

原文:theaisummer.com/Deep-Learni…
作者:Sergios Karagiannakos
因为文章有些长,所以会分成上下两篇文章,分开发。
简介
自从 2012 年在一个图像识别比赛上,一个神经网络的性能超过人类后,深度学习就火了起来,但当时只有少数人会预料到接下来会发生什么。
在过去的十年里,有越来越多的算法面世,也有越来越多的公司开始将这些算法应用到他们的日常业务中。
本文将尝试介绍这些年里,所有重要的深度学习算法和网络结构,包括在计算机视觉和自然语言处理相关的应用中采用的算法。它们之中有的应用非常广泛,但每个算法都有各自的优缺点。
本文的主要目标是让你可以对该领域有一个通用的认识,并让你知道在不同的特定场合里应该采用哪种算法,因为有的人可能对于从零开始学习感到迷茫和困惑。在阅读完本文后,相信你一定能知道这些算法的定义以及如何使用。
目录
本文目录如下:
- 深度学习是什么?
- 神经网络(Neural Networks)
- 前向神经网络(Feedforward Neural Networks, FNN)
- 卷积神经网络(Convolutional Neural Networks, CNN)
- 循环神经网络(Recurrent Neural Networks ,RNN)
- 递归神经网络(Recursive Neural Network )
- 自动编码器(AutoEncoders)
- 深度信念网络(Deep Belief Networks)和受限制玻尔兹曼机(Restricted Boltzmann Machines)
- 生成对抗网络(Generative Adversarial Networks)
- Transformers
- 图神经网络(Graph Neural Networks)
- 基于深度学习的自然语言处理
- 词嵌入(Word Embedding)
- 序列模型(Sequence Modeling)
- 基于深度学习的计算机视觉
- 定位和目标检测(Localization and Object Detection)
- Single shot detectors(SSD)
- 语义分割(Semantic Segmentation)
- 姿势预估(Pose Estimation)
1. 深度学习是什么?
根据维基百科的定义[1]:
深度学习(也称为深度结构化学习或者微分编程)是机器学习算法这个大家庭的一个成员,它是基于人工神经网络和表示学习,并且它的学习可以是有监督的、半监督或者无监督。
在我看来,深度学习是受到人类大脑处理数据和创造用于制定决策的模式而诞生的一系列算法,并拓展和提升一个叫做人工神经网络的单模型结构。
2. 神经网络(Neural Networks)
和人类的大脑一样,神经网络[2] 也包括了很多神经元。每个神经元接受输入的信号,然后乘以对应的权重,并求和然后输入到一个非线性函数。这些神经元相互堆积在一起,并按照层进行组织。如下图左所示:
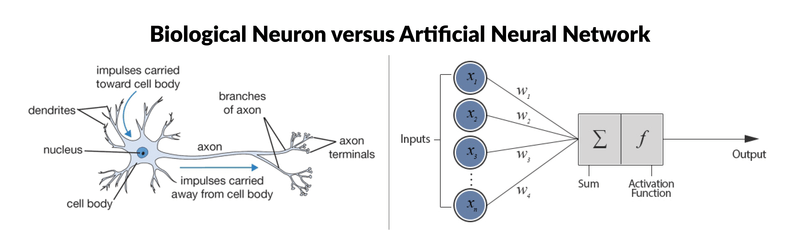
如果按照大脑神经元的方式来实现呢?结果如上图右所示,神经网络是一个优秀的函数近似者。
假设每个行为和每个系统最终都可以用一个数学函数来表示(有的可能是非常复杂的函数),如果能找到这样一个函数,我们就可以了解系统的一切,但寻找这一个函数是非常困难的,所以我们需要对神经网络进行评估。
反向传播
神经网络通过大量的数据以及**反向传播[3]**这样一个迭代算法来学习到目标函数。我们将数据传入网络中,然后它输出结果,接着我们将输出的结果和预期结果进行比较(通过一个损失函数),然后根据两者的差异来调整权重。
不断重复这个过程。调整权重的办法是通过一个非线性优化技术--随机梯度下降[4]来实现的。
在训练一段时间后,网络将可以输出非常好的结果,因此,训练到此结束。也就是说我们得到了一个近似的函数,当给网络一个未知结果的输入数据,网络会根据学习到的近似函数输出结果。
这里举个例子来更好说明这个过程。比如我们现在有个任务是需要识别带有树的图片。我们将任意类别的图片(也就是训练图片)都传给网络,然后网络会输出一个结果,因为我们已经知道图片中是否有树,所以我们只需要将网络的结果和该图片的真实类别(是否有树)进行比较,然后调整网络。
随着训练图片的增加,网络犯的错误会越来越少。现在我们可以传给网络一张未知的图片(非训练图片),然后网络会告诉我们这张图片是否包含了树。
在过去这些年里,研究人员对这个原始的想法提出了很多非常令人惊讶的改进和提升,每种新的网络结构都是对应特定的某些问题,并且得到更好的准确率和运算速度。接下来我们将逐一分类介绍这些模型。
3. 前向神经网络(Feedforward Neural Networks, FNN)
前向神经网络通常采用的都是全连接层[5],也就是说每一层的神经元都和下一层的所有神经元连接在一起。这个结构也被叫做多层感知器,最初诞生于 1958 年,如下图所示。单层的感知器只能学习到线性分离模型,但是一个多层感知器能够学习到数据之间的非线性关系。
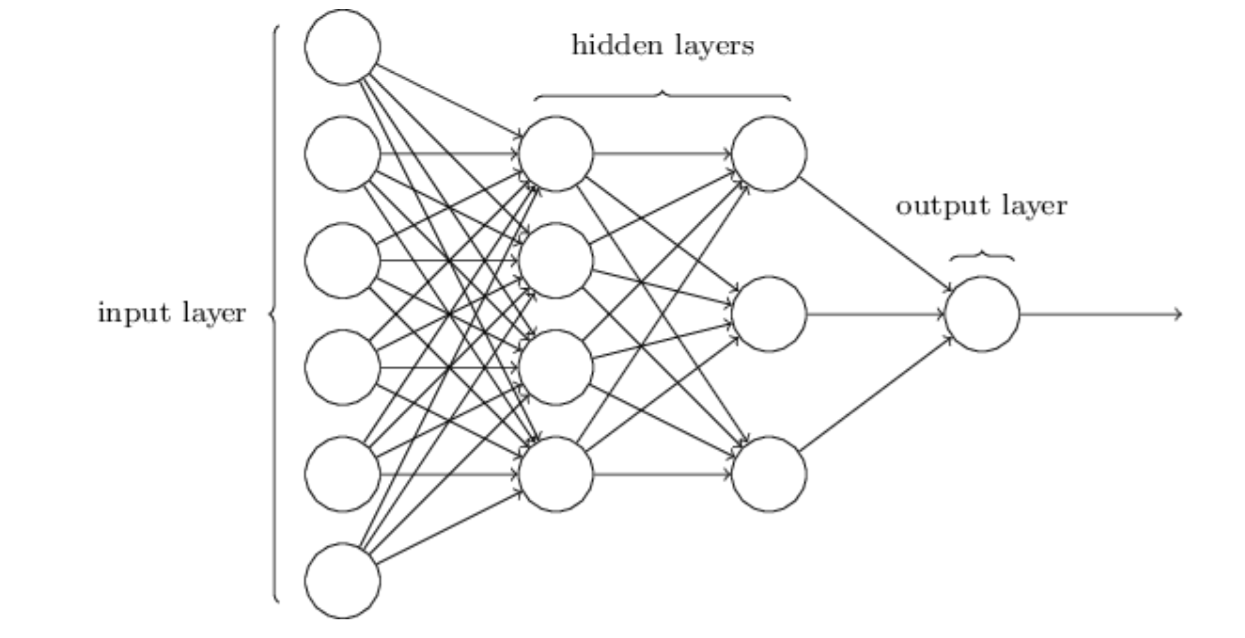
多层感知器在分类和回归任务上有不错的表现,但相比其他的机器学习算法,多层感知器并不容易收敛。另外,训练数据越多,多层感知器的准确率也越高。
4. 卷积神经网络(Convolutional Neural Networks, CNN)
卷积神经网络采用了一个卷积函数[6]。没有采用层与层之间的神经元都全部进行连接,卷积层只让两层之间部分的神经元进行连接(也就是感受野)。
在某种程度上,CNN 是尝试在 FNN 的基础上进行正则化来防止过拟合(也就是训练得到的模型泛化能力差),并且也能很好的识别数据之间的空间关系。一个简单的 CNN 的网络结构如下图所示
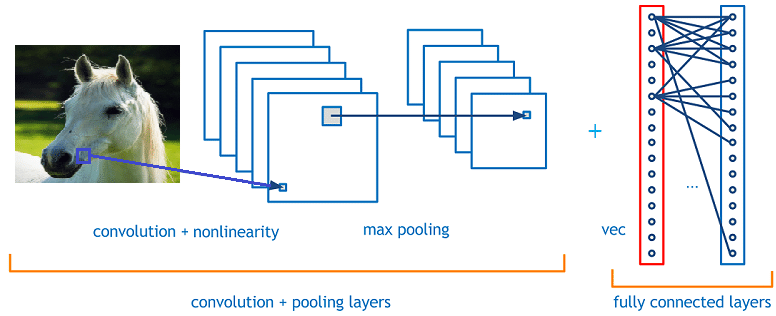
因为能够很好识别数据之间的空间关系,所以 CNN 主要用于计算机视觉方面的应用,比如图像分类、视频识别、医学图像分析以及自动驾驶[7],在这些领域上都取得超过人类的识别精度。
此外,CNN 也可以和其他类型的模型很好的结合在一起使用,比如循环神经网络和自动编码器,其中一个应用例子就是符号语言识别[8]。
5. 循环神经网络(Recurrent Neural Networks ,RNN)
循环神经网络非常适合时间相关的数据,并且应用于时间序列的预测。该网络模型会采用反馈的形式,也就是将输出返回到输入中。你可以把它看成是一个循环,从输出回到输入,将信息传递回网络,因此,网络模型具有记住历史数据并应用到预测中的能力。
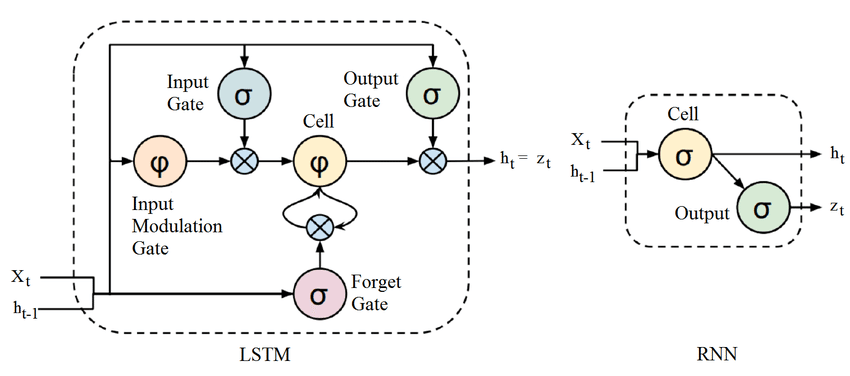
为了提高模型的性能,研究者修改了原始的神经元,创造了更复杂的结构,比如 GRU 单元[9] 和 LSTM 单元[11],分别如下图所示。LSTM 在自然语言处理的任务中应用得非常广泛,包括翻译、语音生成、从文本生成语音等。
6. 递归神经网络(Recursive Neural Network )
递归神经网络是另一种形式的循环神经网络,不同点在于递归神经网络是树状的结构,所以它可以在训练集中建模层次结构。
一般会应用在自然语言处理中的语音转文本和语义分析,因为这些任务和二叉树、上下文还有基于自然语言的分析相关联,但是递归神经网络的速度会比循环神经网络更慢。
参考
- en.wikipedia.org/wiki/Deep_l…
- karpathy.github.io/neuralnets/
- brilliant.org/wiki/backpr…
- ruder.io/optimizing-…
- theaisummer.com/Neural_Netw…
- theaisummer.com/Neural_Netw…
- theaisummer.com/Self_drivin…
- theaisummer.com/Sign-Langua…
- www.coursera.org/lecture/nlp…
- theaisummer.com/Bitcon_pred…
欢迎关注我的微信公众号--算法猿的成长,或者扫描下方的二维码,大家一起交流,学习和进步!

