

在分类模型评判的指标中,常见的方法有如下三种:
- 混淆矩阵(也称误差矩阵,Confusion Matrix)
- ROC曲线
- AUC值
在回归模型评价指标中,常用的方法有如下几种:
- MSE
- RMSE
- MAE
- R2
混淆矩阵(Confusion matrix)
在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型好坏的形象化展示工具。
混淆矩阵的定义
混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表实际的类别,每一行代表的是预测值(反之亦然)。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
大白话来讲,混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。就是对机器学习算法的运行结果进行评价,效果如何,精确度怎么样而已。
混淆矩阵是评判模型结果的指标,属于模型评估的一部分。此外,混淆矩阵多用于判断分类器(Classifier)的优劣,适用于分类型的数据模型,如分类树(Classification Tree)、逻辑回归(Logistic Regression)、线性判别分析(Linear Discriminant Analysis)等方法。
混淆矩阵的指标
一级指标
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是positive,哪些是negative。
因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
- True Positive(真正, TP):真实值是positive,模型认为是positive的数量
- False Negative(假负 , FN):真实值是positive,模型认为是negative的数量 → 误报 (Type I error)
- False Positive(假正 , FP):真实值是negative,模型认为是positive的数量 → 漏报 (Type II error)
- True Negative(真负 , TN):真实值是negative,模型认为是negative的数量
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
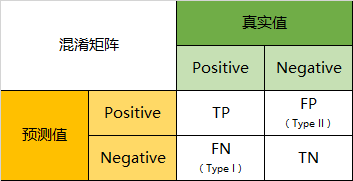
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。
所以模型预测错误就有两种情况:假负和假正。对于不同的场景,我们对模型的要求也不同。
- 对于诊断疾病的模型(假设疾病患者为正类,健康患者为负类),**假负(把病人诊断为健康,会错过最佳治疗时间)**比假正情况更严重,所以该模型应该更倾向于找出所有为positive的样本(患病的就诊者);
- 对于垃圾邮件检测模型(假设垃圾邮件为正类,正常邮件为负类),**假正(把正常邮件检测为垃圾邮件,会错过重要邮件)**比假负情况更严重,所以该模型应该更倾向于选出所有为negative的样本(正常邮件)。
针对这两种场景,就需要两个指标,查准率和查全率。
疾病检测模型需要的是高召回率,即尽量不漏过任何一个正样本;垃圾邮件检测模型需要的是高精确率,即尽量不误判任何一个负样本。
二级指标
但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的):
-
准确率(Accuracy)—— 针对整个模型
-
精确率(Precision)
-
灵敏度(Sensitivity):就是召回率(Recall)
-
特异度(Specificity)
我用表格的方式将这四种指标的定义、计算、理解进行了汇总。
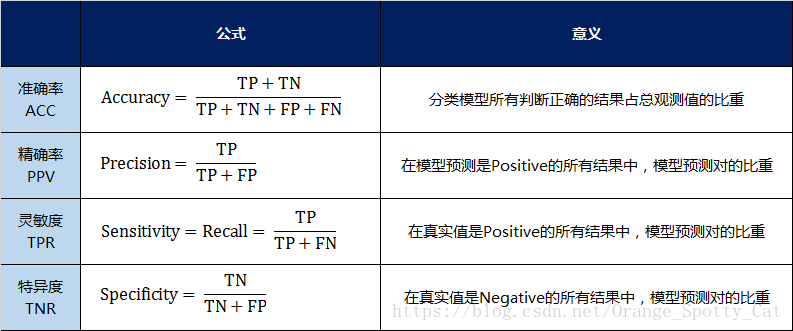
通过上面的四个二级指标,可以将混淆矩阵中数量的结果转化为0-1之间的比率。便于进行标准化的衡量。
在信息检索领域,精确率和召回率又被称为查准率和查全率,
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc 也有 99% 以上,没有意义。
在这四个指标的基础上在进行拓展,会产生另外一个三级指标。
三级指标
这个指标叫做F1 Score。他的计算公式是:
其中,P代表Precision,R代表Recall。
一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。两者的关系可以用一个P-R图来展示(图来自周志华的机器学习):
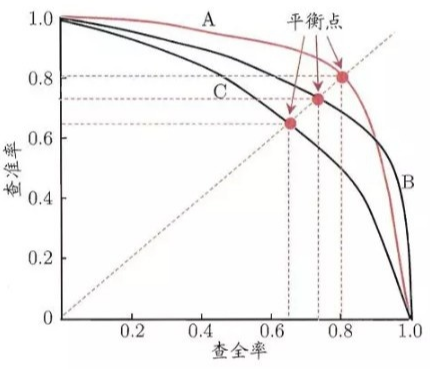
F1-Score指标综合了Precision与Recall的产出的结果(精确率和准确率都高的情况下,F1值也会高)。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
混淆矩阵的实例
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。
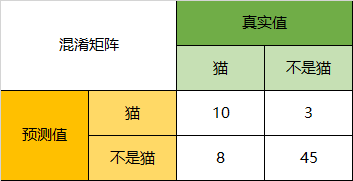
以下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,这是我们的结果:

通过混淆矩阵,我们可以得到如下结论:
Accuracy
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:
Precision
所以,以猫为例,模型的结果告诉我们,66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。这5只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
Specificity
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。
虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
同样,我们也可以分别计算猪与狗各自的二级指标与三级指标值。
通俗理解
刚开始接触这两个概念的时候总搞混,时间一长就记不清了。
实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是对的。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)。
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
ROC曲线
ROC曲线简介
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,若大于阈值则分为正类,否则为反类.例如,神经网络在一般情形下是对每个测试样本预测出一个[0.0,1.0]之间的实值,然后将这个值与0.5进行比较,大于0.5则判为正例,否则为反例.这个实值或概率预测结果的好坏,直接决定了学习器的泛化能力.实际上根据这个实值或概率预测结果,我们可将测试样本进行排序,“最可能”是正例的排在最前面,“最不可能”是正例的排在最后面.这样,分类过程就相当于在这个排序中以某个''截断点” (cut point)将样本分为两部分,前一部分判作正例,后一部分则判作反例。
在不同的应用任务中,我们可以根据任务需求来采用不同的截断点,例如:
-
更重视“查准率”,则可选择排序中靠前的位置进行截断
-
更重视“查全率”,则可选择排序中靠后的位置进行截断
因此,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的“期望泛化性能”的好坏,或者说,“一般情况下”泛化性能的好坏。ROC曲线就是从这个角度出发来研究学习器泛化性能的有力工具。
ROC 曲线是另一种用于评价和比较二分类器的工具。它和精确率/召回率曲线有着很多的相似之处,当然它们也有所不同。它将真正类率(true positive rate,即recall)和假正类率(被错误分类的负实例的比例)对应着绘制在一张图中,而非使用精确率和召回率。
ROC 关注两个指标:
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组,在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即
和
会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
如下面这幅图,(a)图中实线为ROC曲线,线上每个点对应一个阈值。

-
横轴FPR:FPR越大,预测正类中实际负类越多。
-
纵轴TPR:TPR越大,预测正类中实际正类越多。
-
理想目标:TPR=1,FPR=0,**即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
-
理想情况下,TPR应该接近1,FPR应该接近0。
ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。
比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)
-
随着阈值theta增加,TP和FP都减小,TPR和FPR也减小,ROC点向左下移动;
ROC曲线绘制
以FPR作为横轴、TPR作为纵轴作图,就得到了“ROC曲线”,显示ROC曲线的图叫做“ROC图”。如下所示,显然,对角线对应于“随机猜测”模型,而点(0,1)则对应于将所有正例排在所有反例之前的理想模型。

现实任务中通常是利用有限个测试样例来绘制ROC图,此时仅能获得有限个(真正正例率,假正例率)坐标对,无法产生上图(a)中的光滑ROC曲线,只能绘制出上图(b)所示的近似ROC曲线。绘制过程如下:
- 给定
个正例和
个反例,根据学习器预测结果对样例进行排序
- 设置不同的分类阈值:
2.1 把分类阈值设为最大,即把所有样例均预测为反例,此时TPR=FPR=0。在坐标(0,0)处标记一个点。
2.2 将分类阈值依次设为每个样例的预测值,即依次将每个样例划分为正例。设前一个标记点坐标为
: 当前若为真正例(TP),则对应标记点的坐标为
当前若为假正例(FP),则对应标记点的坐标为
- 最后用线段连接相邻点即得ROC曲线
ROC实例
为方便大家进一步理解,在网上找到了一个示例跟大家一起分享。下图是一个二分模型真实的输出结果,一共有20个样本,正样本10个,负样本10个。输出的概率就是模型判定其为正例的概率,第二列是样本的真实标签。
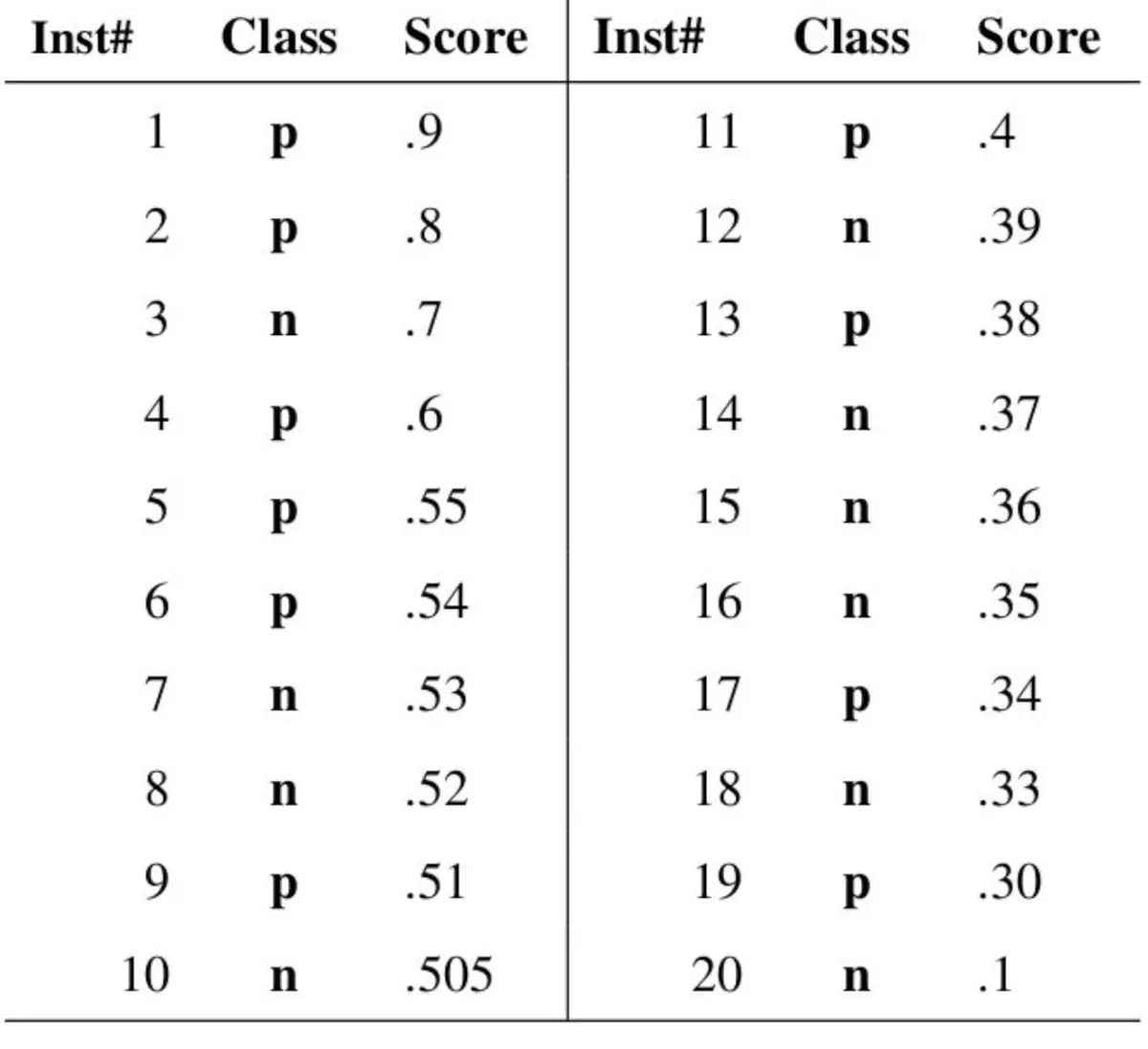
现在我们指定一个阈值为0.9,那么只有第一个样本(0.9)会被归类为正例,而其他所有样本都会被归为负例,因此,对于0.9这个阈值,我们可以计算出为0,
为0.1(因为总共10个正样本,预测正确的个数为1),那么我们就知道曲线上必有一个点为(0, 0.1)。再看第三个样本(0.7), 我们指定阈值为0.7,则预测正样本的为[1, 2, 3],此时TP=2, FP=1,则可以计算出
,
。依次选择不同的阈值(或称为“截断点”),画出全部的关键点以后,再连接关键点即可最终得到ROC曲线如下图所示。

优点
相比 P-R 曲线来说,ROC 曲线有一个很大的特点:ROC 曲线的形状不会随着正负样本分布的变化而产生很大的变化,而 P-R 曲线会发生很大的变化。
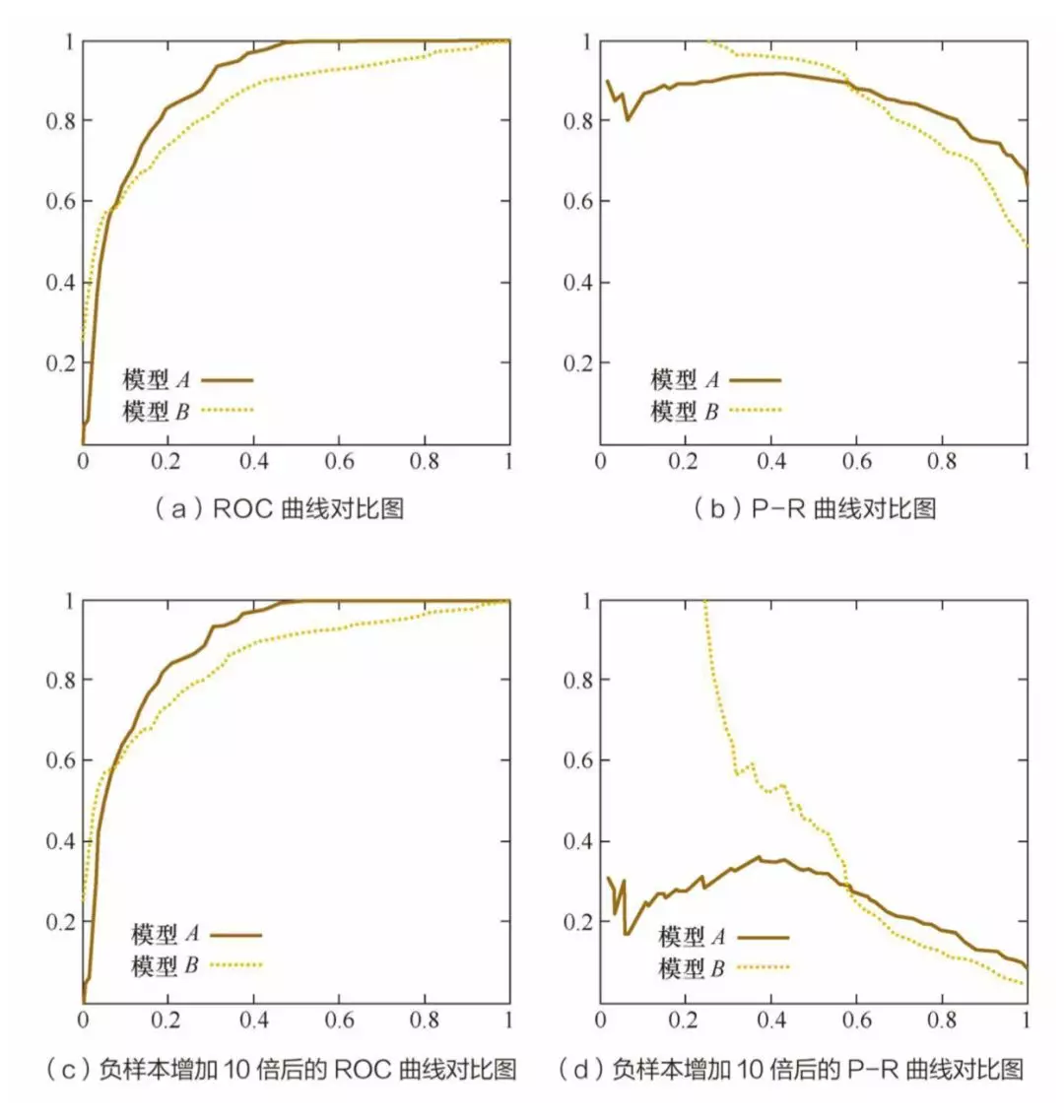
如上图测试集负样本数量增加 10 倍以后 P-R 曲线发生了明显的变化,而 ROC 曲线形状基本不变。在实际环境中,正负样本的数量往往是不平衡的,所以这也解释了为什么 ROC 曲线使用更为广泛。
AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
翻译过来就是,随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。
简单说:AUC值越大的分类器,正确率越高3。
,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
,跟随机猜测一样(例:丢铜板),模型没有预测价值。
,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反)
MSE、RMSE、MAE、R2
定义
- MSE(Mean Squared Error) 均方误差,
- RMSE(Root Mean Squared Error) 均方根误差,
- MAE(Mean Absolute Error) 平均绝对误差,
,决定系数,

优缺点
MSE、RMSE、MAE、 主要用于
回归模型。
MSE 和 RMSE 可以很好的反应回归模型预测值和真实值的偏离成都,但如果存在个别离群点的偏离程度非常大时,即使其数量非常少也会使得RMSE指标变差(因为用了平方)。解决这种问题主要有三个方案:
- 如果认为是异常点时,在数据预处理的时候就把它过滤掉;
- 如果不是异常点的话,就提高模型的预测能力,将离群点产生的原因建模进去;
- 此外也可以找鲁棒性更好的评价指标,如:MAE;
参考链接
- 西瓜书《机器学习》 周志华。
- zhuanlan.zhihu.com/p/68473880
- 一文详尽系列之模型评估指标

