

最近有不少程序员又开始找工作了,为了了解目前技术类各职位的数量、薪资、招聘公司、岗位职责及要求,我爬取了拉勾网北上广深4个城市的招聘数据,共3w条。职位包括:人工智能(AI)、大数据、数据分析、后端(Java、C|C++、PHP、Python)、前端、Android、iOS、嵌入式和测试。下面我将分两部分进行介绍,第一部分是数据抓取;第二部分是数据分析。如需源代码在公众号(见文末)回复关键字 职位 即可。
数据抓取
这里我并不是通过传统的抓网页,解析HTML代码的方式爬取数据,而是用 Charles 软件抓取拉钩APP请求数据的接口实现。
大概的流程是启动Charles -> 手机连接Charles代理(二者需处于同一个局域网)-> 打开APP请求数据->观察Charles截的包,从中找到我们想要的接口
首先,找到搜索职位的接口
/v1/entry/positionsearch/searchPosition这是一个 POST 请求,我们还要找到请求的 header 和 body,最关键的 header 和 body 如下
header:
'X-L-REQ-HEADER': '{"deviceType":150,"userType":0,"lgId":"11835BCC-8815-456A-A094-64FB2B9323EF_1585362240","reqVersion":73600,"appVersion":"7.36.0","userToken":"xxx"}'
'content-type': "application/json"其中,userToken字段每个不一样,需要自己抓包确定
body
{"tagType": "", "isAd": "1", "showId": "", "district": "", "keywordSource": 0, "keyword": "数据开发",
"salaryUpper": 0, "hiTag": "", "longitudeAndLatitude": "-1.000000,-1.000000", "pageNo": 1, "sort": 0,
"pageSize": 15, "refreshHiTagList": True, "lastShowCompanyId": 0, "nearByKilometers": "", "city": "北京",
"businessZone": "", "shieldDeliveyCompany": False, "salaryLower": 0, "subwayLineName": "",
"subwayStation": ""} 其中,我们只需要关注 keyword,pageNo,pageSize字段,分别代表搜索什么职位,搜索第几页,每页搜多少条。
有了这个信息我们就可以通过程序来请求不同的职位数据,同时为了获取职位更详细的信息我们还可以查找获取职位详情页的接口,方式与此类似,这里就不再赘述了。请求职位的代码如下
def get_data(self):
for city in self.cities_conf:
for position in self.positions_conf:
self.position_search_body['keyword'] = position
self.position_search_body['city'] = city
pageNo = 1
has_more = 1
while has_more:
try:
self.position_search_body['pageNo'] = pageNo
url = 'https://gate.lagou.com/v1/entry/positionsearch/searchPosition'
res = requests.post(url, data=json.dumps(self.position_search_body), headers=self.headers)
print('成功爬取%s市-%s职位的第%d页数据!' % (city, position, pageNo))
item = {'city': city, 'pType': position}
print(res.json())
positionCardVos = res.json()['content']['positionCardVos']
self._parse_record(positionCardVos, item)
pageNo += 1
if positionCardVos is None or len(positionCardVos) < 15:
has_more = 0
time.sleep(random.random() * 5)
except Exception as e:
msg = '链接访问不成功,正在重试!Exception: %s' % e
print(msg)
time.sleep((1 + random.random()) * 10)
变量 position 代表不同的职位,这里请求的时候会加随机停留时间,目的为了防止请求过于平凡。我们抓去别人的数据应该注意这一点,不能恶意爬别人的数据。应该模拟得更像普通人一样去请求数据,如果请求过于频繁导致别人服务出现问题那真实罪大恶极。
_parse_record 方法是解析请求的数据,并存入mongo。首先解析数据没什么好说的,就是解析json而已。简单说下为什么存入mongo,第一,解析的json数据,mongo存储就是用json格式,读取和写入非常方便;第二,mongo不用提前设计表Schema,对我们这种临时性和不确定性的分析带来方便;第三,mongo可以存储海量的数据;第四,mongo会缓存热点数据,我们在后续分析时候读取会非常快。
_parse_record 方法代码如下,为了避免啰嗦,我只保留部分字段的解析,其他的代码可以下载详细代码来看
def _parse_record(self, data, item):
if data:
for position in data:
item['pId'] = position.get('positionId')
item['_id'] = '%s_%s_%d' % (item['city'], item['pType'], item['pId'])
# ... 省略
try:
position_detail_res = requests.get(self.position_detail_url % item['pId']
, timeout=20, headers=self.headers) # 请求详情页的数据
position_content = position_detail_res.json()['content']
item['pAdvantage'] = position_content.get('positionAdvantage')
# ...省略
time.sleep(random.random() * 2)
except Exception as e:
msg = '抓去职位%d详情页失败, Exception: %s' % (item['pId'], e)
print(msg)
self.db['positions'].update_one({'_id': item['_id']}, {'$set': item}, upsert=True)
msg = '成功保存数据:{}!'.format(item)
print(msg)
可以看到方法中还请求了职位详情数据来丰富每一条数据的维度。
数据分析
抓取数据后下面就是分析了,主要用pandas进行统计和画图。由于代码是用jupyter写的,这里不方便贴,所以我直接贴结论,感兴趣的朋友可以自行查看详细代码。
1、哪个城市目前招聘的岗位多
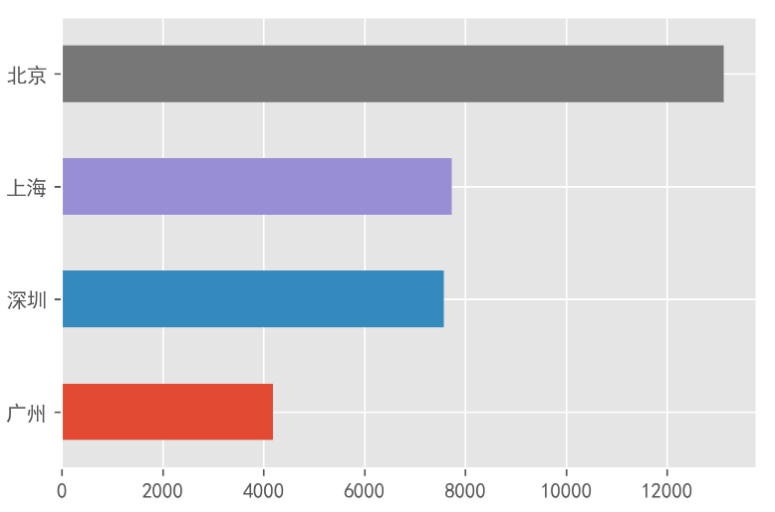
可以看到,目前北京招聘的岗位最多,其次是上海和深圳,广州是最少的。
2、每个城市各岗位的需求量
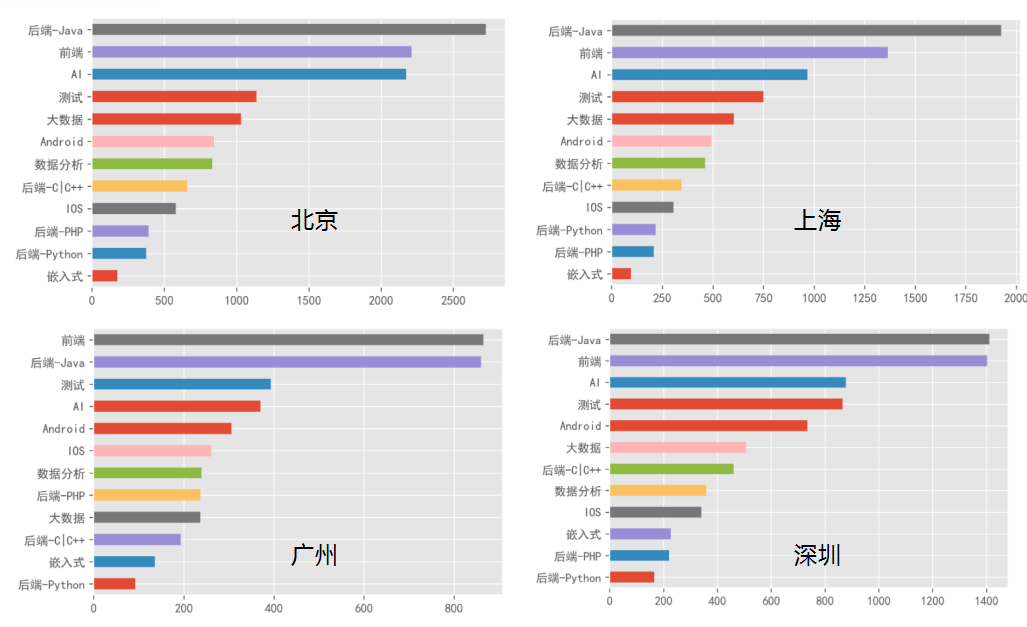
北上广深4个城市目前招聘较多的岗位主要是后端-Java、前端、AI和测试。
3、各岗位的平均薪资情况
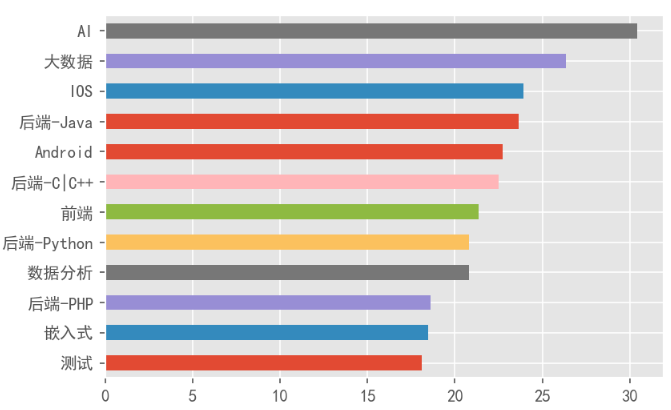
AI岗位的薪资最高,平均每个月30k以上;其次是大数据岗位,平均每个月26k左右,iOS的平均薪资比Android稍微高一些。另外,目前的前端岗位平均薪资偏低。
4、几年工作经验比较吃香
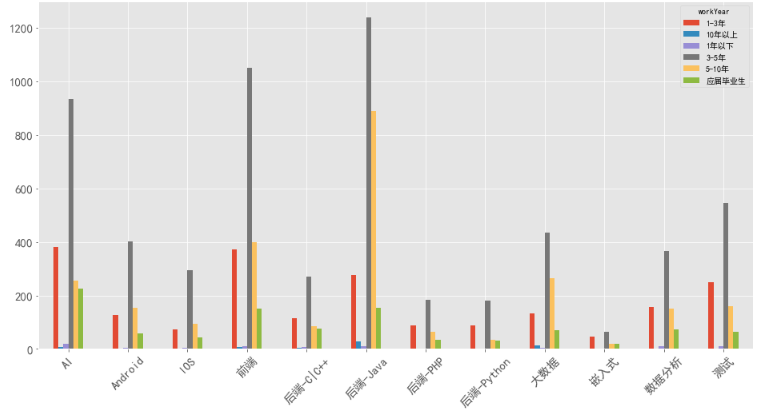
以北京招聘数据为例,目前招聘的各岗位都是以3-5年工作经验为主,1-3年经验的需求量不大。所以,这里也要提醒职场新人,不要轻易跳槽。
其他城市的分布情况与北京类似,这里就不贴图了。
5、什么学历比较吃香
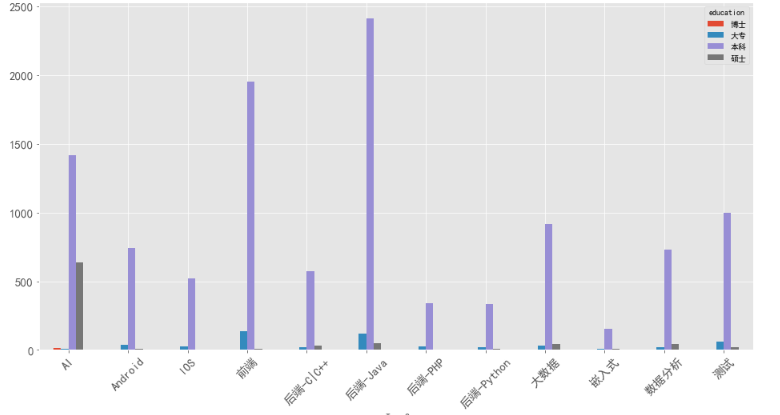
以北京为例,目前招聘的岗位除了AI需要不少的硕士甚至博士外,其他岗位以本科学历为主。
其他城市分布与北京类似。
6、什么规模公司对岗位需求大
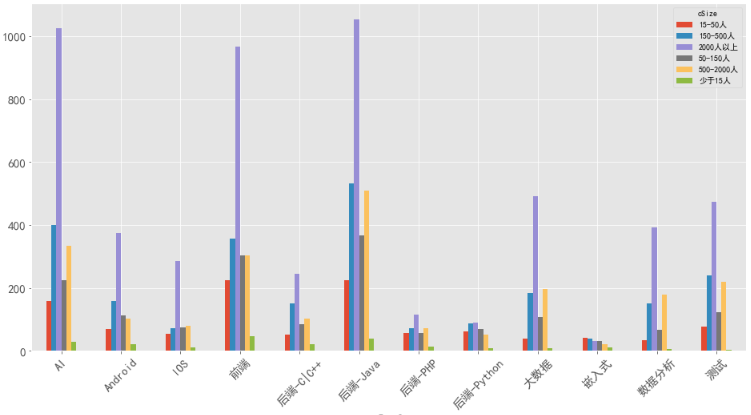
北京
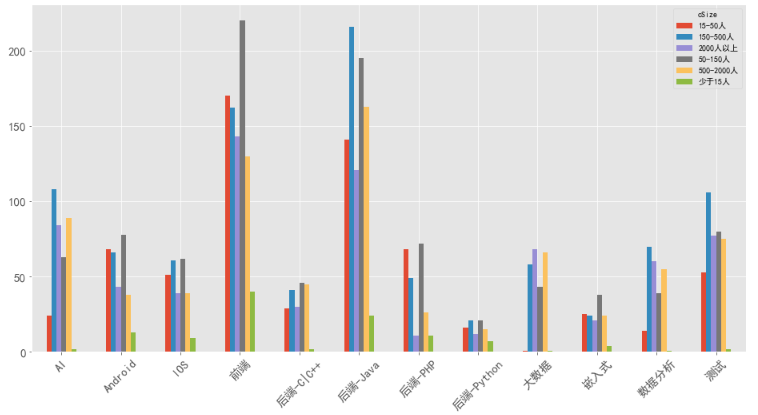
广州
可以看到,北京招聘的企业主要是2000人以上规模的大公司,上海和深圳的分布与北京类似。而广州在AI、前端和后端-Java几个岗位的招聘主要以50-1000人的中等规模公司为主。
7、HR什么时间段更活跃
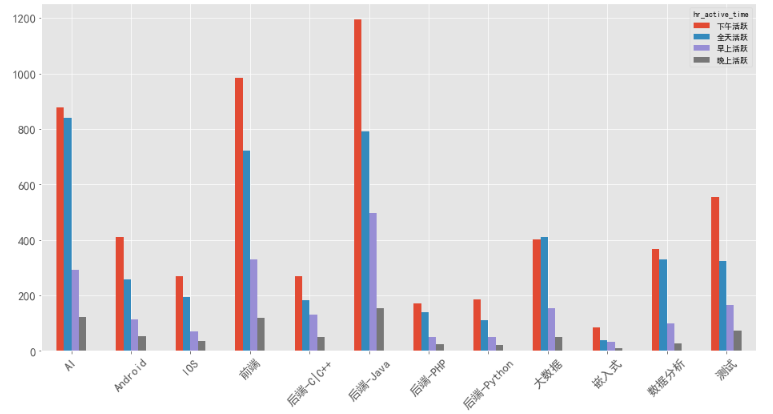
以北京为例,各岗位的HR大部分在下午活跃,所以大家可以将简历的投递时间选在下午。
其他城市分布与北京类似。
8、岗位的职责和要求
限于篇幅,我只跑了AI、后端-Java和前端这3个岗位的数据,以词云的形式展现



希望这次分析能对你有用,欢迎公众号「渡码」,回复关键字 “职位” 即可获取本次分析的源码。

