


1. sink概述
在使用 Flink 进行数据处理时,数据经 Data Source 流入,然后通过系列 Transformations 的转化,最终可以通过 Sink 将计算结果进行输出,Flink Data Sinks 就是用于定义数据流最终的输出位置。Flink 提供了几个较为简单的 Sink API 用于日常的开发,具体如下:
1.1 writeAsText
writeAsText() 将元素以字符串的形式逐行写入
writeAsText 用于将计算结果以文本的方式并行地写入到指定文件夹下,除了路径参数是必选外,该方法还可以通过指定第二个参数来定义输出模式,它有以下两个可选值:
- WriteMode.NO_OVERWRITE:当指定路径上不存在任何文件时,才执行写出操作;
- WriteMode.OVERWRITE:不论指定路径上是否存在文件,都执行写出操作;如果原来已有文件,则进行覆盖。
使用示例如下:
streamSource.writeAsText("D:\\out", FileSystem.WriteMode.OVERWRITE);
以上写出是以并行的方式写出到多个文件,如果想要将输出结果全部写出到一个文件,需要设置其并行度为 1:
streamSource.writeAsText("D:\\out", FileSystem.WriteMode.OVERWRITE).setParallelism(1);
1.2 writeAsCsv
writeAsCsv() 将元组以逗号分隔写入文件中,行与字段之间的分隔是可配置的。
writeAsCsv 用于将计算结果以 CSV 的文件格式写出到指定目录,除了路径参数是必选外,该方法还支持传入输出模式,行分隔符,和字段分隔符三个额外的参数,其方法定义如下:
writeAsCsv(String path, WriteMode writeMode, String rowDelimiter, String fieldDelimiter)
1.3 print \ printToErr
print \ printToErr 是测试当中最常用的方式,用于将计算结果以标准输出流或错误输出流的方式打印到控制台上。
1.4 writeUsingOutputFormat
采用自定义的输出格式将计算结果写出,上面介绍的 writeAsText 和 writeAsCsv 其底层调用的都是该方法,源码如下:
public DataStreamSink<T> writeAsText(String path, WriteMode writeMode) {
TextOutputFormat<T> tof = new TextOutputFormat<>(new Path(path));
tof.setWriteMode(writeMode);
return writeUsingOutputFormat(tof);
}
1.5 writeToSocket
writeToSocket 用于将计算结果以指定的格式写出到 Socket 中,使用示例如下:
streamSource.writeToSocket("192.168.56.102", 9999, new SimpleStringSchema());
2. Streaming Connectors
除了上述 API 外,Flink 中还内置了系列的 Connectors 连接器,用于将计算结果输入到常用的存储系统或者消息中间件中,具体如下:
- Apache Kafka (支持 source 和 sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
除了内置的连接器外,你还可以通过 Apache Bahir 的连接器扩展 Flink。Apache Bahir 旨在为分布式数据分析系统 (如 Spark,Flink) 等提供功能上的扩展,当前其支持的与 Flink Sink 相关的连接器如下:
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
2.1 kafka sink
1.在真实的项目中,kafka往往作为消息的源而存在,也可以作为实时流计算框架处理完毕之后的结果存储的目的地,使用得也很频繁。
Flink 提供了 addSink 方法用来调用自定义的 Sink 或者第三方的连接器,想要将计算结果写出到 Kafka,需要使用该方法来调用 Kafka 的生产者 FlinkKafkaProducer
2.思路梳理
a.启动kafka分布式集群
b.新建两个主题
主题1: 源主题raytekSrc 业务场景是:flume实时地从红外测温仪处采集到了旅客的信息,送往kafka该主题进行存储
主题2: 目标主题raytekTarget 业务场景: flink实时从kafka源主题中拉取数据进行计算,将计算后的结果实时落地到目标主题中存储起来
c. 代码实现
d. 测试
案例: 通过netcat模拟旅客经过红外测温仪的情形,红外测温仪将过安检的每个旅客信息依次读取到后台日志文件中存储起来,flume实时采集该日志文件中的数据,送往kafka源主题保存下来,flink拉取源主题进行实时分析计算,将体温异常的旅客信息保存到目标主题
实操
2.1.1 新建主题
[robin@node01 ~]$ kafka-topics.sh --topic raytekSrc --create --partitions 3 --replication-factor 3 --zookeeper node01:2181
Created topic "raytekSrc".
[robin@node01 ~]$
[robin@node01 ~]$ kafka-topics.sh --topic raytekTarget --create --partitions 3 --replication-factor 3 --zookeeper node01:2181
Created topic "raytekTarget".
2.1.2 编写代码
package com.jd.unbounded.sink_kafka
import java.util.Properties
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer}
/**
* @author lijun
* @create 2020-03-27
*/
object KafkaSinkTest {
def main(args: Array[String]): Unit = {
//步骤
//1.执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.从kafka中源主题中实时读取流数据,并进行后续迭代计算,筛选出体温异常的旅客信息
val props = new Properties()
props.load(this.getClass.getClassLoader.getResourceAsStream("consumer.properties"))
val exceptionDS: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("raytekSrc", new SimpleStringSchema, props))
.map(perMsg => {
val arr = perMsg.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(perTraveler => {
val temp = perTraveler.temperature
val normal = temp >= 36.3 && temp <= 37.2
!normal
}).map(_.toString)
//3.将体温异常的旅客信息保存到kafka目标主题中
exceptionDS.addSink(new FlinkKafkaProducer[String]("node01:9092","raytekTarget",new SimpleStringSchema))
//4. 启动
env.execute(this.getClass.getSimpleName)
}
}
2.1.3 先启动生产端发消息
[robin@node01 ~]$ kafka-console-producer.sh --topic raytekSrc --broker-list node01:9092
2.1.4 启动idea应用
2.1.5 启动消费端 读取flink中的数据
[robin@node01 ~]$ kafka-console-consumer.sh --topic raytekTarget --bootstrap-server node01:9092
2.1.6 测试结果
在 Kafka 生产者上发送消息到 Flink 程序

可以看到 Kafka 生成者发出的数据已经被 Flink 程序正常接收到,并经过转换后又输出到 Kafka 对应的 Topic 上。

2.2 整合kafka优化
针对这个过时的api进行优化
exceptionDS.addSink(new FlinkKafkaProducer[String]("node01:9092","raytekTarget",new SimpleStringSchema))
2.2.1 编写代码
package com.jd.unbounded.sink_kafka
import java.lang
import java.nio.charset.StandardCharsets
import java.util.Properties
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.{ProducerConfig, ProducerRecord}
/**
*
* @author lijun
* @create 2020-03-27
*/
object KafkaSinkTest2 {
def main(args: Array[String]): Unit = {
//步骤
//1.执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.从kafka中源主题中实时读取流数据,并进行后续迭代计算,筛选出体温异常的旅客信息
val props = new Properties()
props.load(this.getClass.getClassLoader.getResourceAsStream("consumer.properties"))
val exceptionDS: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("raytekSrc", new SimpleStringSchema, props))
.filter(_.nonEmpty) //处理非空的情形
.map(perMsg => {
val arr = perMsg.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(perTraveler => {
val temp = perTraveler.temperature
val normal = temp >= 36.3 && temp <= 37.2
!normal
}).map(_.toString)
//3.将体温异常的旅客信息保存到kafka目标主题中
val defaultTopic = "raytekTarget"
val serializationSchema = new KafkaSerializationSchema[String] {
/**
* 针对DataStream中的每个元素,都会调用下述方法进行序列化后,发布到kafka消息队列中存储起来
* @param element 消息的value, 红外测温仪测到的体温偏高的旅客信息
* @param timestamp
* @return
*/
override def serialize(element: String, timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte], Array[Byte]](defaultTopic,element.getBytes(StandardCharsets.UTF_8))
}
}
val producerConfig = new Properties()
producerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092")
val semantic = FlinkKafkaProducer.Semantic.EXACTLY_ONCE
exceptionDS.addSink(new FlinkKafkaProducer[String](defaultTopic,serializationSchema,producerConfig,semantic))
//4. 启动
env.execute(this.getClass.getSimpleName)
}
}
2.2.2 先启动生产端发消息
[robin@node01 ~]$ kafka-console-producer.sh --topic raytekSrc --broker-list node01:9092
2.2.3 启动idea应用
2.2.4 启动消费端 读取flink中的数据
[robin@node01 ~]$ kafka-console-consumer.sh --topic raytekTarget --bootstrap-server node01:9092
2.2.5 测试结果
在 Kafka 生产者上发送消息到 Flink 程序

可以看到 Kafka 生成者发出的数据已经被 Flink 程序正常接收到,并经过转换后又输出到 Kafka 对应的 Topic 上。

2.3 redis sink
业务流程
高铁G66到北京西站后,旅客依次出站,在出站口有红外测温仪在监测每个旅客的体温情况,若体温不在正常范围之内,进行后续处理,否则准予正常放行
技术流程
flink实用实时接收socket端发过来的数据,进行实时处理,处理完毕之后,使用redis存储起来
实现
前提:
1.准备源(socket)
2.目的地(开启redis分布式集群)
步骤:
2.3.1 导入pom依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>
2.3.2 编写代码
package com.jd.unbounded.sink_redis
import java.net.InetSocketAddress
import scala.collection.JavaConversions._
import com.jd.unbounded.Raytek
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.{FlinkJedisClusterConfig, FlinkJedisConfigBase}
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
class MyRedisMapper extends RedisMapper[Raytek]{
/**
* 用来定制保存数据的类型,一个DataStream下述方法只执行一次
* @return
*/
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET,"allTempExceptionTrallers")
}
/**
* 指定key
* @param data
* @return
*/
override def getKeyFromData(data: Raytek): String = {
data.id + data.name
}
/**
* 指定vlaue
* @param data
* @return
*/
override def getValueFromData(data: Raytek): String = {
data.toString
}
}
object RedisSinkTest {
def main(args: Array[String]): Unit = {
//步骤
//1.环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.读取源,进行处理 最后落地到redis中
val result: DataStream[Raytek] = env.socketTextStream("node01", 9999)
.filter(_.trim.nonEmpty)
.map(perLine => {
val arr = perLine.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(perTraveler => {
perTraveler.temperature < 36.3 || perTraveler.temperature > 37.2
})
//落地到redis中
val nodes:Set[InetSocketAddress] = Set(
new InetSocketAddress("node01",7000),
new InetSocketAddress("node01",7001),
new InetSocketAddress("node02",7000),
new InetSocketAddress("node02",7001),
new InetSocketAddress("node03",7000),
new InetSocketAddress("node03",7001)
)
//构建FlinkJedisClusterConfig
val flinkJedisConfigBase: FlinkJedisConfigBase = new FlinkJedisClusterConfig.Builder()
.setNodes(nodes)
.build()
val redisSinkMapper = new MyRedisMapper()
result.addSink(new RedisSink[Raytek](flinkJedisConfigBase,redisSinkMapper))
//3.启动
env.execute()
}
}
2.4 elasticsearch sink
2.4.1 业务及技术流程介绍
业务:
高铁G66到站了,旅客顺次经过出口,出口处的红外测温仪监测每个旅客的体温,若是异常,需要单独处理
技术:
红外测温仪实时监测数据,将数据落地到日志文件中,flume实时采集到kafka,flink实时流应用拉取数据,进行计算,将体温异常的旅客信息存储到es中,使用kibana读取es中存储的体温异常的旅客信息,进行图表的绘制
2.4.2 实施思路梳理
前提:
1.准备数据源(kafka)
2.准备目的地 (es)
步骤
1.导入依赖
<!-- flink es-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
2.编写源码
2.4.3 代码实现
注意: ElasticsearchSink为每个批次请求设置要缓冲的最大操作数,builder.setBulkFlushMaxActions(1),flink处理积攒了多少条数据,然后一起向es发过去,如果不设置数据不能正常落地到es
package com.jd.unbounded.sink_es
import java.util.Properties
import com.jd.unbounded.Raytek
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.http.HttpHost
import org.elasticsearch.client.Requests
import scala.collection.JavaConversions._
/**
* @author lijun
* @create 2020-03-28
*/
object ESSinkTest2 {
def main(args: Array[String]): Unit = {
//1.执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.读取源,进行处理
val props = new Properties()
props.load(this.getClass.getClassLoader.getResourceAsStream("consumer.properties"))
val result: DataStream[Raytek] = env.addSource(new FlinkKafkaConsumer[String]("raytekSrc",new SimpleStringSchema(),props))
.filter(_.trim.nonEmpty)
.map(perLine => {
val arr = perLine.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(perTraveler => perTraveler.temperature < 36.3 || perTraveler.temperature > 37.2)
//落地到es中
val httpHosts:List[HttpHost] = List(
new HttpHost("node01",9200),
new HttpHost("node02",9200),
new HttpHost("node03",9200)
)
val elasticsearchSinkFunction:ElasticsearchSinkFunction[Raytek] = new MyESSinkFunction()
//构建builder实例
val builder: ElasticsearchSink.Builder[Raytek] = new ElasticsearchSink.Builder[Raytek](httpHosts,elasticsearchSinkFunction)
//ElasticsearchSink为每个批次请求设置要缓冲的最大操作数
builder.setBulkFlushMaxActions(1)
//构建ElasticsearchSink实例
val esSink: ElasticsearchSink[Raytek] = builder.build()
result.addSink(esSink)
//3. 启动
env.execute(this.getClass.getSimpleName)
}
/**
* 自定义ElasticsearchSinkFunction 特质实现类,用来向es中存入计算后的数据
*/
class MyESSinkFunction extends ElasticsearchSinkFunction[Raytek]{
/**
* 当前DataStream中每流动一个元素,下述方法就触发执行一次
* @param element
* @param ctx
* @param indexer
*/
override def process(element: Raytek, ctx: RuntimeContext, indexer: RequestIndexer): Unit = {
//将当前的Raytek实例中的信息封装到Map中
val scalamap = Map[String,String](
"id"->element.id.trim,
"temperature"->element.temperature.toString.trim,
"name"->element.name.trim,
"timestamp"->element.timestamp.toString.trim,
"Location"->element.Location.trim
)
val javaMap:java.util.Map[String,String] = scalamap
//构建indexRequest实例
val indexRequest = Requests.indexRequest()
.index("raytek")
.`type`("traveller")
.id(s"${element.id.trim}-->${element.name.trim}")
.source(javaMap)
//存储
indexer.add(indexRequest)
}
}
}
3. 自定义Sink
除了使用内置的第三方连接器外,Flink 还支持使用自定义的 Sink 来满足多样化的输出需求。想要实现自定义的 Sink ,需要直接或者间接实现 SinkFunction 接口。通常情况下,我们都是实现其抽象类 RichSinkFunction,相比于 SinkFunction ,其提供了更多的与生命周期相关的方法。两者间的关系如下:
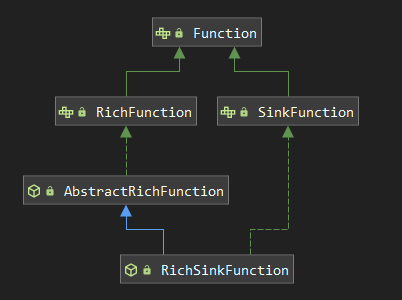
3.1 业务说明
将体温异常的旅客信息经由flink实时处理,将结果落地到mysql中存储起来
3.2 步骤
3.2.1 前提
mysql db server要启动,及创建结果表(t_raytek_result)
# 创建结果表
create table t_raytek_result(
id VARCHAR(20),
temperature NUMERIC(8,4),
`name` VARCHAR(30),
`timestamp` LONG,
location VARCHAR(50),
constraint pk PRIMARY KEY(id,`name`)
);
3.2.2 导入mysql依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
3.2.3 代码实现
package com.jd.unbounded.sink_self
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.api.scala._
import com.jd.unbounded.Raytek
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
/**
* @author lijun
* @create 2020-03-29
*/
object SelfDefineSinkTest {
def main(args: Array[String]): Unit = {
//1.执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.读取源,进行处理
val result: DataStream[Raytek] = env.socketTextStream("localhost", 9999)
.filter(_.trim.nonEmpty)
.map(perLine => {
val arr = perLine.split(",")
val id = arr(0).trim
val temperature = arr(1).trim.toDouble
val name = arr(2).trim
val timestamp = arr(3).trim.toLong
val location = arr(4).trim
Raytek(id, temperature, name, timestamp, location)
}).filter(perTraveler => perTraveler.temperature < 36.3 || perTraveler.temperature > 37.2)
//落地到mysql中
result.addSink(new FlinkToMySQLSink())
//启动
env.execute(this.getClass.getSimpleName)
}
//自定义sink类
class FlinkToMySQLSink extends RichSinkFunction[Raytek]{
//连接
var conn:Connection = _
var insertOrUpdateStatement:PreparedStatement = _
//针对于一个DataStream, 下述的方法只会执行一次,用来进行初始化的动作
override def open(parameters: Configuration): Unit = {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/flink?useUnicode=true&characterEncoding=utf-8&useSSL=false","root","root")
insertOrUpdateStatement = conn.prepareStatement("insert into t_raytek_result values(?,?,?,?,?) on duplicate key update temperature=?, `timestamp`=?,location=? ")
}
/**
* 每次处理DataStream中的一个元素,下述的方法就执行一次
* @param value 当前待处理的元素
* @param context 上下文信息
*/
override def invoke(value: Raytek, context: SinkFunction.Context[_]): Unit = {
//步骤
//进行更新,
//给用于插入的占位符赋值
insertOrUpdateStatement.setString(1,value.id)
insertOrUpdateStatement.setDouble(2,value.temperature)
insertOrUpdateStatement.setString(3,value.name)
insertOrUpdateStatement.setLong(4,value.timestamp)
insertOrUpdateStatement.setString(5,value.Location)
//给用于更新的占位符赋值
insertOrUpdateStatement.setDouble(6,value.temperature)
insertOrUpdateStatement.setLong(7,value.timestamp)
insertOrUpdateStatement.setString(8,value.Location)
//执行 将sql语句传给远程的db server, dbserver会自动进行判断,若存在就更新,否则执行插入
insertOrUpdateStatement.executeUpdate()
}
//下述的方法就执行一次,用来进行资源的释放
override def close(): Unit = {
if(insertOrUpdateStatement != null){
insertOrUpdateStatement.close()
}
if(conn != null){
conn.close()
}
}
}
}
3.2.4 实时数据输入

3.2.5 测试结果
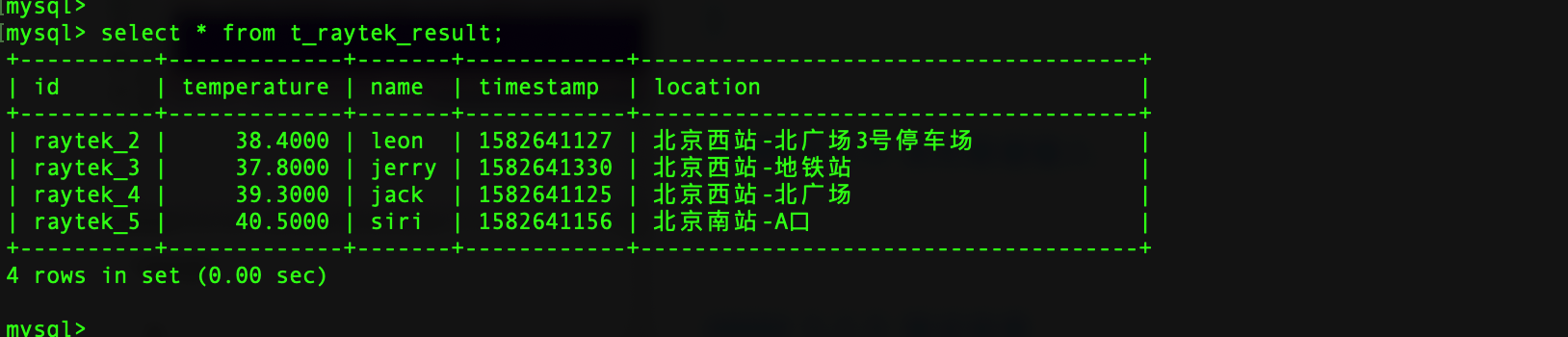
数据库成功写入,代表自定义 Sink 整合成功。
