

如果问到 Java 程序员日常用到最多的数据结构是什么?我想不外乎这 3 个: ArrayList,HashMap 和 HashSet。这次我们就来分析其中的 ArrayList 的源码。
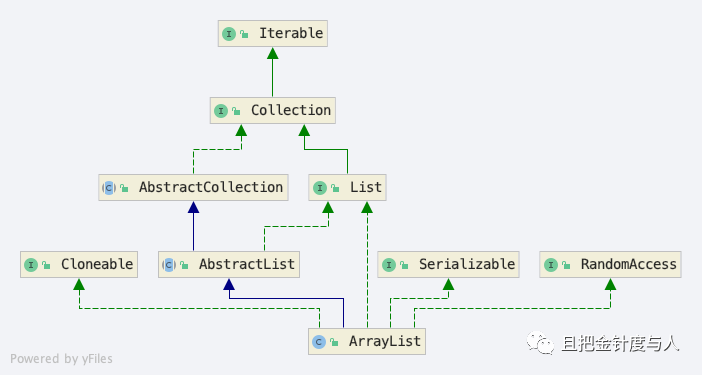
List 接口
ArrayList 主要实现了 List 接口,并继承了 AbstractList 抽象类,我们先看一下 List 接口。List 接口即成了我们之前提到的 Collection 接口,同时加入了自己特有的属性主要有以下这些:
List是有序的,开发人员可以通过序号 (index) 来访问List内的元素。- 允许「重复」元素,即
e1.equals(e2)的结果为true。 - 允许插入
null值
在继承 Collection 方法的基础上,List 提供了数个基于 index 访问元素,以及批量加入,移除元素的 API。同时 List 提供了一个自己特殊的 Iterator 实现,ListIterator 。ListIterator 与 Iterator 的区别在于 ListIterator 是支持双向移动的,不仅可以向后移动,也可以向前移动。
AbstractList 抽象类
AbstractList 继承了 AbstractCollection,也同样是为 List 数据结构的实现提供了一个模版。如果要实现一个 unmodifiable list ,只需要实现 get(int) 和 List.size() 这两个方法,而如果要实现一个 modifiable list 则需要实现 set(int),当这个 list 是可变长的话则还需要重写 add(int, Object) 和 remove(int) 这两个方法。此外开发人员不需要自己实现 Iterator,在 AbstractList 中自己实现了 Iterator 和 ListIterator 接口。
从 AbstractList 的实现中可以看到,它的 Iterator 和 ListIterator 的实现比较简单,通过一个当前的 index 来计数遍历的次数,而把如何通过 index 获取元素的实现留给了开发者。
ArrayList
终于来到了这次分析的主角,ArrayList 。在开始阅读之前,我们不妨先看看这个源码文件的注释。在阅读源码时,注释往往是我们最好的朋友,能够帮助我们理清系统的架构和设计思想,同时也会提纲挈领的描述功能上的一些特色以及使用过程中需要注意的事项。而且比较幸运的是 JDK 源码的注释非常规整,在每个源码开头都会有一段详细的描述,来阐述这个类的一些特点,所以大家不妨在开始阅读源码前先仔细的阅读一下注释。
通过阅读开头的注释,我们可以获得以下的一些信息:
ArrayList是通过数组来实现List的所有接口。size,isEmpty,get,set,iterator,listIterator这些操作的时间复杂度都是常量。add方法经过经过摊销后,时间复杂度也接近常量,而其他操作的时间复杂度接近 O(n)。ArrayList不是一个线程安全的类,如果多个线程对其进行 Structural Modification 会抛出异常。- 通过
iterator或listIterator方法获得迭代器后,如果对ArrayList进行 Structural Modification 也会导致抛出异常。
通过注释了解了这些特性后,我们就可以正式开始 ArrayList 源码的阅读了。
我们先会看到如下的几个变量:
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
第一个成员变量 DEFAULT_CAPACITY 是默认数组的大小,即创建一个新的 ArrayList 时对应数组的默认大小。
我们先看第三个变量 DEFAULTCAPACITY_EMPTY_ELEMENTDATA ,这是一个空的数组。具体的作用就是当我们使用无参数构造函数创建 ArrayList 时,新创建的 ArrayList 所对应的数组都是它,可以节约内存的使用。代码参考如下:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
紧接着的 elementData 就是 ArrayList 实际存放数据元素的地方,和之前注释中的信息相符。而 size 变量就 ArrayList 中元素长度,参考代码:
/**
* Returns the number of elements in this list.
*
* @return the number of elements in this list
*/
public int size() {
return size;
}
/**
* Returns {@code true} if this list contains no elements.
*
* @return {@code true} if this list contains no elements
*/
public boolean isEmpty() {
return size == 0;
}
比较有意思的是 EMPTY_ELEMENTDATA 这个变量,它的作用和之前的 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 类似也是为了节约内存,让空的 ArrayList 的数组指向同一个对象,但是为什么区分两个不同的数组呢?让我们来看一下源码中是怎么使用它的。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
上述代码中可以看到,当我们使用 int 类型构造函数时,该参数就是 elementData 数组的初始大小。当这个参数为 0 时,elementData 的数组就会指向 EMPTY_ELEMENTDATA ,之后的差异体现在 add 函数中,我们继续看以下的代码:
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
add 函数应该是 ArrayList 中被调用频率最高的函数,我们着重来分析一下。外层的 add 函数很简单,第一行自增了 modCount 来防止多线程对数据的修改,然后就直接调用内部私有的 add 方法来执行具体操作。
执行具体操作的 add 函数也很简单,首先判断当前的 size 是否与存放数据的数组大小一致,如果 elementData 还存在空间,则直接讲需要添加的元素放入数组,同时增加 size 变量的值,否则的话则会先对数组扩容,即调用 grow 方法,所以 grow 才是 add 方法的核心,让我们继续往下看一下 grow 的实现。
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
grow 更加简单,参数是数组扩容需要满足最小长度,具体数组扩容的逻辑在 newCapacity 方法中。这个方法看上很熟悉,和我们之前介绍 AbstractCollection 中转换数组时对数组扩容的代码类似。例如通过位移操作来优化除法,需要判断是否数字溢出等,都比较好理解。可以获得的信息是,在扩容时,增长的速率是按照当前数组长度的一半扩容,假如当前 elementData 长度为 20 时,扩容后的的长度就为 20 + 20/2 = 30 。第二个信息就是,如果当前数组指向的是 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时会按照默认数组大小即 10 和 minCapacity 的最大值来初始化新的数组。可以看到,如果使用 0 显示地初始化 ArrayList 时,相关数组的增长速率会大不相同。
其他类似 set,get 方法实现都比较非常简单易懂,就不在这里赘述了,下面会详细说一个我个人觉得有点意思的方法:reomveIf ,这个方法是由 JDK1.8 开始引入的,接受参数一个 Predicatie 对象,即一个 lambda 表达式,对于 ArrayList 中的每个元素都会作为参数调用这个 lambda 表达式,并移除返回结果为 true 的对象,我们先来看一下它的具体实现:
public boolean removeIf(Predicate<? super E> filter) {
return removeIf(filter, 0, size);
}
boolean removeIf(Predicate<? super E> filter, int i, final int end) {
Objects.requireNonNull(filter);
int expectedModCount = modCount;
final Object[] es = elementData;
// Optimize for initial run of survivors
for (; i < end && !filter.test(elementAt(es, i)); i++)
;
// Tolerate predicates that reentrantly access the collection for
// read (but writers still get CME), so traverse once to find
// elements to delete, a second pass to physically expunge.
if (i < end) {
final int beg = i;
final long[] deathRow = nBits(end - beg);
deathRow[0] = 1L; // set bit 0
for (i = beg + 1; i < end; i++)
if (filter.test(elementAt(es, i)))
setBit(deathRow, i - beg);
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
modCount++;
int w = beg;
for (i = beg; i < end; i++)
if (isClear(deathRow, i - beg))
es[w++] = es[i];
shiftTailOverGap(es, w, end);
return true;
} else {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return false;
}
}
我们先不纠结一些细节的方法,梳理一下大体的逻辑。reomveIf 会使用数组 deathRow 来存放匹配成功的元素的偏移量,然后再次遍历 deathRow 数组时将 elementData 的元素收缩起来。大体明白了算法后,我们再依次深入每部分的逻辑。
for (; i < end && !filter.test(elementAt(es, i)); i++) 会将 i 设置为第一个满足匹配条件元素的序号,然后开始后续循环。后续循环中需要理解的第一个方法是 nBits 方法,我们看一下具体代码:
private static long[] nBits(int n) {
return new long[((n - 1) >> 6) + 1];
}
这个方法作用是初始化一个数组,数组长度是按照 (n - 1) >> 6 + 1 的逻辑来得到的。>> 是算术位移,简单的来说就是将数字除以 2 的 n 次方,>> 6 就是除以 2 的 6 次方,即除以 64。因此 nBits 方法会以 64 为单位来收缩,并返回收缩后长度的数组。
接着后续循环中,如果元素匹配成功,会调用 setBit 方法来设置标记位,下面是 setBit 方法的代码:
private static void setBit(long[] bits, int i) {
bits[i >> 6] |= 1L << i;
}
代码只有一行,但是涉及到 3 个位操作,我们一个个来看。第一个还是我们熟悉的 >> 6 操作,即将匹配到的元素的序号除以 64,对应到 deathRow 的序号。1L << i 是左算术位移,与右算术位移类似,但不同的是乘以 2 的 n 次方,这里就是 1 乘以 2 的 i 次方,即结果一定是一个 2 的 i 次方的数字。在这里先要提到的是 2 的 n 次方的数字二进制的特点是最为高 1,而其他位都是 0。例如以下的对照表:
2 -> 10
4 -> 100
8 -> 1000
16 -> 10000
| 运算符非常简单,就是「或」操作。所以 setBit 方法的作用就是将 i 转换为 2 的 i 次方数字后,进行合并,而合并的结果其实是将第 i 位置为 1。简而言之 deathRow 是一个「位图」(Bitmap) 的数据结构。
设置完 deathRow 的值后,会开始第二轮的循环。在这轮循环中核心方法是 isClear ,我们看下代码:
private static boolean isClear(long[] bits, int i) {
return (bits[i >> 6] & (1L << i)) == 0;
}
经过 setBit 方法的解释,相信你应该能理解这个方法的用意,isClear 会按照输入去看数组中元素的第 i 位是否被置为 1,如果 没有 被置为 1 ,则返回 true 。
之后收缩元素的代码比较简单,就不深入讲解了。从上面的代码来看可以学习到不少位移操作和 Bitmap 的使用技巧。
这次对于 ArrayList 分析就到这了,如果你还对其他方法有疑问可以在公众号上 @ 我,我会仔细的回复你,下次的主题是 LinkedList ,敬请期待吧!
欢迎关注我的微信号「且把金针度与人」,获取更多高质量文章

