

我们在Vue中会使用一些变量,表达式,指令来填充模板,但是这些语法在HTML中是不存在的,那么Vue是如何对这样的模板进行编译的呢?
模板编译
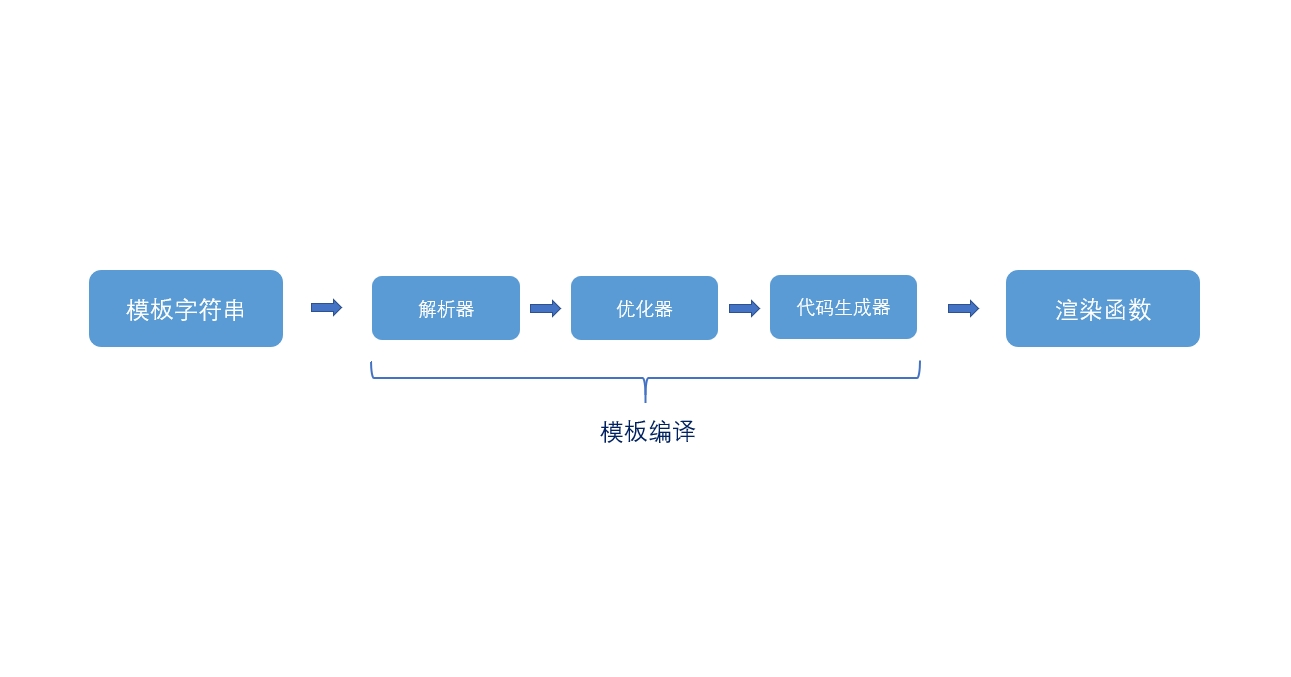
模板编译的主要作用是将Vue模板编译为渲染函数,首先将模板解析成AST(抽象语法树),然后使用AST生成渲染函数。
首先我们要知道Vue每次渲染,都会生成一份新的vNode与旧的vNode进行对比,在生成渲染函数之前还会遍历一遍AST,为所有的静态节点做一个编辑,在重新渲染时,不会生成新得节点,而是直接克隆已存在的之前的静态节点。
所以总体过程是:将模板解析成AST=>遍历AST标记静态节点=>使用AST生成渲染函数。
模板解析成AST
在这一步骤中,需要经过解析器将模板解析AST,然后还需要经过优化器,遍历AST找出静态节点并标记。
解析器
在解析器内部还分成了文本解析器,HTML解析器和过滤器解析器。
其中核心部分是HTML解析器,作用是用来解析字符串模板。变量解析器用于解析带有模板的文本变量,而不带用变量的文本节点就是刚才所说的静态节点,不需要解析。过滤器解析器用来解析过滤器。解析结果AST是一种以节点为结构的树形结构的对象,一个对象表示一个节点,对象的属性用来保存节点所需要的数据。
解析模板例如:
<div>
<p>{{name}}</p>
</div>
解析成AST之后:
//里面的内容后续会解释
{
tag: "div"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: undefined,
attrsList: [],
attrsMap: {},
children: [
{
tag: "p"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: {tag: "div", ...},
attrsList: [],
attrsMap: {},
children: [{
type: 2,
text: "{{name}}",
static: false,
expression: "_s(name)"
}]
}
]
}
解析器在解析HTML的过程中会不断触发各种钩子函数。这些钩子函数包括开始标签钩子函数、结束标签钩子函数、文本钩子函数以及注释钩子函数。
例如:
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数
},
end () {
// 每当解析到标签的结束位置时,触发该函数
},
chars (text) {
// 每当解析到文本时,触发该函数
},
comment (text) {
// 每当解析到注释时,触发该函数
}
})
我们简单举一个例子来说明上述方法是如何构建AST节点的:
<div><p>我是一个节点</p></div>
首先,解析器会将html模板作为一段字符串模板从前向后进行解析,解析到<div>时,会触发一个标签开始的钩子函数start();然后解析到<p>时,又触发一次钩子函数start();接着解析到我是一个节点这行文本,此时触发了文本钩子函数chars();然后解析到</p>,触发了标签结束的钩子函数end();接着继续解析到</div>,此时又触发一次标签结束的钩子函数end(),解析结束。
start()函数你可以看作为HTML解析函数,他的三个参数分别是分别是tag、attrs和unary,分别代表标签名、标签的属性以及是否是自闭合标签。
而文本节点的解析函数chars和注释节点的解析函数comment都只有一个参数text。这是因为构建元素节点需要知道标签名、属性和是否是自闭合元素,而构建注释节点和文本节点时只需要知道文本内容即可。 我们将上面的parseHTML()扩充一下:
//我们模拟一个创建AST元素类型节点的函数
function createASTElement (tag, attrs, parent) {
// 返回的是一个节点对象
return {
type: 1, // 指定节点类型 1.元素节点
tag, // 指定节点
attrsList: attrs, // 指定节点属性
parent, // 指定是否是自闭合标签
children: []
}
}
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数
// 将标签名、标签的属性以及是否是自闭合标签传入
let element = createASTElement(tag, attrs, currentParent)
},
end () {
// 每当解析到标签的结束位置时,触发该函数
},
chars (text) {
// 每当解析到文本时,触发该函数
// 返回的是一个文本节点对象
// 文本分两种类型 2.带变量的动态文本节点 3.不带变量的纯文本节点
let element = {type: 3, text}
},
comment (text) {
// 每当解析到注释时,触发该函数
// 返回的是一个注释节点对象,注释文本和文本的区别是打上了isComment标记
let element = {type: 3, text, isComment: true}
}
})
但是使用上述方式创建的节点虽然带有节点对象信息,但是是扁平的,没有层级关系,而Vue使用了出入栈的方式来构建一个AST结构对象,为之前的扁平数据实现层级关系。
每次解析HTML,都会使用一个栈来存储维护,当触发start()函数时,将当前构建的节点推入栈中;每当触发钩子函数end()时,就从栈中弹出上一个节点。举个例子:
<div>
<h1>我是h1</h1>
<p>我是文本</p>
</div>
- 模板的开始位置是div的开始标签,此时发现栈是空的,这说明div节点是根节点,因为它没有父节点。最后,将div节点推入栈中,
并将模板字符串中的div开始标签从模板中截取掉。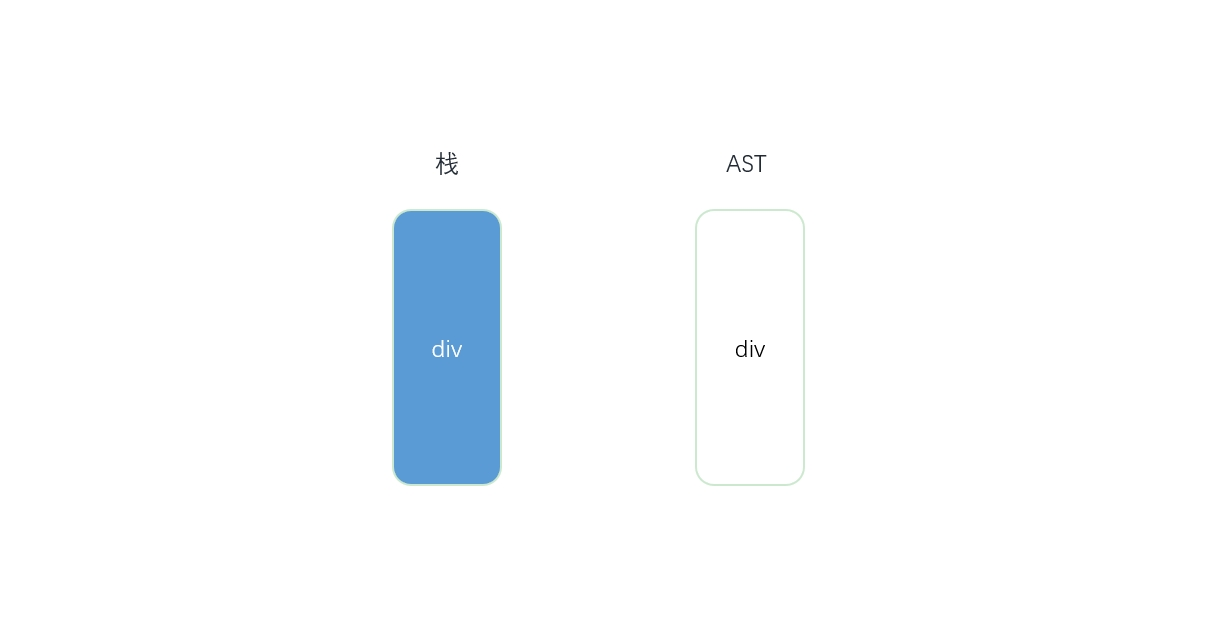
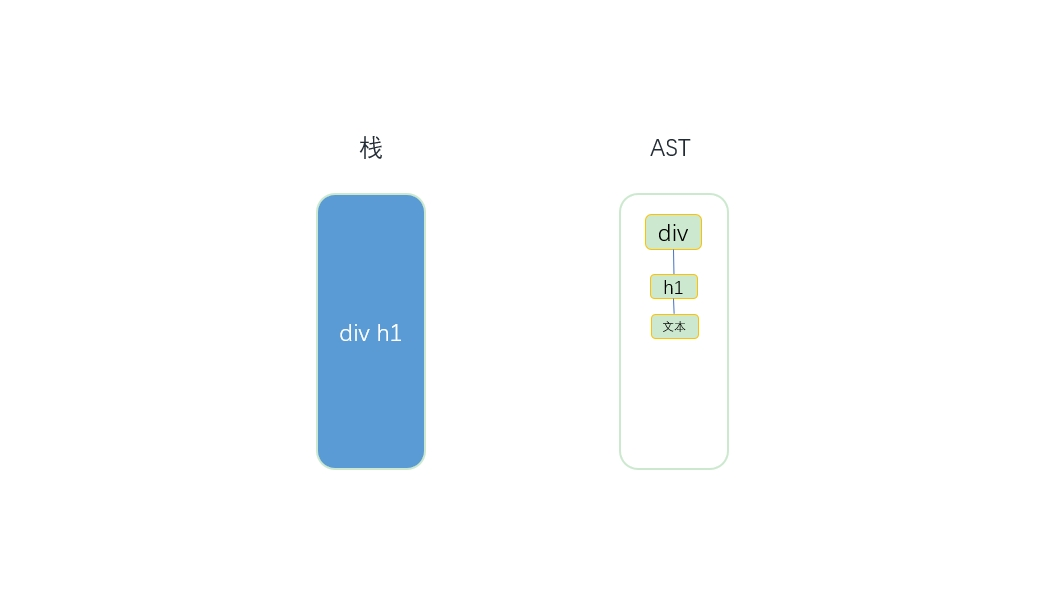
- 钩子函数里会忽略空格,同时会在模板中将这些空格截取掉。接下来发现是h1的开始标签,于是会触发钩子函数start,会先构建一个h1节点。此时发现栈里存的最近一个节点是div节点,这说明h1节点的父节点是div,于是
将h1添加到div的子节点中(也就是children中),并且将h1节点推入栈中,同时从模板中将h1的开始标签截取掉。![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PphkP0lG-1585107481902)(https://s1.ax1x.com/2020/03/25/8XUvYn.jpg)\]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/3/25/17110052c6de080f~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
- 这时模板的开始位置是一段文本,于是会触发钩子函数chars。先构建一个文本节点,此时发现栈中的最后一个节点是h1,这说明文本节点的父节点是h1,于是将文本节点添加到h1节点的子节点中。由于文本节点没有子节点,所以文本节点不会被推入栈中。最后,将文本从模板中截取掉。
- 这时模板的开始位置是h1结束标签,于是会触发钩子函数end。end触发后,会把栈中最后一个节点(也就是h1)弹出来。
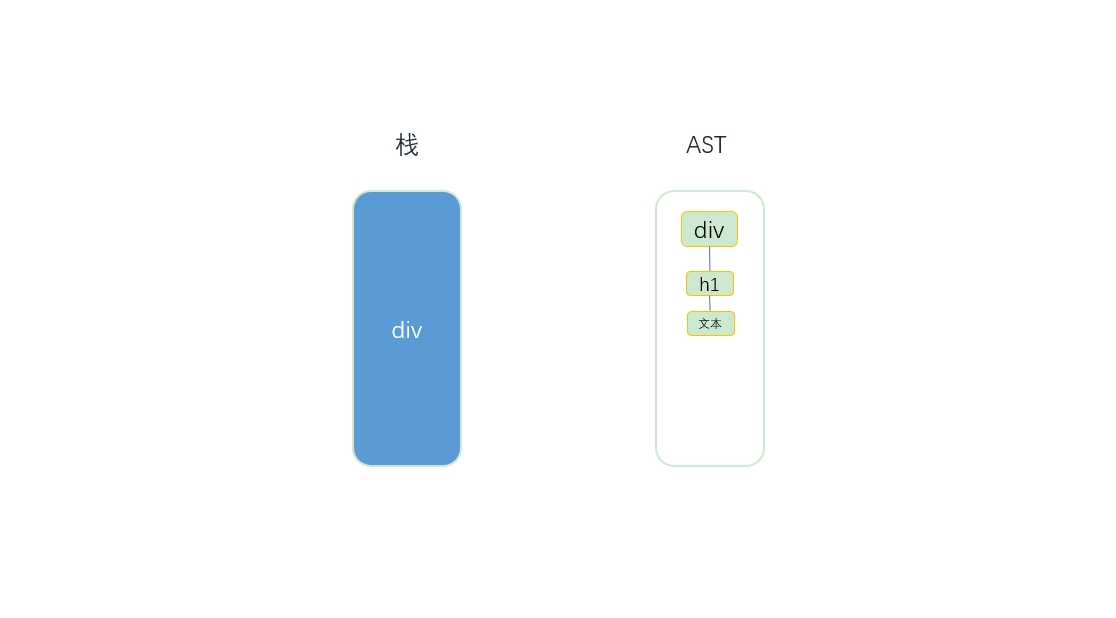
- 第2个标签是p标签和h1标签同理,会先构建一个p节点,由于第4步已经从栈中弹出了一个节点h1,所以此时栈中的最近一个节点是div,于是将p推入div的子节点中,最后将p推入到栈中,从模板中截取掉。然后会一样构建文本节点,截取,最后根据p结束标签触发钩子函数end,把p节点弹出来。
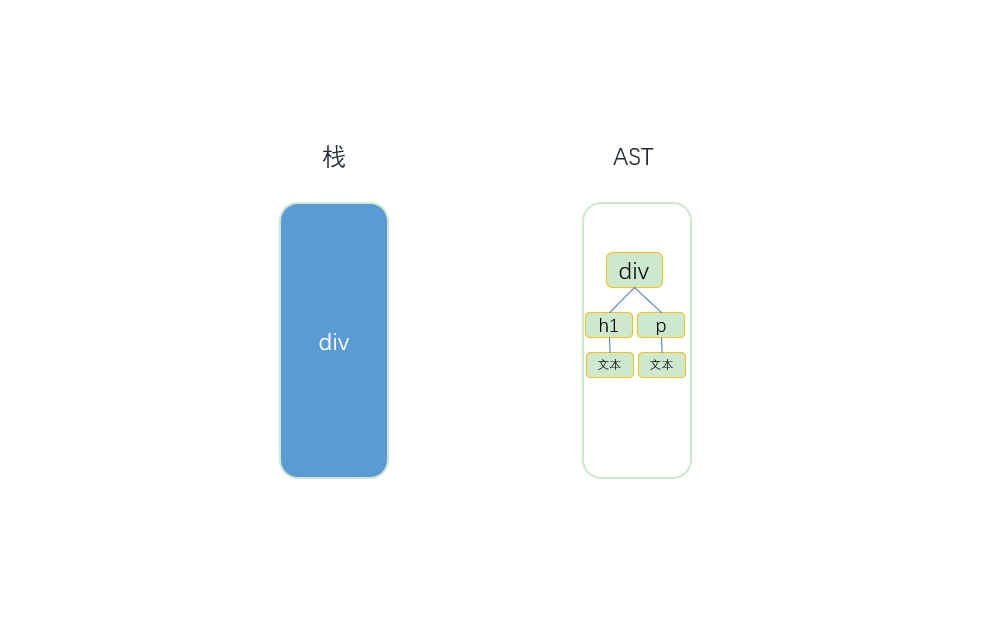
- 最后开始位置是div的结束标签,于是会触发钩子函数end。其逻辑与之前一样,把栈中的最后一个节点div弹出来,并将div的结束标签从模板中截取掉。HTML解析器已经运行完毕,这时我们会发现栈已经空了,而我们得到了一个完整的带层级关系的AST语法树
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qOVcHowI-1585107971471)(https://s1.ax1x.com/2020/03/25/8Xw1JA.jpg)\]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/3/25/17110052fed4e6bf~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
其中对开始标签,结束标签,还有标签属性的解析基本是使用了大量正则表达式:去解析<div </div> : class=这样的字符串,去判定这是一个什么标签该去触发什么函数,不做过多描述。
这个过程如何解析HTML中的注释,条件注释,DOCTYPE,文本?
HTML中的注释,判断<!--,通过indexOf找到注释结束位置-->的下标,然后将结束位置前的字符都截取掉。条件注释注释用提前的表达式判断<,条件注释会被直接截取掉。DOCTYPE直接匹配这段字符,根据它的length属性来决定要截取多长的字符串。文本我们只需要找到>与下一个<在什么位置,这之前的所有字符都属于文本。
节点不完整?
<div><p></div>
在上面的代码中,p标签没有结束标签,那么当HTML解析器解析到div的结束标签时,发现栈内元素却是p标签。就会从栈顶向栈底遍历寻找到div标签,在找到div标签之前遇到的所有其他标签都会标记为忘记闭合的标签,在非生产环境下在控制台打印警告提示。
文本解析器
为什么文本解析器要单独说,因为文本其实分两种类型,一种是纯文本,另一种是带变量的文本。
Hello name
Hello {{name}}
如果是纯文本,不需要进行任何处理;但如果是带变量的文本,那么需要使用文本解析器进一步解析。因为带变量的文本在使用虚拟DOM进行渲染时,需要将变量替换成变量中的值。
- 第一步要做的事情就是使用正则表达式来判断文本是否是带变量的文本,也就是检查文本中是否包含{{xxx}}这样的语法。
- 我们创建一个数组,把变量左边的文本添加到数组中,然后把变量改成_s(变量名)这样的函数形式也添加到数组中。如果变量后面还有变量,则重复以上动作。
- 数组元素的顺序和文本的顺序是一致的,此时将这些数组元素用+连起来变成字符串(_s(变量名)是Vue中对应的解析变量函数,会返回该变量的值)
优化器
静态节点:
<p>我就是一个纯文本的静态节点</p>
优化器则是将解析完的AST进行遍历,找出静态节点并标记,在下次更新对比虚拟DOM的vNode时,如果发现这两个节点是静态节点,则直接跳过更新节点的流程。达到进一步避免一些无用的DOM操作来提升性能,因为静态节点在首次渲染后一定不会改变。
AST生成渲染函数
代码生成器
代码生成器是将解析完的AST转化为渲染函数需要的内容,这个内容叫代码字符串,例如:
<div>
<p>{{name}}</p>
</div>
// 解析为AST
{
tag: "div"
type: 1,
staticRoot: false, // 是否为根静态节点(根静态节点下的所欲节点会认为是静态节点)
static: false, // 是否为根静态节点
plain: true,
parent: undefined,
attrsList: [], // 元素属性
attrsMap: {},
children: [
{
tag: "p"
type: 1, //
staticRoot: false,
static: false,
plain: true,
parent: {tag: "div", ...}, // 所有子节点会带有父节点信息
attrsList: [],
attrsMap: {},
children: [{
type: 2,
text: "{{name}}",
static: false,
expression: "_s(name)"
}]
}
]
}
// 解析完的AST生成代码字符串
`with(this) {return _c('div', [_c('p', [_v(_s(name))]), _v(" "), _m(0)])}`
之后将这串代码字符串传到Vue的渲染函数中,渲染函数根据参数结构,调用相关的创建vNode的方法(生成后的代码字符串中看到了有几个函数调用 _c,_v,_s,这是Vue内部的一些渲染函数,_c可以创建元素类型的vNode,_v可以创建文本类型的vNode,_e可以创建注释类型的vNode)最后组成一份虚拟DOM结构。
我们拿_c来解释一下这个字符串的结构:
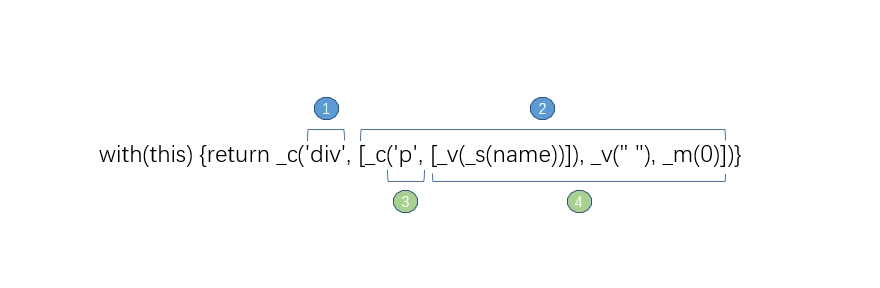
<p title="biaoti">name</p>
with(this){
return _c(
'p', // 标签名
{
attrs:{"title":"biaoti"},
}, // 属性
[_v("name")] // 子节点
)
}
代码生成器的总体逻辑其实就是递归ATS,然后根据ATS结构拼出这样的_c('div',[_c('p',[_v(_s(name))])]) 字符串,再将其传入渲染函数执行。
至于具体的AST转换过程就不做深入解释,会令文章显得枯燥。
总结
我们以上简单讲述了Vue对模板编译的整体流程:解析器(模板字符串转换成AST),优化器(标记静态节点)和代码生成器(将AST装换成带结构的代码字符串)。
解析器通过使用一个栈来维护节点,每从模板字符串中截取一个节点字符串,就将其推入栈中,同时构建一个AST节点,一直到结束节点在将其推出栈,如此循环最后构建出一套带有结构的AST对象。
优化器是通过遍历AST节点,对其中的静态节点做标记,同时最后标记处根静态节点,节省部分不必要的性能消耗。
代码生成器也是通过遍历去拼出一个渲染函数执行的代码字符串,遍历的过程根据不同的节点类型type调用不同的生成字符串方法,最后拼出一个完整的 render 函数需要的代码字符串。
后续还有两篇:
《Vue不看源码懂原理》系列——Vue的diff算法不难懂(直接传送)
《Vue不看源码懂原理》系列——Vue的实例函数和指令解密(下周)
之有一篇用心总结的《Javascript垃圾回收原理》没太有响应,我觉得大家可以看一看,耐心一下的话比较好理解。
点个赞,我加油
点关注,不迷路,哈哈哈
