

2月初,AAAI 2020在美国纽约拉开了帷幕。本届大会百度共有28篇论文被收录。本文将对其中的机器翻译领域入选论文《Synchronous Speech Recognition and Speech-to-Text Translation with Interactive Decoding》进行解读。

一、研究背景
语音翻译技术是指利用计算机实现从一种语言的语音到另外一种语言的语音或文本的自动翻译过程。该技术可以广泛应用于会议演讲、商业会谈、跨境客服、出国旅游等各个领域和场景,具有重要的研究价值和广阔的应用前景。
近年来,随着人工智能技术在语音、翻译等相关领域的蓬勃发展,语音翻译技术逐渐成为学术界和企业界竞相研究的热点。当前的语音翻译系统通常由语音识别、机器翻译和语音合成等多个模块串联组成,方法简单,但面临着噪声容错、断句标点、时间延迟等一系列技术难题。
端到端的语音翻译模型在理论上可以缓解级联系统的缺陷,它通过直接建立源语言语音到目标语言文本的映射关系,一步实现跨模态跨语言的翻译,一旦技术成熟,理论上可以让语音翻译更准更快,极大地提升模型的性能。论文作者发现语音识别和语音翻译两个任务是相辅相成的。
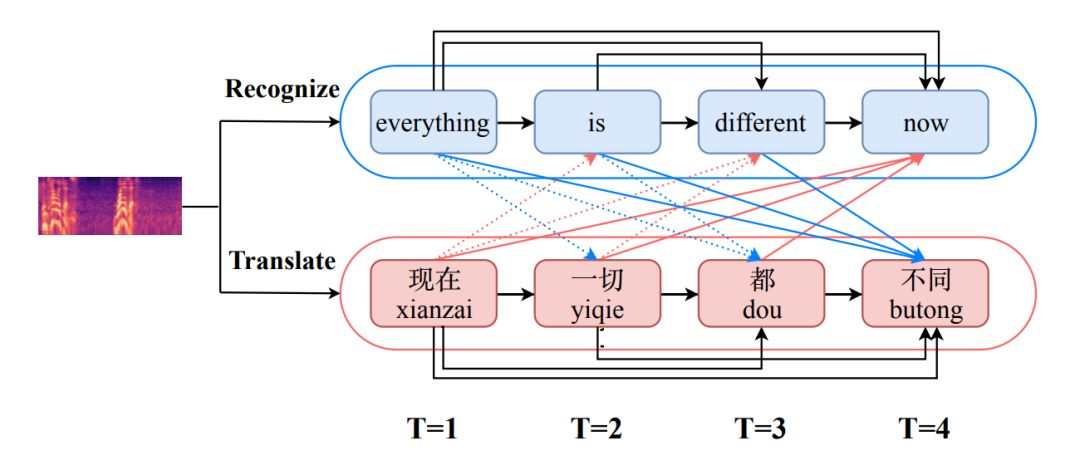
图1如图1所示,语音识别和语音翻译交互示例相比于直接将原始语音作为输入,如果能够动态获取到识别出的文本信息,语音翻译将变得更加容易;而翻译出的结果也有助于同音词识别的消歧,使识别结果更加准确。
因此,论文作者们希望设计一种交互式的模型,让语音识别与语音翻译两个任务可以动态交互学习,实现知识的共享和传递。
二、技术方案
针对上述问题,作者们在论文中提出了一种基于交互式解码的同步语音识别与语音翻译模型。
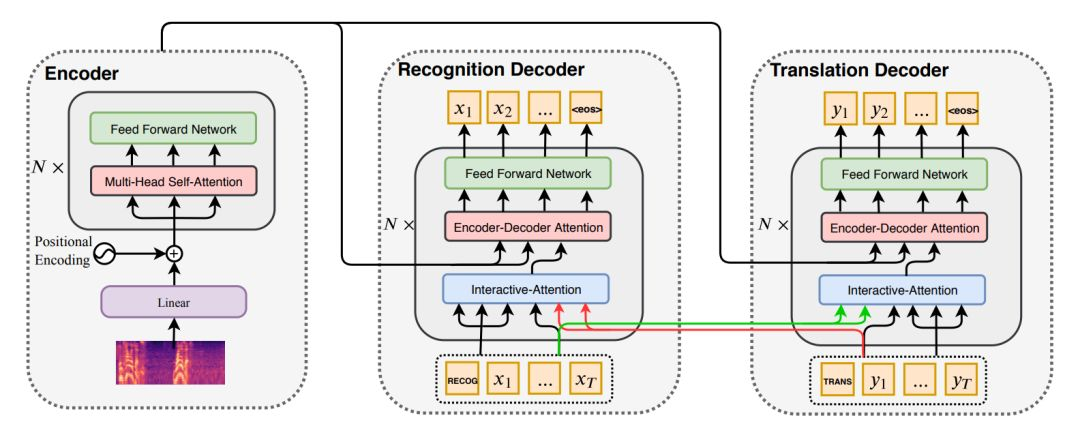
图2 基于交互式解码的同步语音识别与语音翻译
如图2所示,论文作者使用基于自注意力机制的Transformer模型作为主框架,语音识别任务和语音翻译解码任务共享同一个编码器,在解码器中加入一个交互注意力机制层,实现两个任务的知识交互和传递。
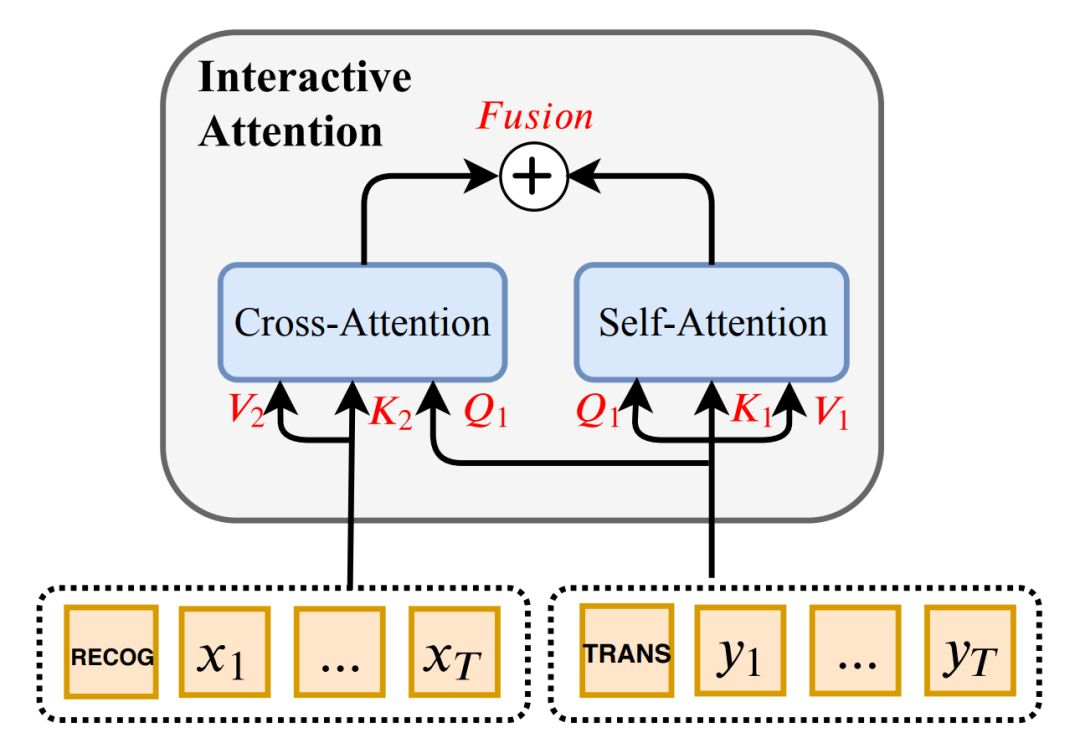
图3 交互注意力机制层
如图3所示,交互注意力机制层包含一个自注意力模块和一个跨任务注意力模块。其中前者用于提取当前任务输出端的特征表示,后者用于提取另一个任务输出端的特征表示,两者通过一个线性插值函数融合得到包含两个任务信息的特征表示。
在训练阶段,两个任务同时优化;在解码阶段,两个任务同步进行。如此,在预测下一个词的过程中既可以用到当前任务的已生成的词语,也可以利用到另一个任务上已生成的词语。为了进一步提升语音翻译的性能,论文作者采用了一种wait-k的方法,使得语音翻译任务相比语音识别任务延迟k个词语进行,以获得更多更可靠的文本信息作为辅助。
三、实验结果
实验结果相关内容,欢迎前往“百度NLP”公众号,查看论文解读全文,百度NLP将通过公众号文章的形式就AAAI 2020入选的其余三篇NLP领域论文进行详细解读,敬请关注!
