

在大流量下的node方案中,如何保证最低的SLA和问题追踪效率和闭环建设,如果保证请求流量的透明化和业务操作的透明化?这里介绍下百度网盘是如何做的。
难点
- 千万级PV下的node运维
- 可用性保障,保障最低
SLA 99.98% - 问题追踪和闭环建设
- 流量透明化、操作透明化
解决方案
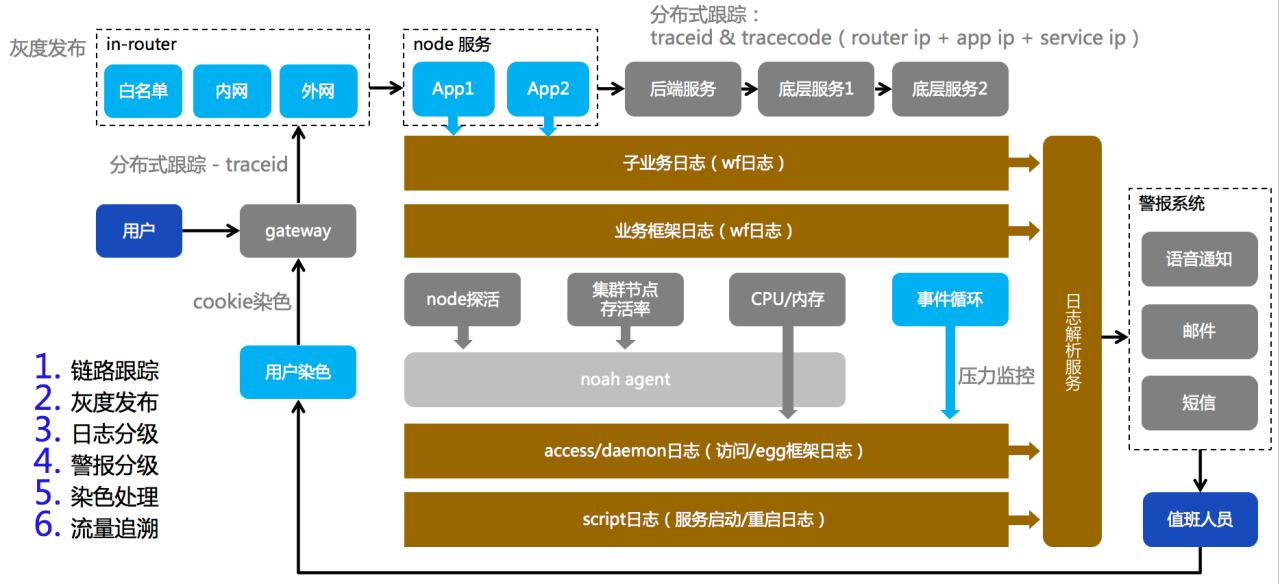
我们将整个运维方案分为了6步,我们的目的:流量透明化 与 操作透明化。
第一步:流量跟踪
为了解决微服务引起分布式流量链路问题,我们借鉴了spring cloud的思想。设计了traceid 和 tracecode两个跟踪字段,用于追踪落地容器的整个流量链路中的节点信息,通过每个请求的Response Header中的标识信息进行流量的跟踪和定位。
第二步:灰度发布
大流量下的业务必须提供灰度和AB测试的方案,结合in-router的upstream配置能力和BNS(naming service)节点,将用户流量分为白名单、内网、外部,部署级别分为单台、单边和全量,以此实现流量的控制。
名词解释:
in-router:专门为node流量进行负载处理的ngx集群
BNS:baidu naming service,通过虚拟域名的方式将IDC或集群进行逻辑编排,方便流量的定位和处理。
第三步:日志分级
整个日志系统分为4级,每一级记录不同的信息,详细记录 【什么时候、在哪儿、谁、做了什么错误、引起了什么问题】,此外还针对node还做了事件循环的lagTime监控,以此监控node服务器的压力。
日志级别:
- 业务日志
- 业务框架日志
- daemon日志
- script日志(含:环境日志)
第四步:警报分级
日志经过解析服务处理后,将数据发送给监控平台,然后再通过分级和阈值判断确实是否应该触发警报。警报手段分为:邮件、短信、电话 等。
第五步:染色处理
值班人员收到警报后从监控平台获取具体信息,如果是复杂问题,通过cookie染色,指定流量链路和操作,便可追踪定位到绝大多数的问题。
第六步:流量追溯
更好确定用户的流量走向,通过traceid和tracecode以及配合requestid,我们便可复现用户的流量走向以及内部逻辑操作。
最后:闭环建设
最后通过整合这六个步骤,使每一部分相互联结和转化,将整个链路串联在一起,从而完成运维流量透明化和操作透明化的目的
结语
总体通过这六步操作,完成了网盘的高性能node应用 和最低SLA的建设要求,以及对流量和操作的透明化要求。
本文给出node大流量下的运维方案思路,主要起抛砖引玉的作用,具体细节还需自己深入体会和理解;
它并不是一篇普适性的科普文章,所以需要一定的运维基础才可以更好地理解文章中的内容。如果你有node运维这方面的需求,那么希望这篇文章可以给你一些启发和参考。
