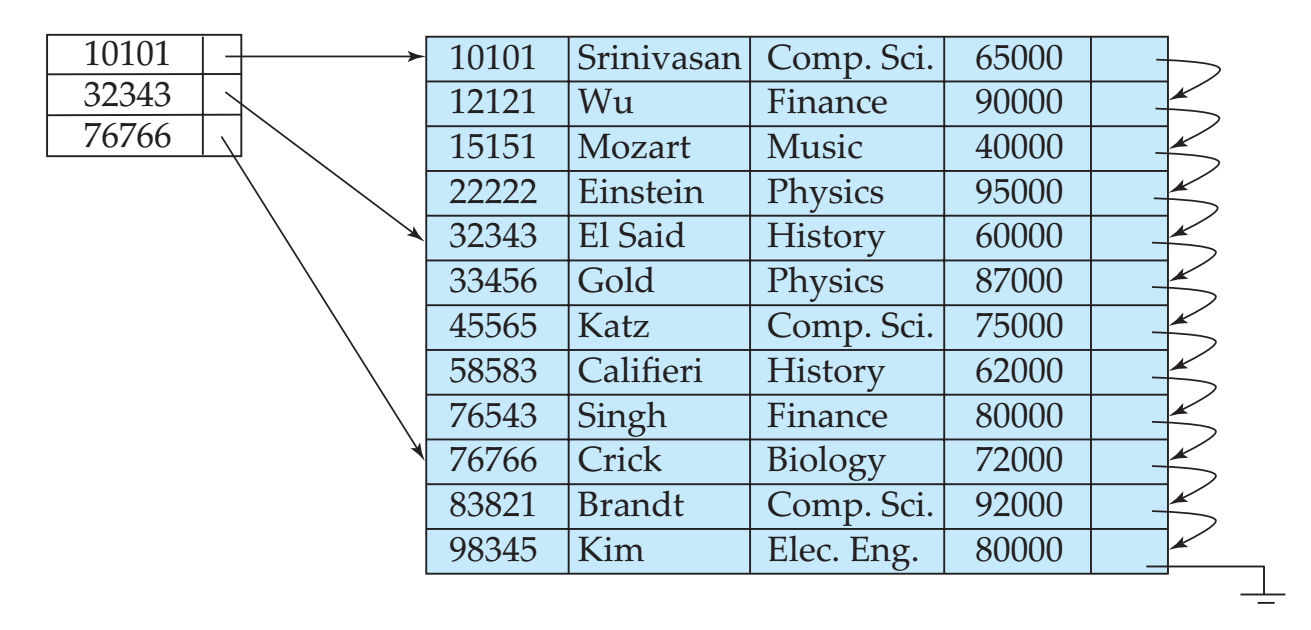
- 稀疏索引:只有部分搜索码有对应的指针,要求对应记录中的搜索码必须按照顺序保存。
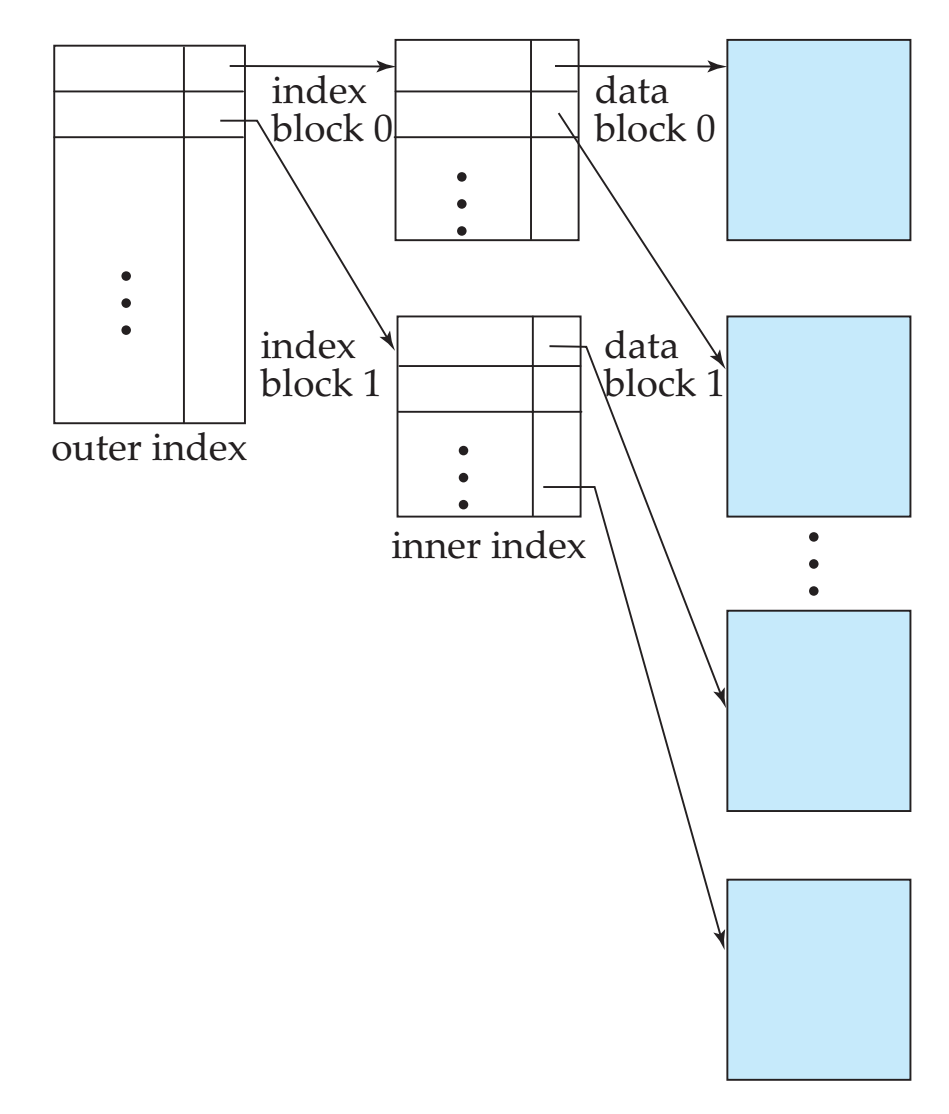
- 多级索引:如果索引大到跨越多个磁盘块,那么在一个索引上面查找某个元素需要读取很多磁盘块,因此可以考虑使用多级索引进行优化。
B+树索引
B+树是一种平衡数,它的基本特性为
- 从树根和每个到树叶的路径长度相同
- 每个非叶节点有
个子节点
- 叶节点最少包含
个搜索码
B+树的叶节点包含了个搜索码和
个指针,显然他们需要被按顺序摆放,
指向
对应的文件位置,而
指向下一个叶节点,便于遍历。

一个典型的叶节点是这样的:
非叶节点同样可以保存n个指向子节点指针和n-1个搜索码,假设非叶节点有m个子节点,那么
- 对于
,
指向包含搜索码小于
并且大于等于
的子节点
指向搜索码大于等于
部分
指向搜索码小于
部分
一个完整的B+数如下所示
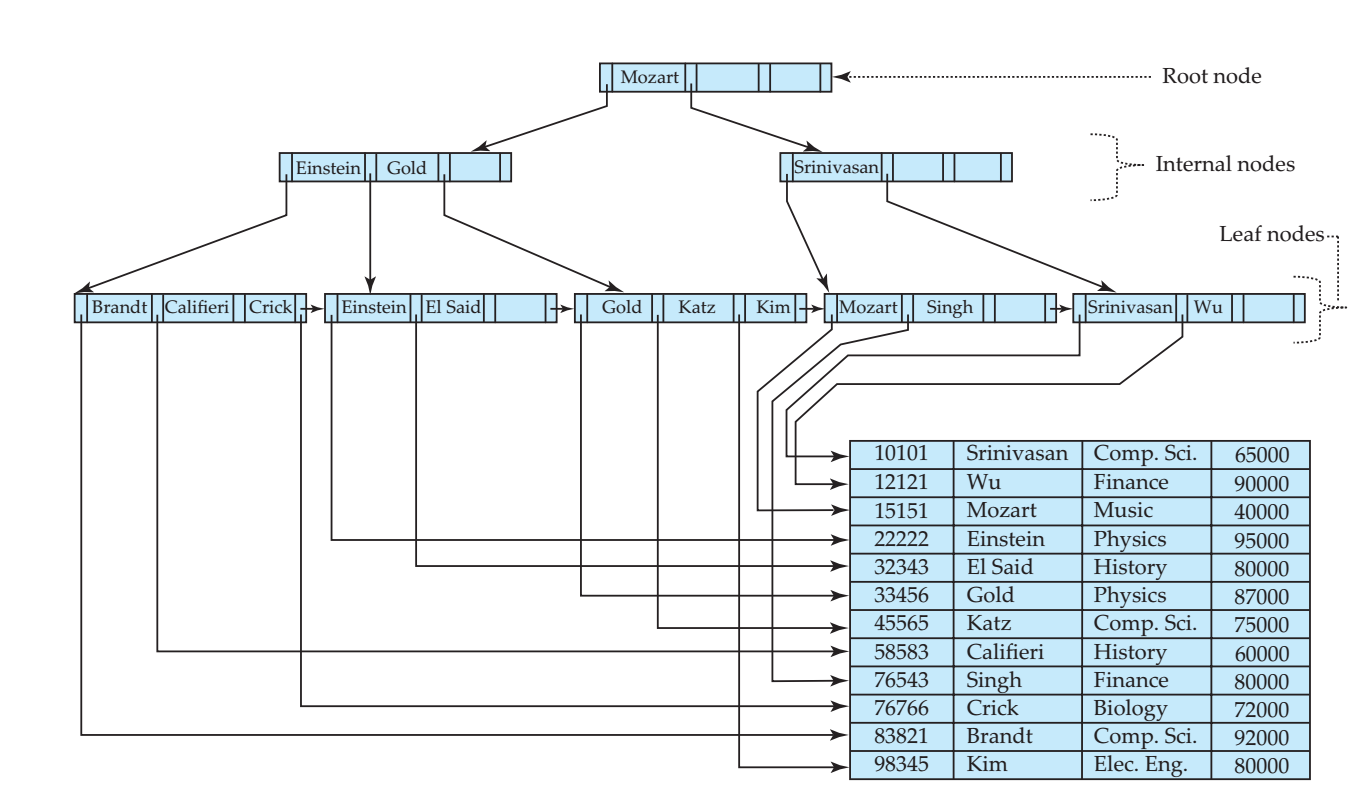
B+树扩展
B+树的变种B树可以用于组织文件,它直接将记录保存到了节点中,而不再需要指向文件的指针,具体数据结构和算法可以参考另外一篇文章算法笔记:B树。
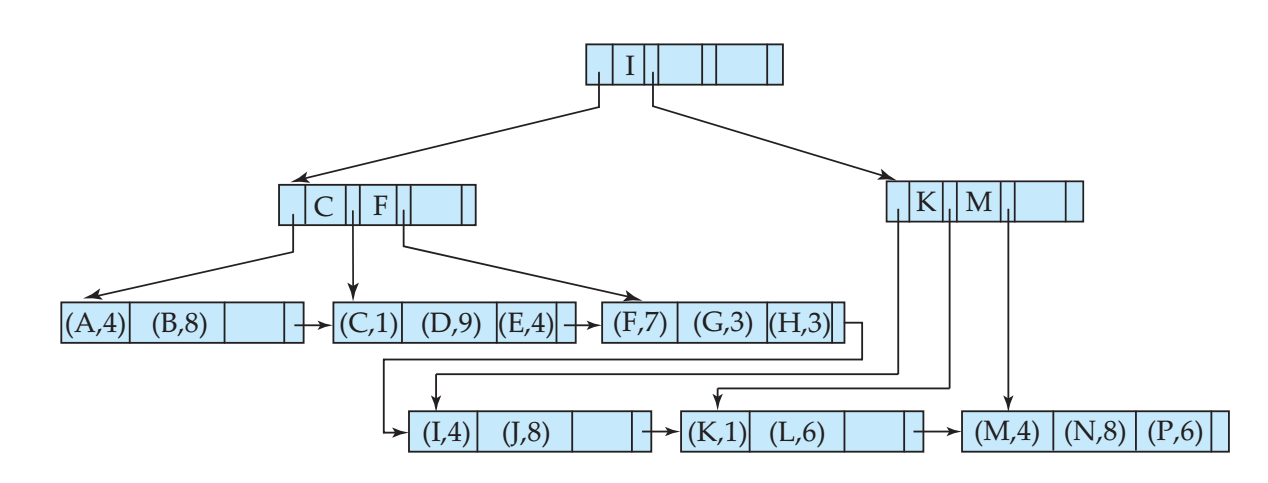
B树也可以用来组织索引,就是将记录位置替换为“搜索码+指针”的形式即可。
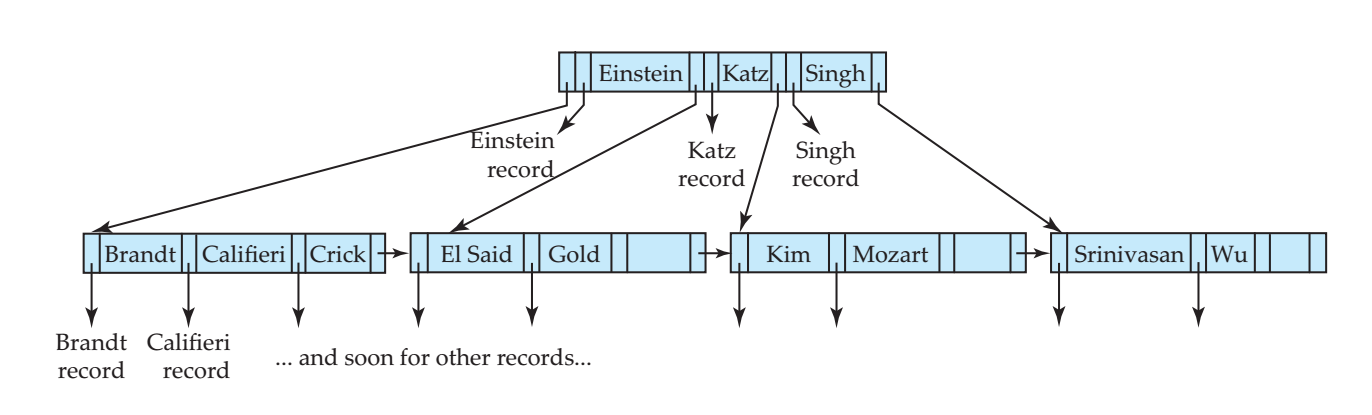
静态散列
利用散列可以直接将通过主键得到记录保存的磁盘块位置。
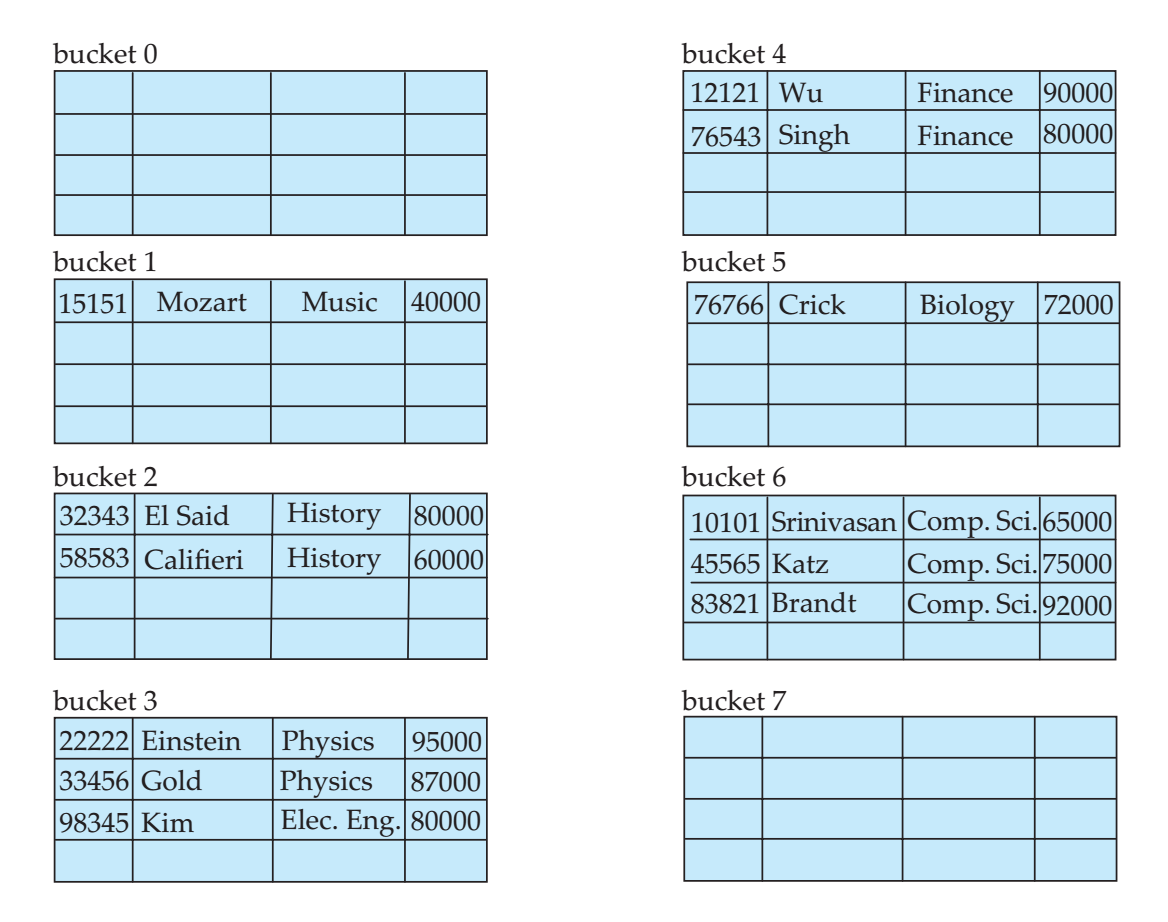
而如果使用散列组织索引的话,则在散列桶中保存包含的搜索码和对应的文件位置指针。
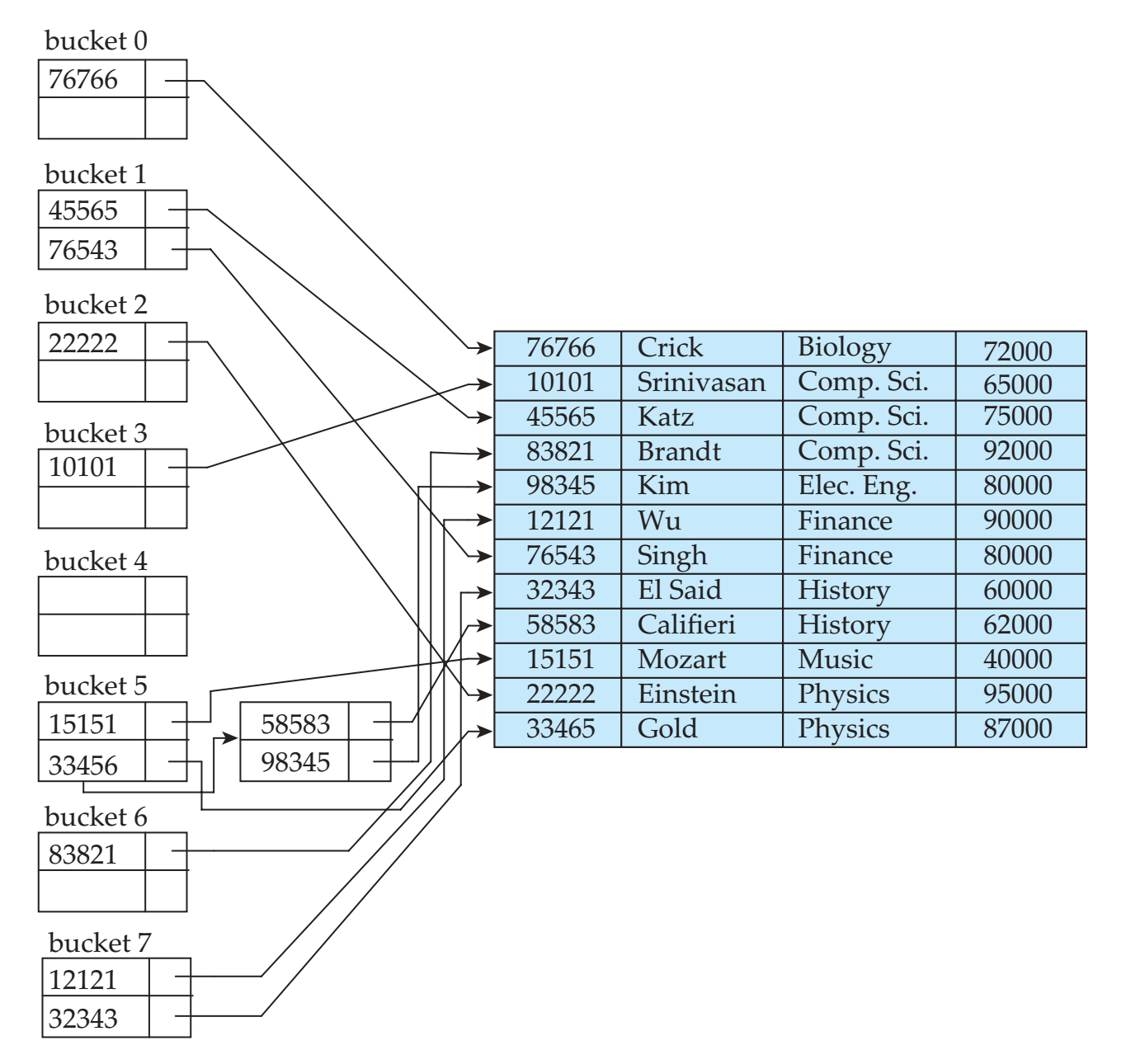
动态散列
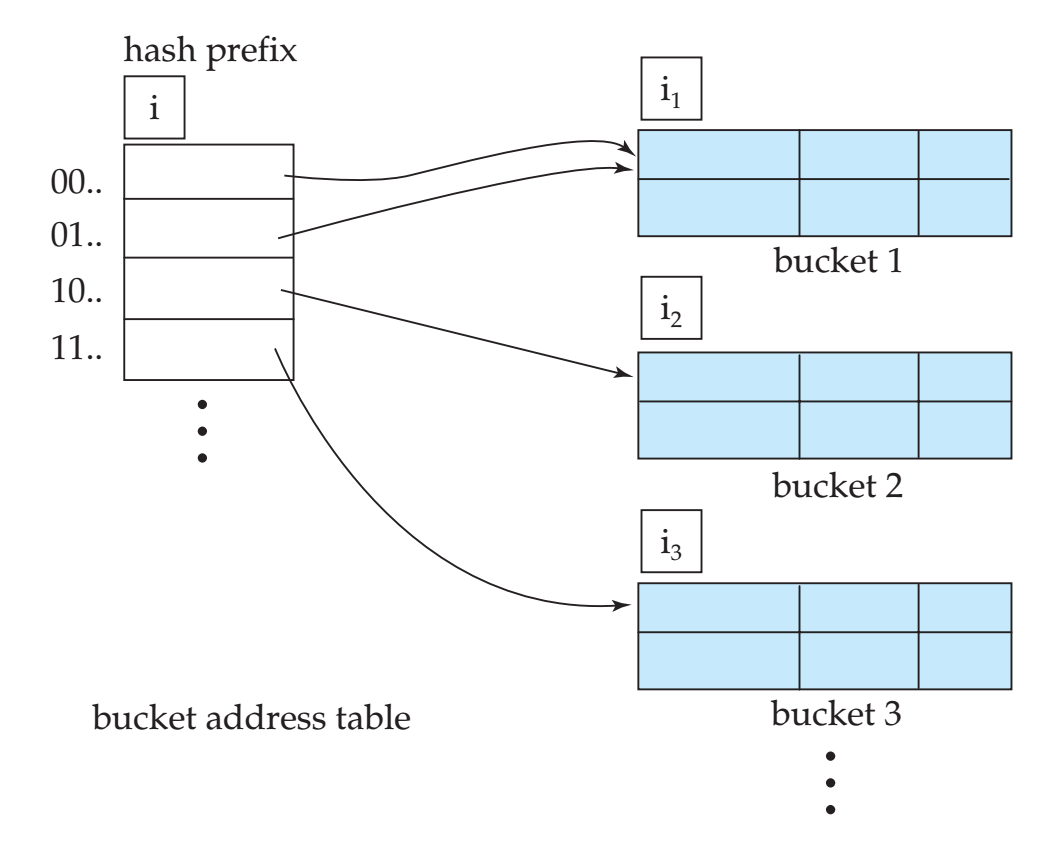
散列表中的数据量会不断增加,然而直接增加桶的数量需要大负荷的重组工作,一个更好的数据结构是动态散列。
假设散列函数得到一个位二进制的散列值,任意时刻使用前
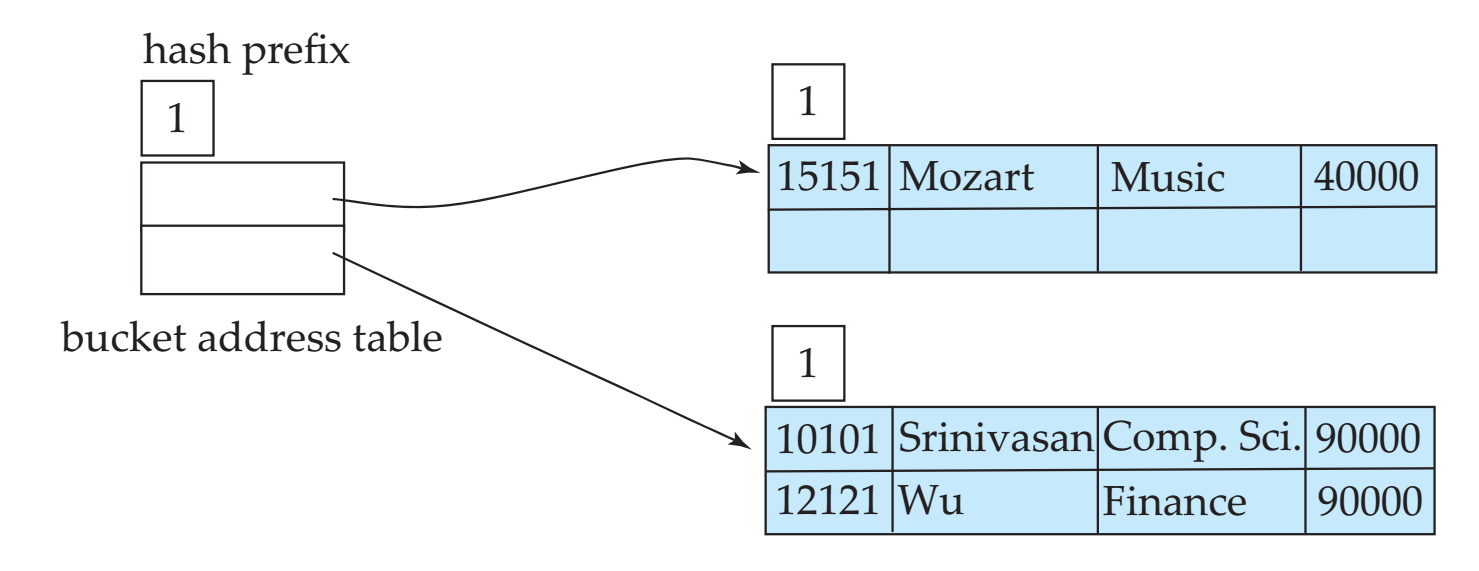
位,使用的位数随着数据量增加而增加。图中的桶编号
为和桶j关联的散列位数。
最开始,我们不使用任何的散列位,那也就只有一个散列桶。
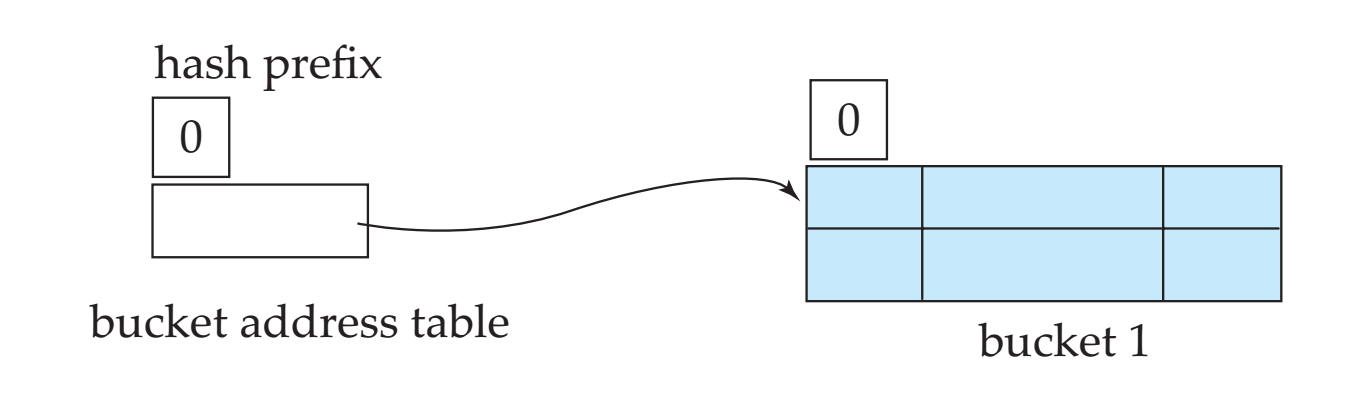
对于插入操作,根据散列值前i位找到散列桶,如果桶没有满,那么直接插入数据,否则需要考虑扩充散列位数或者分裂桶,假设和桶关联的位数为:
- 如果
,那么说明地址表中只有一个表项指向桶j,需要增加位数才能分裂桶
- 如果
,那么说明地址表中有多个表项指向桶j,只需要分配一个新桶即可
分裂之后需要重新组织受影响的记录和表项。例如,插入三项之后,散列表会变成以下情况:
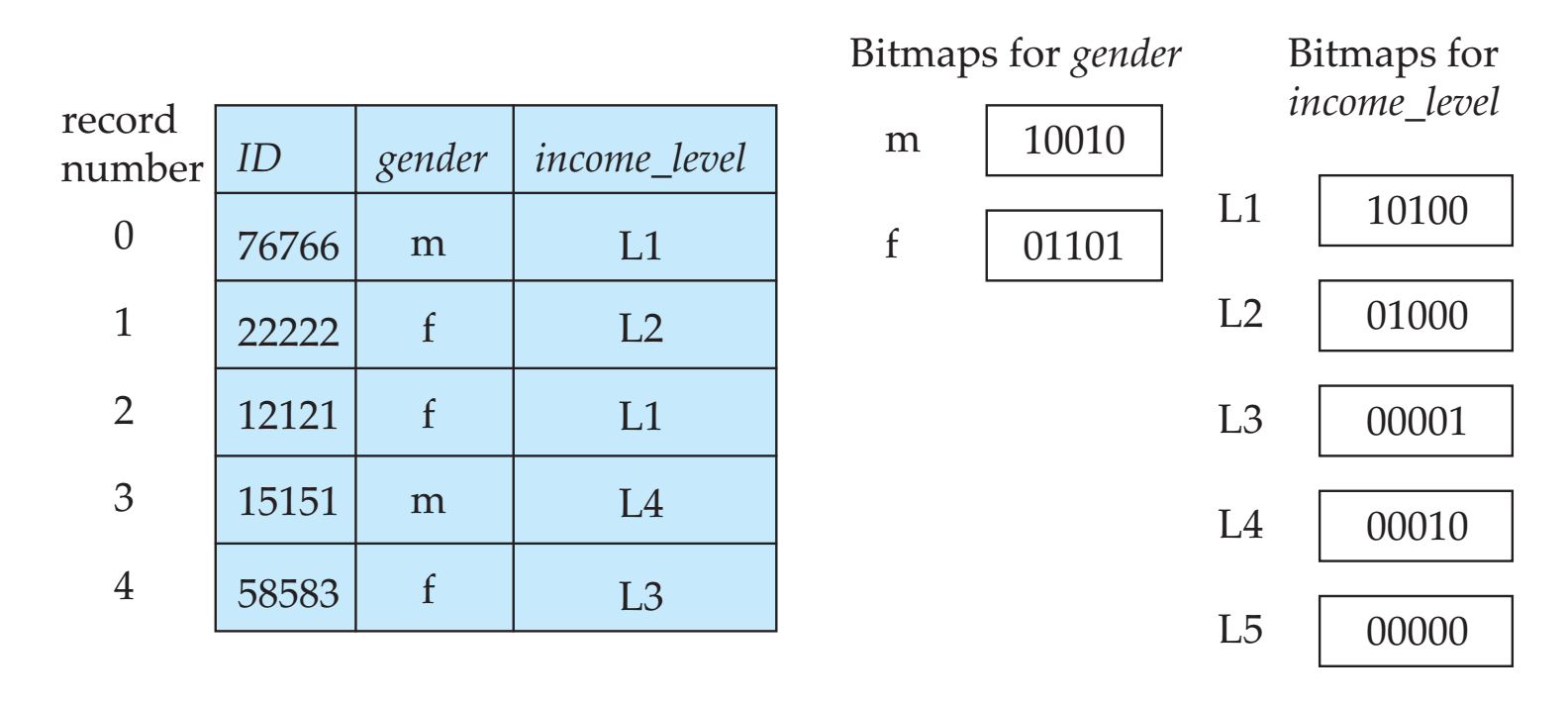
位图索引
对于枚举类型的属性,可以采用为每种取值建立一个位图进行索引,表示是否存在某种取值。
第十二章:查询处理
查询代价的度量
数据库中的查询优化器需要选择消耗资源最少的查询方案。磁盘的速度是最慢的,因此查询优化器主要将搜索磁盘次数和传送磁盘块数度量查询代价。令
- 磁盘块平均传输时间为
- 磁盘块平均搜索时间为
那么一次操作总代价就是搜索磁盘次数×+传送磁盘块数×
。
选择运算
查询最为底层的操作就是从文件中获取需要的记录。
- A1(线性搜索):扫描整个文件,测试每一条记录检查是否满足条件。
- A2(主索引,码属性等值比较):在主索引上进行等值比较,可以找到唯一匹配的记录。
- A3(主索引,非码属性等值比较):当属性为非码属性时,可能存在多条匹配的记录,如果它们是连续的。
- A4(辅助索引,等值比较):使用等值条件的选择可以使用辅助索引。若等值条件是码属性上的,则该策略可检索到唯一一条记录;若索引字段是非码属性,则可能检索到多条记录。
- AS(主索引,比较):可在顺序主索引进行区间扫描。
- A6(辅助索引,比较):同样在顺序主索引进行区间扫描。
| 算法 | 开销 | 原因 | |
|---|---|---|---|
| A1 | 线性搜索 | 一次初始搜索加上 |
|
| A1 | 线性搜索,码属性等值比较 | 平均情况 |
因为最多一条记录满足条件,所以只要找到所需的记录,扫描就可以终止。在最坏的情形下,仍需要 |
| A2 | B+树主索引,码属性等值比较 | (其中 |
|
| A3 | B+树主索引,非码属性等值比较 | 树的每层一次搜索,第一个块一次搜索。 b 是包含具有指定搜索码记录的块数。假定这些块是顺序存储(因为是主索引)的叶子块井且不需要额外搜索 | |
| A4 | B+树辅助索引,码属性等值比较 | 这种情形和主索引相似 | |
| A4 | B+树辅助索引,码属性等值比较 | (其中 n 是所取记录数。)索引查找的代价和 A3 相似,但是每条记录可能在不同的块上,这需要每条记录一次搜索。如果 n 值比较大,代价可能会非常高 | |
| A5 | B+树主索引,比较 | 和 A3, 非码属性等值比较情形一样 | |
| A6 | B+树辅助索引.比较 | 和 A4, 非码属性等值比较情形一样 |
数据库中会涉及到复杂的选择谓词的组合,例如有
- 合取:
- 析取:
- 取反:
实现的方式主要有
- A7(利用一个索引的合取选择):首先使用一个简单的条件选择出记录,然后在内存缓冲区中测试每条记录是否满足其余的简单条件。
- A8(使用组合索引的合取选择):如果多个属性上的等值合取条件刚好有组合索引,直接使用组合索引选择。
- A9(通过标识符的交实现合取选择):可以找出满足各个条件的记录指针,然后通过交集实现合取。
- A10(通过标识符的井实现析取选择):可以找出满足各个条件的记录指针,然后通过交集实现析取。
排序
- 外部排序归并算法
- 第一阶段,建立多个排好序的归井段。
i=0;
repeat
读入关系的 M 块数据或剩下的不足 M 块的数据;
在内存中对关系的这一部分进行排序;
将排好序的数据写到归并段文件 R. 中;
i=i+1·
until 到达关系末尾
- 第二阶段,对归并段进行归并。为 N 个归并段文件 R, 各分配一个内存缓冲块,井分别读人一个数据块:
repeat
在所有缓冲块中按序挑选第一个元组;
把该元组作为输出写出,并将其从缓冲块中删除;
if 任何一个归并段文件 R, 的媛冲块为空并且没有到达 R, 末尾
then 读入 R, 的下一块到相应的缓冲块
until 所有的缓冲块均空
如果内存不足以给每个归并段分配一个缓冲区,那么可以进行多次合并:
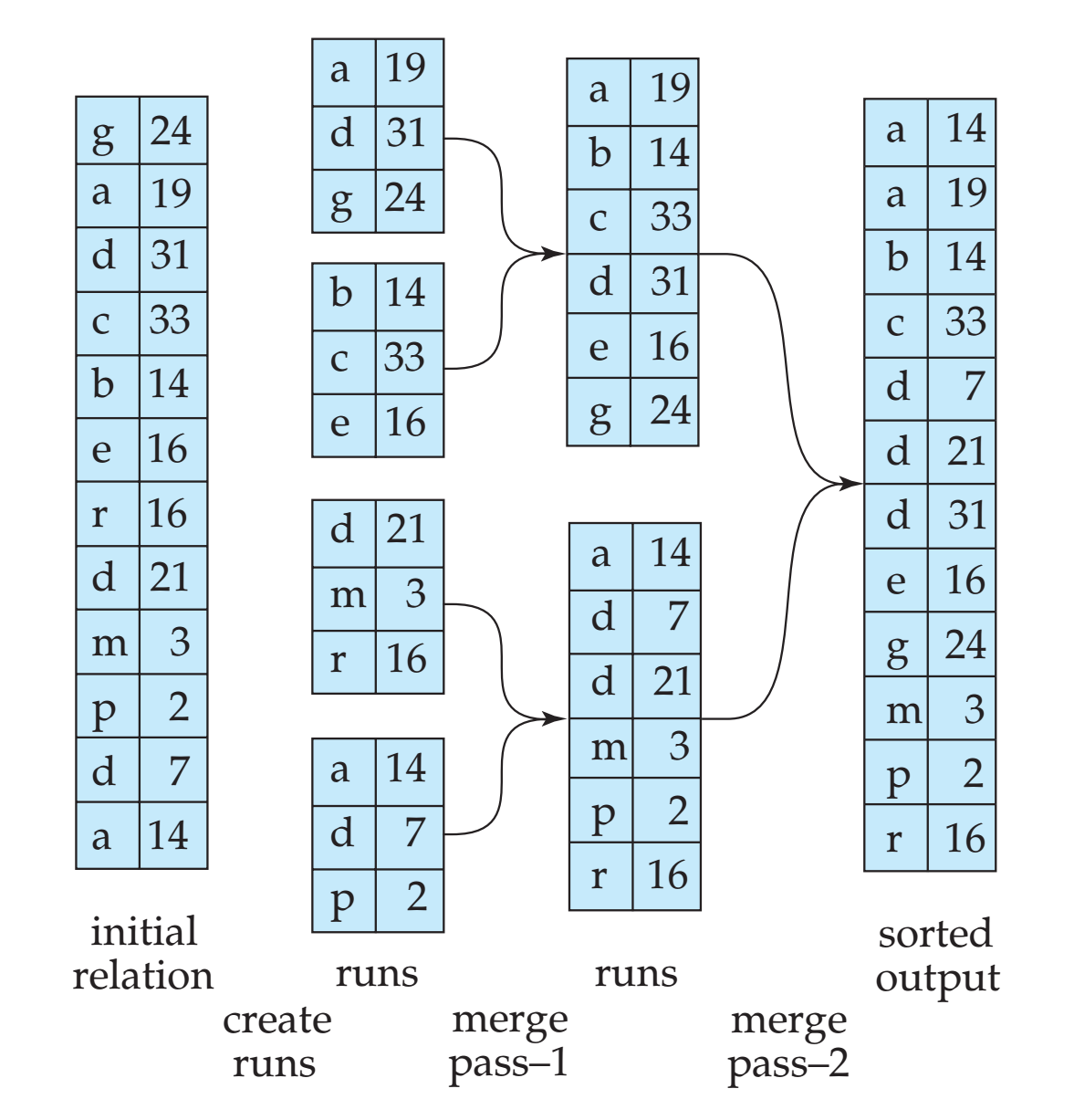
连接运算
- 嵌套循环连接:能想到最简单的方式就是使用一个两层循环完成连接。
for each 元组 t_r in r do begin
for each 元组 t_s in s do begin
测试元组对 (t_r,t_s) 是否满足连接条件
如果满足,把 t_r+t_s 加到结果中
end
end
- 块嵌套循环连接:当内存无法容纳任何一个关系时,可以考虑以磁盘块为单位进行连接。
for each 块 B_r of r do begin
for each 块 B_s of s do begin
for each 元组 t_r in B_r do begin
for each 元组 t_s in B_s do begin
测试元组对 (t_r,t_s) 是否满足连接条件
如果满足,把 t_r+t_s 加到结果中
end
end
end
end
- 索引嵌套循环连接:如果嵌套循环连接中内循环的关系上存在连接属性的索引,那么可以使用索引寻找匹配的记录,而不再需要扫描整个关系。
- 归并连接:归并连接用来处理等值连接,将关系按照连接属性排序之后,按照顺序进行归并。
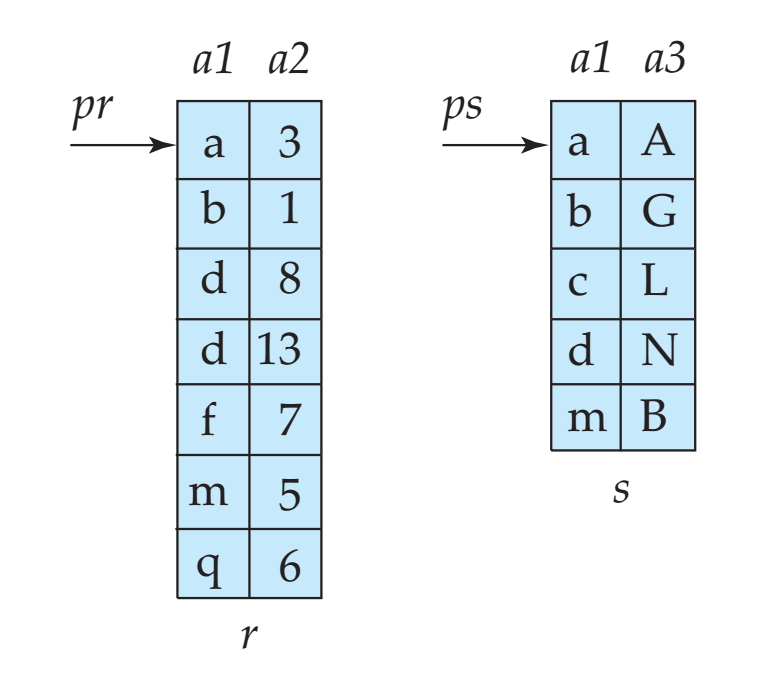
- 散列连接:散列连接同样用于等值连接和自然连接,在连接属性上利用散列函数将记录归到各个散列桶中,然后在散列桶之间进行索引嵌套循环连接。
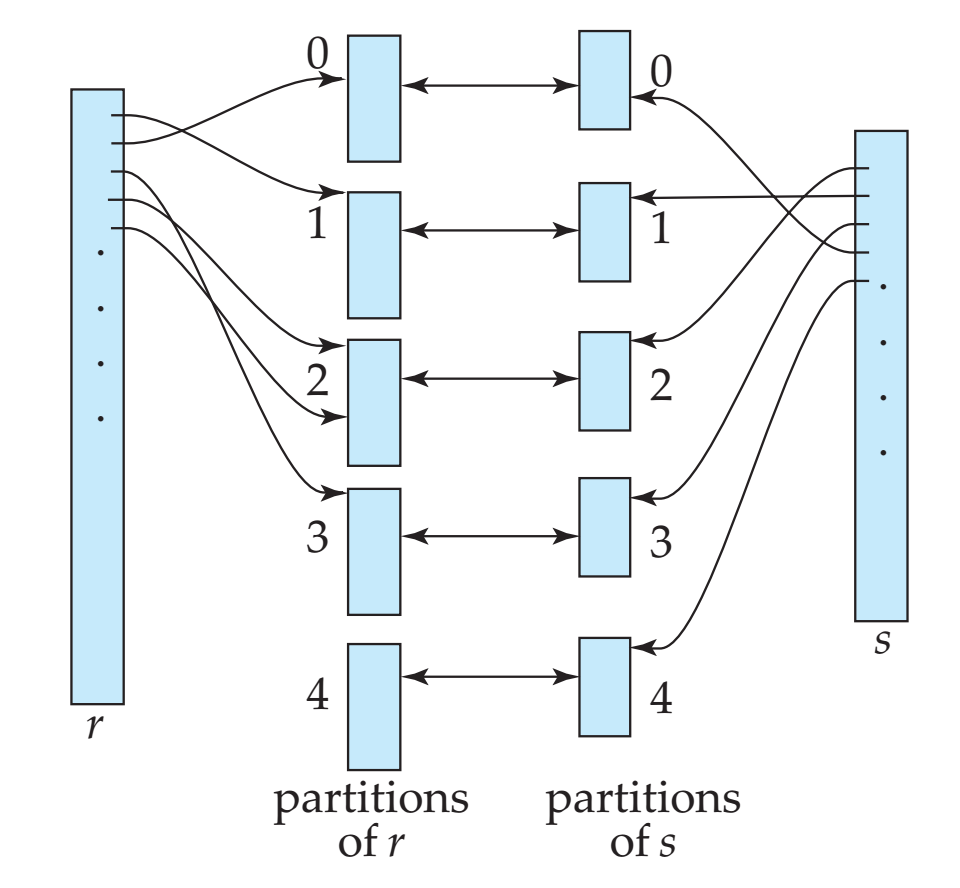
其他运算
- 去除重复:可以使用排序法或者散列法来解决。
- 集合运算:和去除重复类似,可以采用排序法或者算咧法。
- 外连接:可以找出没有匹配的元组填充空值加入结果,或者修改连接算法给不匹配的元组填充空值。
- 聚集:和去除重复类似,可以采用排序法或者算咧法。
表达式计算
SQL表达式计算有两种方式
- 物化:计算出子表达式得到的关系,然后进行下一层运算。
- 流水线:当子表达式的一个元组产生后,立刻参与下一层的运算。
第十三章:查询优化
关系表达式的转换
查询优化器需要产生一些等价的关系表达式,然后选择出估计代价最小的等价表达式。通过一系列的等价规则可以产生等价的表达式,例如:
- ...
通过下面的算法可以产生所有等价表达式
proudure genAIIEquivalent(E)
EQ = |E|
repeat
将 EQ 中的每条表达式 E_i 与每条等价规则 R_j 进行匹配
如果 E_i 的某个子表达式与R_j的某一边相匹配
生成一个与 E_i 等价的 E', 其中 e_i 被替换成 R_j 的另一边
如果 E' 不在 EQ 中,则将其添加到 EQ 中
until 不再有新的表达式可以添加到 EQ 中
表达式结果集统计大小的估计
优化器需要统计信息来估计查询代价,通常数据库目录存储了数据库的下列统计信息:
, 关系 r 的元组数。
,, 包含关系 r 中元组的磁盘块数。
, 关系 r 中每个元组的字节数。
, 关系 r 的块因子一—一个磁盘块能容纳关系 r 中元组的个数。
, 关系 r 中属性 A 中出现的非重复值个数。
进一步可以通过维护直方图来估计每个属性的每种取值的分布,用于更加精确地估计选择结果数目:
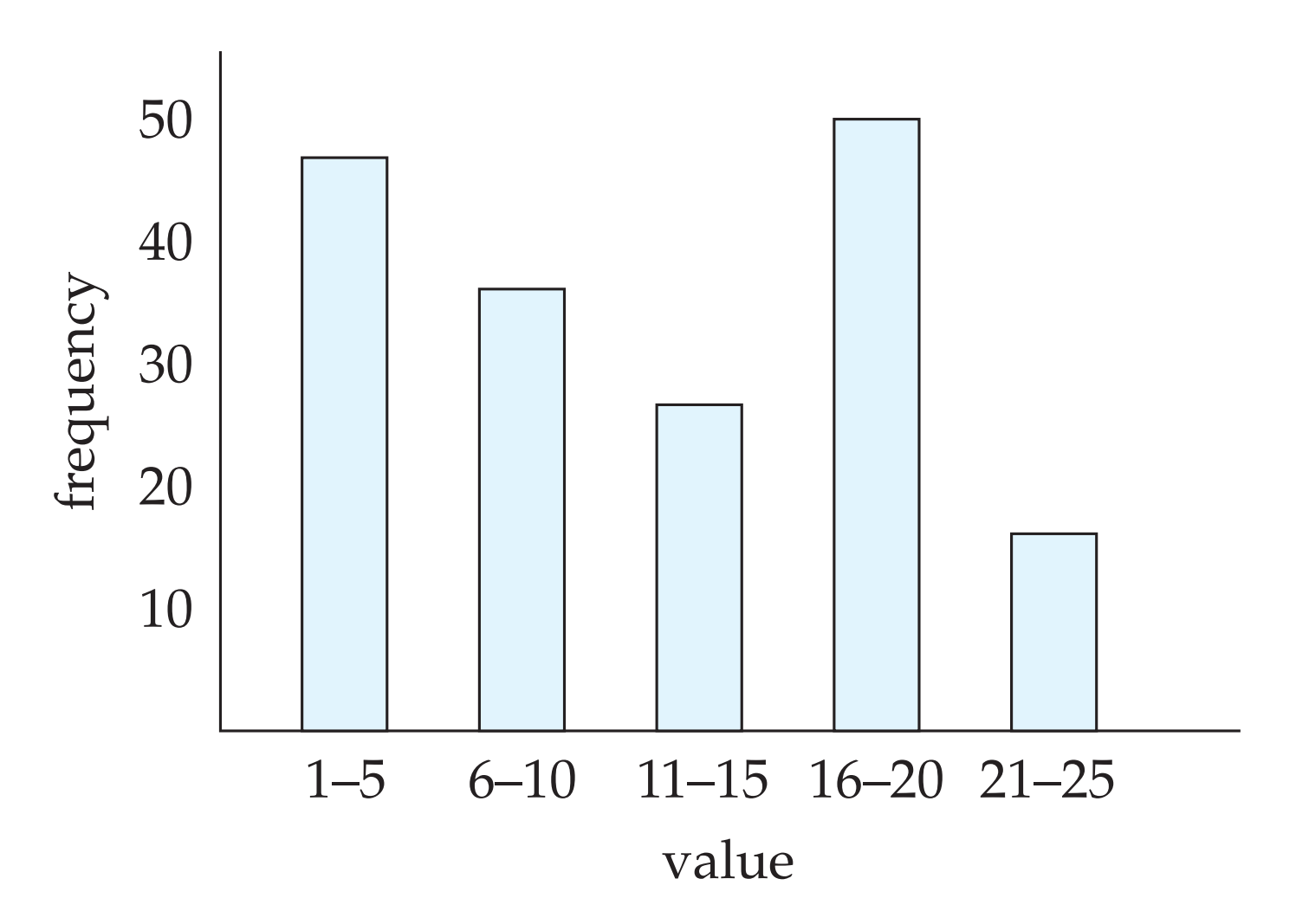
有了目录信息就可以估计选择结构数目:
:假设取值均匀分布,那么选择得到记录数量为
。
:
:
:
- 自然连接:自然连接操作略微复杂,假设自然连接条件的属性集分别为R和S
- 如果
——结果数为笛卡尔积
- 如果
是R的主键——结果数刚好为关系r中的元组数
- 其他情况估计为
- 如果
其他操作的估计方法不再介绍。
执行计划选择
- 基于代价的连接顺序选择:一组连接操作会有多种连接顺序可以选择,可以使用动态规划找到最佳的顺序
procedure FindBestPlan(S)
if (bestplan[S].cost != oo) /* bestplan[S] 已经计算好了*/
retum bestplan[S]
if (S只包含一个关系)
根据访问 S 的最佳方式设置 bestplan[S].plan 和 bestplan[S].cost
else for each S 的非空子集 S1, 且 S1 != S
Pl = FindBestPlan(SI)
P2 = FindBestPlan(S - S1)
A = 连接 Pl 和 P2 的结果的最佳算法
cost = Pl.cost + P2.cosi + A的代价
If cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[SJ.plan = "执行 Pl.plan; 执行 P2. plan;
利用 A 连接 Pl 和 P2 的结果”
retum bestplan[S]
-
采用等价规则的基千代价的优化器:直接采用等价规则转换产生等价表达式搜索空间过大,很少会直接使用。
-
启发式优化:产生所有的等价转换是不现实的,因此可以采用启发规则来产生一些等价表达式进行选择。例如可以:
- 尽早执行选择运算。
- 尽早执行投影运算。
