

- 原文地址:8 Useful Tree Data Structures Worth Knowing
- 原文作者:Vijini Mallawaarachchi
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Amberlin1970
- 校对者:PingHGao, Jiangzhiqi4551
8 个值得了解的树形数据结构
对于一棵树你会想到什么呢?树根、分支和树叶?一个有树根、分支和树叶的大橡树可能会在你脑海浮现。相似地,在计算机科学中,树形数据结构有根部、分支和树叶,但它是自上而下的。树是一种层级数据结构,以表达不同节点之间的关系。在这篇文章中,我将会简要地给你介绍 8 种树形数据机构。
树的属性
- 树可以没有节点也可以包含一个特殊的节点根节点,该根节点可以包含零或多棵子树。
- 树的每条边都直接或间接地源于根节点。
- 每个孩子节点只有一个父节点,但每个父节点可以有很多孩子节点。
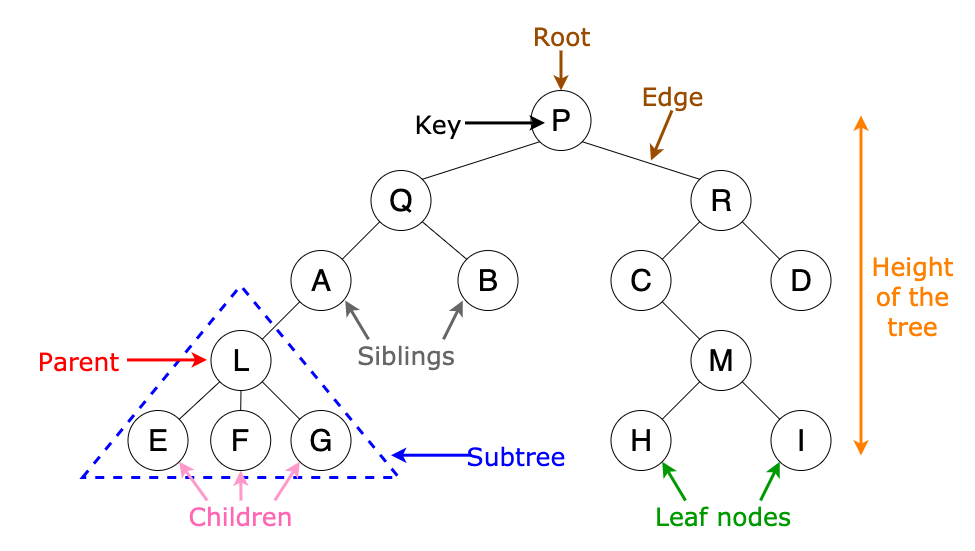
在这篇文章中,我将会简要地解释下面 8 种树形数据结构及它们的用途。
- 普通树
- 二叉树
- 二叉搜索树
- AVL树
- 红黑树
- 伸展树
- 树堆
- B树
1. 普通树
普通树是一种在层级结构上无限制的树形数据结构。
属性
- 遵循树的属性。
- 一个节点可以有任意数量的孩子。
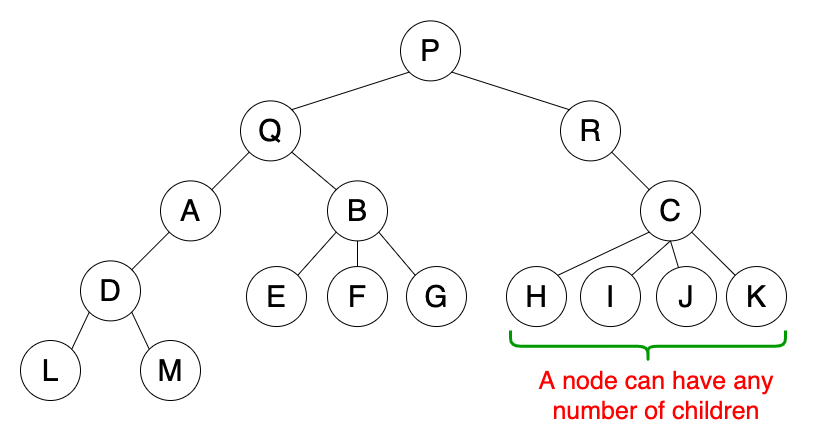
用途
- 用于存储如文件结构类的层级数据。
2. 二叉树
二叉树是一种有如下属性的树形数据结构。
属性
- 遵循树的属性。
- 一个节点至多有两个孩子。
- 这两个孩子分别称为左孩子和右孩子。
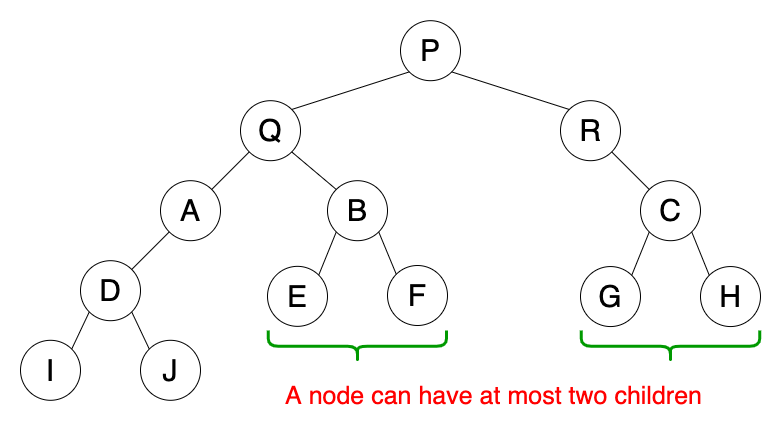
用途
- 在编译器中用于构造语法树。
- 用于执行表达式解析和表达式求解。
- 路由器中用于存储路由器表。
3. 二叉搜索树
二叉搜索树是二叉树的一种更受限的扩展。
属性
- 遵循二叉树的属性。
- 有一个独特的属性,称作二叉搜索树属性。这个属性要求一个给定节点的左孩子的值(或键)应该小于或等于父节点的值,而右孩子的值应该大于或等于父节点的值。
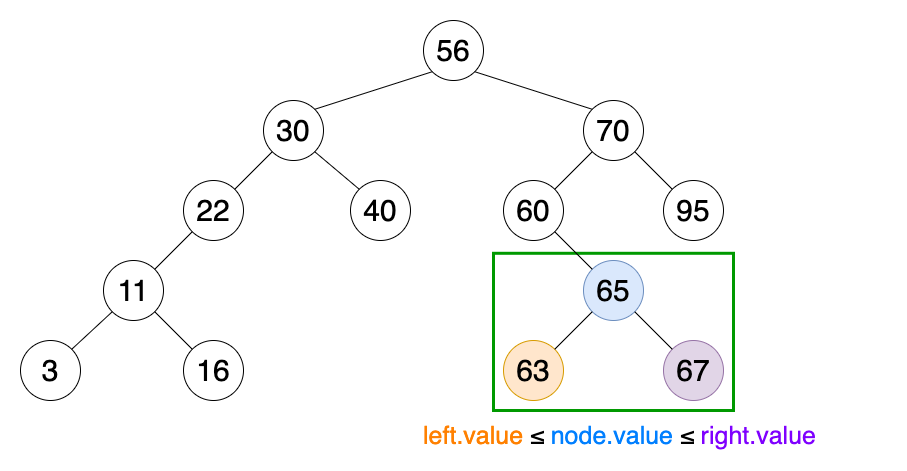
用途
- 用于执行简单的排序算法。
- 可以用作优先队列。
- 适用于数据持续进出的很多搜索应用中。
4. AVL树
平衡二叉树是一种自我平衡的二叉搜索树。这是介绍的第一种自动平衡高度的树。
属性
- 遵循二叉搜索树的属性。
- 自平衡。
- 每一个节点储存了一个值,称为一个平衡因子,即为其左子树和右子树的高度差。
- 所有的节点都必须有一个平衡因子且只能是 -1、0 或 1。
在进行插入或是删除后,如果有一个节点的平衡因子不是 -1、0 或 1,就必须通过旋转来平衡树(自平衡)。你可以在我前面的文章 这里 阅读到更多的旋转操作。
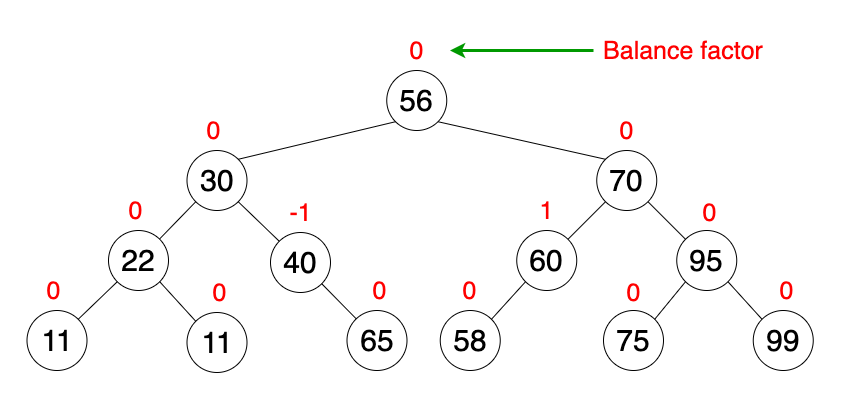
用途
- 用于需要频繁插入的情况。
- 在 Linux 内核的内存管理子系统中用于在抢占期间搜索进程的内存区域。
5. 红黑树
红黑树是一种自平衡的二叉搜索树,每一个节点都有一种颜色:红或黑。节点的颜色用于确保树在插入和删除时保持大致的平衡。
属性
- 遵循二叉搜索树的属性。
- 自平衡。
- 每个节点或是红色或是黑色。
- 根节点是黑色(有时省略)。
- 所有叶子(标注为 NIL)是黑色。
- 如果一个节点是红色,那它的孩子都是黑色。
- 从一个给定的节点到其任意的叶子节点的每条路径都必须经过相同数目的黑色节点。
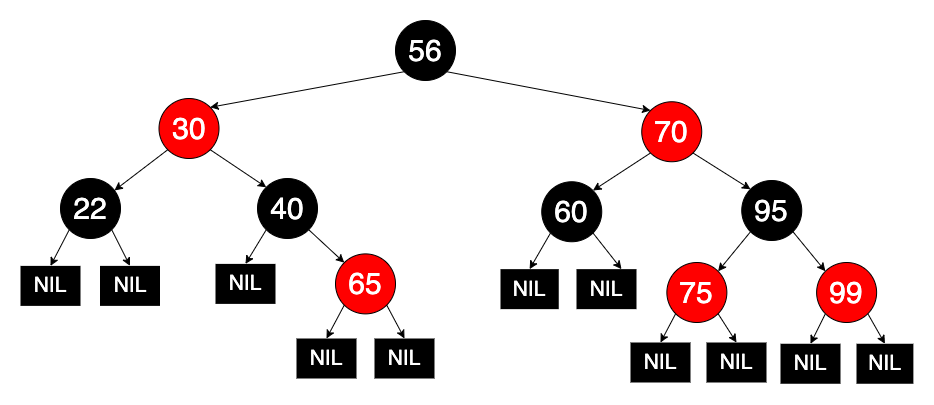
用途
- 在计算几何中作为数据结构的基础。
- 用于现在的 Linux 内核的完全公平调度算法中。
- 用于 Linux 内核的 epoll 系统中。
6. 伸展树
伸展树是一种自平衡的二叉搜索树。
属性
- 遵循二叉搜索树的属性。
- 自平衡。
- 近期获取过的元素再次获取时速度更快。
在搜索、插入或是删除后,伸展树会执行一个动作,称为伸展,在执行伸展动作时,树会被重新排列(使用旋转)将特定元素放置在树的根节点。
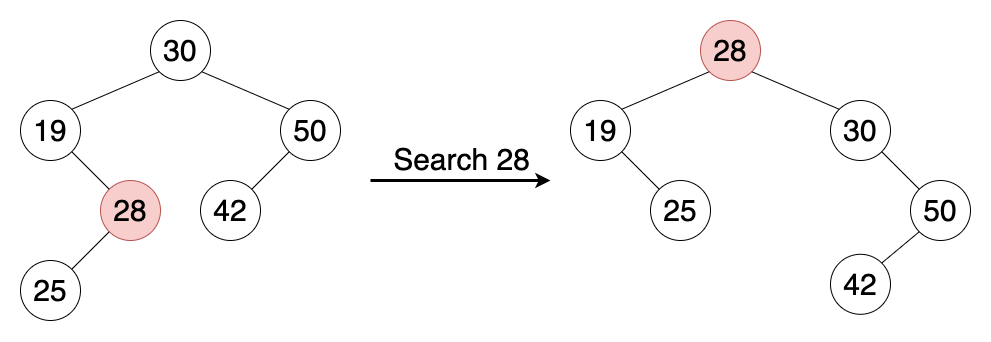
用途
- 用于实现缓存。
- 用在垃圾收集器中。
- 用于数据压缩。
7. 树堆
树堆(名字来源于树和堆的结合)是一种二叉搜索树。
属性
- 每个节点有两个值:一个键和一个优先级。
- 键遵循二叉搜索树的属性。
- 优先级(随机值)遵循堆的属性。
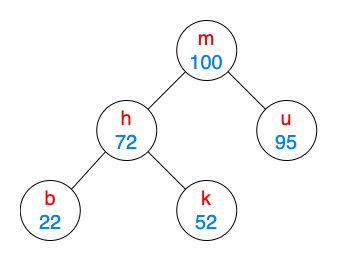
用途
- 用于维护公钥密码系统中的授权证书。
- 可以用于执行快速的集合运算。
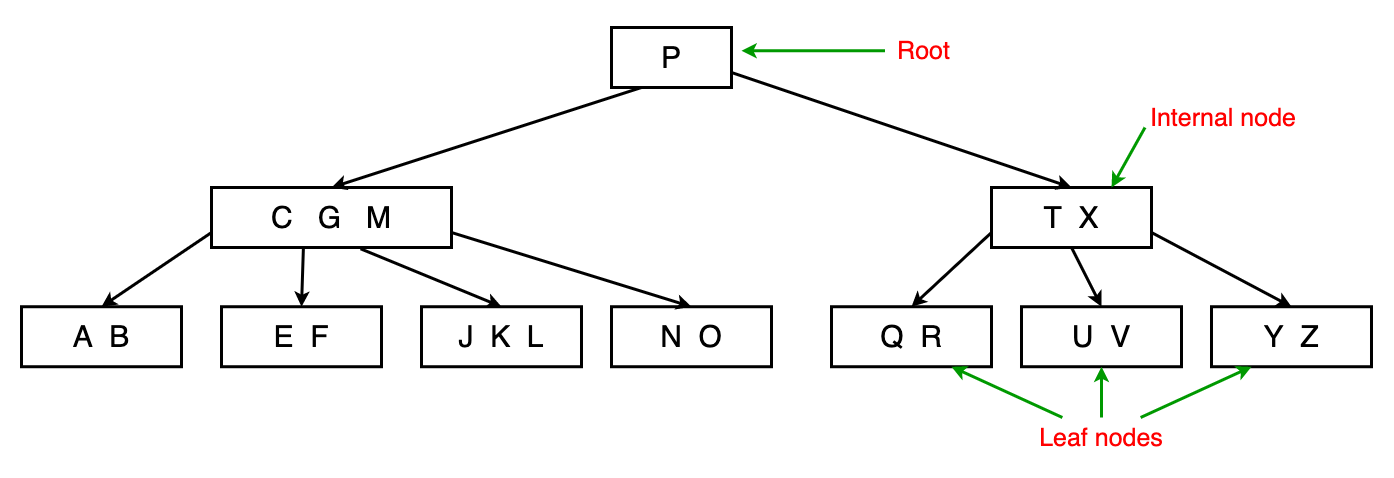
8. B树
B树是一种自平衡的搜索树,而且包含了多个排过序的节点。每个节点有 2 个或多个孩子且包含多个键。
属性
- 每个节点 x 有如下(属性):
- x.n(键的数量)
- x.keyᵢ(键以升序存储)
- x.leaf(x 是否是一个叶子)
- 每个节点 x 有(x.n + 1)孩子。
- 键 x.keyᵢ 分割了存储在每个子树中键的范围。
- 所有的叶子有相等的深度,即为树的高度。
- 节点有存储的键的数量的上界和下界。这里我们考虑一个值 t≥2,称为 B树的最小度(或分支因子)。
- 根节点必须至少有一个键。
- 每个其余节点必须有至少(t - 1)个键和至多(2t - 1)个键。因此,每个节点将会有至少 t 个孩子和至多 2t 个孩子。如果一个节点有(2t - 1)个键,我们称这个点是满的。
用途
- 用于数据库索引以加速搜索。
- 在文件系统中用于实现目录。
最后的思考
数据结构操作的时间复杂度的备忘录可以在这个链接找到。
我希望这篇文章作为一个对树形结构的简单介绍对你是有用的。我很乐意听你的想法。😇
非常感谢阅读!
祝愉快! 😃
参考
- [1] 算法导论(第三版),作者:Thomas H.Cormen / Charles E.Leiserson / Ronald L.Rivest / Clifford Stein.
- [2] en.wikipedia.org/wiki/List_o…
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接* 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
