

导读:怎样刻画用户嵌入向量(user embedding)和物品嵌入向量(item embedding)之间的交互是在评分矩阵上面做协同滤波的关键问题。随着机器学习技术的发展,交互函数(interaction function)渐渐的由最初简单的矩阵内积,发展到现在复杂的结构化神经网络。本文介绍了第四范式研究组将自动化机器学习技术引入推荐系统中的一次尝试;特别地,将交互函数的设计建模成一个结构化神经网络问题,并使用神经网络搜索(neural architecture search)技术去设计数据依赖的交互函数。
01整体工作概述
交互函数(interaction funciton,IFC)是协同过滤(Collaboration Filtering,CF)的核心,它对性能非常敏感。下面简单地介绍一下我们在这方面取得的成果。
1. 我们将交互函数的设计形式化为一个自动化机器学习(Automated Machine Learning,AutoML)的问题。这是首次将自动化机器学习引入交互函数进行特征工程;
2. 构造了结构化的搜索空间,目的是使得机器学习算法能够快速自动化搜索,同时使得搜索的交互函数超过专家设计的交互函数带来的效果;
3. 提出了one-shot搜索算法,允许交互函数能够高效地进行随机梯度下降、点对点的进行AutoML搜索。
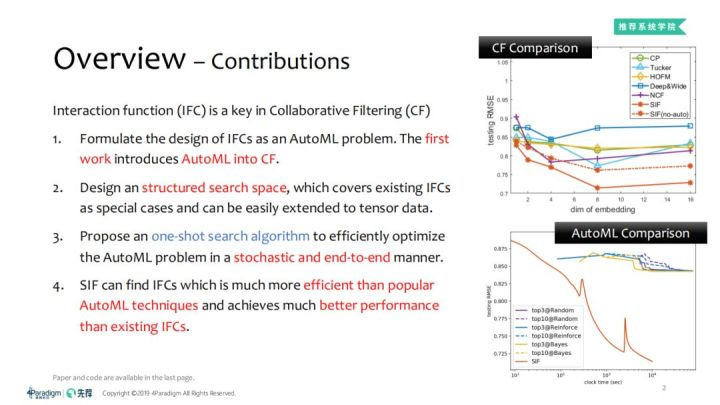
4. 不同算法能够搜索到的交互函数效果对比:目前我们形成的搜索交互函数算法(Searching Interaction Functions for Collaboration Filtering,SIF)存在两种形式:SIF、SIF(no-auto)。SIF、SIF(no-auto)比常见的协同过滤方法(如CP、Tucker、HOFM、Deep&Wide、NCF等方法)得到更好的效果:
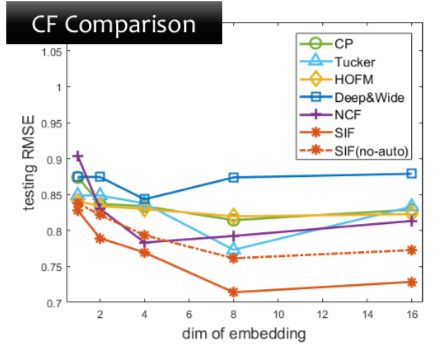
SIF、SIF(no-auto)比AutoML算法(如经典的Random算法、Reinforce算法、Bayes算法)等效果好,大致快2个阶:
相关的论文成果:1. Q. Yao, J. Xu, W. Tu, Z. Zhu. Efficient Neural Architecture Search via Proximal Iterations. AAAI Conference on Artificial Intelligence (AAAI). 2020
2. Q. Yao, X. Chen, J. Kwok, Y. Li, C.-J. Hsieh. Efficient Neural Interaction Function Search for Collaborative Filtering. WWW. 2020
3. Q. Yao, M. Wang, Y.-F. Li, W.-W. Tu, Q. Yang, Y. Yu. Taking Human out of Learning Applications: A Survey on Automated Machine Learning. Arvix. 2018
接下来重点介绍本文的主要内容,包括三个部分:协同过滤及AutoML的相关背景知识、设计的算法及实验效果。
02背景知识
为什么可以用机器学习的方法搜索交互函数实现协同过滤?进一步讲,AutoML目前用于什么场景,为什么要将AutoML引入协同过滤中?这就需要我们了解协同过滤及AutoML的相关背景知识。
1. 协同过滤
1.1 协同过滤的基本知识
抽丝剥茧,我们回到最原始的问题,因为面对的基本问题可以给我们指导方向。

- 数据:评分矩阵,许多位置的元素是未知的。
- 任务:预测未知位置用户可能给予的得分。
- 评价方式:用最简单的estimated ratings,看预测的值和正确的方差。
简单地说就是:已知的值是User已经交互过的 item,如何基于这些已知值填充矩阵剩下的未知值,也就是去预测User没有交互过的 item是我们需要解决的问题。对于实际环境还会有其他影响因素,所以:
- 在此将CF当做一个回归任务;
- 不考虑隐式反馈行为数据;
- 不考虑user/item等辅助信息。
1.2 协同过滤的低秩矩阵

让我们回到推荐系统开始爆发的元年,那一年有两个重要的工作广受关注,第一个是推荐系统应用层面的C++,另一个是数据统计分析。那么这两个工作做了什么事呢?有一个全面的观测矩阵,把这个矩阵拆成两个矩阵相乘,U就是一个矩阵,整体优化目标是拟合函数,后面有个正则相,OIC是已经观测到的打分,这是一个CF标准的模板, U可以看成用户的向量,V是物品的向量,在做预测的时候使用UV做了内积与推荐目标进行比较,从2008年开始,推荐系统有单独的会议,09年左右是推荐系统的爆发点。整体优化目标函数如下:
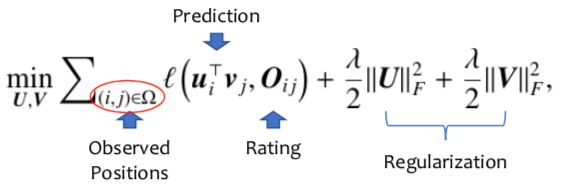
- 评分矩阵能够用低秩矩阵进行逼近;
- 矩阵U的每一行可以看作user embedding向量 ,矩阵V的每一列可以看作item embedding向量;
- 得分预测实际上是user embedding及item embedding的内积。
1.3 协同过滤的交互函数

简单看了推荐系统,那我们一起来看看交互函数是什么,简单而言,就是User向量和Items向量怎么进行交互,对于算法而言,就是向量扩大,两个向量怎么做积,然后使用损失函数在训练集上作评价,所以对于这种标准的low-rank,就是他的交互函数。所以,CF之所以称之为交互函数,是因为它可以表示User embedding与Item embedding之间是如何相互交互的。对于低秩目标:
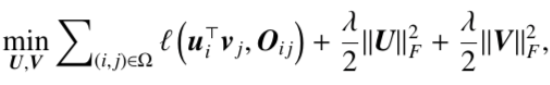
1. 生成User及Item的embedding向量;
2. 通过内积的形式生成两个embedding向量的预测得分;
3. 在训练数据集上基于损失函数评估预测。那么简单地说,低秩方法:就是采用内积作为交互函数。
1.4 协同过滤中更多的交互函数
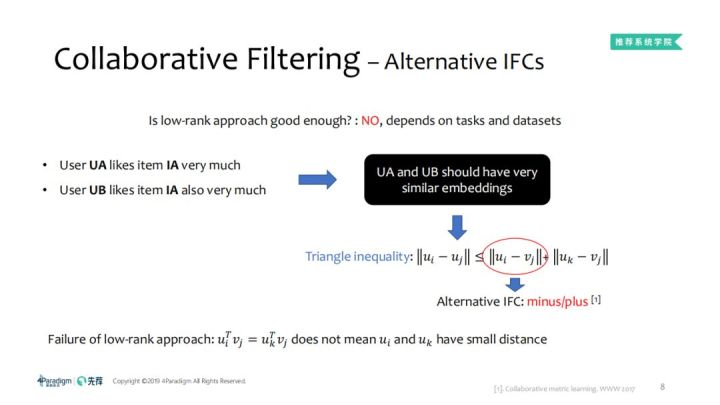
采用矩阵乘法的低秩方法是否足够好了?No,因为它依赖于任务及数据集的多样性。WWW2017上给出了一个简单的协同滤波函数,比如这个UA非常喜欢A物品,UB同样很喜欢A物品,那么UA和UB的相似度很可能是很高的,但是对于low-rank而言,因为uiTvj=ukTvj不意味着ui与uk之间存在有很小的距离,并不能保证两个用户也就是在距离上保持相似,但是对于三角函数而言,有这样的性质,可以保证喜欢相同物品的人,他们之间具有很高的相似性。所以在计算的相似度时,这两个可以做上界,我们把两个用户的相似用ui-vj的相似来表示,也就可以很好的拟合数据上的特征,强烈喜欢相似物品的人之间的相似度很高,这就是诞生的另一种交互函数,加法和减法。依据对数据不同的假设,可能low-rank的函数或者加法减法的函数,但仅仅是这样吗?其实不是的,正是数据和交互函数的多元化,在有各种不同的交互函数,差别还是很大的,没有一个交互函数在所有的数据上都有一个好的效果,没有绝对最好的交互函数,随着数据和任务变的越来越复杂,交互函数也变得越来越复杂,这也是协同过滤为什么由开始简单的加减法扩展到现在常见的深度学习模型,又会受卷积神经网络的启发,把卷积引入做ConvMF或ConvNCF。这就是对交互函数的简单描述和目前的概况。
1.5 协同过滤中的更多交互函数的例子
但是由于数据及任务的多样性,可以选择各种各样的交互函数:

表中H表示训练参数。对于验证集,SIF利用AutoML搜索一个合适的交互函数,其他的则是专家们设计的非常著名的交互函数。在不同的任务及数据集上具有一致性性能好的IFC我们称其为最佳的IFC,那么这样的IFC是否存在?No,因为它依赖于任务及数据集。
2. 自动化机器学习AutoML
研究交互函数,我们就需要纵观整个自动化机器学习的发展。接下来我们一起从学术角度回顾自动化机器学习,自动化机器学习在机器学习中摆在什么位置呢?
机器学习的核心问题是:如何提高学习效果?
2.1 机器学习的发展史
AutoML是一种通过进化的方式进而提高学习效果。它的发展史如下:
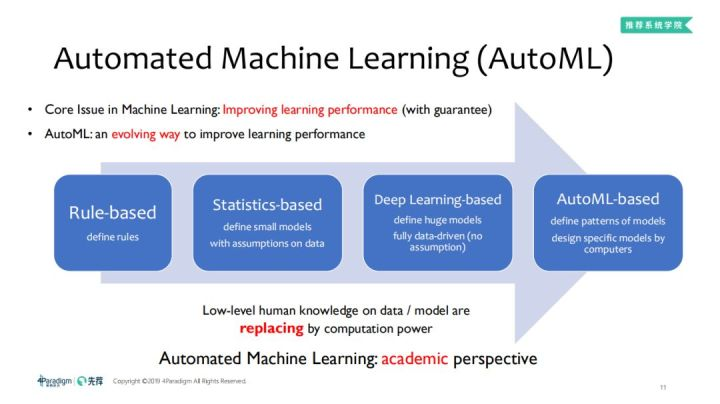
① 基于规则函数:因为简单、易于理解,因此它是一个很强的baseline(上世界70年代);
② 基于统计规则的方式:随着数据量及数据维度的增多,规则的编写变得不太容易,加上图像、视频、NLP的数据等是很难指定规则, 由于存在着上述问题,因此在数据的基础建立向量空间,基于一定的统计假设,如何建立一个超平面把回归问题或者分类问题做好,与此同时考虑模型的泛化性如何。(上世界80年代)
③ 基于深度学习的方式:更多的数据如何抽取特征,简单的模型不能够胜任,且也不能够实现从非结构化数据中抽取特征。此时采用数据驱动的方式定义一个大型模型,即深度学习,但是它的网络结构设计仍然需要很强的先验知识。
④ 基于AutoML的方式:通过计算探索网络结构如何设计,交互函数如何设计,进而定义模型,这是学术方面应该探索的事情。上述整个过程可以看出计算力不断地替代基于人类低水平知识的模型。
2.2 AutoML-神经网络结构搜索 ( Neural Architecture Search ,NAS )
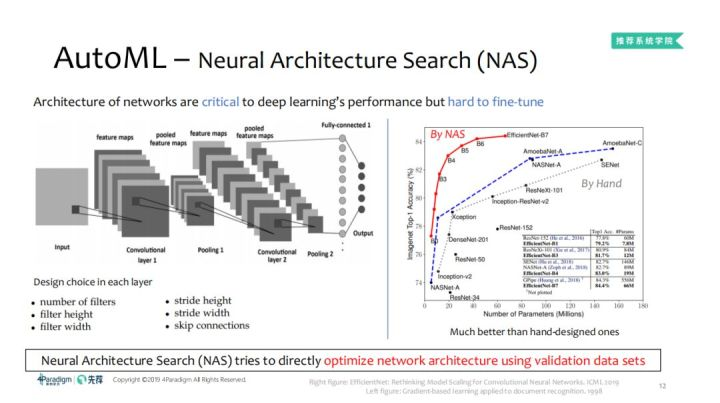
对于左图中的经典AlexNet网络,每一层的设计选择包括卷积核的数量、宽度、高度;卷积和移动步长的宽度、高度;是否需要跳跃连接等,这些因素对神经网络的性能有着很大影响。通过NAS与专家设计的网络准确性比较,效果如右图,可以看出,专家设计的各种网络正在持续不断地改进网络性能。在相同参数量/计算量下,准确性能达到当时的最好水平,超越了Inception,DenseNet,ResNet,SENet等一系列优秀网络。相比于优秀的SENet,NAS参数量在不断地减少,准确性也在不断地提高。事实上,人无法探索设计模型的所有空间,但是探索设计的模型空间可以更好地理解机器学习的极限在哪里,对于模型的理解偏差在哪里,因此NAS更多的作用就是在验证集上搜索网络空间。而且可以看出,手工设计的网络与NAS搜索的网络空间达到的效果目前存在一个较大的差距。下面来看一下NAS的发展历史:
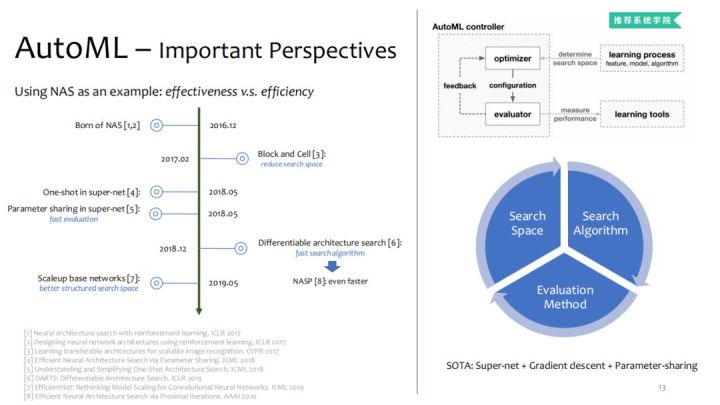
NAS最初是谷歌及MIT分别开发的。上面时间节点主要是依据论文发表的时间节点。
[1] Neural architecture search with reinforcement learning. ICLR 2017
[2] Designing neural network architectures using reinforcement learning. ICLR 2017
[3] Learning transferable architectures for scalable image recognition. CVPR 2017
[4] Efficient Neural Architecture Search via Parameter Sharing. ICML 2018
5] Understanding and Simplifying One-Shot Architecture Search. ICML 2018
[6] DARTS: Differentiable Architecture Search. ICLR 2019
[7] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ICML 2019
[8] Efficient Neural Architecture Search via Proximal Iterations. AAAI 2020
NAS重要的三要素是:搜索空间、搜索算法、评价方法。
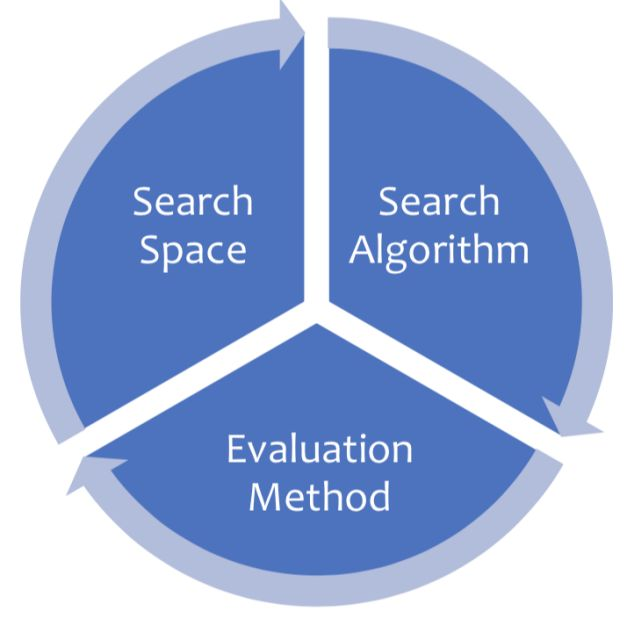
现在SOTA中指的搜索空间对应的是一个“超级网络”;搜索算法是基于“梯度下降”;衡量指标指的是“参数共享”。上述三要素在AutoML中对应关系如下:AutoML设计controller,里边包含优化器及评价器。优化器在搜索空间生成更好的候选空间,利用评价器来衡量候选空间的效果,这样反复迭代直至达到结束条件的过程就构成了一个AutoML。
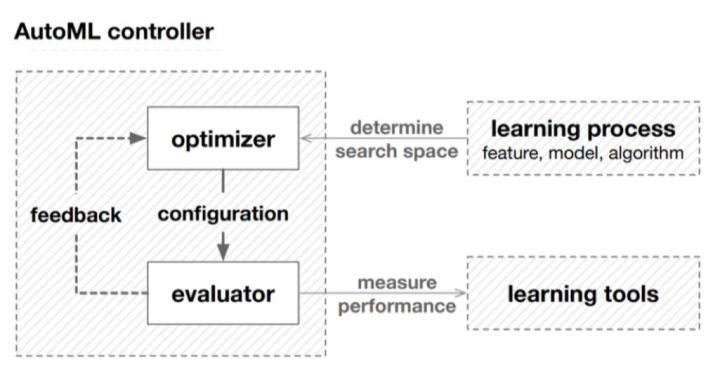
NAS最初是缩小搜索空间,以此缩短搜索时间,提高搜索效率。下一步是改善评价方法,由标准的stand-alone 转变成参数共享。这样就在搜索空间、搜索算法、评价方法这个闭环中完成了NAS三个侧面的一次循环。接下来就是让NAS变成一个更多元、更快、更有应用前景的方法。上述三个方面的核心指标是效率及效果。下面介绍一下我们在这个方面的工作,主要是在搜索效率方面做了改进。
2.3 NAS – Efficient NAS via Proximal Iterations (NASP)

在super-net进行搜索:对于单个cell而言,有两个输入节点,1个输出节点,中间就涉及到网络如何设计,0、1 表示中间节点,边上代表选择,如3*3卷积,7*7卷积等。对于Edge representation,这个方面做得重点改进就是:利用稀疏性限制,这样就限制了operation的离散选择,这样极大改善效率及效果问题。
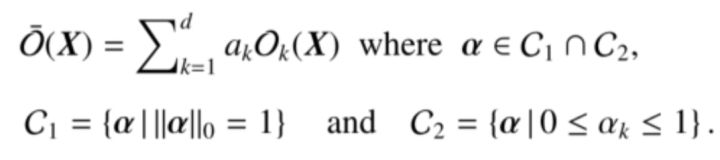
优化目标函数(双层优化):
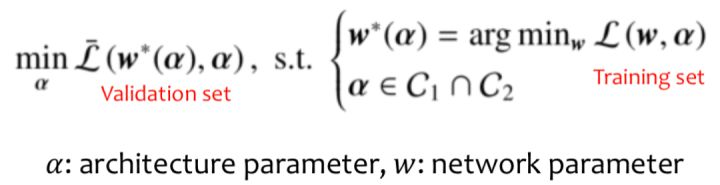
NASP算法:
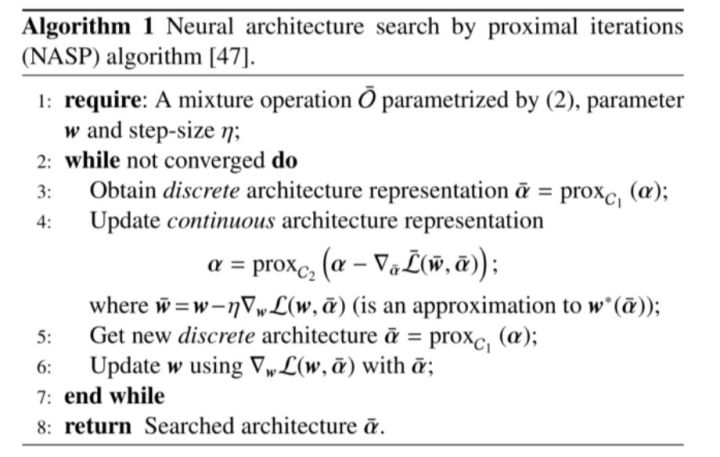
NASP算法逻辑如上图,对于向量层面可以理解为简单的线性代数运算,同时元素映射可以理解为非线性转换,这使得算法可以训练端对端和随机搜索,相比以往我们引入通过限制运算的离散选择,可以极大的改善效率问题同时极大程度上提高效果,有兴趣的朋友可以看看我们的论文。该算法有三大要素:① 搜索空间:Super-net② 搜索算法:(近邻梯度下降)Proximal Gradient descent③ 评价方法:Parameter-sharing总结而言,NASP算法是临近迭代算子法,最后是在共享参数的情况下进行迭代,所以整体可以比DARTS达到快十多倍的效果。
03如何提出SIF方法?

是否存在绝对最优的IFC?答案是否定的。因为协同过滤中,任务与数据集具有多样性。真正想要回答这个问题,就要知道why以及我们为什么要采用这种方式设计。基于给定的任务在数据的基础上采用AutoML的方式进行搜索IFC。特别地,要考虑AutoML中三大要素:搜索空间、搜索算法,评价方法。那么这三大要素需要精心设计才能比已经存在的IFC具有更好的效率与更高的性能。接下来我们介绍如何进行设计。
1. 搜索空间

如图左侧是我们的优化目标,写成稍抽象点的形式,F是交互函数,使用了f(ui, vj)替代,w是权重。这个过程,参数在验证集上的验证效果,下一层是训练集上拿到一个嵌入,这是一个比较标准的协同滤波背景下的自动化机器学习。那么怎样设计一个搜索空间呢,如果太大会导致很高很高的搜索计算代价,例如在一百维空间要比一维空间搜索的代价高的多,且随着搜索空间的增大搜索代价成指数级的放大;搜索空间太大不可以,同样的,太小也不可以,太小就不需要自动化机器学习,而且效果要比已存在的交互函数更差。
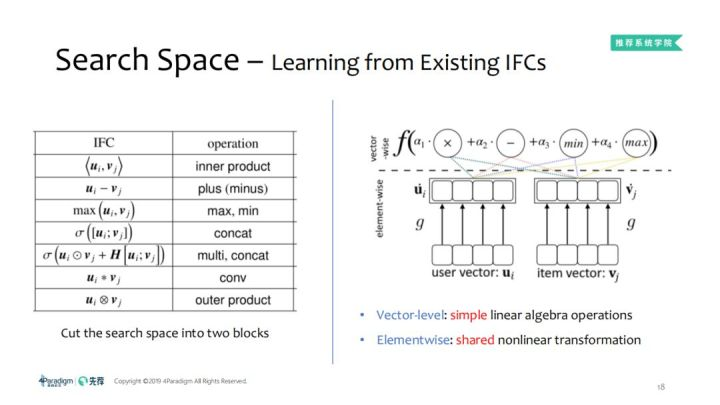
那么怎样设计一个合理的AutoML呢,学习已有算法的长处并弥补他们的短处。左边的就是交互函数,会有加减操作以及简单的向量级别的相关操作,如向量的加减法、串并联、卷积等操作,基于这样的观察,就有了右图,可以看出交互函数有两类元素的操作:vector-level及elementwise:
- vector-level:比较简单的线性代数计算;
- elementwise:所有的User Embedding共享一个非线性转换函数,所有的Item Embedding共享一个非线性转换函数。
2. 搜索算法及评价方法-利用NASP
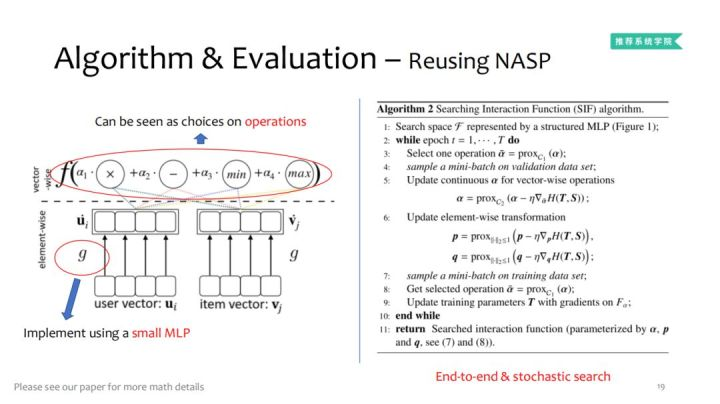
简单来说,上层通过利用加法、减法、max、min等operation(α1、α2、α3、α4为operation的权重)。下层通过一个简单的MLP去分离,并且User Embedding、Item Embedding共享的。特别地,这里的MLP可以用来近似任意非线性函数。采用点对点及随机搜索办法:

这就是整体SIF做什么以及怎么优化复用的实现过程。
04实验效果
采用的数据集:
- MovieLens-100K、MovieLens-1M是矩阵数据集;
- YouTube是三维的tensor数据集。
1. 不同embedding维度,测试集上的RMSE
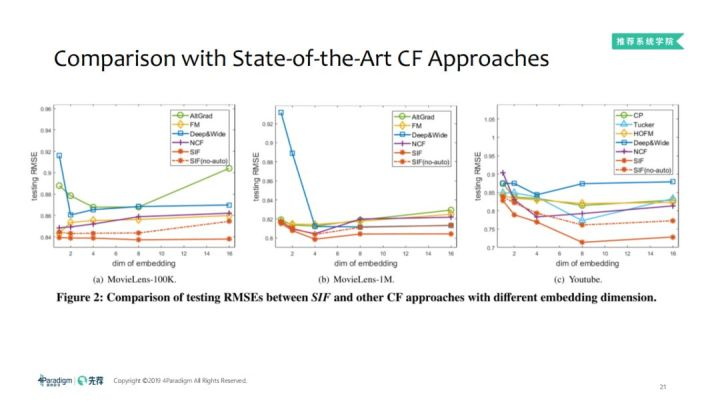
① 通过不同的embedding维度,对比SIF及其他的CF方法测试集上的RMSE,可以看到SIF、SIF(no-auto)表现出了很好的优势。② 在矩阵数据集上效果提升不大,但是在tensor数据集上效果提升明显。
2. 相同embedding维度,测试集上的收敛性
如果设计的交互函数能够更好地拟合我们所需要的函数,那么它的收敛速度将会更快。当Embedding维度为8时,比较SIF及其他的CF方法的收敛性。
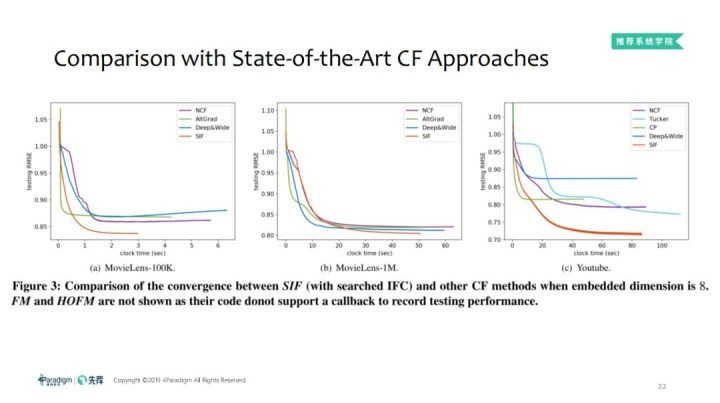
从图中可以看到SIF比大部分的交互函数更快的收敛,说明更有可能去拟合数据。
3. 相同embedding维度,与自动化学习算法比较搜索效果
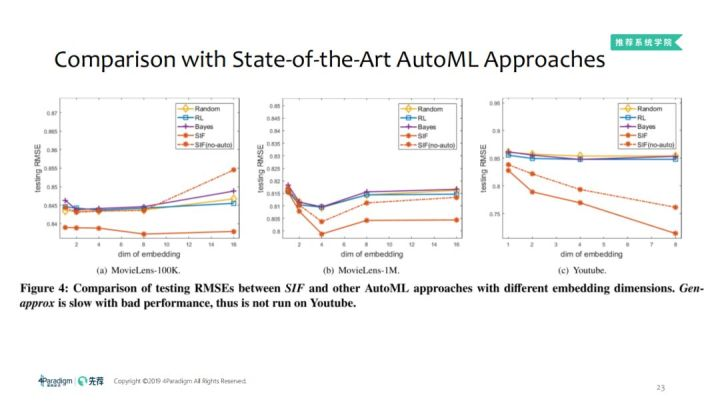
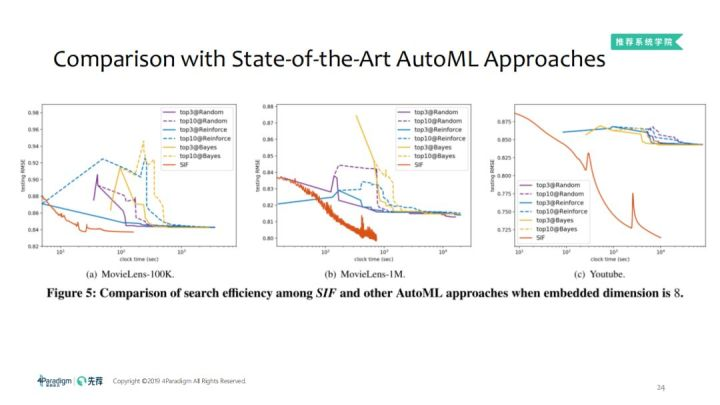
和AutoML算法比较,SIF可以比其他AutoML获得更好的结果,因为连续函数是一个小的阶段,要找到合适的超参数是比较难的,所以SIF比其他的效果都要好。
4. Case study
4.1 MovieLens-100K数据集上的交互函数
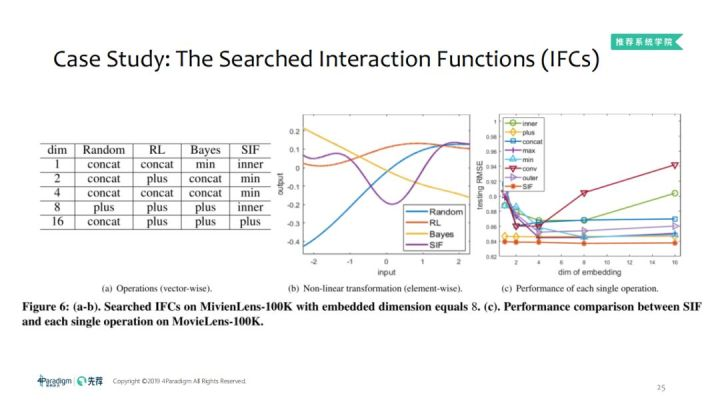
左图中可以看出,在相同的数据集上不同的自动化机器学习搜索到的operation是不一样的。
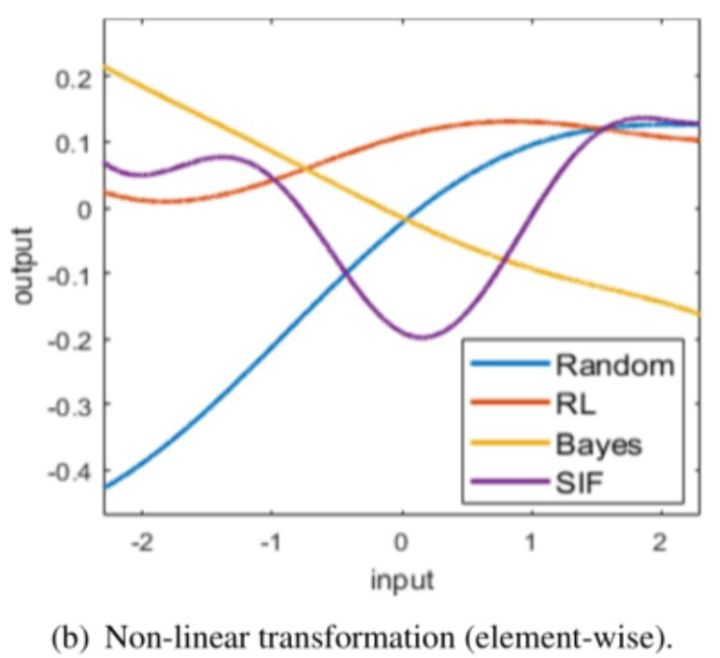
对应的Embedding维度为8SIF搜索到的非线性变换比RL、Random、Bayes更加复杂,这也解释了为什么SIF会取得更好的效果。
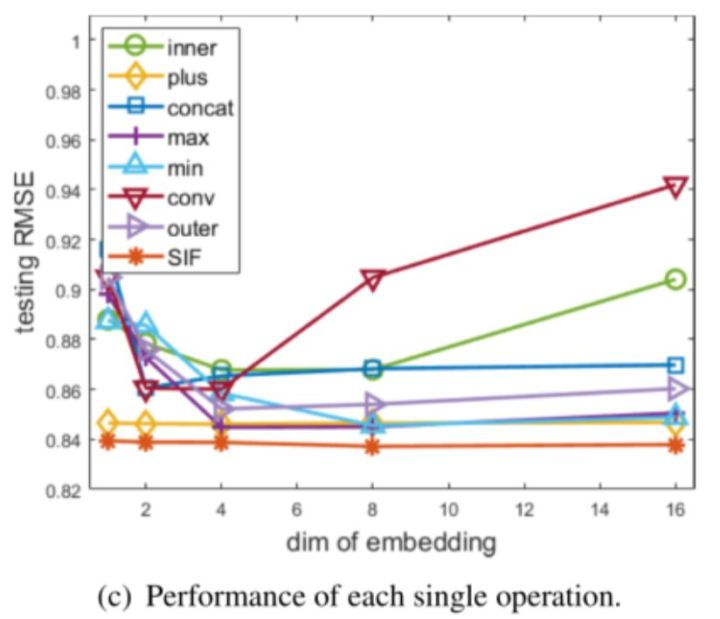
SIF与所有单个操作的性能比较,可以看到,SIF的效果比任何一个单个的operation都要好。
4.2 MovieLens-100K数据集上各种操作的收敛性
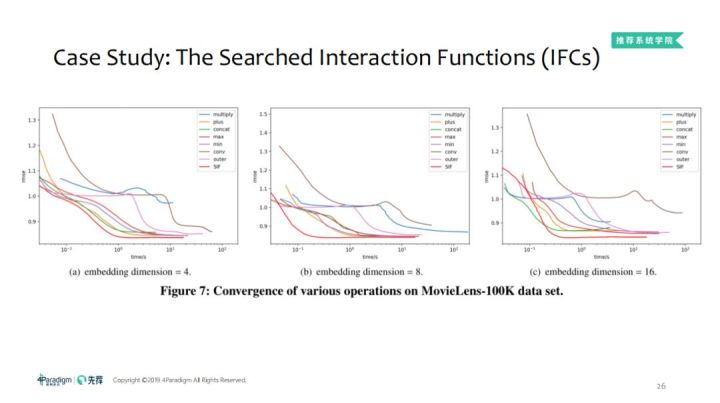
看过整体效果,接下来我们看下细节刻画,首先,搜索空间除了MLP可以放过来,我们也可以在标准的MLP嵌入SIF,图中可以看出,在相对宽泛的数据空间,利用空间还是相对较低的,SIF会明显的快很多。如果增加更多的算法运算,效果会好,MLP越多,100K的数据集上设计了不同的嵌入维度以及激活函数的类型,隐藏层到10左右效果就差不多了,不同的算法区别不大,因为只是拟合一个比较简单的非线性函数,不需要过高的复杂度。
5. Ablation study
5.1 Ablation study:不同的搜索空间
在宽泛的搜索空间,搜索效率会比较低效,因为搜索空间比较大。当Embedding维度为8时,不同搜索空间比较:
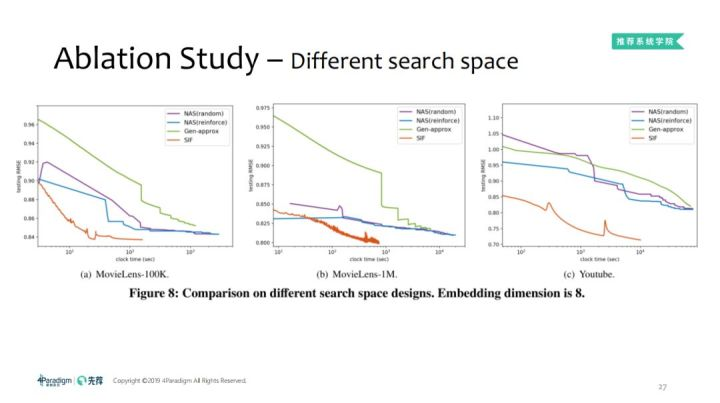
5.2 Ablation study:更多的operation
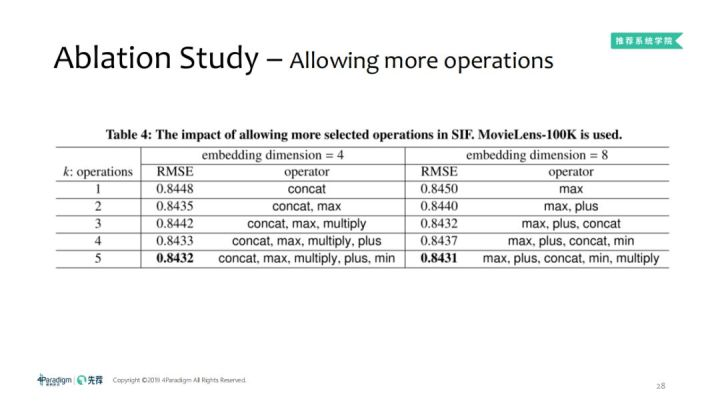
从上表可得出,operation的数量越多,效果更好。5.3 Ablation study:逐元素转换

使用简单的MLP进行元素转换,使用不同的激活函数(行)和隐藏单元(列)的数量。在MovieLens-100K数据集上,对于测试集上的RMSE结果如下表:当隐藏单元数量为10的时候,对于不同的激活函数取得的效果基本相差不大,我们需要的是简单的非线性函数,而不是复杂度特别高的函数。
5.4 Ablation study:更加复杂的预测器(MLP)

将线性的predictor换成非线性的MLP后,fine-tune的难度会变得更大,复杂度更高,对于在MovieLens-100K数据集上运用MLP替代线性预测器的效果如下,可以看到在该数据集上linear的效果比较好。以上就是我们的工作展示,把神经网络放到推荐系统中,基于神经网络构建自动化机器学习的搜索工作。今天的分享就到这里,谢谢大家。
