

前言
Redis 已经是大家耳熟能详的东西了,日常工作也都在使用,面试中也是高频的会涉及到,那么我们对它究竟了解有多深刻呢?
我读了几本 Redis 相关的书籍,尝试去了解它的具体实现,将一些底层的数据结构及实现原理记录下来。
本文将介绍 Redis 中底层的 dict(字典) 的实现方法。 它是 Redis 中哈希键和有序集合键的底层实现之一。

可以看到图中,当我给一个 哈希结构中放了两个短的值,此时 哈希的编码方式是 ziplist, 而当我插入一个比较长的值,哈希的编码方式成为了 hashtable.
注:本文默认读者对于 hashtable 这一数据结构有基本的了解,因此不会详细讲解这块内容
定义
字典
字典作为一种常用的数据结构,也被内置在很多编程语言中,比如 Java 的 HashMap 和 Python 的 dict. 然而 C 语言又没有(知道为什么大家更喜欢写 Java,Python 等高级语言了吧).
所以 Redis 自己实现了一个字典:
typedef struct dict{
// 类型特定函数
dictType *type;
// 私有数据
void *private;
// 哈希表
dictht ht[2];
// rehash 索引,当当前的字典不在 rehash 时,值为-1
int trehashidx;
}
- type 和 private
这两个属性是为了实现字典多态而设置的,当字典中存放着不同类型的值,对应的一些复制,比较函数也不一样,这两个属性配合起来可以实现多态的方法调用。
- ht[2]
这是一个长度为 2 的 dictht结构的数组,dictht就是哈希表。
- trehashidx
这是一个辅助变量,用于记录 rehash 过程的进度,以及是否正在进行 rehash 等信息。
看完字段介绍,我们发现,字典这个数据结构,本质上是对 hashtable的一个简单封装,因此字典的实现细节主要就来到了 哈希表上。
哈希表
哈希表的定义如下:
typedef struct dictht{
// 哈希表的数组
dictEntry **table;
// 哈希表的大小
unsigned long size;
// 哈希表的大小的掩码,用于计算索引值,总是等于 size-1
unsigned long sizemasky;
// 哈希表中已有的节点数量
unsigned long used;
}
其中哈希表中的节点的定义如下:
typedef struct dictEntry{
// 键
void *key;
// 值
union {
void *val;
uint64_tu64;
int64_ts64;
}v;
// 指向下一个节点的指针
struct dictEntry *next;
} dictEntry;
如果你看过 Java 中 HashMap 的源码,你会发现这一切是如此的熟悉。因此我不对其中的每个属性进行详细的解释了。
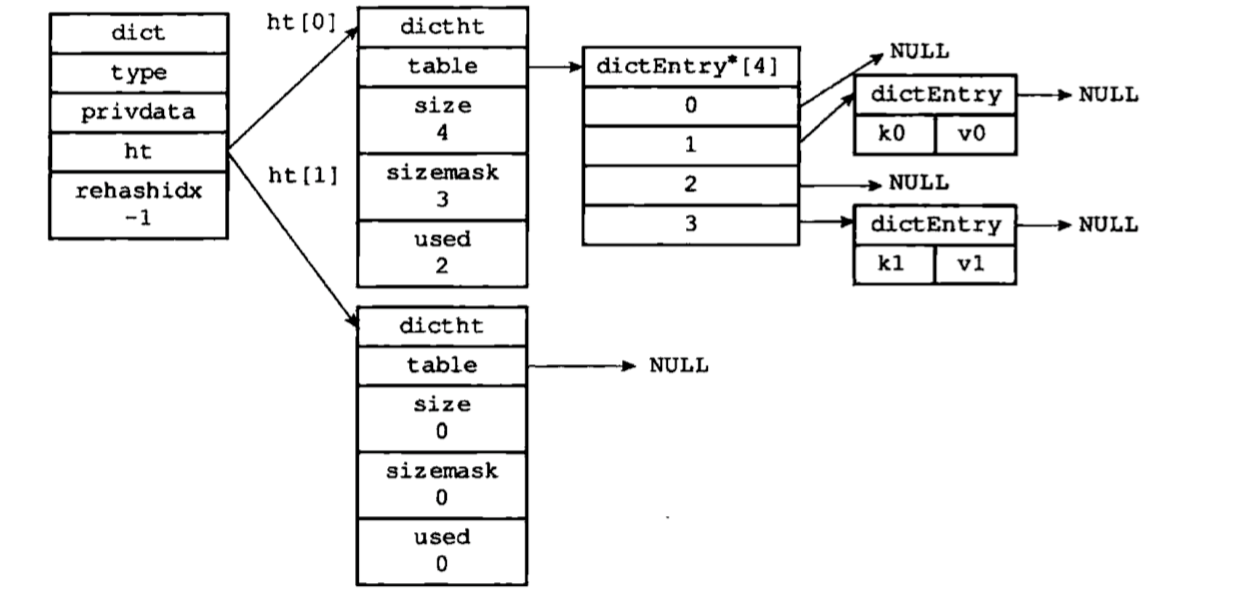
上图是一个没有处在 rehash 状态下的字典。可以看到,字典持有两张哈希表,其中一个的值为 null, 另外一个哈希表的 size=4, 其中两个位置上已经存放了具体的键值对,而且没有发生 hash 冲突。
哈希算法
哈希表添加一个元素首先需要计算当前键值的 hash 值,之后根据 hash 值来定位即将它即将被放入的槽。由于 hash 值可能冲突,因此 hash 算法的选择尤其重要,要将 key 值打散的足够均匀。
Redis 选用了业内的一些算法来实现 hash 过程。
在 Redis 5.0 以及 4.0 版本,都使用了 siphash 哈希算法。siphash 可以在输入的 key 值很小的情况下,产生随机性比较好的输出。
在 Redis 3.2, 3.0 以及 2.8 版本,使用 Murmurhash2 哈希算法,Murmurhash 可以在输入值是有规律时,也能给出比较好的随机分布。
当然以上两个算法,都有一个共同点,就是计算性能很好,这才符合 Redis 的产品特性。
hash 结束之后,会根据当前哈希表的长度,来确定当前键值所在的 index, 而由于长度有限,那么迟早会产生两个键值要放到同一个位置的问题,也就是常说的 hash 冲突问题。
哈希冲突
既然是哈希表,那么就也有 hash 冲突问题。
Redis 的哈希表处理 Hash 冲突的方式和 Java 中的 HashMap 一样,选择了分桶的方式,也就是常说的链地址法。Hash 表有两维,第一维度是个数组,第二维度是个链表,当发生了 Hash 冲突的时候,将冲突的节点使用链表连接起来,放在同一个桶内。
由于第二维度是链表,我们都知道链表的查找效率相比于数组的查找效率是比较差的。那么如果 hash 冲突比较严重,导致单个链表过长,那么此时 hash 表的查询效率就会急速下降。
扩容与缩容
当哈希表过于拥挤,查找效率就会下降,当 hash 表过于稀疏,对内存就有点太浪费了,此时就需要进行相应的扩容与缩容操作。
想要进行扩容缩容,那么就需要描述当前 hasd 表的一个填充程度,总不能靠感觉。这就有了 负载因子 这个概念。
负载因子是用来描述哈希表当前被填充的程度。计算公式是:负载因子=哈希表以保存节点数量 / 哈希表的大小.
在 Redis 的实现里,扩容缩容有三条规则:
- 当 Redis 没有进行 BGSAVE 相关操作,且
负载因子>1的时候进行扩容。 - 当
负载因子>5的时候,强行进行扩容。 - 当
负载因子<0.1的时候,进行缩容。
根据程序当前是否在进行 BGSAVE 相关操作,扩容需要的负载因子条件不相同。
这是因为在进行 BGSAVE 操作时,存在子进程,操作系统会使用 写时复制 (Copy On Write) 来优化子进程的效率。Redis 尽量避免在存在子进程的时候进行扩容,尽量的节省内存。
熟悉 hash 表的读者们应该知道,扩容期间涉及到到 rehash 的问题。
因为需要将当前的所有节点挪到一个大小不一致的哈希表中,且需要尽量保持均匀,因此需要将当前哈希表中的所有节点,重新进行一次 hash. 也就是 rehash.
渐进式 hash
原理
在 Java 的 HashMap 中,实现方式是 新建一个哈希表,一次性的将当前所有节点 rehash 完成,之后释放掉原有的 hash 表,而持有新的表。
而 Redis 不是,Redis 使用了一种名为渐进式 hash 的方式来满足自己的性能需求。
这是一个我亲历的面试原题:Redis 的字典结构,在 rehash 时和 Java 的 HashMap 的 Rehash 有什么不同?
rehash 需要重新定位所有的元素,这是一个 O(N) 效率的问题,当对数据量很大的字典进行这一操作的时候,比较耗时。
对于单线程的 Redis 来说,表示很难接受这样的延时,因此 Redis 选择使用 一点一点搬的策略。
Redis 实现了渐进式 hash. 过程如下:
- 假如当前数据在 ht[0] 中,那么首先为 ht[1] 分配足够的空间。
- 在字典中维护一个变量,rehashindex = 0. 用来指示当前 rehash 的进度。
- 在 rehash 期间,每次对 字典进行 增删改查操作,在完成实际操作之后,都会进行 一次 rehash 操作,将 ht[0] 在
rehashindex位置上的值 rehash 到 ht[1] 上。将 rehashindex 递增一位。 - 随着不断的执行,原来的 ht[0] 上的数值总会全部 rehash 完成,此时结束 rehash 过程。 将 rehashindex 置为-1.
在上面的过程中有两个问题没有提到:
- 假如这个服务器很空余呢?中间几小时都没有请求进来,那么同时保持两个 table, 岂不是很浪费内存?
解决办法是:在 redis 的定时函数里,也加入帮助 rehash 的操作,这样子如果服务器空闲,就会比较快的完成 rehash.
- 在保持两个 table 期间,该哈希表怎么对外提供服务呢?
解决办法:对于添加操作,直接添加到 ht[1] 上,因此这样才能保证 ht[0] 的数量只会减少不会增加,才能保证 rehash 过程可以完结。而删除,修改,查询等操作会在 ht[0] 上进行,如果得不到结果,会去 ht[1] 再执行一遍。
渐进式 hash 带来的好处是显而易见的,他采用了分而治之的思想,将 rehash 操作分散到每一个对该哈希表的操作上以及定时函数上,避免了集中式 rehash 带来的性能压力。
与此同时,渐进式 hash 也带来了一个问题,那就是 在 rehash 的时间内,需要保存两个 hash 表,对内存的占用稍大,而且如果在 redis 服务器本来内存满了的时候,突然进行 rehash 会造成大量的 key 被抛弃。
小应用
我们学习渐进式 hash 是为了面试吗?如果不是为了面试,那么我们又不用去设计一个 Redis, 为啥要知道这个?
我个人觉得,我们是为了理解它的思想。在我学习完渐进式 hash 之后的某一天,在某论坛回答了一位网友的问题。
他的问题是这样一个场景:
有两张表,一张工作量表,一张积分表,积分=工作量*系数。
系数是有可能改变的,当系数发生变化之后,需要重新计算所有过往工作量的对应新系数的积分情况。
而工作量表的数据量比较大,如果在系数发生变化的一瞬间开始重新计算,可以会导致系统卡死,或者系统负载上升,影响到在线服务。
怎么解决这个问题?
我个人的理解是,这个可以用 redis 渐进式 rehash 的思路来解决。
原数据(原有的工作量表), 负载因子达到某个值(系数改变), 进行 rehash(重新计算所有值)
所有的元素都齐活了。
我们只需要额外记录一个标志着正在进行重新计算过程中的变量即可。之后的思路就完全和 Redis 一致了。
- 首先我们可以在某个用户请求自己的积分的时候,再帮他计算新的积分。来分散系统压力。
- 如果系统压力并不大,可以在系统定时任务里重算一小部分(一个 batch), 具体多少可以由数据量决定。
这样完美的解决了性能压力,代码层面只是加一个记录参数以及给一个接口加个"触发器"而已,也算不上麻烦~.
思考问题:为什么缩容不用考虑 bgsave?
这是我看的《Redis 深度历险:核心原理和应用实践》中的一个思考问题,我在这里写下个人的一点理解。
扩容时考虑 BGSAVE 是因为,扩容需要申请额外的很多内存,且会重新链接链表(如果会冲突的话), 这样会造成很多内存碎片,也会占用更多的内存,造成系统的压力。
而缩容过程中,由于申请的内存比较小,同时会释放掉一些已经使用的内存,不会增大系统的压力。因此不用考虑是否在进行 BGSAVE 操作。
总结
Redis 的字典数据结构,和下一篇文章要将的跳跃表数据结构一样,是面试中的高频问题。
Redis 字典中,用 table[2] 的数组保存着两张 hash 表,正常情况下只使用其中一张,在 rehash 的时候使用另外一张表。
Redis 为了提高自己的性能,rehash 过程不是一次性完成的,而是使用了渐进式 hash 的策略,逐步的将原有元素 rehash 到新的哈希表中,直到完成。
至于其他方面,和其他语言中的哈希表区别不是特别大,比如 hash 算法以及如何解决哈希冲突。
参考文章
《Redis 的设计与实现(第二版)》
《Redis 深度历险:核心原理和应用实践》
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。 也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >------>呼延十
