

近日 PyTorch 发布了 1.5 版本的更新,作为越来越受欢迎的机器学习框架,PyTorch 本次也带来了大的功能升级。此外, Facebook 和 AWS 还合作推出了两个重要的 PyTorch 库。
随着 PyTorch 在生产环境中的应用越来越多,为社区提供更好的工具和平台,以便高效地扩展训练和部署模型,也成了 PyTorch 的当务之急。
近日 PyTorch 1.5 发布,升级了主要的 torchvision,torchtext 和 torchaudio 库,并推出将模型从 Python API 转换为 C ++ API 等功能。

除此之外,Facebook 还和 Amazon 合作,推出了两个重磅的工具:TorchServe 模型服务框架和 TorchElastic Kubernetes 控制器。
TorchServe 旨在为大规模部署 PyTorch 模型推理,提供一个干净、兼容性好的工业级路径。
而 TorchElastic Kubernetes 控制器,可让开发人员快速使用 Kubernetes 集群,在 PyTorch 中创建容错分布式训练作业。
这似乎是 Facebook 联手亚马逊,在针对大型性能 AI 模型框架上,宣战 TensorFlow 的一个举措。
TorchServe:用于推理任务
部署机器学习模型进行规模化推理并非易事。开发人员必须收集和打包模型工件,创建安全的服务栈,安装和配置预测用的软件库,创建和使用 API 和端点,生成监控用的日志和指标,并在可能的多个服务器上管理多个模型版本。
上述每一项任务都需要大量的时间,并可能会使模型部署速度减慢数周甚至数月。此外,为低延迟在线应用优化服务是一件必须要做的事情。

此前使用 PyTorch 的开发人员,均缺乏官方支持的部署 PyTorch 模型的方法。而生产模型服务框架 TorchServe 的发布,将改变这一现状,它能够更容易地将模型投入到生产中。
在下面的例子中,将说明如何从 Torchvision 中提取训练过的模型,并使用 TorchServe 进行部署。
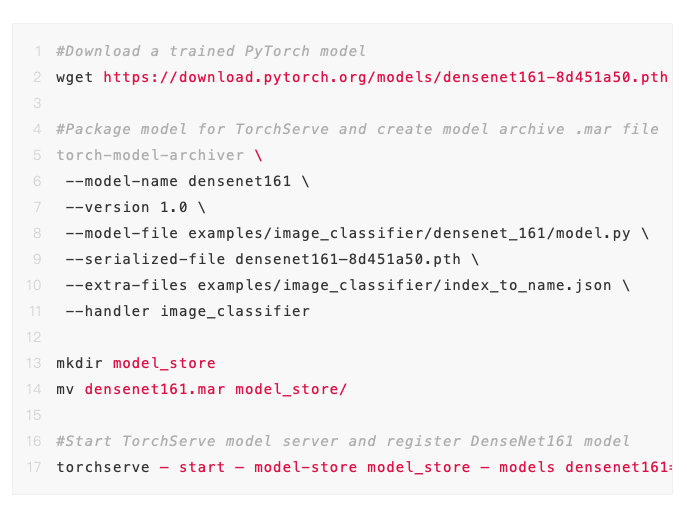
TorchServe 的测试版本现已可用,其特点包括:
- 原生态 API:支持用于预测的推理 API,和用于管理模型服务器的管理 API。
- 安全部署:包括对安全部署的 HTTPS 支持。
- 强大的模型管理功能:允许通过命令行接口、配置文件或运行时 API 对模型、版本和单个工作线程进行完整配置。
- 模型归档:提供执行「模型归档」的工具,这是一个将模型、参数和支持文件打包到单个持久工件的过程。使用一个简单的命令行界面,可以打包和导出为单个「.mar」文件,其中包含提供 PyTorch 模型所需的一切。该 .mar 文件可以共享和重用。
- 内置的模型处理程序:支持涵盖最常见用例,如图像分类、对象检测、文本分类、图像分割的模型处理程序。TorchServe 还支持自定义处理程序。
- 日志记录和指标:支持可靠的日志记录和实时指标,以监视推理服务和端点、性能、资源利用率和错误。还可以生成自定义日志并定义自定义指标。
- 模型管理:支持同时管理多个模型或同一模型的多个版本。你可以使用模型版本回到早期版本,或者将流量路由到不同的版本进行 A/B 测试。
- 预构建的图像:准备就绪后,可以在基于 CPU 和 NVIDIA GPU 的环境中,部署 T orchServe 的 Dockerfile 和 Docker 镜像。最新的 Dockerfiles 和图像可以在这里找到。
用户也可以从 pytorch.org/serve 获得安装说明、教程和文档。
TorchElastic :集成的 K8S 控制器
当前机器学习的训练模型越来越大,如 RoBERTa 和 TuringNLG,它们向外扩展到分布式集群的需求也变得越来越重要。为了满足这一需求,通常会使用抢占式实例(例如 Amazon EC2 Spot 实例)。
但这些可抢占实例本身是不可预测的,为此,第二个工具 TorchElastic 出现了。
Kubernetes 和 TorchElastic 的集成,允许 PyTorch 开发人员在一组计算节点上训练机器学习模型,这些节点可以动态地变化,而不会破坏模型训练过程。
即使节点发生故障,TorchElastic 的内置容错功能也可以暂停节点级别的训练,并在该节点再次恢复正常后恢复训练。

此外,使用带有 TorchElastic 的 Kubernetes 控制器,可以在硬件或节点回收时问题上,在被替换了节点的集群上,运行分布式训练的关键任务。
训练任务可以使用部分被请求的资源启动,并且可以随着资源可用而动态扩展,无需停止或重新启动。
要利用这些功能,用户只需在简单的作业定义中指定训练参数,Kubernetes-TorchElastic 软件包便可以管理作业的生命周期。
以下是用于 Imagenet 训练作业的 TorchElastic 配置的简单示例:

微软、谷歌,就问你们慌不慌?
这次两家合作推出全新 PyTorch 库的操作,其背后也许有着更深层的意义,因为「不带你玩」这个套路,在框架模型发展的历史上,已不是第一次出现。
2017 年 12 月,AWS、Facebook 和微软宣布,他们将共同开发可用于生产环境的 ONNX ,以此来对抗谷歌 TensorFlow 对工业界使用的垄断。
随后 Apache MXNet 、Caffe2、PyTorch 等主流深度学习框架,都对 ONNX 实现了不同程度的支持,这方便了算法及模型在不同的框架之间的迁移。

而 ONNX 想打通学术界和产业界的愿景,实际上并没有达到当初的预期,各家框架依然用各自的服务体系,基本上只有 MXNet 和 PyTorch 深入到了 ONNX。
而如今,PyTorch 推出了自己的服务体系,ONNX 则近乎失去了存在的意义(MXNet 表示不知所措)。
另一方面,PyTorch 在不断的升级更新之下,框架的兼容性和易用性,正在逼近甚至赶超最强劲的对手 TensorFlow。
虽然谷歌有自己的云服务和框架,但 AWS 的云资源和 Facebook 的框架体系联合,强强联手之下,恐怕谷歌也将难以招架。
而微软已经被曾经 ONNX 三人组的两个小伙伴踢出群聊,下一步不知做何打算?
—— 完 ——
