

最近有幸拜读 Google 分布式的三大论文,本着好记性不如烂笔头的原则,谈谈楼主对分布式系统开发的一点小小的心得~
相信用过 Hadoop 的同学在等待结果输出的时候会出现类似于这样的 INFO : 2020-01-17 11:44:14,132 Stage-11 map = 0%, reduce = 0% 的日志,它展示了 MapReduce 的执行过程,下面我们也将就 MapReduce 进行展开,阐述 MapReduce 的执行原理以及根据 Google 的论文实现了 mini 版的 MapReduce。
什么是 MapReduce
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
就像 Google 的 MapReduce 论文中所说的, MapReduce 是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。用户首先创建一个 Map 函数处理一个基于 key/value pair 的数据集合,输出中间的基于 key/value pair 的数据集合,然后再创建一个 Reduce 函数用来合并所有的具有相同中间 key 值的中间 value 值。
MapReduce 的例子
Map 与 Reduce 的原理
MapReduce编程模型的原理是:利用一个输入 key/value pair 集合来产生一个输出的 key/value pair 集合。MapReduce 库的用户用两个函数表达这个计算:Map和Reduce。
Map : 用户自定义的 Map 函数接受一个输入的 key/value pair 值,然后产生一个中间 key/value pair 值的集合。MapReduce 库把所有具有相同中间 key 值的中间 value 值集合在一起后传递给 Reduce 函数。
Reduce : 用户自定义的 Reduce 函数接受一个中间 key 的值和相关的一个 value 值的集合。Reduce 函数合并这些 value 值,形成一个较小的 value 值的集合。一般的,每次 Reduce 函数调用只产生 0 或 1 个输出 value 值。通常我们通过一个迭代器把中间 value 值提供给 Reduce 函数,这样我们就可以处理无法全部放入内存中的大量的 value 值的集合。
Map 与 Reduce 的应用例子
- 计算文档中每个单词出现的次数:Map 函数处理文档,对文档中的单词进行拆分,然后输出(单词,1)。Reduce 函数把相同单词的 value 值都累加起来,产生(单词,记录总数)结果。
- 倒排索引:Map 函数分析每个文档输出一个(词,文档号)的列表,Reduce函数的输入是一个给定词的所有(词,文档号),排序所有的文档号,输出(词,list(文档号))。所有的输出集合形成一个简单的倒排索引,它以一种简单的算法跟踪词在文档中的位置。
MapReduce 执行过程图解
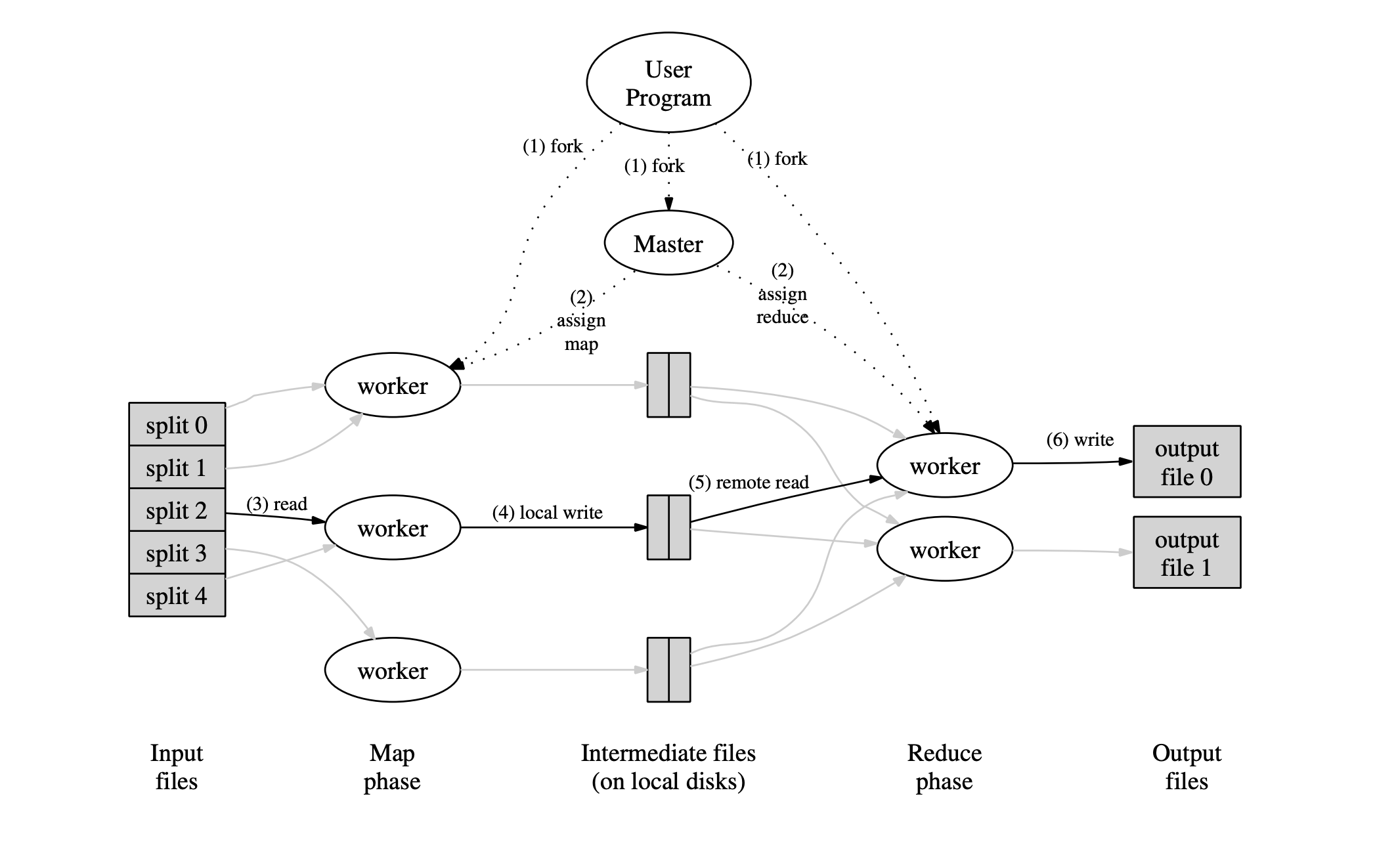
- 用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大小一般从 16MB 到 64MB (可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量的程序副本。
- 这些程序副本中的有一个特殊的程序
master。副本中其它的程序都是worker程序,由master分配任务。有 M 个 Map 任务和 R 个 Reduce 任务将被分配,master将一个 Map 任务或 Reduce 任务分配给一个空闲的worker。 - 被分配了 Map 任务的
worker程序读取相关的输入数据片段,从输入的数据片段中解析出key/value pair,然后把key/value pair传递给用户自定义的 Map 函数,由 Map 函数生成并输出的中间key/value pair,并缓存在内存中。 - 缓存中的
key/value pair通过分区函数分成 R 个区域,之后周期性的写入到本地磁盘上。缓存的key/value pair在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置再传送给Reduce worker。 - 当
Reduce worker程序接收到master程序发来的数据存储位置信息后,使用 RPC 从Map worker所在主机的磁盘上读取这些缓存数据。当Reduce worker读取了所有的中间数据后,通过对 key 进行排序后使得具有相同 key 值的数据聚合在一起。由于许多不同的 key 值会映射到相同的 Reduce 任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。 Reduce worker程序遍历排序后的中间数据,对于每一个唯一的中间 key 值,Reduce worker程序将这个key值和它相关的中间 value 值的集合传递给用户自定义的 Reduce 函数。Reduce 函数的输出被追加到所属分区的输出文件。- 当所有的 Map 和 Reduce 任务都完成之后,
master唤醒用户程序。在这个时候,在用户程序里的对 MapReduce 调用才返回。
在成功完成任务之后,MapReduce 的输出存放在 R 个输出文件中(对应每个 Reduce 任务产生一个输出文件,文件名由用户指定)。一般情况下,用户不需要将这 R 个输出文件合并成一个文件,我们经常把这些文件作为另外一个 MapReduce 的输入,或者在另外一个可以处理多个分割文件的分布式应用中使用。
MapReduce 程序的实现
MapReduce 的核心就是实现其 Map 与 Reduce 的逻辑代码,显示楼主将就在上面描述的 Map 与 Reduce 的执行过程完成对 Map 与 Reduce 的实现。
实现 Map
1,下面的 doMap 函数管理一项 map 任务:它读取输入文件(inFile),为该文件的内容调用用户定义的 map 函数(mapF),然后将 mapF 的输出分区为 nReduce 中间文件。
2,每个 reduce 任务对应一个中间文件。文件名包括 map 任务编号和 reduce 任务编号。使用由reduceName 函数生成的文件名作为 reduce 任务的中间文件。在每个key mod nReduce 上调用 ihash()来选择对应的 reduce 任务。
3,mapF 是应用程序提供的 map 函数。第一个参数应该是输入文件名。第二个参数应该是整个输入文件的内容。 mapF()返回包含用于 reduce 的键/值对的切片。
4,下面程序中使用 json 格式将 mapF 处理好的数据写入文件中,为了数据处理方便,下面程序中处理好的每条数据都采用换行符进行分割。
func reduceName(jobName string, mapTask int, reduceTask int) string {
return "mrtmp." + jobName + "-" + strconv.Itoa(mapTask) + "-" + strconv.Itoa(reduceTask)
}
func doMap(
jobName string, // MapReduce 的任务名称
mapTask int, // 当前执行的 mapTask
inFile string, // 输入的的文件
nReduce int, // reduceTask 的数量
mapF func(filename string, contents string) []KeyValue, // 用户自定义的 map 函数
) {
f, err := os.Open(inFile)
if err != nil {
debug("open file err %v", err)
}
defer f.Close()
dat, err := ioutil.ReadAll(f)
if err != nil {
debug("open map file err %v", err)
}
res := mapF(inFile, string(dat))
for _, kv := range res {
hash := ihash(kv.Key)
r := hash % nReduce
// mrtmp.xxx-0-0
fd, err := os.OpenFile(reduceName(jobName, mapTask, r), os.O_RDWR|os.O_CREATE|os.O_APPEND, 0644)
if err != nil {
debug("open mrtmp.xxx file err %v", err)
continue
}
enc := json.NewEncoder(fd)
if err := enc.Encode(&kv); err != nil {
debug("encode json err %v", err)
continue
}
fd.Close()
}
}
func ihash(s string) int {
h := fnv.New32a()
h.Write([]byte(s))
return int(h.Sum32() & 0x7fffffff)
}
实现 Reduce
doReduce 管理一个 reduce 任务:它读取任务的中间文件,按 key 对中间文件中的数据对进行排序,为每个 key 调用用户定义的 reduceF 函数,并将 reduceF 的输出的写入磁盘。
func reduceName(jobName string, mapTask int, reduceTask int) string {
return "mrtmp." + jobName + "-" + strconv.Itoa(mapTask) + "-" + strconv.Itoa(reduceTask)
}
func doReduce(
jobName string, // MapReduce 的任务名称
reduceTask int, // 当前运行的 reduce 任务的任务号
outFile string, // 结果输出的文件路径
nMap int, // map 任务的个数
reduceF func(key string, values []string) string, // 用户的自定义 reduce 函数
) {
kvMap := make(map[string][]string)
for i := 0; i < nMap; i++ {
func() {
inFileName := reduceName(jobName, i, reduceTask)
inFile, err := os.Open(inFileName)
if err != nil {
panic("can't open file:" + inFileName)
}
defer inFile.Close()
// Read and Decoder the file
var kv KeyValue
for decoder := json.NewDecoder(inFile); decoder.Decode(&kv) != io.EOF; {
kvMap[kv.Key] = append(kvMap[kv.Key], kv.Value)
}
}()
}
var keys []string
// sort by key
for k := range kvMap {
keys = append(keys, k)
}
sort.Strings(keys)
// reduce
outfd, err := os.Create(outFile)
if err != nil {
panic("can't create file:" + outFile)
}
defer outfd.Close()
enc := json.NewEncoder(outfd)
for _, k := range keys {
reducedValue := reduceF(k, kvMap[k])
enc.Encode(KeyValue{Key: k, Value: reducedValue})
}
}
对 doMap 与 doReduce 的封装
下面的函数是对 doMap 与 doReduce 进行顺序调用,生成 MapReduce 任务的结果输出到结果文件中。
func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, mergeName(mr.jobName, i), len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}
使用 MapReduce 实现词频统计和倒排索引
在上面我们提到了 MapReduce 在实际应用中的例子,下面我们将对这两个例子做一下简单的实现。
实现词频统计
为了实现词频统计这一功能,我们使用 MapReduce 框架的思路就是实现自定义的 map 与 reduce 函数: 1,map:读取文档,将文档中的单词逐个提取出来,生成(单词,1)这样的键值对,然后把数据罗盘,写入到中间文件中。
2,reduce:读取中间文件,按照键值对进行排序,将 key 相同的数据聚合到一起,统计每个单词出现的次数,然后将结果写入到文件中落盘。
package main
import (
"6.824/src/mapreduce"
"fmt"
"os"
"strconv"
"strings"
"unicode"
)
func mapF(filename string, contents string) (res []mapreduce.KeyValue) {
// Your code here (Part II).
f := func(c rune) bool {
return !unicode.IsLetter(c)
}
words := strings.FieldsFunc(contents, f)
for _, w := range words {
kv := mapreduce.KeyValue{Key: w, Value: "1"}
res = append(res, kv)
}
return res
}
func reduceF(key string, values []string) string {
// Your code here (Part II).
sum := 0
for _, e := range values {
data, err := strconv.Atoi(e)
if err != nil {
fmt.Printf("Reduce err %s%v\n", key, err)
continue
}
sum += data
}
return strconv.Itoa(sum)
}
func main() {
if len(os.Args) < 4 {
fmt.Printf("%s: see usage comments in file\n", os.Args[0])
} else {
var mr *mapreduce.Master
mr = mapreduce.Sequential("wcseq", os.Args[3:], 3, mapF, reduceF)
mr.Wait()
}
}
实现倒排索引
同样,在理解了倒排索引的基础上设计我们自己的 map 与 reduce 方法, 1,map:将读取文档,将文档中的单词作为 key,单词所在的文档作为 value,写入到中间文件中。
2,reduce:读取中间文件,按照键值对进行排序,将 key 相同的数据聚合到一起,将单词出现的文件名拼接在一起,写入到结果文件中。
package main
import (
"bytes"
"os"
"strconv"
"strings"
"unicode"
)
import "fmt"
import "6.824/src/mapreduce"
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
words := strings.FieldsFunc(value, func(c rune) bool {
return !unicode.IsLetter(c)
})
for _, w := range words {
res = append(res, mapreduce.KeyValue{Key: w, Value: document})
}
return res
}
func reduceF(key string, values []string) string {
// Your code here (Part V).
sum := 0
var buffer bytes.Buffer
if key == "www" {
fmt.Println(values)
}
isExist := make(map[string]string)
for _, e := range values {
if _, ok := isExist[e]; !ok {
buffer.WriteString(e)
buffer.WriteString(",")
sum += 1
isExist[e] = e
}
}
iiRes := strconv.Itoa(sum) + " " + strings.TrimRight(buffer.String(), ",")
return iiRes
}
func main() {
if len(os.Args) < 4 {
fmt.Printf("%s: see usage comments in file\n", os.Args[0])
} else {
var mr *mapreduce.Master
mr = mapreduce.Sequential("iiseq", os.Args[3:], 3, mapF, reduceF)
mr.Wait()
}
}
小结
本文参考 Google 的论文,实现了一个单机版的 MapReduce 框架,并实现了两个简单的 MapReduce 实例,文中的代码可以在楼主的 GitHub 下载查看。
参考
MapReduce: Simplified Data Processing on Large Clusters
关注我们

