

本篇文章的脑图来袭喽
1. 正则的认识
1.1 什么是正则
❝regular expression:RegExp (处理字符串的一种规则)
❞
- 用来「处理字符串」的一种规则(只能处理字符串,不是字符串不能处理,但是可以使用
toString()方法变为字符串,哈哈哈哈,有没有被绕蒙,下面举个栗子理解一下吧) - 他是一个「规则」:可以验证字符串是否符合某个规则(test),也可以把字符串中符合规则的内容捕获到(exec/match...)
1.2 初步查看正则
❝下面是使用正则去验证某个字符串的例子!先简单的看一下格式,如果正在看文章的你是第一次接触正则,看完下面的文章就可以轻松理解这个例子了(抛砖引玉一下,哈哈,带着你好奇的心情继续看下去吧!)
❞

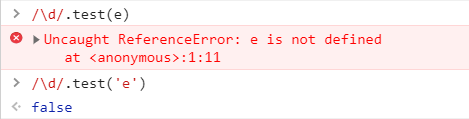
let str = 'good';
let reg = /\d+/;
reg.test(str); //false
str = '2020-04-09';
reg.test(str); //true
2. 编写正则表达式
2.1 创建方式
2.1.1 字面量创建方式
两个斜杆之间包起来的,都是用来描述规则的元字符
let reg1 = /\d+/;
2.1.2 构造函数模式创建
使用正则对象 new的方式,写成字符串形式的
//说明,字符串中直接`\d`是输出的d,因此需要使用`\`转义一下,
let reg2 = new RegExp('\\d+');
❝不管使用以上哪种方式创建,得到的都是对象数据类型的。虽然 reg1 和 reg2 的规则一样,但是
❞reg1!==reg2,其实就是他们的堆内存地址不一样。(这个涉及到了 JS 中的数据类型的知识,不明白的小伙伴们可以去回顾一下哟!)
2.2 正则表达式的组成
很重要,「背下来,背下来,背下来...」 这是正则的基础,如果连每个字符代表的含义都不明白,正则基本就废了哟

2.2.1 元字符
- 量词元字符:设置出现的次数
| 元字符 | 含义 |
|---|---|
| * | 零到多次 |
| + | 一到多次 |
| ? | 零到一次 |
| {n} | n 次 |
| {n,} | n 到多次 |
| {n,m} | n 到 m 次 |
- 特殊元字符:单个或者组合在一起代表特殊的含义
| 元字符 | 含义 |
|---|---|
| \ | 转义字符 |
| . | 除\n(换行符)之外的任意字符 |
| ^ | 以哪一个元字符开头 |
| $ | 以哪一个元字符结尾 |
| \n | 换行符 |
| \d | 0-9 之间的一个数字(包含 0 和 9) |
| \D | 除 0-9 之间的一个数字 |
| \w | 数字、字母、下划线中的任意一个字符 |
| \s | 一个空白字符(包含空格、制表符、换页符) |
| \t | 一个制表符(一个 TAB 键,四个空格) |
| \b | 匹配一个单词的边界 |
| x|y | x 或 y 中的一个字符 |
| [xyz] | x 或 y 或 z 中的一个字符 |
| [^xy] | 除了 x 和 y 以外的任意一个字符 |
| [a-z] | 指定 a-z 这个范围的任意字符 |
| [^a-z] | 上一个的取反“非” |
| () | 正则中的分组符号 |
| (?:) | 只匹配不捕获 |
| (?=) | 正向预查 |
| (?!) | 反向预查 |
普通元字符:代表本身含义的
/name/此正则就是去匹配字符串中的'name'
2.2.2 修饰符:放在正则表达式的外面 /j/g
| 修饰符 | 含义 |
|---|---|
| i(ignoreCase) | 忽略大小写匹配 |
| m(multiline) | 可以进行多行匹配 |
| g(global) | 全局匹配 |
| u(Unicode) | 用来正确处理大于\uFFF 的 Unicode 字符 |
| y(sticky) | 粘连 |
| s(dotAll) | 让'.'能匹配任意字符,包含\n\r |
背下来,背下来,背下来
2.3 常用元字符的详解
2.3.1 ^ $
❝在我们写正则表达式的时候,为了更加严谨,一般都要加上这两个元字符,然后把我们的规则写在他们之间(如果不写^$ 的话,我们写的规则有时会出现意想不到的事情,哈哈,别着急,一步步来。下面介绍到{n,m}的时候会结合它一起说明)
❞
- ^ 以什么元字符开始
- $ 以什么元字符结尾
- ^/$ 两个都不加匹配的是:字符串中包含符合规则的内容即可
- ^/$ 两个都加匹配的是:字符串只能是和规则一致的内容
//匹配的是:以数字开头的字符串
let reg = /^\d/;
console.log(reg.test('name')); //false
console.log(reg.test('2020name')); //true
console.log(reg.test('name2020')); //false
//匹配的是:以数字结尾的字符串
let reg = /\d$/;
console.log(reg.test('name')); //false
console.log(reg.test('2020name')); //false
console.log(reg.test('name2020')); //true
// ^/$ 两个都不加匹配的是:字符串中包含符合规则的内容即可
let reg1 = /\d/;
console.log(reg1.test('as2')); //true
//^/$ 两个都加匹配的是:字符串只能是和规则一致的内容
let reg2 = /^\d$/
console.log(reg2.test('as2')); //false
console.log(reg2.test('22')); //false
console.log(reg2.test('2')); //true
2.3.2 \
- 转义字符,他可以把没有意义的转为有意义的,也可以把有意义的变为没有意义的(好像又成功的把你们说迷糊了吧,哈哈,举个栗子什么都明白了)
//‘.’ 是代表除换行符之外的任意字符,而不是小数点
let reg = /^2.3$/;
console.log(reg.test('2.3')); //true
console.log(reg.test('2@3')); //true
console.log(reg.test('23')); //false
//现在我们把‘.’变为一个普通的小数点(使用到的就是\)
let reg = /^2\.3$/;
console.log(reg.test('2.3')); //true
console.log(reg.test('2@3')); //false
2.3.3 x|y
- x 或 y:直接 x|y 会存在优先级问题,一般配合小括号进行分组使用,因为小括号改变处理的优先级 => 小括号:分组
//匹配的是:以18开头或者以29结尾的都可以,以1开头以9结尾,8或2都可以,所以不加括号怎么理解都可以
//以下的匹配结果都为true
let reg = /^18|29$/;
console.log(reg.test('18'));
console.log(reg.test('29'));
console.log(reg.test('129'));
console.log(reg.test('189'));
console.log(reg.test('1829'));
console.log(reg.test('182'));
//以上不加括号我们可以有很多理解方式都是对的,但是我们加上括号,就不可能想上面那样理解了;
//匹配的是:18或者29中的一个,其余都是false
let reg = /^(18|29)$/;
console.log(reg.test('18'));
console.log(reg.test('29'));
console.log(reg.test('129'));
console.log(reg.test('189'));
2.3.4 []
- 中括号中出现的字符「一般」都代表它本身的含义(会消磁,把他本身的意义都消除掉了)
- \d 在中括号里面的含义仍然是 0-9,这个没有消磁
- [18]:代表的是 1 或者 8 中的任意一个
- [10-29]:代表的是 1 或者 9 或者 0-2
//下面的‘.’就是小数点的意思
let reg = /^[.]+$/;
//匹配的含义是:只能是@或者+的
let reg = /^[@+]$/;
console.log(reg.test('@')); //true
console.log(reg.test('+')); //true
console.log(reg.test('@@')); //false
console.log(reg.test('@+')); //false
//匹配的含义是:\d还是代表0-9
let reg = /^[\d]$/;
console.log(reg.test('9')); //true
console.log(reg.test('\\')); //false
console.log(reg.test('d')); //false
//匹配的含义是:1或者8
let reg = /^[18]$/;
console.log(reg.test('1')); //true
console.log(reg.test('8')); //true
console.log(reg.test('18')); //false
//匹配的含义是:1或者0-2或者9
let reg = /^[10-29]$/;
//匹配的含义是:1或者0-2或者9或'('或')'
let reg = /^[(10-29)]$/;
2.3.5 {n,m}
- 它是代表前面的元字符出现 n 到 m 次
❝
下面的例子中,不加^$ 的超出范围的虽然返回的是 true,但是在使用 exec 捕获的时候,最多捕获 4 个(这个问题是我在学习的时候最大的一个纠结点,如果不知道加上开头结尾符的话,一直认为这个{n,m}在超出范围是不管用的,哈哈)
❞
//这个正则匹配的是数字出现2到4次即可,明显第三个超出了,应该返回false,但是结果却是true,但是加上^$ 就不一样了
let reg = /\d{2,4}/;
reg.test('1'); //false
reg.test('14'); //true
reg.test('123456'); //true
//加上^$ 之后的结果:这个就代表只能有2-4位数字,超过就多余,而上一个匹配的是只有字符串中出现2-4次即可,因此加上^$ 更加严谨
let reg = /^\d{2,4}$/;
reg.test('1'); //false
reg.test('14'); //true
reg.test('123456'); //false
2.3.6 分组作用
- 1.就是改变默认的优先级;
- 2.分组捕获;
- 3.分组引用
//第一个作用:提升优先级,reg1可以匹配的比reg2的多,这个作用在上面已经说过了,这里就不再详细写
let reg1 = /^18|29$/;
let reg2 = /^(18|29)$/
//第二个作用:使用exec捕获的时候不仅可以得到整个大正则的结果,也会分别拿到每一个分组内的
let reg1 =/^([1-9]\d{5})((19|20)\d{2})(0[1-9]|10|11|12)(0[1-9]|[1-2]\d|30|31)\d{3}(\d|x)$/i;
//第三个作用:第一位是a-z的字母,分组1,;第二位也是a-z的字母,分组2;第三位\2是和第二个分组出现一模一样的内容...
let reg1 =/^([a-z])([a-z]\2\1)$/
2.3.7 分组的具名化(给分组起名字)?<名字>
let str = '132123201203200000';
let reg = /^(?<A>[1-9]\d{5})(?<B>(19|20)\d{2})(?<C>0[1-9]|10|11|12)(?<D>0[1-9]|[1-2]\d|30|31)\d{3}(\d|x)$/i;
let res = reg.exec(str);
console.log(res);
console.log(res.groups.B);//可以直接拿到B组的内容
2.3.8 问号在正则中的五大作用
- 1.问号左边是非量词元字符:本身代表量词元字符,出现零到一次;
- 2.问号左边是量词元字符:取消捕获时候的贪婪性;
- (?:):只匹配不捕获;
- 4.(?=):正向预查;
- (?!)负向预查
2.4 常用的正则表达式
2.4.1 验证手机号
规则:
- 11 位
- 第一位是数字 1
- 第二位是数字 3-9 中的任意一位
let reg = /^1[3-9]\d{9}$/;
console.log(reg.test('13245678945')); //true
console.log(reg.test('1324567895')); //false
console.log(reg.test('12245678945')); //false
2.4.2 验证是否为有效数字
规则:
- 开头可以有+ -
- 整数位:
- 如果是一位数可以是 0-9 任意数;
- 如果是多位数,首位不可以是 0;
- 小数位:如果有小数位,那么小数位后面至少有一位数字,也可以没有小数位
let reg = /^[+-]?(\d|[1-9]\d+)(\.\d+)?$/;
console.log(reg.test('0.2')); //true
console.log(reg.test('02.1')); //false
console.log(reg.test('20.')); //false
2.4.3 验证密码
规则:
- 6-16 为组成
- 必须由数字字母组成
let reg = /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[\d(a-z)(A-Z)]{6,16}$/;
2.4.4 验证真实姓名
规则:
- 必须是汉字
- 名字长度 2-10 位
- 可能有译名:·汉字
补充:怎么打出中间位置的点:中文状态下,ESC 下面的那个键就可以
let reg = /^[\u4E00-\u9FA5]{2,10}(·[\u4E00-\u9FA5]{2,10})?$/;
2.4.5 验证邮箱
规则:
- 邮箱的名字以‘数字字母下划线-.’几部分组成,但是-/.不能连续出现也不能作为开头 \w+((-\w+)|(.\w+))*;
- @ 后面可以加数字字母,可以出现多位 @[A-Za-z0-9]+ ;
- 对@后面名字的补充:多域名 .com.cn ;企业域名 (.|-)[A-Za-z0-9]+)*
- .com/.cn 等域名 .[A-Za-z0-9]+
let reg = /^\w+((-\w+)|(\.\w+))*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/
2.4.6 验证身份证号
规则:
- 18 位
- 最后一位是数字或者 X
- 前 6 位是省市县
- 后四位是年
- 后两位是月 01-12
- 后两位是日 01-31
- 最后四位
- 最后一位:X 或者数字
- 倒数第二位:偶数:女 奇数:男 小括号分组的作用:分组捕获,不仅可以把大正则匹配信息捕获到,还可以单独捕获到每个小分组的内容
let reg =/^([1-9]\d{5})((19|20)\d{2})(0[1-9]|10|11|12)(0[1-9]|[1-2]\d|30|31)\d{3}(\d|x)$/i;
2.5 使用正则写注册页面的校验
2.5.1 布局
我使用的是 bootstrap 布局(咳咳咳,这一部我们只需要做一个高级的 CV 工程师就可以完成,哈哈哈哈)
- 在项目文件加下下载 bootstrap 包,可以直接去官网下载,也可以在 node 环境下使用命令下载
npm i bootstrap - 把刚才下载的包中的 css 引入到页面
<link rel="stylesheet" href="node_modules/bootstrap/dist/css/bootstrap.min.css"> - 去 bootstrap 官网上找到自己需要的结构,复制到自己的页面(注意:bootstrap 官网中提到过我们把内容都放在 contain 容器中,因此首先在外面加一个 class 名的 div)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="node_modules/bootstrap/dist/css/bootstrap.min.css">
<style>
.container {
padding: 0;
width: 300px;
}
.form-text {
color: red !important;
}
</style>
</head>
<body>
<section class="container">
<form>
<div class="form-group">
<label>真实姓名</label>
<input type="text" class="form-control" id='userNameInp'>
<small class="form-text text-muted" id='userNameTip'></small>
</div>
<div class="form-group">
<label>邮箱</label>
<input type="email" class="form-control" id='userEmailInp'>
<small class="form-text text-muted" id='userEmailTip'></small>
</div>
<div class="form-group">
<label>电话</label>
<input type="text" class="form-control" id='userPhoneInp'>
<small class="form-text text-muted" id='userPhoneTip'></small>
</div>
<div class="form-group">
<label>密码</label>
<input type="password" class="form-control" id='userPassInp'>
<small class="form-text text-muted" id='userPassTip'></small>
</div>
<div class="form-group">
<label>确认密码</label>
<input type="password" class="form-control" id='userPassConfirmInp'>
<small class="form-text text-muted" id='userPassConfirmTip'></small>
</div>
<button type="button" class="btn btn-primary" id='submit'>提交</button>
</form>
</section>
</body>
</html>
2.5.2 JS 验证
- 所有项都必须填写;
- 输入的格式必须符合要求;
- 鼠标离开文本框的时候校验;
- 当点击提交按钮的时候也要校验;
let reginModule = (function () {
let query = function (selector) {
return document.querySelector(selector);
}
let userNameInp = query('#userNameInp'),
userNameTip = query('#userNameTip'),
userEmailInp = query('#userEmailInp'),
userEmailTip = query('#userEmailTip'),
userPhoneInp = query('#userPhoneInp'),
userPhoneTip = query('#userPhoneTip'),
userPassInp = query('#userPassInp'),
userPassTip = query('#userPassTip'),
userPassConfirmInp = query('#userPassConfirmInp'),
userPassConfirmTip = query('#userPassConfirmTip'),
submit = query('#submit');
// 姓名验证 trim() 去除字符串的首尾空格
let checkName = function checkName() {
let val = userNameInp.value.trim(),
reg = /^[\u4E00-\u9FA5]{2,10}(·[\u4E00-\u9FA5]{2,10})?$/;
if (val.length === 0) {
userNameTip.innerHTML = '真实姓名不能为空';
return false;
}
if (!reg.test(val)) {
userNameTip.innerHTML = '不符合姓名格式';
return false;
}
userNameTip.innerHTML = '';
return true;
};
//EMAIL
let checkEmail = function checkEmail() {
let val = userEmailInp.value.trim(),
reg = /^\w+((-\w+)|(\.\w+))*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/;
if (val.length === 0) {
userEmailTip.innerHTML = '邮箱不能为空';
return false;
}
if (!reg.test(val)) {
userEmailTip.innerHTML = '邮箱格式不正确';
return false;
}
userEmailTip.innerHTML = '';
return true;
};
// 手机号
let checkPhone = function checkPhone() {
let val = userPhoneInp.value.trim(),
reg = /^1[3-9]\d{9}$/;
if (val.length === 0) {
userPhoneTip.innerHTML = '手机号不能为空';
return false;
}
if (!reg.test(val)) {
userPhoneTip.innerHTML = '手机号格式不正确';
return false;
}
userPhoneTip.innerHTML = '';
return true;
};
// 密码
let checkPass = function checkPass() {
let val = userPassInp.value.trim(),
reg = /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[\d(a-z)(A-Z)]{6,16}$/;
if (val.length === 0) {
userPassTip.innerHTML = '密码不能为空';
return false;
}
if (!reg.test(val)) {
userPassTip.innerHTML = '密码格式不正确';
return false;
}
userPassTip.innerHTML = '';
return true;
};
// 确认密码
let checkPassC = function checkPassC() {
let val = userPassConfirmInp.value.trim(),
val2 = userPassInp.value.trim();
if (val !== val2) {
userPassConfirmTip.innerHTML = '密码不一致';
return false;
}
userPassConfirmTip.innerHTML = '';
return true;
};
// 提交
let handel = function handel() {
if (!checkName() || !checkEmail() || !checkPass() || !checkPassC() || !checkPhone()) {
return;
}
alert('请去登录');
}
return {
init() {
userNameInp.onblur = checkName;
userEmailInp.onblur = checkEmail;
userPhoneInp.onblur = checkPhone;
userPassInp.onblur = checkPass;
userPassConfirmInp.onblur = checkPassC;
submit.onclick = handel;
}
};
})();
reginModule.init();
2.5.3 效果
3. 正则捕获
想要实现正则捕获,首先需要满足要和正则匹配(test方法为true,才可以捕获)
- 正则
RegExp.prototype上的方法(exec、test) - 字符串
String.prototype上支持正则表达式处理的方法(replace、match、splite...)
3.1 exec(正则原型上的方法)
❝基于
❞exec实现正则的捕获,它有两个性质:懒惰性和贪婪性。
因此就有一句话叫:做人不能太‘正则’哈哈哈
3.1.1 懒惰性:默认只捕获一个
- 捕获到的结果是
null或一个 数组- 第一项:本次捕获到的内容
- 其余项:对应小分组本次单独循环的内容
index:当前捕获内容在字符串中的起始索引input:原始字符串
- 每执行一次
exec,只能捕获到一个符合正则规则的,但是默认情况下,我们执行一百次,获取的结果永远都是第一个匹配到的,其余的都捕获不到
let str = 'name2020name2020name2020';
reg =/\d+/;
console.log(reg.exec(str));//["2020", index: 4, input: "name2020name2020name2020", groups: undefined]
3.1.2 懒惰性的解决方法
reg.lastIndex:当前正则下一次匹配的起始索引位置
let str = 'name2020name2020name2020';
reg =/\d+/;
console.log(reg.lastIndex);//0
「原因:」 默认情况下lastIndex的值不会被修改,每一次都是从字符串开始位置查找,所以找到的永远都是第一个。因此只要把lastIndex值改变,就可以解决这个问题
「解决方法:」 设置全局修饰符g
❝设置全局修饰符g后,第一次匹配完成,lastIndex的值会自己修改。
❞
当全部捕获后,再次捕获的结果是null,但是lastIndex又回了初始值零,再一次捕获又从第一个开始了...
基于test匹配验证后,lastIndex也会被修改
3.1.3 封装解决正则懒惰性的方法
需求:编写一个方法execAll,执行一次可以把所有匹配的结果捕获到(前提正则一定要设置全局修饰符g)
~ function(){
function execAll(str = ''){
if(!this.global) return this.exec(str);
let ary = [],
res = this.exec(str);
while(res){
ary.push(res[0]);
res = this.exec(str);
}
return ary.length ===0?null:ary;
}
RegExp.prototype.execAll = execAll;
}();
let reg = /\d+/g,
str = 'name2020name2020';
console.log(reg.execAll(str));
3.1.4 贪婪性
默认情况下正则捕获的时候,是按照当前正则所匹配的最长结果来获取的。
let str = 'name2020',
reg = /\d+/g;
console.log(str.match(reg));
3.1.5 解决正则的贪婪性问题
在量词元字符后面设置?取消捕获时候的贪婪性(按照正则匹配的最短结果来获取)
let str = 'name2020',
reg = /\d+?/g;
console.log(str.match(reg));
3.2 正则的分组捕获() | 字符串match方法
分析下面栗子的结果:
- 第一项:大正则匹配的结果
- 其余项:每一个小分组单独匹配捕获的结果
- 如果设置了分组(改变优先级),但是捕获的时候不需要单独捕获,可以基于?:来处理,不捕获最后一项:
/^([1-9]\d{5})((19|20)\d{2})(0[1-9]|10|11|12)(0[1-9]|[1-2]\d|30|31)\d{3}(?:\d|x)$/i
//身份证号
let str = '130222195202303210',
reg =/^([1-9]\d{5})((19|20)\d{2})(0[1-9]|10|11|12)(0[1-9]|[1-2]\d|30|31)\d{3}(\d|x)$/i;
console.log(reg.exec(str));
console.log(str.match(reg));
//["130222195202303210", "130222", "1952", "19", "02", "30", "0", index: 0, input: "130222195202303210", groups: undefined]
================================================
- 字符串中的
match方法可以在执行一次的情况下,捕获到所有匹配的数据(前提正则也得设置g才可以) - 加g之后,
match不能获取到小分组内的东西
let reg = /\d+/g;
console.log('name2020name2020'.match(reg));//["2020", "2020"]
//既要捕获到{0},也要捕获到0
let str = '{0}年{1}月';
reg = /\{(\d)\}/g;
console.log(reg.exec(str));
console.log(str.match(reg));
3.3 replace(字符串原型上的方法)
本身是字符串替换的意思。在这里结合正则使用他有一下几个特点 str = str.replace(reg,func);
- 首先会拿reg和func去进行匹配,匹配捕获一次,就会把func函数执行一次
- 并且会把每一次捕获的结果(和exec捕获的结果一样)传递给func函数
- 在func函数中返回return什么,就相当于把原始字符中,大正则匹配的结果替换成啥
//把-替换成/(不使用正则的时候需要多次执行这个方法,但是正则可以一次替换,前提是加g)
let str = '2020-04-09';
str = str.replace(/-/g,'/');
console.log(str);
let str = '{0}年{1}月';
let reg = /\{\d\}/g;
str = str.replace(reg,(...args)=>{
console.log(args);//存储的是每次正则捕获的结果
return 1;
})
console.log(str);//'1年1月'
4.正则中捕获方法的应用
4.1 时间格式字符串
- 月日不足十位补零
- 换成年月日的格式
//方法一
let time = '2020-4-9';
let arr = time.match(/\d+/g);//拿到每一项
arr = arr.map(item=>item.length<2?'0'+item:item);
time = `${arr[0]}年${arr[1]}月${arr[2]}日`;
console.log(time);
//方法二
let time = '2020-4-9';
let arr = time.match(/\d+/g);//拿到每一项
arr = arr.map(item=>item.length<2?'0'+item:item);
let template = '{0}年{1}月{2}日';
template = template.replace(/\{(\d+)\}/g, (value, group) => {
return arr[group]; //=>返回啥就是把TEMPLETE中大正则本次匹配的结果替换成啥
});
console.log(template);
//方法三
let time = '2020-4-9';
String.prototype.formatTime = function formatTime(template) {
let arr = this.match(/\d+/g).map(item => {
return item.length < 2 ? '0' + item : item;
});
template = template || '{0}年{1}月{2}日 {3}时{4}分{5}秒';
return template.replace(/\{(\d+)\}/g, (_, group) => {
return arr[group] || "00";
});
};
console.log(time.formatTime());
4.2 字符串中出现最多次数的字符,多少次
//方法一
let str = "qwerttydsdsssfggg";
let ary = [...new Set(str.split(''))];
let max = 0;
let code = '';
for (let i = 0; i < ary.length; i++) {
//创建正则匹配字符
let reg = new RegExp(ary[i], 'g');
//利用match找出对应字符在中字符串中出现的地方,取匹配的返回数组的长度,即是对应字符串出现的次数
let val = str.match(reg).length;
//更新出现次数最高的字符与次数
if (val > max) {
max = val;
code = ary[i];
} else if (val === max) { //处理不同字符出现次数相同的情况
code = `${code}、${ary[i]}`;
}
}
console.log(`出现次数最多的字符是:${code},次数为:${max}`);
//方法二
let str = "sfsdfsgdsdgdfg";
let obj = {};
// str.match(/[a-zA-Z]/g) <==> str.split('')
str.match(/[a-zA-Z]/g).forEach(item => {
// 每一次存储之前,验证一下对象中是否已经包含这个字符,如果有,则代表之前存储过,我们此时让数量累加1即可
if (obj[item] !== undefined) {
obj[item]++;
return;
}
obj[item] = 1;
});
let max = 0,
result = '';
for (let key in obj) {
let val = obj[key];
if (val > max) {
max = val;
result = key;
} else if (val === max) {
result += `|${key}`;
}
}
console.log(max, result);
//方法三
let str = "sfsdfsdsfdgffd";
let arr = str.split('').sort((a, b) => {
// 字符比较
return a.localeCompare(b);
});
let max = 1,
result = '',
temp = 1;
for (let i = 0; i < arr.length - 1; i++) {
let curr = arr[i],
next = arr[i + 1];
if (curr === next) {
temp++;
if (temp > max) {
max = temp;
result = curr;
}
} else {
temp = 1;
}
}
console.log(max, result);
//方法四
let str = "sfsdsdgsdgsg";
str = str.split('').sort((a, b) => a.localeCompare(b)).join('');
// console.log(str);//=>"aeefghhhiilnnoopsuuuxzz"
let ary = str.match(/([a-zA-Z])\1+/g).sort((a, b) => b.length - a.length);
let max = ary[0].length,
res = [ary[0].substr(0, 1)];
for (let i = 1; i < ary.length; i++) {
let item = ary[i];
if (item.length < max) {
break;
}
res.push(item.substr(0, 1));
}
console.log(`出现次数最多的字符:${res},出现了${max}次`);
//方法五
let str = "fdsgsgdfhi",
max = 0,
res = [],
flag = false;
str = str.split('').sort((a, b) => a.localeCompare(b)).join('');
for (let i = str.length; i > 0; i--) {
let reg = new RegExp("([a-zA-Z])\\1{" + (i - 1) + "}", "g");
str.replace(reg, (content, $1) => {
res.push($1);
max = i;
flag = true;
});
if (flag) break;
}
console.log(`出现次数最多的字符:${res},出现了${max}次`);
4.3 获取URL中的传参信息(可能也包含HASH值)
String.prototype.queryURLParams = function queryURLParams() {
let obj = {};
// 哈希值值的处理
this.replace(/#([^?=#&]+)/g, (_, group) => obj['HASH'] = group);
// 问号传参信息的处理
this.replace(/([^?#=&]+)=([^?#=&]+)/g, (_, group1, group2) => {
obj[group1] = group2;
});
return obj;
};
let str = 'http://www.baidu.cn/?lx=1&from=weixin&name=xxx#video';
let obj = str.queryURLParams();
console.log(obj);
4.4 millimeter:实现千分符处理
String.prototype.millimeter = function millimeter() {
return this.replace(/\d{1,3}(?=(\d{3})+$)/g, value => {
return value + ',';
});
};
let str = "2312345638";
str = str.millimeter();
console.log(str); //=>"2,312,345,638"

写到这里,关于正则的学习可以说是掌握的差不多了,(你肯定回想,这是个啥,要疯了,哈哈哈。是很烧脑,但是我们也要拿出吃奶的劲头把它学会,哈哈哈)。整理不易,动动小手,为小女子留下一个小心心吧。
