我的Github地址
小码哥《恋上数据结构与算法》笔记
极客时间《iOS开发高手课》笔记
iOS大厂面试高频算法题总结
iOS面试资料汇总
一、二叉堆(Heap)
1、思考

- 更优秀的数据结构:
堆,获取最大值复杂度O(1),删除最大值O(logn),添加元素O(logn)
2、概念
- 堆(Heap)也是一种树状的数据结构
- 堆的一个重要性质:任意节点的值总是
大于等于或小于等于子节点的值。
- 如果任意节点的值总是大于等于子节点的值,称为
最大堆,大根堆,大顶堆。
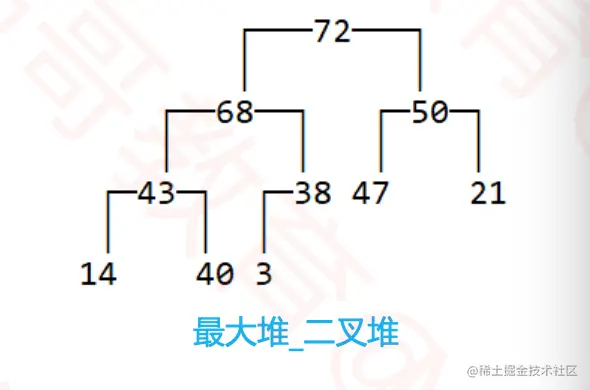
- 反之称为
最小堆,小根堆,小顶堆。
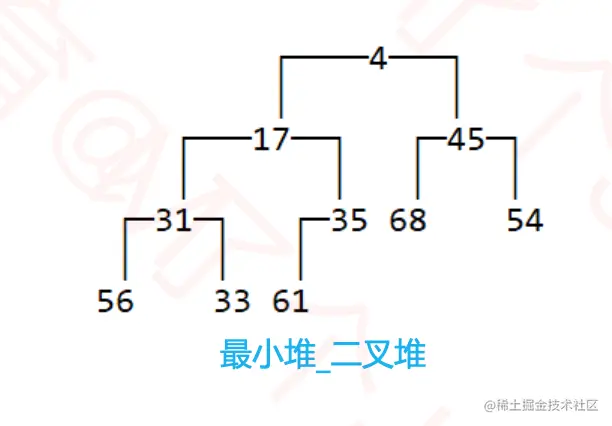
- 最大堆和最小堆的最大值/最小值都在顶部。且堆中的元素必须具备可比较性。
3、堆的接口设计
public interface Heap<E> {
int size();
boolean isEmpty();
void clear();
void add(E element);
E get();
E remove();
E replace(E element);
}
二、二叉堆(Binary Heap)
二叉堆的逻辑结构就是一颗完全二叉树,所以也叫完全二叉堆。
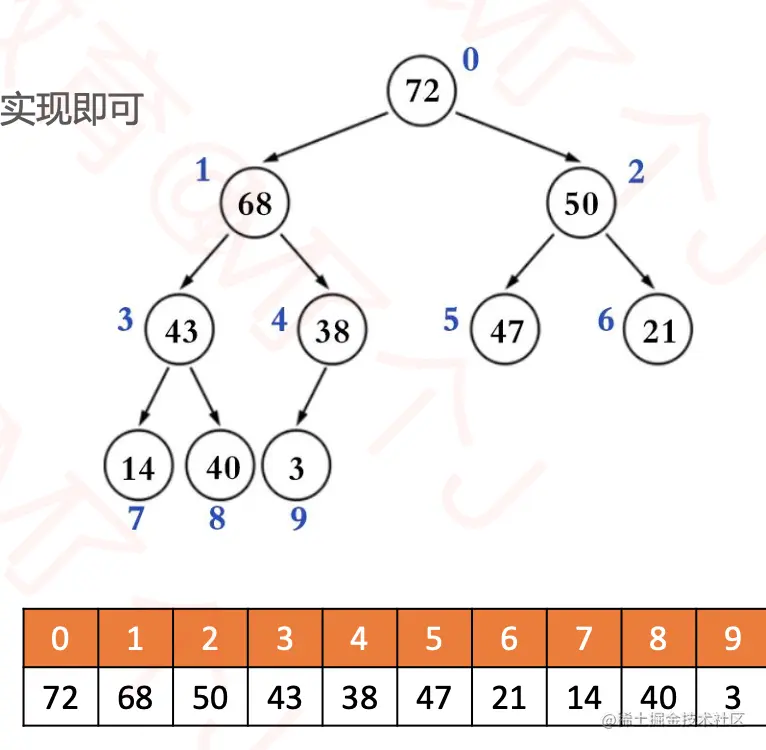
- 鉴于完全二叉树的一些性质,二叉堆的底层(物理结构)一般用数组实现即可。
- 索引i的规律(n是元素数量)
- 如果
i = 0,它是根节点。
- 如果
i > 0,它的父节点的索引为floor((i-1) / 2)。
- 如果
2i + 1 <= n - 1,它的左子节点的索引为2i + 1。
- 如果
2i + 1 > n - 1,它无左子节点。
- 如果
2i + 1 <= n - 1,它的右子节点的索引为2i + 2`。
- 如果
2i + 1 > n - 1,它无右子节点。
三、二叉堆(Binary Heap)接口实现
1、构造函数
public BinaryHeap(E[] elements, Comparator<E> comparator) {
super(comparator);
if (elements == null || elements.length == 0) {
this.elements = (E[]) new Object[DEFAULT_CAPACITY];
} else {
size = elements.length;
int capacity = Math.max(elements.length, DEFAULT_CAPACITY);
this.elements = (E[]) new Object[capacity];
for (int i = 0; i < elements.length; i++) {
this.elements[i] = elements[i];
}
heapify();
}
}
2、添加
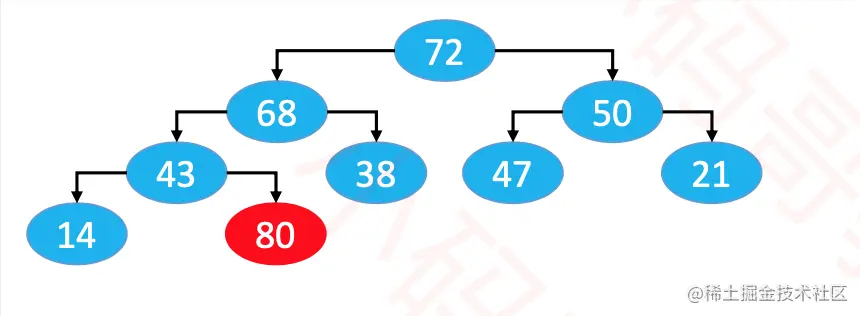
- 添加操作需要循环执行以下步骤:
- 如果
node > 父节点,则与父节点交换位置。
- 如果
node <= 父节点,或者node没有父节点,则退出循环。
- 这个过程叫做
上滤(Sift Up),时间复杂度为O(logn) 。
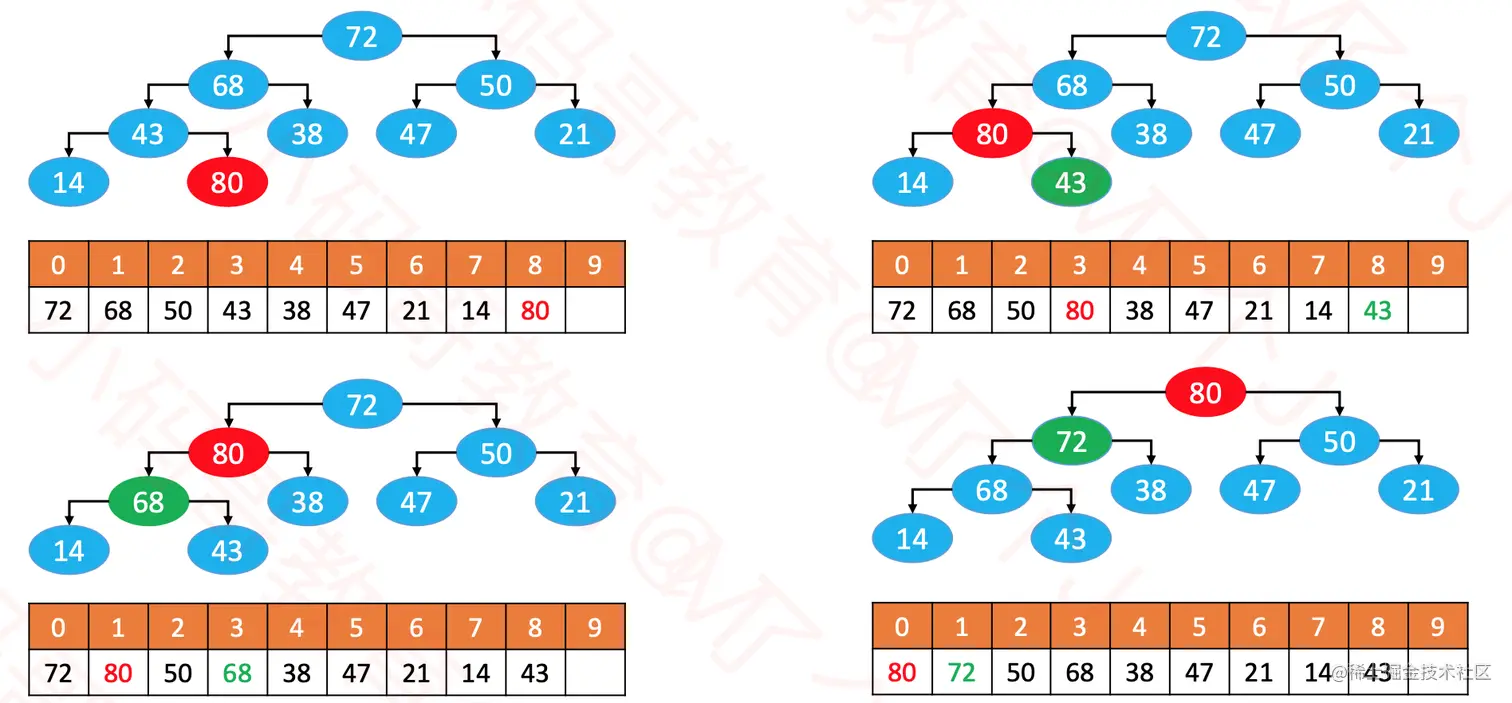
@Override
public void add(E element) {
elementNotNullCheck(element);
ensureCapacity(size + 1);
elements[size++] = element;
siftUp(size - 1);
}
private void elementNotNullCheck(E element) {
if (element == null) {
throw new IllegalArgumentException("element must not be null");
}
}
private void ensureCapacity(int capacity) {
int oldCapacity = elements.length;
if (oldCapacity >= capacity) return;
int newCapacity = oldCapacity + (oldCapacity >> 1);
E[] newElements = (E[]) new Object[newCapacity];
for (int i = 0; i < size; i++) {
newElements[i] = elements[i];
}
elements = newElements;
}
private void siftUp(int index) {
E element = elements[index];
while (index > 0) {
int parentIndex = (index - 1) >> 1;
E parent = elements[parentIndex];
if (compare(element, parent) <= 0) break;
elements[index] = parent;
index = parentIndex;
}
elements[index] = element;
}
3、删除
- 用最后一个节点覆盖根节点
- 删除最后一个节点
- 循环执行以下步骤(
43简称为node)
- 如果
node < 最大的子节点,与最大的子节点交换位置。
- 如果
node >= 最大的子节点,或者node没有子节点,则退出循环。
- 这个过程叫做
下滤(Sift Down),时间复杂度:O(logn)。
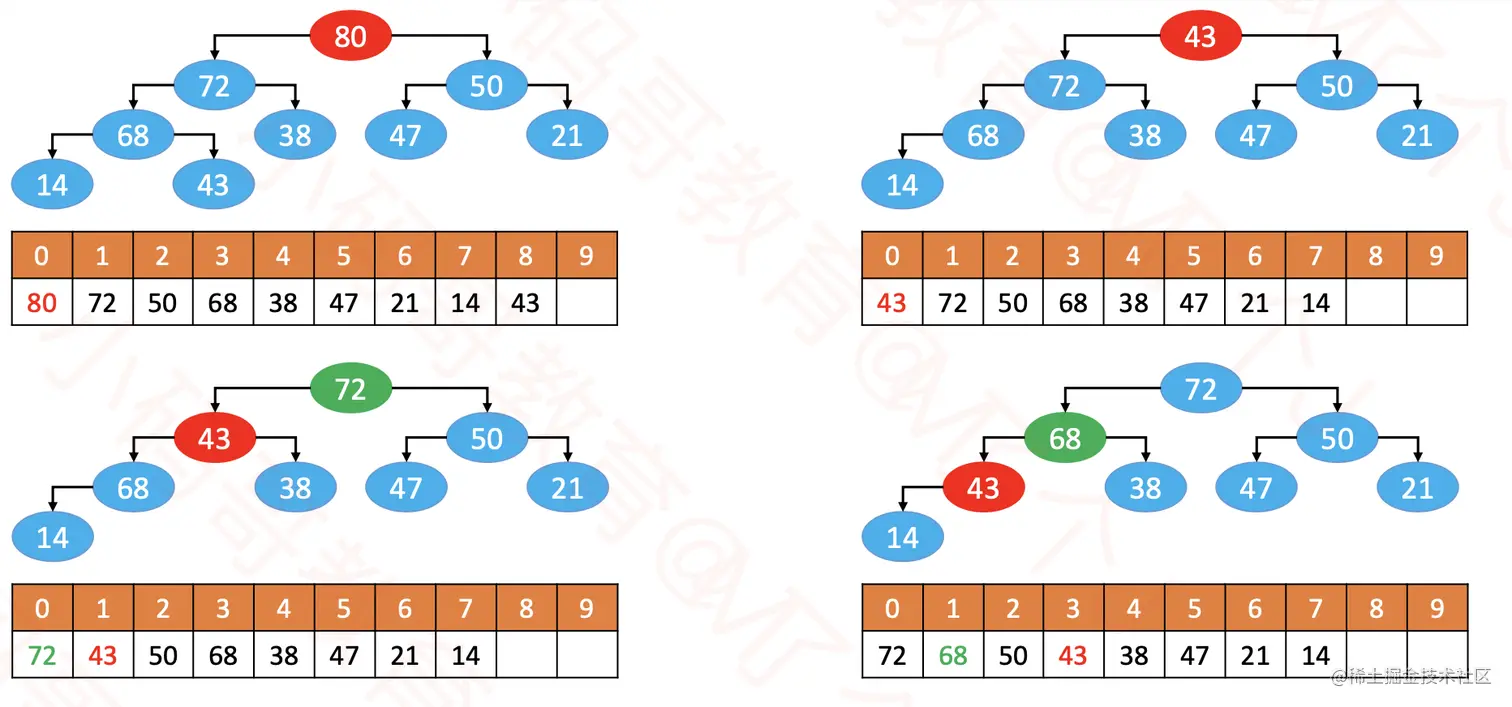
@Override
public E remove() {
emptyCheck();
int lastIndex = --size;
E root = elements[0];
elements[0] = elements[lastIndex];
elements[lastIndex] = null;
siftDown(0);
return root;
}
private void siftDown(int index) {
E element = elements[index];
int half = size >> 1;
while (index < half) {
int childIndex = (index << 1) + 1;
E child = elements[childIndex];
int rightIndex = childIndex + 1;
if (rightIndex < size && compare(elements[rightIndex], child) > 0) {
child = elements[childIndex = rightIndex];
}
if (compare(element, child) >= 0) break;
elements[index] = child;
index = childIndex;
}
elements[index] = element;
}
4、replace操作
- 删除堆顶元素,并用新值替换。
- 用新值替换堆顶,然后做
下滤操作即可。
@Override
public E replace(E element) {
elementNotNullCheck(element);
E root = null;
if (size == 0) {
elements[0] = element;
size++;
} else {
root = elements[0];
elements[0] = element;
siftDown(0);
}
return root;
}
5、批量建堆
- 批量建堆有两种做法
- 自上而下的上滤:从上而下拿到每个元素,然后上滤。
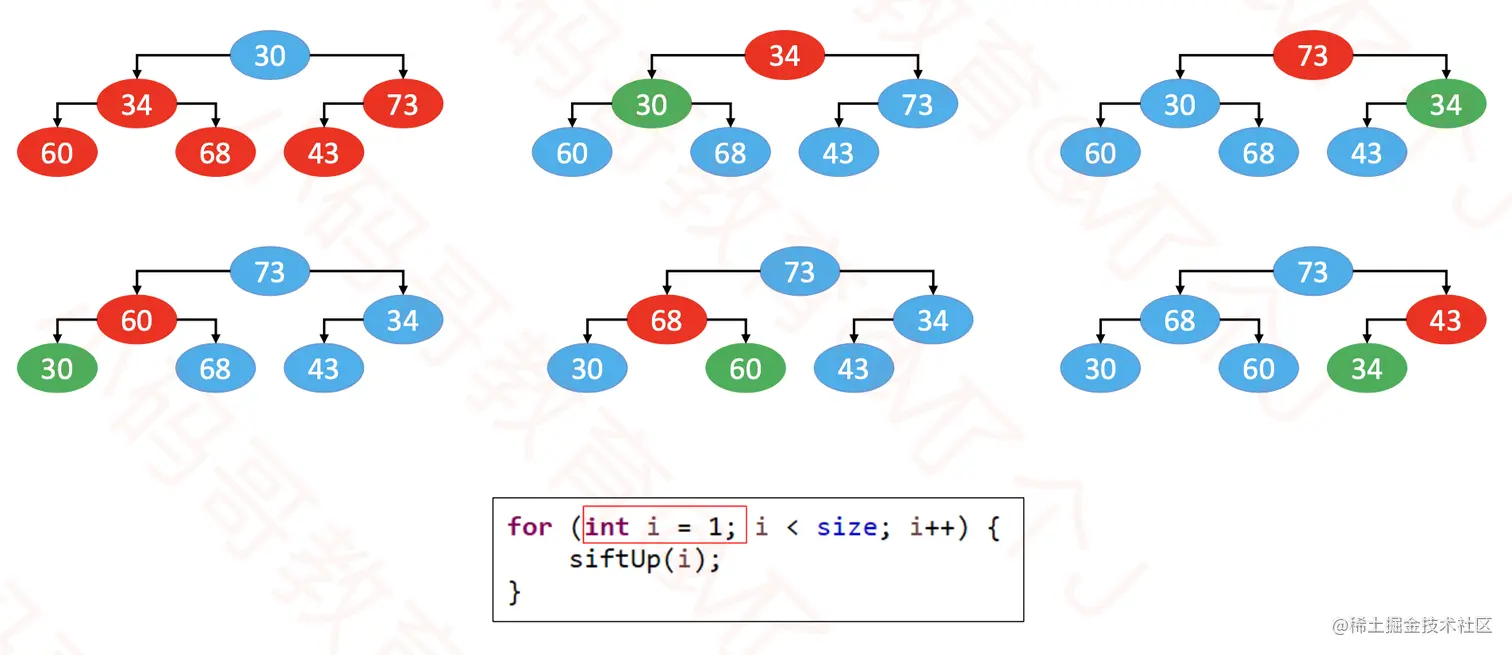
- 自下而上的下滤:从下而上拿到每个元素,然后下滤。
- 叶子节点无须下滤,所以从第一个非叶子节点开始操作。
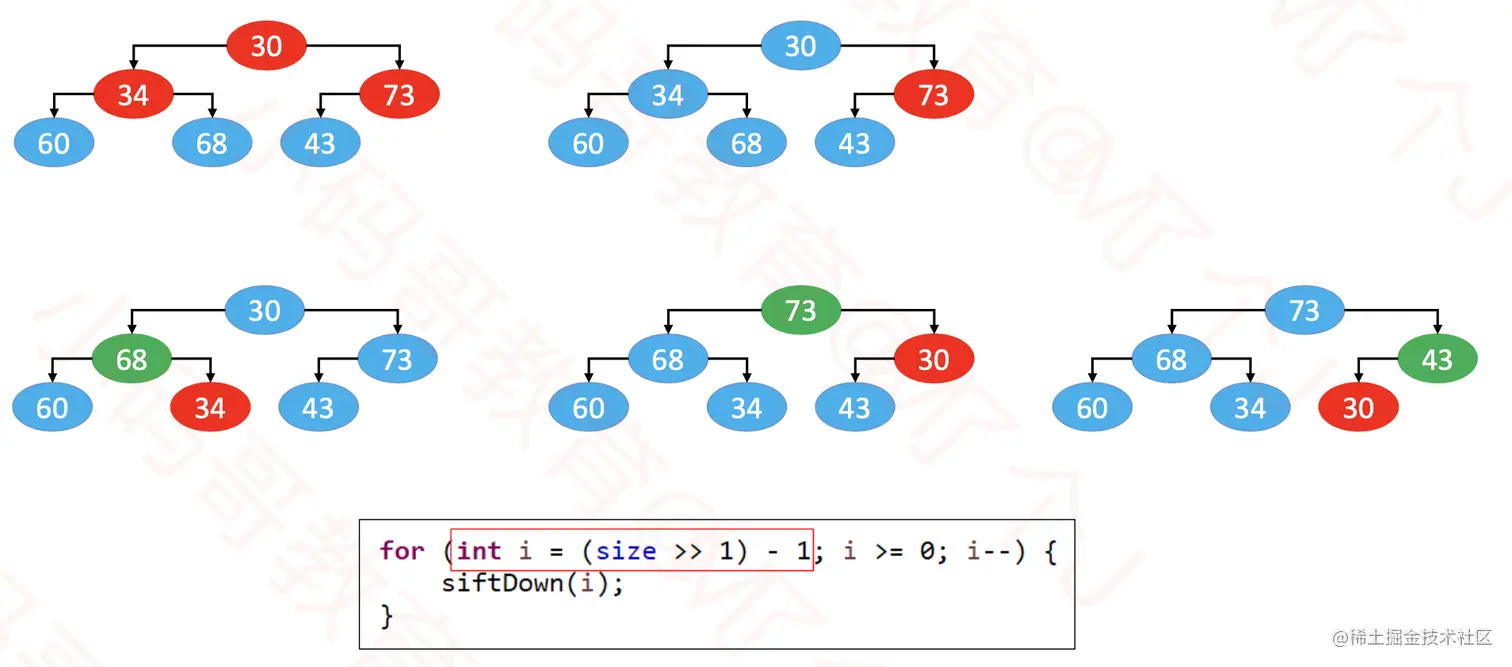
- 效率比较:
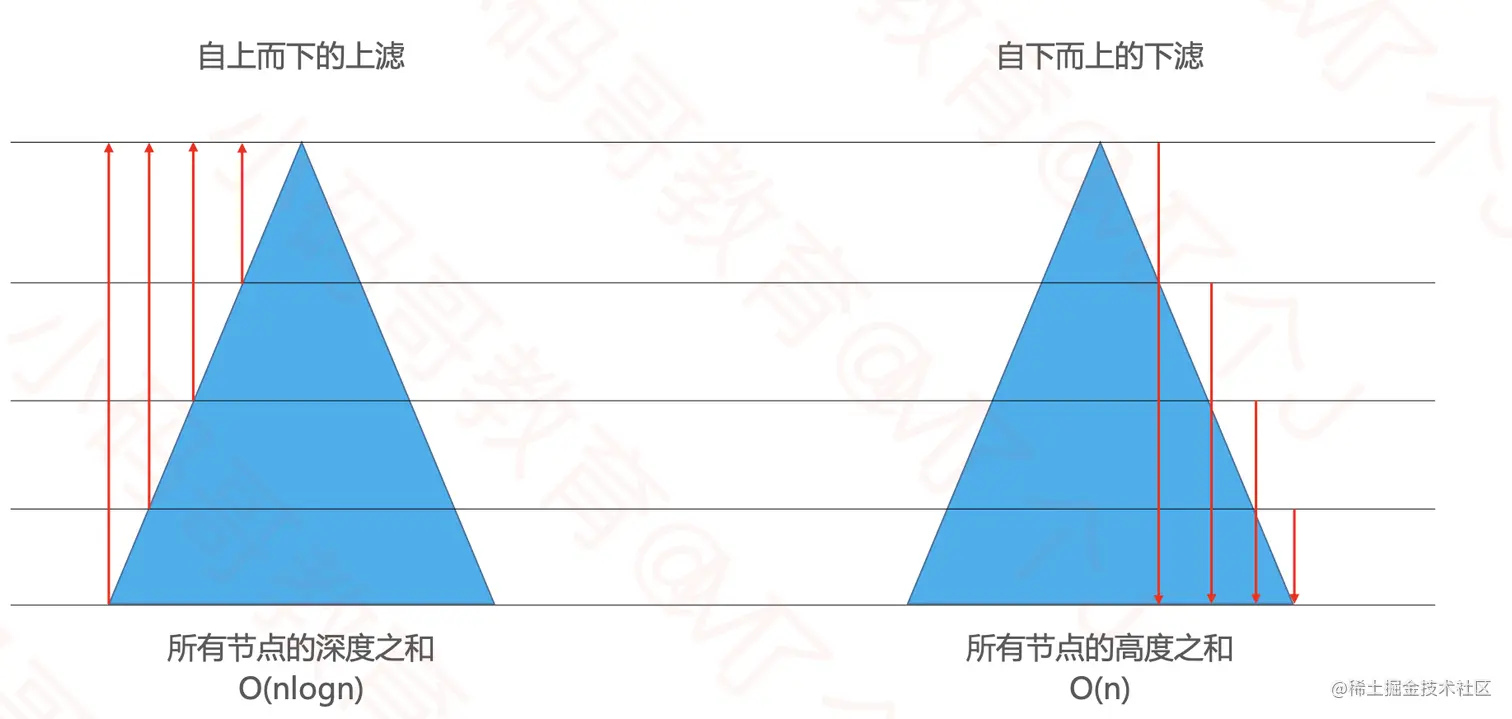
- 下滤执行最长操作的元素最少,而上滤需要执行最长操作的元素非常多。所以下滤效率更高。
四、leetcode算法题
最小K个数


