

本文整理自集智系列活动AI&Society 第八期:图网络:融合推理与学习的全新深度学习架构
主讲人张江教授,来自北京师范大学系统科学学院教授,博士生导师。同时也是集智俱乐部和集智学园的创始人。图网络是张老师近年来的主要研究和兴趣方向。
原文首发于集智斑图
背景:系统科学和图网络的关系
所谓的系统科学(school of system science)是干什么的。其实不用说的太复杂,系统科学就是研究graph的。我们看很多系统的时候,包括社会、生物、技术等等,其实很多时候我们就是把它抽象成一个网络(graph)。所以网络是我们从事系统科学研究的人主要关心的东西。一直以来其实和深度学习这个领域没什么关系。
在大概2014年的时候,我们在彩云举办了一个小型的读书会,读到了一篇特别有意思的文章,就是word2Vect,当时听了觉得很振奋。是因为它不仅仅能把单词嵌进去,而且它会有一些代数运算,而代数运算跟语义的运算是非常相关的。我一下就敏锐的感觉到这东西很重要。实际上它的基本的原理,是通过机器学习,学习到每个词的所谓的“生态位”,也就是上下文(context)。这种“生态位”恰恰就是我们系统科学关注的一个概念。于是我就很兴奋,因为我意识到这个东西是可以放在复杂网络上面的。后来也知道了deepWalk那篇文章也已经做了这件事,就是特别简单地把word2vect直接套到一个复杂网络。然后我开始就决定了在这个领域扎下去,觉得机器学习和graph,这一定是一个全新的碰撞。
之后就非常快,由图像领域扩展到图上的图卷积网络(graph convolutional network),图上强化学习,图生成等等技术的飞速崛起,都预示着图和深度学习的结合,也就是图网络,即将成为一个炙手可热的研究领域。后来的现象也证实了这一点:谷歌,deepMind等业界大佬都开始关注这个领域,并出了第一篇相关的图网络综述文章(Relational inductive biases, deep learning, and graph networks)。
今天主要的内容,就是想跟大家介绍一下图网络到底是怎么回事,图网络目前的发展情况,以及它可以用来做什么
深度学习的本质
首先我想来说说深度学习,它最本质的因素是什么?最本质意味着它可以进一步扩展。肯定有多种理解了,比如有说它就是深度神经网络(deep nerual network),还有说它是一种表征学习或者向量表示(representation learning),其实这些都不够本质,因为这么理解的话,它不能扩展到我们今天所谈论的内容。我来说说我的理解,我觉得深度学习本质是一种可微分的编程(differential computation)。
比如我们比较喜欢用的pytorch就非常好地体现了这种思想。pytorch跟其他编程语言相比,其实没有本质的区别,你就像在写python程序一样。但是它有一点很神奇,就是可以自动做梯度反传(backward),它之所以能做到这一点,是因为背后有一套“计算图”作为支撑(computation graph),也就是你在写代码的时候,已经搭建了一个图的框架。换句话说,它实际上是一种符号计算和数值计算的融合,因为这种“计算图”的存在,所以我们可以去做求微分的操作。可以这么说,这种所谓的深度学习,就是一个可微分的(可导的)架构下的一个计算。
那么这是不是就意味着,任何一种东西——我们不妨先畅想一下——比如一个建筑物,只要能够把它的部件使用可微分的元件搭建起来,我们给定最终的目标,也就是评价标准,那么整个设计过程就成了一个可学习的模式,它自己不断的进行梯度反传,就能自动调整整个设计模型和结构呢。
当graph遇上深度学习
实际上,我们的畅想是完全可行的。图网络非常强大,可以完成的任务非常之多。
比如像图卷积神经网络(graph convolutional neural network),卷积对平移之类的操作有非常好的可移植性,也就是它的权重都是可复制的,图卷积神经网络搭建了一种层层深入的架构,就是为了去捕获数据之中的不变性,所以它的学习表现特别好。除此之外还有带注意力(attention)机制的模型,15年deepMind的可微分计算机等等,和传统任务相比都有非常优秀的表现,这里就不过多的展开讲。
那么所有上述的这一些都是过去的进展了。有人可能会质疑现在的deep learning也没什么了不起,毕竟不能融合传统的人工智能学派,比如符号运算,行为学派,贝叶斯学派等等(这里的学派划分相对比较任意,仅供作为示例参考)。实际上,这个问题目前部分已经得到了解决,比如说与符号学派搜索算法的结合,就是alphaGo的蒙特卡洛树搜索;还比如说我们系统科学很感兴趣的多主体算法(multi agent)也融合了学习的框架进来;另外像贝叶斯网络,这种具有推理能力的概率图模型和深度学习的融合,也有人已经在做了。我们待会儿还会对某些问题具体展开。
除此之外,还有很多很多领域,社交网络,生物的网络,脑网络,我们会发现这种非欧氏几何(graph)数据,在大千世界数不胜数。而下面篇文章就告诉我们,我们完全有能力去处理这种graph数据结构。
Relational inductive biases, deep learning, and graph networks [2018]Peter W. Battaglia,Jessica B. Hamrick,Victor Bapst查看论文
这篇文章在挂出来之后就引起了广泛的讨论。虽然我觉得可能有一点夸大其词,比如我们今天要讲的是要融合推理与学习,也许其实并没有做到这一步,但整个领域的确是在往这个方向走的。大家正在全力以赴的把深度学习放到“图”的架构上面。
文章列了几个典型的图网络的系统,包括分子网络,这是一个典型的图;包括物理上的n体问题;包括在图像上,有多个物体在运动,要捕捉这些物体的运动,实际上也可以把它抽象成节点(node)和关系(egde)的图结构。
图网络到底是什么
那么到底什么是图网络呢,图网络实际上是对神经网络(neural network)的一种扩充。我们知道神经网络其实就是一个图,只不过它的图结构比较特殊,在神经网络中基本上都是前馈的,而且层级分明,另外神经网络的学习通常仅仅发生在连边上,然后调整连边的权重。图网络对神经网络在多个方面进行了扩充。
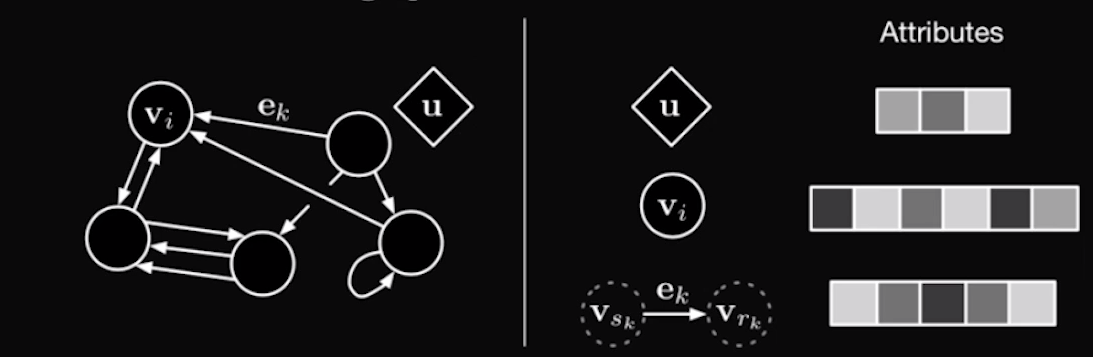
其次,当做完前馈运算以后,它也会进行反向传播的学习,刚刚我们也说到它的每一步运算都是可微分的,这就是一个普通的前馈神经网络的过程。也就是它把前馈神经网络放在了每一个环节,比如连边上有一个,节点有一个,全局可能还有一个等等。这样就导致了它就可以对结构进行概括,并通过反向传播算法进行学习,从而更新映射函数,使得整个网络架构变成了一个可学习的架构。
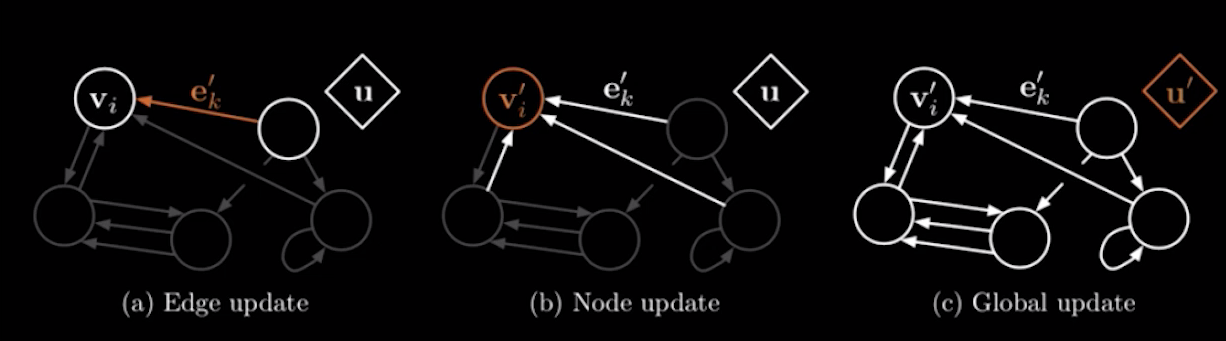

为什么说图网络能融合推理和学习
就像刚刚那篇论文的题目,induction bias,翻译成中文的话就是,它是一种推断性的先验的偏见,实际上这个偏见是指网络的架构。换句话说,一般的情况下,图网络模型网络的拓扑结构是给定不变的,它是不可学习的(这里先不考虑图生成这种情况)。既然固定不变,那实际上就是模型设计者的一种先验“偏见”。我们知道我们搞推理的很多时候,其实也可以理解成是这样一种图。比如因为a事件发生导致b事件,实际上就可以表示成这样一个有向的连边。包括贝叶斯网随机变量a影响随机变量b,那么它们之间就有一条连边。这种连边暗含了这种推理的信息,于是我们工程师就把这种推理的,也就是先验的信息放到了这种图的架构上面。这就是所谓的inductive bias,也就是体现了所谓的“推理”
其次就是学习能力,当然我们刚才说的,图上的每一个环节映射本身都是可学习的,所以它就具有了学习和推理相融合的能力。举一个很典型的例子就能够看出来。比如下图这种机械狗,是一个非常简单的框架,通过一个多体的连杆把关节连接以来。对于这种结构,如果要对它去做预测、控制等任务,就可以放到图网络上面。
首先图的建立,每个杆就是一个实体( Entity),我们可以抽象成为节点,杆和杆之间的关节就是一种连线,那就很自然地可以把这只机械狗建模成如图所示的graph。如图4(a)
我们假设每个节点,也就是每个多体的连杆都有6个自由度(实际上可不止6个,可以人为设置),就相当于每个连杆都可以用一组向量来表示它的状态(很显然,设置的自由度特征越多,学习效果越好)。那当机器狗运动的时候,关节怎么去联系呢?
我们知道在物理学中,力学上有各种复杂的动力学传导过程,这些动力学的传导过程,就可以完全给它编码成一组连边上的向量。还有一些全局信息,比如说外界给它的这种指令,或者是它的一些整体的表现,整体的速度,整体的位置等等,这是属于全局的信息,编码到g里边。于是机械狗就可以建模成一个图网络。(如图4(b))
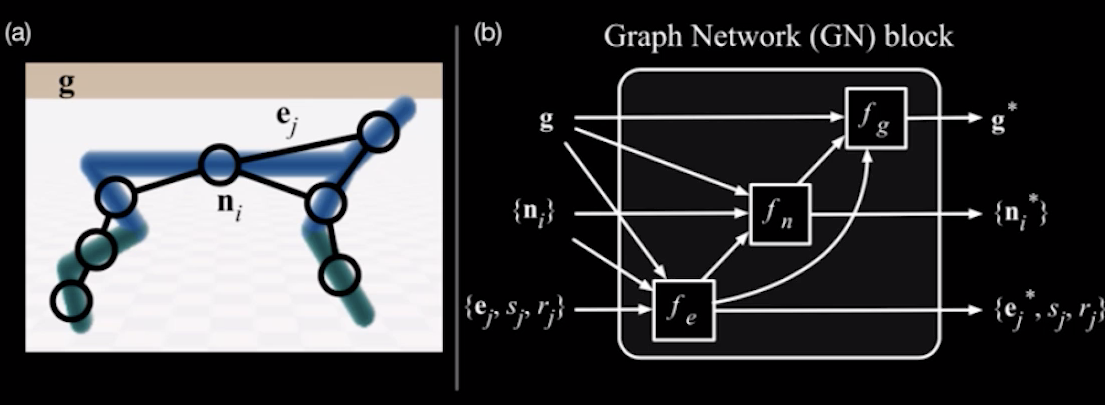
这里面它三条线就分别表示是连边、节点、还有全局信息,这里面的函数fn用一个普通的MLP去建模它就可以,有了这种前馈,一个backward它就能自动地去学习了。假如说这是一个预测任务,我们能观察到的是,机械狗这些关节在前t-1步的状态(速度,位置等)是什么,根据这些信息去预测t、t+1、t+2等等时间步的状态。
Graph networks as learnable physics engines for inference and control [2018]Alvaro Sanchez-Gonzalez,Nicolas Heess,Jost Tobias Springenberg查看论文 当然在基本的图网络构建完成之后,它还可以在高层次进行组合以实现不同的任务,就像卷积神经网络一样,构建一个多层的图网络结构,可以去拟合更复杂的运算过程。同样的,还可以加入RNN,即加入记忆机制等方式去构建网络,拟合结果都是非常好的。
图卷积网络
刚才说的是一个物理系统,实际上这套原理完全可以放到一个更宏观的框架下。下面我介绍一下我带着我的一个学生辛茹月做的一些小的东西。我们在用这个框架去学习网络上的动力学过程。我们知道在复杂世界里面,疾病的传播它就是一个网络上的一个动力学过程。因为每一个社交网络里面每一个人是个节点,然后你可能感染疾病,可能不感染,这个疾病可以传播。再比如说交通流也是这样,一个交通拥堵的扩散过程也是一个动力学过程。我们就去仿照了卷积神经网络这种框架,尝试在graph上面做convolution操作。
那么大家可能会很跟我当时一样感到很好奇:graph上面怎么去做卷积操作?实际上大约在15年就有一篇文章提出来一种可能性,就是做一个傅立叶变换。也就是说可以把图上的一个信号,先把它傅立叶变换到频域上。这里大家可能会感到奇怪,傅立叶变换一般的都是连续的信号,比如说时域信号或者是一个二维的图像可以做傅立叶变换,那么对于graph怎么去做呢?
刚好在10年左右有一个新兴的领域,就是graph signal processing(图信号处理)一下火了起来。这就启发这帮搞深度学习的人,了解到实际上可以对图去做这种傅立叶变换,有了傅立叶变换,那么卷积在这种频域下就变成了一种乘法,这对于卷积过程来说事情就变得超级简单了。
这样,我们就可以去扩展卷积的定义,并在图上去做这种卷积操作。
最后推导实际上也是超级简单,Kipf他们做了一个很大的改进,发现虽然兜了一圈——想参考图像的图傅立叶变换——最后图上的卷积操作变成了一个“随机游走矩阵”,乘以图上的信号,再由一个可训练的映射,就可以完成一步卷积运算,最终就可以从一个状态(即一组向量)输出一组向量。
Semi-Supervised Classification with Graph Convolutional Networks [2019]Esteban Bautista,Patrice Abry,Paulo Gonçalves查看论文
这样定义了卷积以后,整个过程就有一种很神奇的本领,比如拿跆拳道俱乐部网络举例,我们已知一些标签信息,但是我们没有告诉图卷积网络模型,它自己在一个完全随机化的初始状态下,对整个网络去做图卷积,得到了表征空间。最后我们神奇地发现,没有任何训练,只是做了一次两次图卷积以后,有些相同地标签就会自发地聚集在一起了。为什么会是这样?我们也分析过,是因为图卷积操作,它就是在捕获邻域信息,也就是这个节点跟谁相连的信息,而这些邻域信息又会在一开始就被编码在随机的权重里。因此当做了一次两次卷积以后,尽管一开始的初始化是随机的,但这种邻域信息在不同的节点上就会逐渐表现出来。所以我们会发现做了一步卷积操作以后,网络好像就可以自动地对这些节点做聚类,这是很神奇的一个特性。
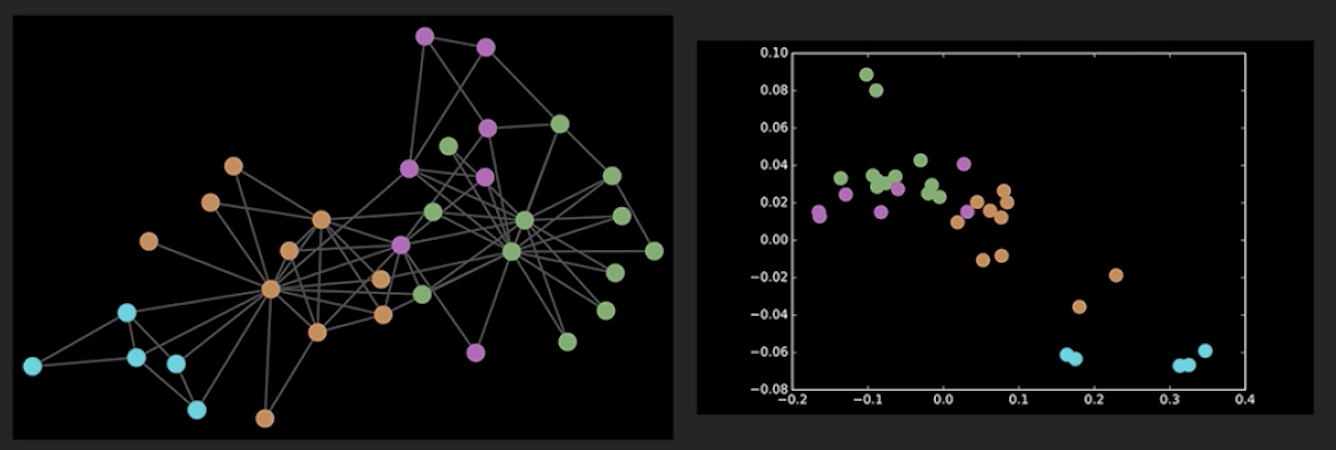
有了这种图卷积网络,我们还可以去做一些任务的训练,效果也不错。比如说在Kipf这篇论文里面,还介绍了一个半监督学习的方式。
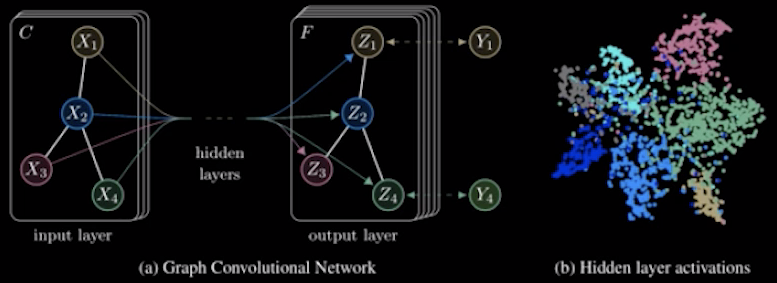
这是一个节点分类任务。假如说是一个社交网络,我们已知张三李四王五是恐怖分子,想找出其他未知的节点哪些是恐怖分子。我们通过这个社交网络的连接结构,去进行推测。具体怎么做呢。首先把已知标签信息赋予给这些节点,然后进行多层的图卷积操作,做完若干步以后,这些已知的标签就好像一个状态一样有一个扩散过程,之后再拿已知信息的那些节点来做监督,去训练调节整个结构,从而使得已知的标签信息被推广到整个网络上。而且这个标签信息很符合我们的预期。报告里面称实验结果的准确度能达到80%以上。这个是一个很典型的图卷积神经网络。
我们自己也拿这个图卷积神经网络去玩了一些小玩意,我们做的这个事很简单,就是使用SIR模型(一个网络上的疾病传播模型),整个网络是固定的,也就是结构不变,而且模型的动力学过程已知,它是t,t+1,t+2,t+3这样不断的去演化的。每个节点都有自己的状态:感染,未感染、康复。我们使用图卷积网络模型去预测整个网络下一步的演化状态。做法也很简单,就是不断地输入t-1步所有节点的状态,让图卷积网络模型去预测t步的状态,用真实的状态做目标,让它进行参数学习。学习完成后,模型就可以去预测未来的状态。现在的准确度是有82%。更有意思的是,假如一开始模型只知道一部分节点的信息,最终模型可以把未知部分节点的状态也能预测出来,准确度也不错。
图网络的扩展与应用
最近图网络也有一些很有意思的扩展,比如说把注意力机制(self attention)放到这个图网络上面,扩展的就是图卷积神经网络(GCN),他们做的就是把一个自注意力机制放到了网络上
也就是说在更新节点信息的时候会先算出来一个注意力的值,这个注意力值决定了邻居的权重,重点关注重要的邻居,从而提高预测的准确性,目前也是业界顶尖的水平。另外我自己最近也在研究这块内容,我们网络是VC网络,发现学出来的注意力真的可以把真正起作用的VC挖出来。
刚在提到的都是属于图网络以及基于图网络的变种。接下来我来讲一讲目前有意思的图网络的应用。
首先李飞飞他们组,他们做的一个工作很有意思,题目叫social LSTM。我们知道在多主体领域有一个著名的社会力模型。比如说这个会场突然说着火,大家就会拥挤着去冲出门。那么用多主体的方式把这个现象模拟出来就是社会力模型(social force)。李飞飞就是呼应这个,给自己的模型取了个名字叫social LSTM,他们的模型不仅仅是有多主体,而且多主体可以去自学习,最后的结果会非常精确的去逼近每一个人运动轨迹。
模型的基本的架构还是很简单很清晰的,首先每一个主体(这里是人)都是一个LSTM,我们知道LSTM里面它会有一个隐含层的变量,这个状态信息叫h。在这个social模型中的体现就是,如果空间上的邻居靠的很近,那么我们就认为这两个人是很有可能发生相互作用,那么就把这些主体的信息耦合在一起(做加法),合成新的隐含状态信息放入LSTM。这里graph的连边相当于就是欧氏空间的相邻。最终训练出来的结果和实际数据非常的吻合,也就是说整个模型非常好的去把握住了这一人类群体的运动过程。这是一个典型的图网络在Multi agent system这个领域的应用
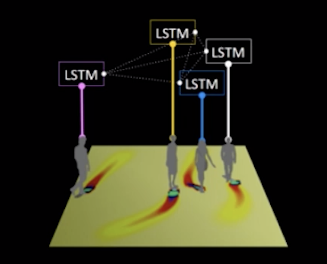
Social LSTM: Human Trajectory Prediction in Crowded Spaces [2019]Alexandre Alahi, Kratarth Goel, Vignesh Ramanathan查看论文
另外一个很多人可能会比较关心的例子,就是怎么去融合推理和学习。不过我觉得图网络在这方面可做的仅仅只是一个小小的开端。
我们知道贝叶斯网(又叫概率图模型,或者马尔科夫场,随机场等等),它实际上本身就是有连边、有节点。这个节点是随机变量,连边是因果关系。而通常情况下这个网络是要人事先建好,并且同时还要赋予节点分布信息,每条连边的分布概率等等。所以这个建模的过程并不容易。而有了图网络之后,我们是希望它去自动计算这些信息,而我们只需要考虑某一个观测节点的表现。
一个典型的应用就是,我们都知道在深度学习出现之前我们是使用隐马尔可夫模型(hidden mark)来去做语音序列的学习,这是一个典型的随机图模型。传统方法我们去计算边缘概率的时候,会使用信念传播算法(belief propagation)。而现在,也是17年的SCI上的一个论文,他们不使用bp算法,而是用图网络来学习这种过程,从而让整个过程更加高效,最终效果也非常好。
Inference in Probabilistic Graphical Models by Graph Neural Networks [2018]KiJung Yoon,Renjie Liao,Yuwen Xiong查看论文
当然,可能结果并没有那么让人吃惊,但我觉得想说的一点是,如果我们这些图结构,以及每一个节点和连边上的概率分布都是可学习的话,那就意味着我们只需要一些观测信息,就有可能推测出来整个网络,以及每一个网络上相应的分布信息。这其实就可以做到融合推理和学习了。
离散过程的学习
以上我们对图网络的概述可以描述为这么一句话:Neural liked learning can be applied on any differential structure。只要是可微分,那么图网络就能把整个过程都模拟出来。现在,我想把这句话改成:Neural liked learning can be applied on any any structure。这意味着,实际上现在已经有技术可以让我们做到,即使不可微分(即离散),只要可以构建出一个网络,那么就可以使用图网络做学习。
这一点可以说是突破性的进展!深度学习之所以可以进行拟合和学习,是因为梯度反传的机制去调整其中的参数,而如果节点状态是离散变化的,也就意味着梯度断了。那么在一个离散的过程中,要如何自动调整参数呢?
如果你玩过强化学习,都会知道policy gradient。在强化学习中,可能前面复杂的神经网络都是可微分的,但总是会有最后一步:依概率去选择一个行动(action),最终针对每个选择都会有一个评价(奖励或者惩罚),这个选择的过程就会导致梯度信息丢失。在强化学习中解决这个问题的方法就是policy gradient。它是用一个概率期望来去替代评价函数,也就是说并不是每一次最后选择一个action,就给一个回报去学习,而是要做多次选择,这样的话就可以产生一个期望。当你把这个期望经过这样的一个公式,最后期望的梯度就完全变成是一个可微分的,从而可以继续梯度反传。
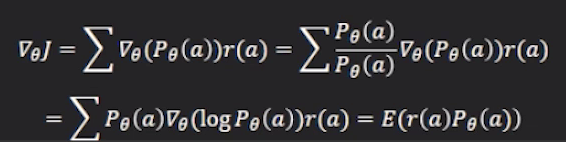
这部分内容牵扯到强化学习,大家了解就好,大家只需要知道的是有这么一种技术,可以使得离散的选择变成是可微分的,可传递梯度的,可学习的过程。但是这里面有一个缺陷,主要就是体现在算梯度的时候,如果仅仅算reward的期望是不行的,最后结果的震动性很大,非常不确定,也很难去优化,可能每次做最终的效果都不一样,而且非常难收敛,所以人们就不得不去扩展这种方法,比如说加一个critic等等。谷歌brain这篇文章就是在尝试扩展policy gradient方法,但是很受争议。有些人认为他们太过夸大,有些人质疑他们的计算结果不好,但也有一些人对他们的工作非常支持。
那么在这里我介绍一个克服梯度反传的神奇技术,叫做gumbel softmax。如图展示了基本的思路。
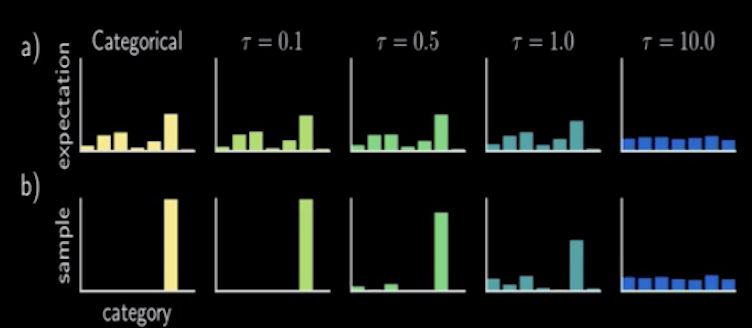
gumbel分布是一种极值型分布,假设现在有一组数,每次都抽最大的那个数值,多次操作之后,最后这一堆最大值会形成一个分布,这就是gumbel分布。
那么当我们的模型要进行最后的概率选择,每个选择都加上一个gumbel随机数,并通过一个温度参数T去调节这个数的随机性。用这种方式,可以实现概率选择的“连续过度”,使得整个过程都是可微分的,即在梯度不丢失的情况下,也作出了概率选择。
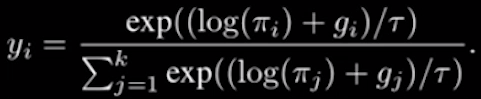
Categorical Reparameterization with Gumbel-Softmax [2016]Eric Jang,Shixiang Gu,Ben Poole查看论文
这就意味着,现在的深度学习领域已经完全可以扩大到任意一种结构!
回过头来我们说像贝叶斯网这种概率图模型,也就完全可以做到用深度学习的方法去建模。我们现在也正在尝试,想通过这样的一种方式,去把网络结构学习出来。网络结构的学习其实很困难,因为结构是一个离散的概念,有连边,或者没有连边。我们使用这种算法就有可能去突破这个困难。所以在未来,任何事物都是可学习的,我相信这一点真的是有可能实现的。
总结
我们可以看到现在图网络已经扩展到了非常多的领域,很多领域的架构本来是各自平行的发展的,在图网络这个框架下,却逐渐走到了一块去。
不仅如此,图网络还可以融合机器学习和先验的对结构的认知信息,更有意思的是,像policy gradient和gumbel这些方法的突破,很可能使得任何的架构都成为一种可学习的网络。
