1. Flink 介绍
Flink是对无界和有界流数据进行处理的分布式计算框架
1.1 如何学习Flink
- 官网
https://flink.apache.org/
- 官方的案例
- 国内关于flink的权威平台
https://ververica.cn/
- 源码
https://github.com/apache/flink
1.2 Flink1.9 跟之前的版本有什么区别?
之前离线处理和实时处理是两套api处理的,1.9使用的是统一的流式api来处理的
1.3 Flink核心计算框架
Flink的核心计算架构是Flink Runtime执行引擎,它是一个分布式系统,能够接受数据流程序并在一台或多台机器上以容错方式执行。Flink Runtime执行引擎可以作为YARN(Yet Another Resource Negotiator)的应用程序在集群上运行,也可以在Mesos集群上运行,还可以在单机上运行(这对于调试Flink应用程序来说非常有用)。
Flink分别提供了面向流式处理的接口(DataStream API)和面向批处理的接口(DataSet API)。因此,Flink既可以完成流处理,也可以完成批处理。Flink支持的拓展库涉及机器学习(FlinkML)、复杂事件处理(CEP)、以及图计算(Gelly),还有分别针对流处理和批处理的Table API。Flink 是一个真正的流批结合的大数据计算框架,将大数据背景下的计算统一整合在一起,不仅降低了学习和操作难度,也有效实现了离线计算和实时计算的大一统
2. Flink开发环境搭建
2.1 安装scala插件
Flink 分别提供了基于 Java 语言和 Scala 语言的 API ,如果想要使用 Scala 语言来开发 Flink 程序,可以通过在 IDEA 中安装 Scala 插件来提供语法提示,代码高亮等功能。打开 IDEA , 依次点击 File => settings => plugins 打开插件安装页面,搜索 Scala 插件并进行安装,安装完成后,重启 IDEA 即可生效。
2.2 使用idea构建工程
2.2.1 新建maven工程 flink-learning
2.2.2 添加依赖
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.main.version>2.11</scala.main.version>
<flink.version>1.9.1</flink.version>
<hadoop.version>2.7.5</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Test-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.1</version>
<scope>test</scope>
</dependency>
<!-- hdfs-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- flink-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink kafka-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink table &sql-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- lombok是一个用于简化pojo类书写方式的库,可使用一些注解的方式代替实体类中的代码-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
<version>1.16.18</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.6</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>
2.2.3 添加log4j.properties文件
log4j.rootLogger=INFO,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
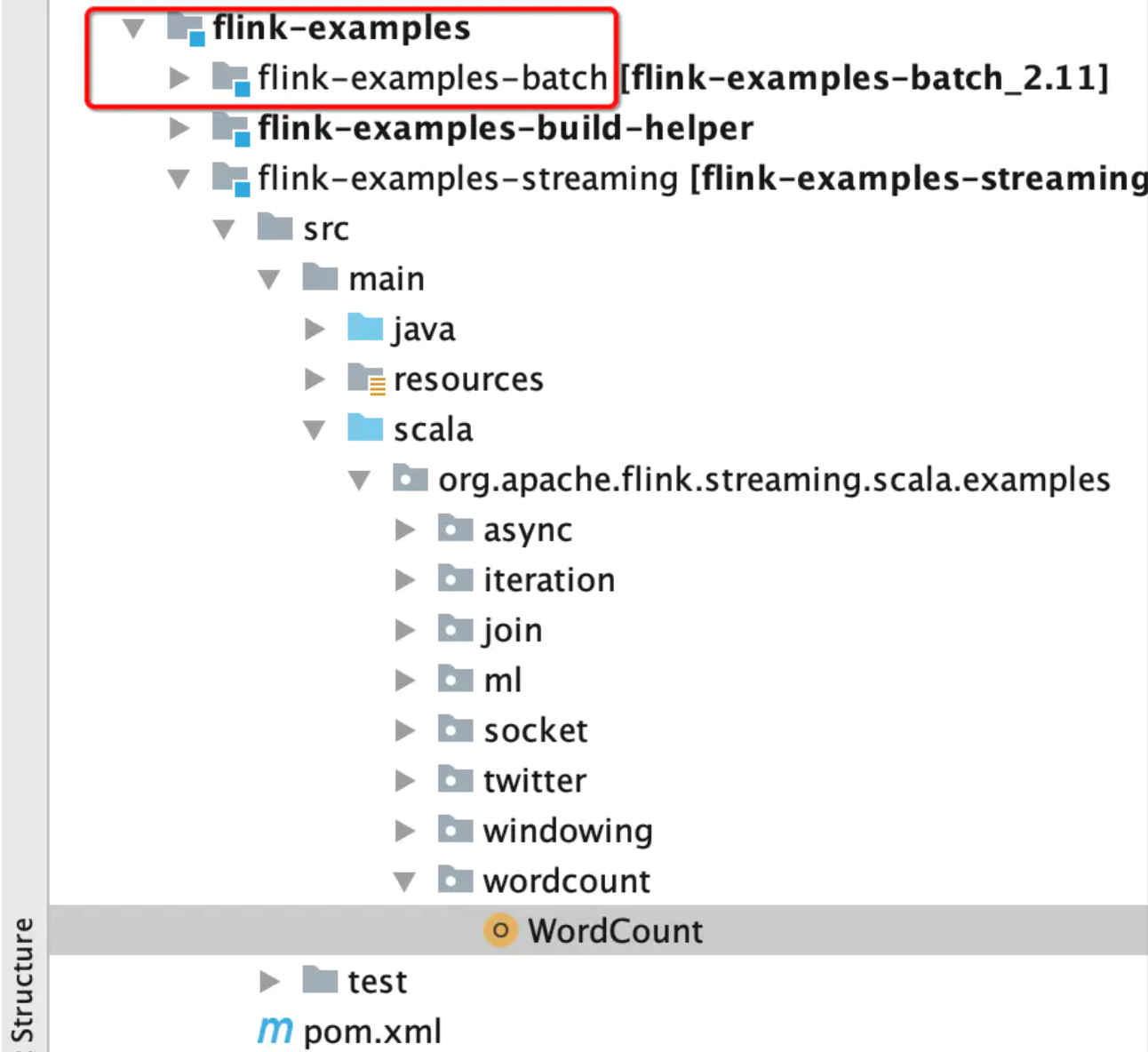
2.2.4 项目结构
3.词频统计案例
项目创建完成后,可以先书写一个简单的词频统计的案例来尝试运行 Flink 项目,以下以 Scala 语言为例,分别介绍流处理程序和批处理程序的编程示例:
3.1 关于有界流的处理
需求:计算指定目录下所有文件中单词出现的次数
涉及到哪些API
ExecutionEnvironment 用于获得执行的环境
导入相应的隐式的成员:
DataSet相应的api
flapMap
filter
map
sum等等
3.1.1 情形1: 源和目的地都在本地
package com.jd.bounded.local
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object BoundedFlowTest {
def main(args: Array[String]): Unit = {
//1. 执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2. 计算 保存结果
env.readTextFile("/Users/lijun/Downloads/flink_input/")
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty)
.map((_,1))
.groupBy(0)
.sum(1)
.print()
}
}

3.1.2 情形2: 源在hdfs之上,目的地在本地
package com.jd.bounded.hdfs_local
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object BoundedFlowTest {
def main(args: Array[String]): Unit = {
//1. 执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2. 计算 保存结果
env.readTextFile("hdfs://node01:9000/flink/input")
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty)
.map((_,1))
.groupBy(0)
.sum(1)
.print()
}
}
3.1.3 情形3: 源在本地上,目的地在hdfs
package com.jd.bounded.local_hdfs
import org.apache.flink.core.fs.FileSystem
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object BoundedFlowTest {
def main(args: Array[String]): Unit = {
//1. 执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2. 计算 保存结果
env.readTextFile("/Users/lijun/Downloads/flink_input/")
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty)
.map((_,1))
.groupBy(0)
.sum(1)
.writeAsText("hdfs://node01:9000/flink/output/result.txt", FileSystem.WriteMode.OVERWRITE)
//3. 执行提交
env.execute(this.getClass.getSimpleName)
}
}
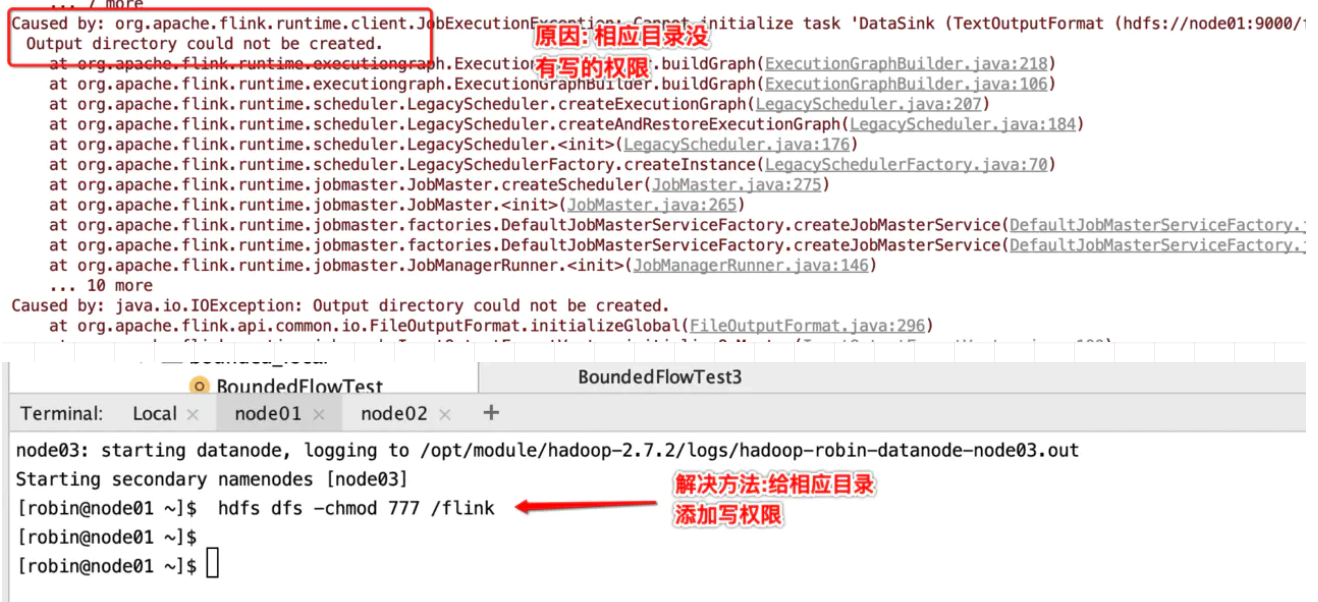
重新运行一下
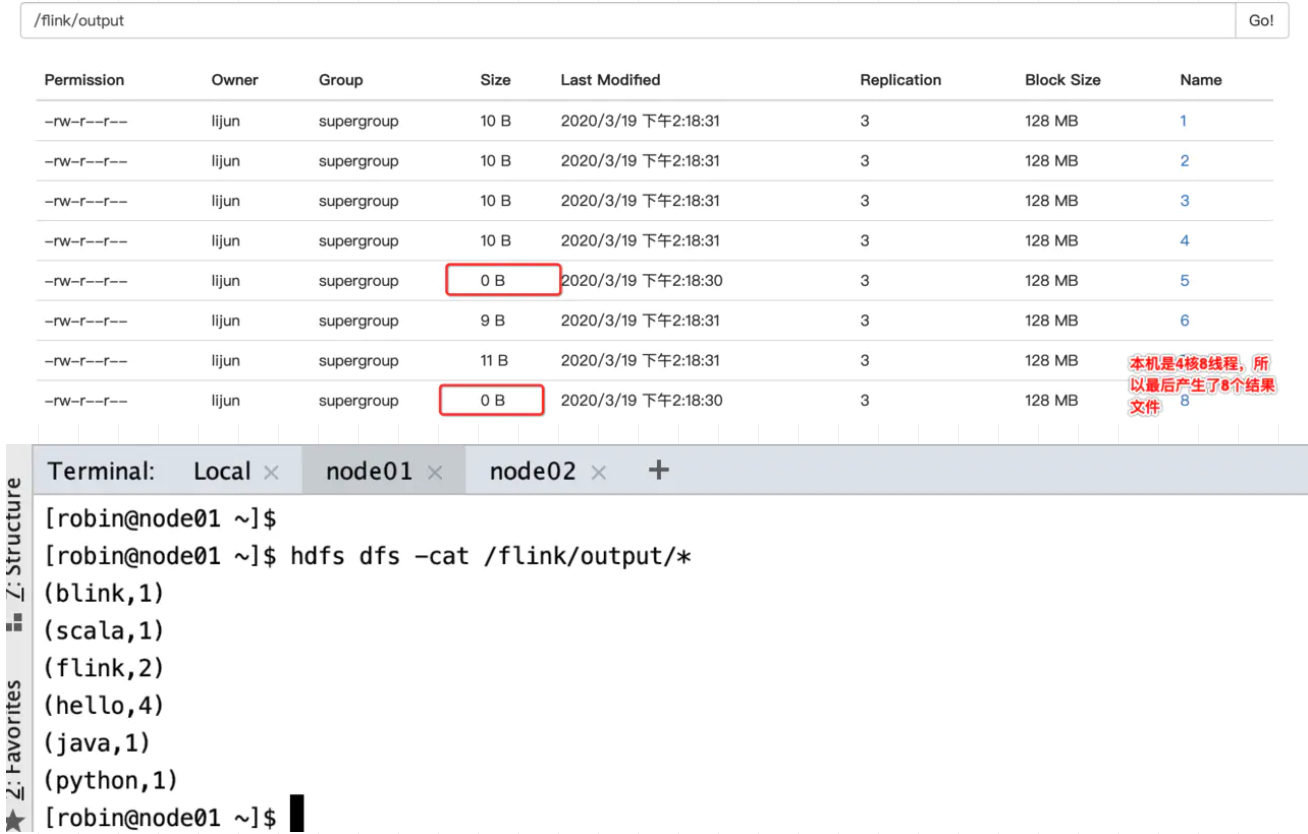
并行度的设置
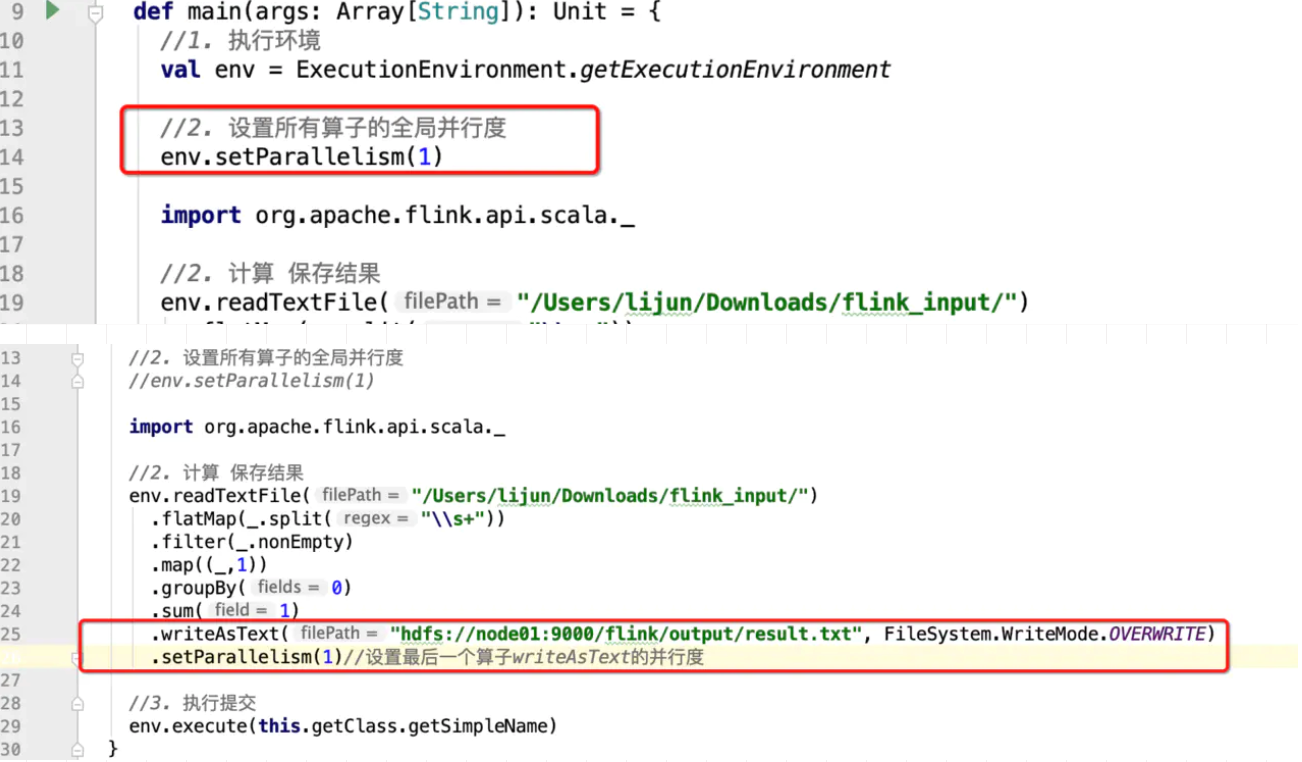
结果
3.1.4 情形4: 源在hdfs上,目的地也在hdfs(在生产环境下采取此种方式)
package com.jd.bounded.hdfs_hdfs
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.core.fs.FileSystem
import org.apache.flink.api.scala._
/**
* Description: 计算指定目录下所有文件中单词出现的次数(源->hdfs, 目的地->hdfs 且源和目的地需要动态传入)
* @author lijun
* @create 2020-03-19 15:34
*/
object BoundedFlowTest {
def main(args: Array[String]): Unit = {
//拦截非法参数
if(args == null || args.length != 4){
println("请录入参数!--input<源path> --output<目的地的path>")
sys.exit(-1)
}
val tool = ParameterTool.fromArgs(args)
val inputPath = tool.get("input")
val outputPath = tool.get("output")
//1. 执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
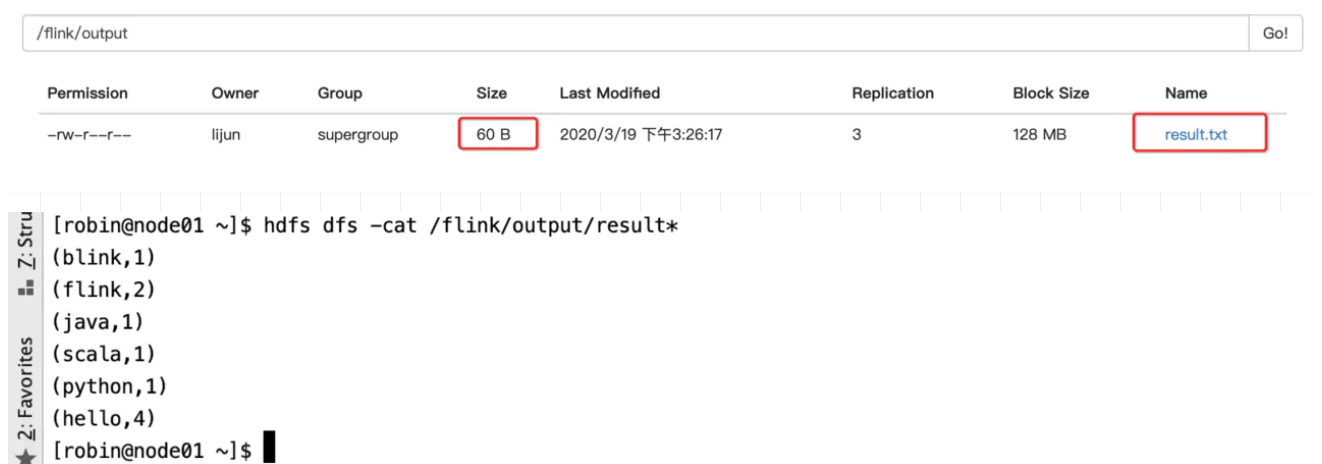
//2. 设置所有算子的全局并行度
//env.setParallelism(1)
//2. 计算 保存结果
env.readTextFile(inputPath)
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty)
.map((_,1))
.groupBy(0)
.sum(1).setParallelism(2)
.writeAsText(outputPath, FileSystem.WriteMode.OVERWRITE)
.setParallelism(1)//设置最后一个算子writeAsText的并行度
//3. 执行提交
env.execute(this.getClass.getSimpleName)
}
}
结果
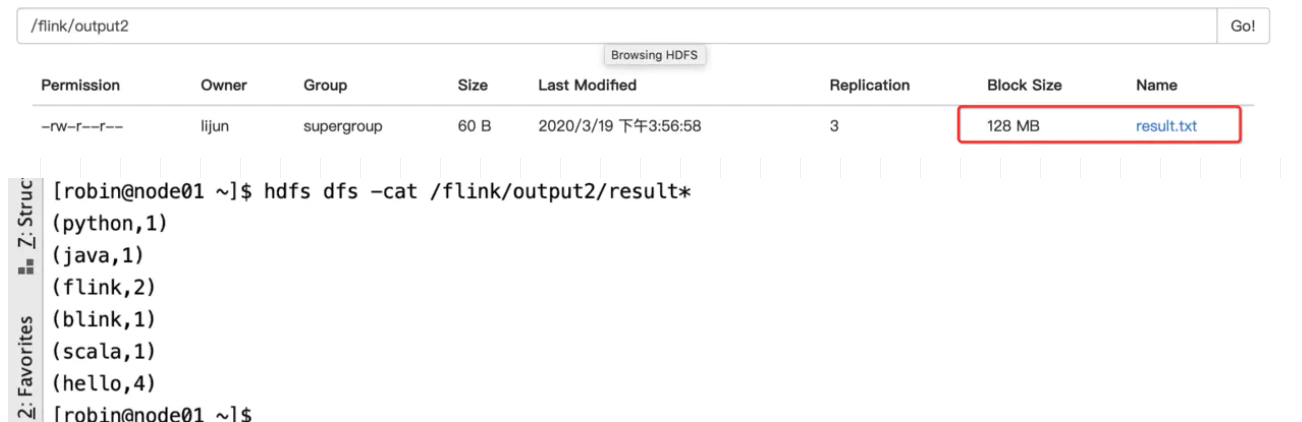
3.2 关于无界流的处理
3.2.1 介绍
1.对应的API:
StreamExecutionEnvironment 封装了无界流计算使用到的环境信息
DataStream 是flink生态中进行无界流数据计算的核心api
DataStream下的常用的算子有:
flatMap
keyBy
sum
2.需求使用flink无界流处理实时监控netcat客户端和服务器交互的数据,进行实时的计算,将计算后的结果显示出来
代码实现
package com.jd.unbounded.wordcount
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
/**
* 使用flink无界流处理实时监控netcat客户端和服务器交互的数据,进行实时的计算,将计算后的结果显示出来
* @author lijun
* @create 2020-03-19
*/
object UnboundedFlowTest {
def main(args: Array[String]): Unit = {
//拦截非法参数
if(args == null || args.length != 4){
println("警告!应该传入参数 --hostname<主机名> --port<端口号>")
sys.exit(-1)
}
//获得参数
val tool = ParameterTool.fromArgs(args)
val hostname = tool.get("hostname")
val port = tool.getInt("port")
//执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//计算
env.socketTextStream(hostname,port)
.flatMap(_.split("\\s+"))
.filter(_.nonEmpty).map((_,1))
.keyBy(0)
.sum(1)
.print()
// 启动
env.execute(this.getClass.getSimpleName)
}
}
配置参数
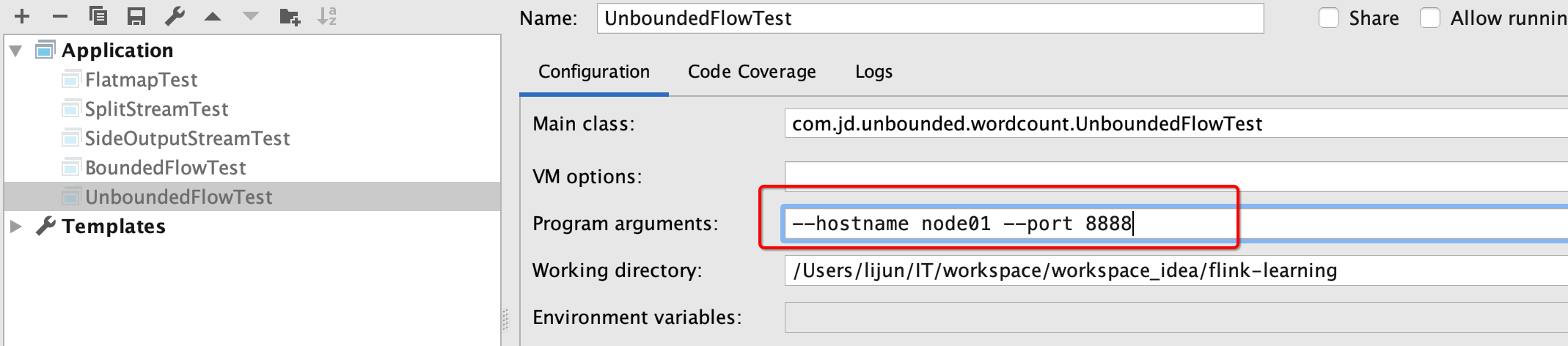
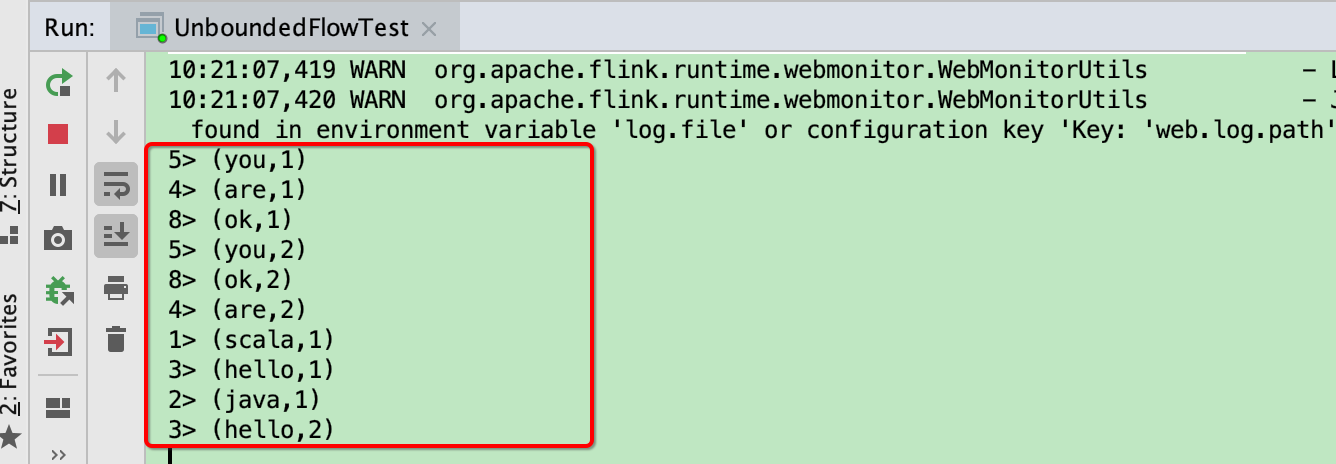
我在终端一个个输入下面的字符串
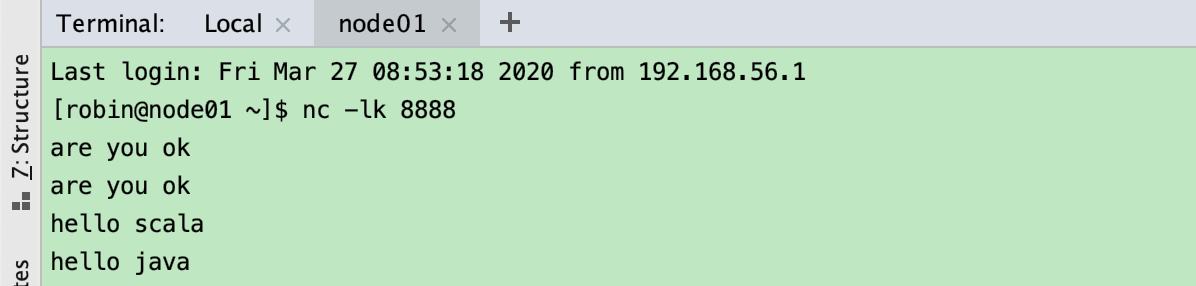
然后在 IDEA 的控制台中会将运行结果一个个输出来:
运行结果如下图: