

github 地址
一、问题描述
上周五晚上主营出现部分设备掉线,经过查看日志发现是由于缓存系统出现长时间gc导致的。这里的gc日志的特点是:
- 1.gc时间都在2s以上,部分节点甚至出现12s超长时间gc。
- 2.同一个节点距离上次gc时间间隔为普遍为13~15天。
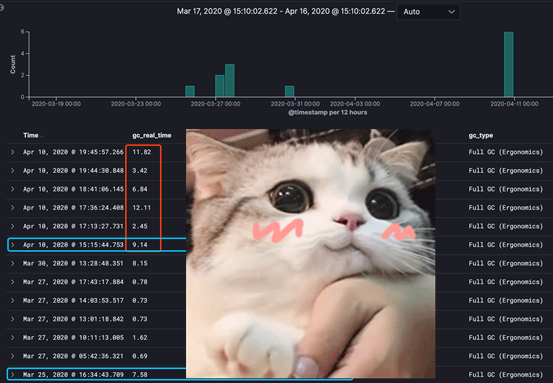
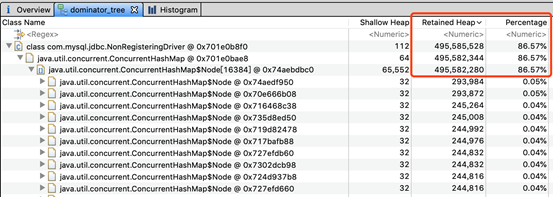

初步判断长时间gc的问题应该是由于 com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 这个对象大量堆积引起的。
二、问题分析
目前正式环境使用数据库相关依赖如下:
| 依赖 | 版本 |
|---|---|
| mysql | 5.1.47 |
| hikari | 2.7.9 |
| Sharding-jdbc | 3.1.0 |
根据以上描述,提出以下问题:
- 1、com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 到底是个什么对象呢?
- 2、这种对象为什么会大量堆积,JVM回收不过来了?
NonRegisteringDriver$ConnectionPhantomReference 到底是个什么对象呢?
简单来说,NonRegisteringDriver类有个虚引用集合connectionPhantomRefs用于存储所有的数据库连接,NonRegisteringDriver.trackConnection方法负责把新创建的连接放入connectionPhantomRefs集合。源码如下:
1.public class NonRegisteringDriver implements java.sql.Driver {
2. protected static final ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference> connectionPhantomRefs = new ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference>();
3. protected static final ReferenceQueue<ConnectionImpl> refQueue = new ReferenceQueue<ConnectionImpl>();
4.
5. ....
6.
7. protected static void trackConnection(Connection newConn) {
8.
9. ConnectionPhantomReference phantomRef = new ConnectionPhantomReference((ConnectionImpl) newConn, refQueue);
10. connectionPhantomRefs.put(phantomRef, phantomRef);
11. }
12. ....
13. }
我们追踪创建数据库连接的过程源码,发现其中会调到com.mysql.jdbc.ConnectionImpl的构造函数,该方法会调用createNewIO方法创建一个新的数据库连接MysqlIO对象,然后调用我们上面提到的NonRegisteringDriver.trackConnection方法,把该对象放入NonRegisteringDriver.connectionPhantomRefs集合。源码如下:
1.public class ConnectionImpl extends ConnectionPropertiesImpl implements MySQLConnection {
2.
3. public ConnectionImpl(String hostToConnectTo, int portToConnectTo, Properties info, String databaseToConnectTo, String url) throws SQLException {
4. ...
5. createNewIO(false);
6. ...
7. NonRegisteringDriver.trackConnection(this);
8. ...
9. }
10.}
connectionPhantomRefs 是一个虚引用集合,何为虚引用?为什么设计为虚引用队列
- 虚引用队列也称为“幽灵引用”,它是最弱的一种引用关系。
- 如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃 圾回收器回收。
- 为一个对象设置虚 引用关联的唯一目的只是为了能在这个对象被收集器回收时收到一个系统通知。
- 当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在垃圾回收后,将这个虚引用加入引用队列,在其关联的虚引用出队前,不会彻底销毁该对象。所以可以通过检查引用队列中是否有相应的虚引用来判断对象是否已经被回收了。
connectionPhantomRefs 这种对象为什么会大量堆积,JVM回收不过来了?
这里结合项目中hikaricp数据配置和官方文档结合说明~
我们先查阅hikaricp数据池的官网地址,看看部分属性介绍如下:
maximumPoolSize
This property controls the maximum size that the pool is allowed to reach, including both idle and in-use connections. Basically this value will determine the maximum number of actual connections to the database backend. A reasonable value for this is best determined by your execution environment. When the pool reaches this size, and no idle connections are available, calls to getConnection() will block for up to connectionTimeout milliseconds before timing out. Please read about pool sizing. Default: 10
maximumPoolSize控制最大连接数,默认为10
minimumIdle
This property controls the minimum number of idle connections that HikariCP tries to maintain in the pool. If the idle connections dip below this value and total connections in the pool are less than maximumPoolSize, HikariCP will make a best effort to add additional connections quickly and efficiently. However, for maximum performance and responsiveness to spike demands, we recommend not setting this value and instead allowing HikariCP to act as a fixed size connection pool. Default: same as maximumPoolSize
minimumIdle控制最小连接数,默认等同于maximumPoolSize,10。
⌚idleTimeout
This property controls the maximum amount of time that a connection is allowed to sit idle in the pool. This setting only applies when minimumIdle is defined to be less than maximumPoolSize. Idle connections will not be retired once the pool reaches minimumIdle connections. Whether a connection is retired as idle or not is subject to a maximum variation of +30 seconds, and average variation of +15 seconds. A connection will never be retired as idle before this timeout. A value of 0 means that idle connections are never removed from the pool. The minimum allowed value is 10000ms (10 seconds). Default: 600000 (10 minutes)
连接空闲时间超过idleTimeout(默认10分钟)后,连接会被抛弃
⌚maxLifetime
This property controls the maximum lifetime of a connection in the pool. An in-use connection will never be retired, only when it is closed will it then be removed. On a connection-by-connection basis, minor negative attenuation is applied to avoid mass-extinction in the pool. We strongly recommend setting this value, and it should be several seconds shorter than any database or infrastructure imposed connection time limit. A value of 0 indicates no maximum lifetime (infinite lifetime), subject of course to the idleTimeout setting. Default: 1800000 (30 minutes)
连接生存时间超过 maxLifetime(默认30分钟)后,连接会被抛弃.
我们再回头看看项目的hikari配置:
- 配置了minimumIdle = 10,maximumPoolSize = 50,没有配置idleTimeout和maxLifetime。所以这两项会使用默认值 idleTimeout = 10分钟,maxLifetime = 30分钟。
- 也就是说假如数据库连接池已满,有50个连接,假如系统空闲,40个连接会在10分钟后(超过idleTimeout)被废弃;假如系统一直繁忙,50个连接会在30分钟后(超过maxLifetime)后被废弃。
猜测问题产生的根源:
每次新建一个数据库连接,都会把该连接放入connectionPhantomRefs集合中。数据连接在空闲时间超过idleTimeout或生存时间超过maxLifetime后会被废弃,在connectionPhantomRefs集合中等待回收。因为连接资源一般存活时间比较久,经过多次Young GC,一般都能存活到老年代。如果这个数据库连接对象本身在老年代,connectionPhantomRefs中的元素就会一直堆积,直到下次 full gc。如果等到full gc 的时候connectionPhantomRefs集合的元素非常多,该次full gc就会非常耗时。
那么怎么解决呢?可以考虑优化minimumIdle、maximumPoolSize、idleTimeout、maxLifetime这些参数,下一小节我们分析一波
三、问题验证
线上模拟环境
为了验证问题,我们需要模拟线上环境,调整maxLifetime等参数~压测思路如下:
- 1.缓存系统模拟线上的配置,使用压测系统一段时间内持续压缓存系统,使缓存系统短时间创建/废弃大量数据库连接,观察 NonRegisteringDriver 对象是否如期大量堆积,再手动调用 System.gc() 观察 NonRegisteringDriver 对象是否被清理。
- 2.调整maxLifetime 参数,观察相同的压测时间内 NonRegisteringDriver 对象是否还发生堆积。
这里有以下注意点:
- 1、 要满足 (gc 间隔时间 * 新生代进入老年代前的存活次数 < maxLifetime)这个条件,NonRegisteringDriver 对象才满足进入老年代的条件。
- 2、 minimumIdle = 10,maximumPoolSize = 50(minimumIdle和maximumPoolSize和线上配置一致),idleTimeout设置10s,maxLifetime设 100s(gc时间约20s,所以要大于 20 * 3 = 60s)。这样预计在持续压测下每30s就会产生10个新连接(就算设置了maximumPoolSize = 50,这种程序的压测10个连接足以应付)
- 3、 项目内存分配小一点,以及把新生代进入老年代前的存活次数调小一点,方便新生代的NonRegisteringDriver对象在较短时间能进入老年代,方便在较短时间观察到明显的对象增长。
- 4、 要监测缓存系统数据连接池的连接存活情况,以及系统 gc情况。
最终环境配置如下:
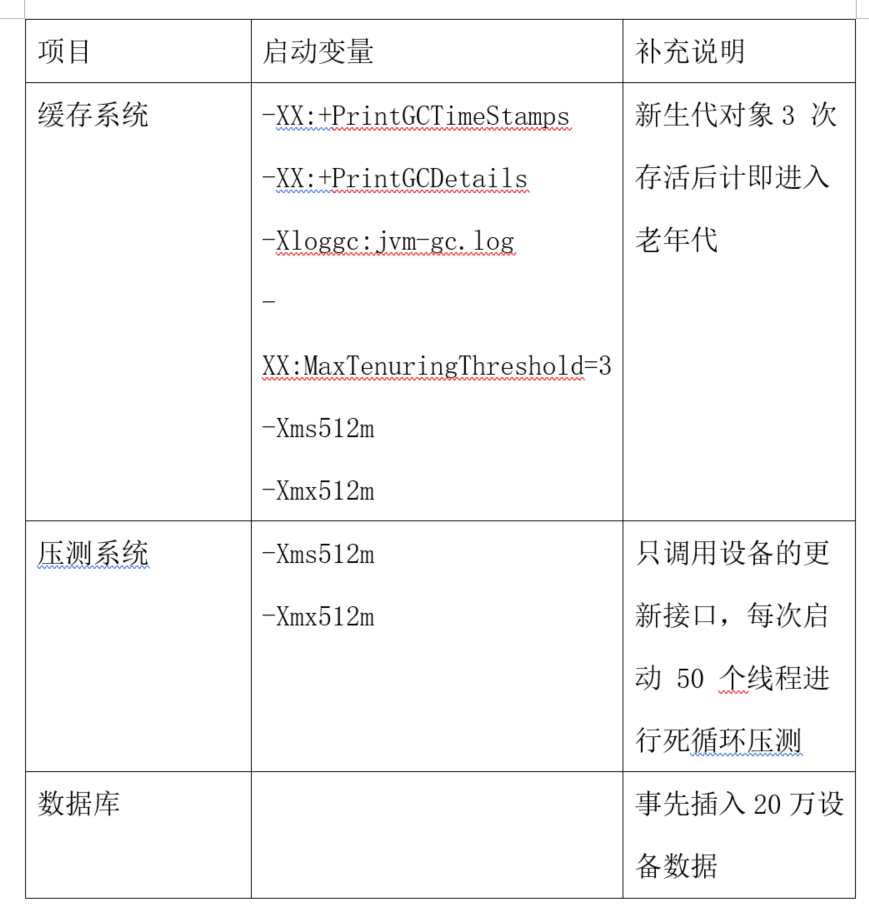
模拟实验结果
- 启用jvisualvm工具对缓存系统进行实时观察
- 打开hikari相关debug日志观察连接池情况
设置 maxLifetime = 100s,启动缓存系统
确认hikari和jvm配置生效
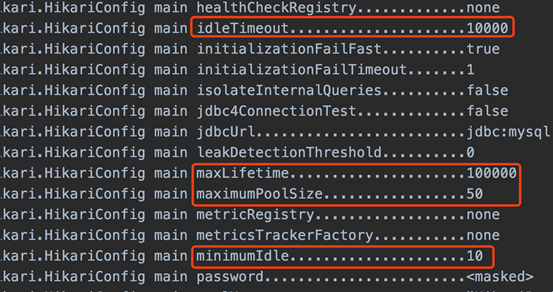
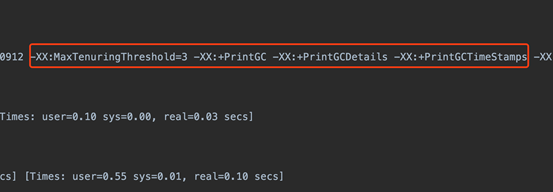

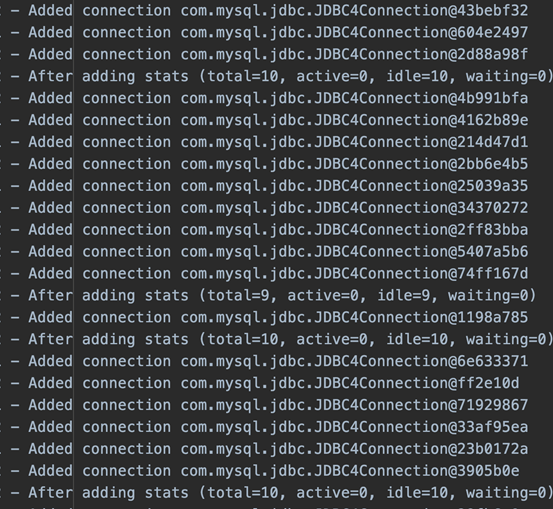
启动压测程序,压测1000s
期间观察gc日志,gc时间间隔约20s,100s后发生5次 gc

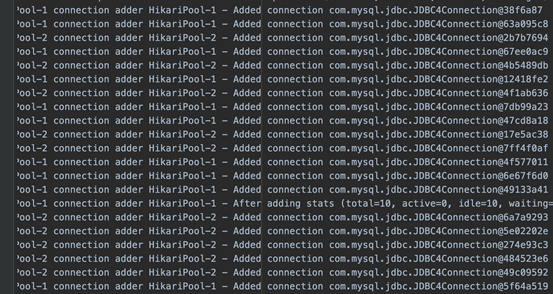

持续观察,1000s后理论上会产生220个对象(20 + 20 * 1000s / 100s),查看 jvisualvm 如下

实验结果分析
再结合我们生产的问题,假设我们每天14个小时高峰期(12:00 ~ 凌晨2:00),期间连接数20,10个小时低峰期,期间连接数10,每次 full gc 间隔14天,等到下次 full gc 堆积的 NonRegisteringDriver 对象为 (20 * 14 + 10 * 10) * 2 * 14 = 10640,与问题dump里面NonRegisteringDriver对象的数量10140 个基本吻合。
至此问题根源已经得到完全确认!!!
四、问题解决方案
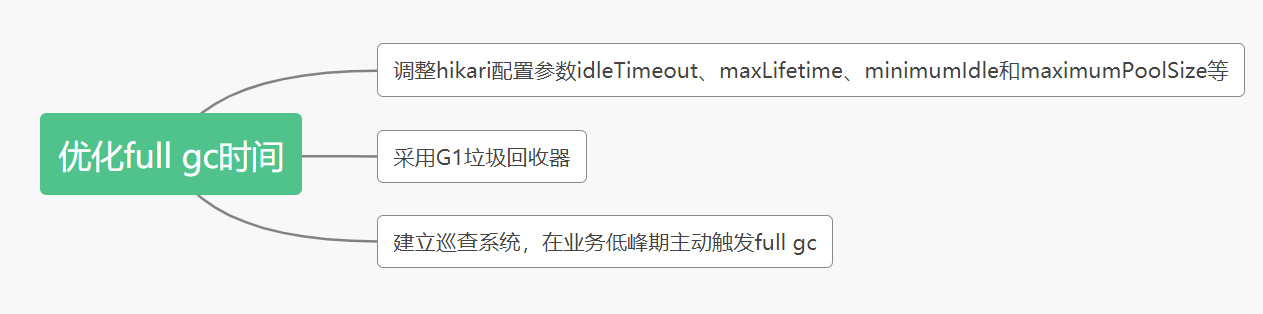
由上面分析可知,问题产生的废弃的数据库连接对象堆积,最终导致 full gc 时间过长。所以我们可以从以下方面思考解决方案:
- 1、减少废弃的数据连接对象的产生和堆积。
- 2、优化full gc时间.
【调整hikari参数】
我们可以考虑设置 maxLifetime 为一个较大的值,用于延长连接的生命周期,减少产生被废弃的数据库连接的频率,等到下次 full gc 的时候需要清理的数据库连接对象会大大减少。
Hikari 推荐 maxLifetime 设置为比数据库的 wait_timeout 时间少 30s 到 1min。如果你使用的是 mysql 数据库,可以使用 show global variables like '%timeout%'; 查看 wait_timeout,默认为 8 小时。
下面开始验证,设置maxLifetime = 1小时,其他条件不变。压测启动前观察jvisualvm,NonRegisteringDriver 对象数量为20


同时另外注意:minimumIdle和maximumPoolSize不要设置得太大,一般来说配置minimumIdle=10,maximumPoolSize=10~20即可。
【使用G1回收器】
G1回收器是目前java垃圾回收器的最新成果,是一款低延迟高吞吐的优秀回收器,用户可以自定义最大暂停时间目标,G1会尽可能在达到高吞吐量同时满足垃圾收集暂停时间目标。
下面开始验证G1回收器的实用性,该验证过程需要一段较长时间的观察,同时借助链路追踪工具skywalking。最终观察了10天,结果图如下: 使用G1回收器,部分jvm参数-Xms3G -Xmx3G -XX:+UseG1GC

使用java 8默认的Parallel GC回收器组合,部分jvm参数-Xms3G -Xmx3G

- 1、堆内存,分为已使用和空闲内存。
- 2、方法区内存,这个不需要关注
- 3、young gc和full gc时间
- 4、程序启动以后young gc和full gc次数
我们可以看到使用Parallel GC回收器组合的服务消耗的内存速度较快,发生了6996次young gc且发生了一次full gc,full gc时间长达5s。另外一组使用G1回收器的服务消耗内存速度较为平稳,只发生3827次young gc且没有发生full gc。由此可以看到G1回收器确实可以用来解决我们的数据库连接对象堆积问题。
【建立巡查系统】
这个我们目前还没有经过实践,但是根据上面分析结果判断,定期触发full gc可以达到每次清理少量堆积的数据库连接的作用,避免过多数据库连接一直堆积。采用该方法需要对业务的内容和高低峰周期非常熟悉。实现思路参考如下:
- 1、创建java程序,使用定时任务定期调用System.gc()。该方法的缺点是即使手动调用了System.gc(),jvm不一定会立刻开始回收工作,有可能会根据它本身的算法,自行选择最优时间才开始进行回收工作。
- 2、创建shell脚本调用jmap -dump:live,file=dump_001.bin PID,使用linux的crontab任务保证定时执行,执行完后再把dump_001.bin删掉即可。该方法能保证一定发生full gc,缺点是功能过于单一零散,不好集中管理。
五、总结
我们这次问题产生的根源是数据库连接对象堆积,导致full gc时间过长。解决思路可以从以下三点入手:
- 1、调整hikari配置参数。例如把maxLifetime设置为较大的值(比数据库的wait_timeout少30s),minimumIdle和maximumPoolSize值不能设置太大,或者直接采用默认值即可。
- 2、采用G1垃圾回收器。
- 3、建立巡查系统,在业务低峰期主动触发full gc。
个人公众号

- 如果你是个爱学习的好孩子,可以关注我公众号,一起学习讨论。
- 如果你觉得本文有哪些不正确的地方,可以评论,也可以关注我公众号,私聊我,大家一起学习进步哈。
- github地址:github.com/whx123/Java…
