

“不畏惧,不讲究,未来的日子好好努力” ;大家好,我是小芝麻😄
本文脑图较多,方便梳理,适合:前端小白
今天小芝麻主要想阐述的就是一个问题:
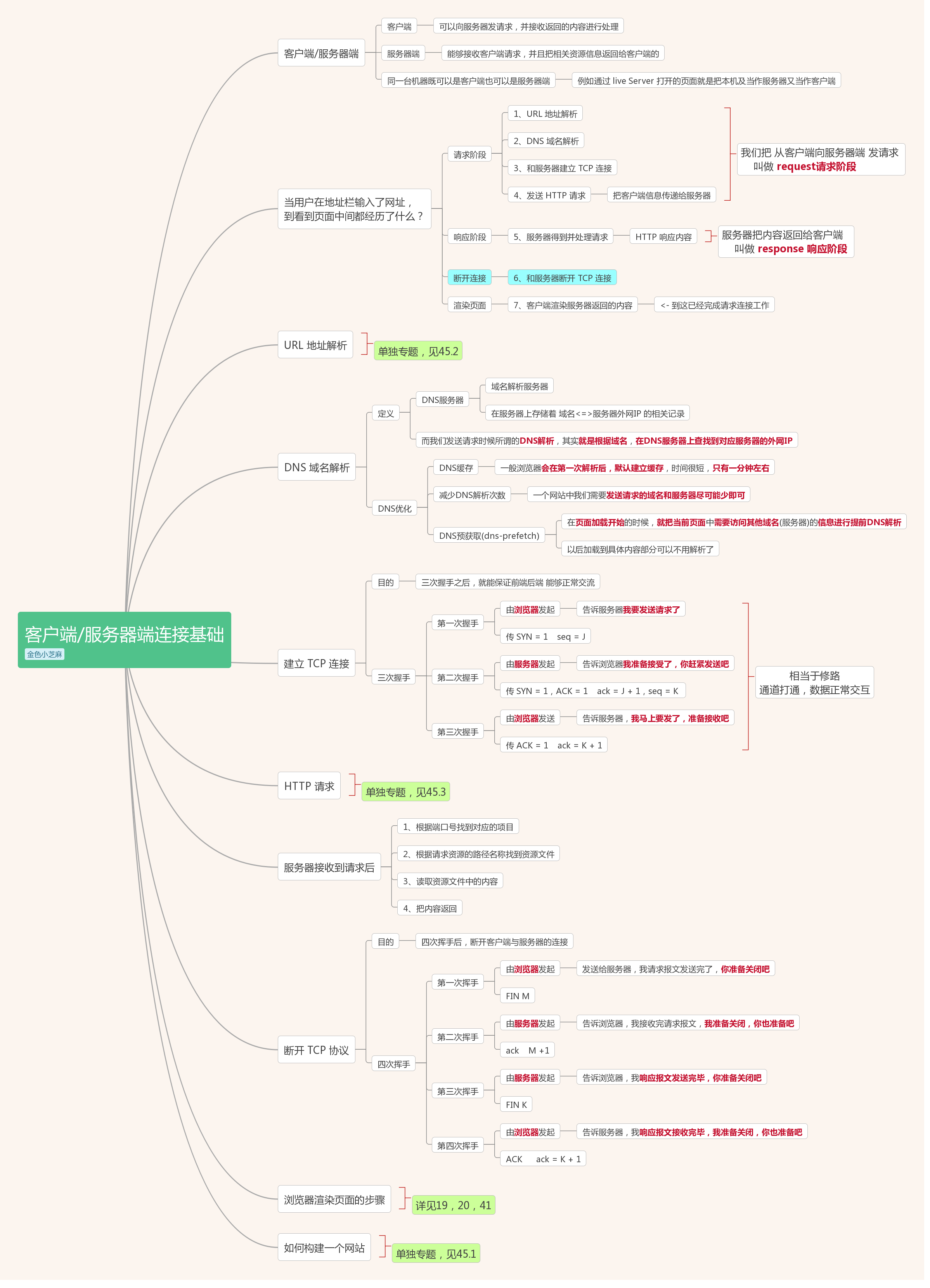
当用户在地址栏输入了网址,到看到页面中间都经历了什么?
request请求阶段
- 1、URL 地址解析
- 2、DNS 域名解析
- 3、和服务器建立 TCP 连接
- 4、发送 HTTP 请求
response 响应阶段
- 5、服务器得到并处理请求
断开连接
- 6、和服务器断开 TCP 连接
渲染页面
- 7、客户端渲染服务器返回的内容
下面我们会详细阐述以上几个方面具体都是啥;
客户端/服务器端
在开始正题之前,我们先了解以下,这两个概念;
- 客户端:可以向服务器发请求,并接收返回的内容进行处理
- 服务器端:能够接收客户端请求,并且把相关资源信息返回给客户端的
具体交互如图:

好的下面进入正题
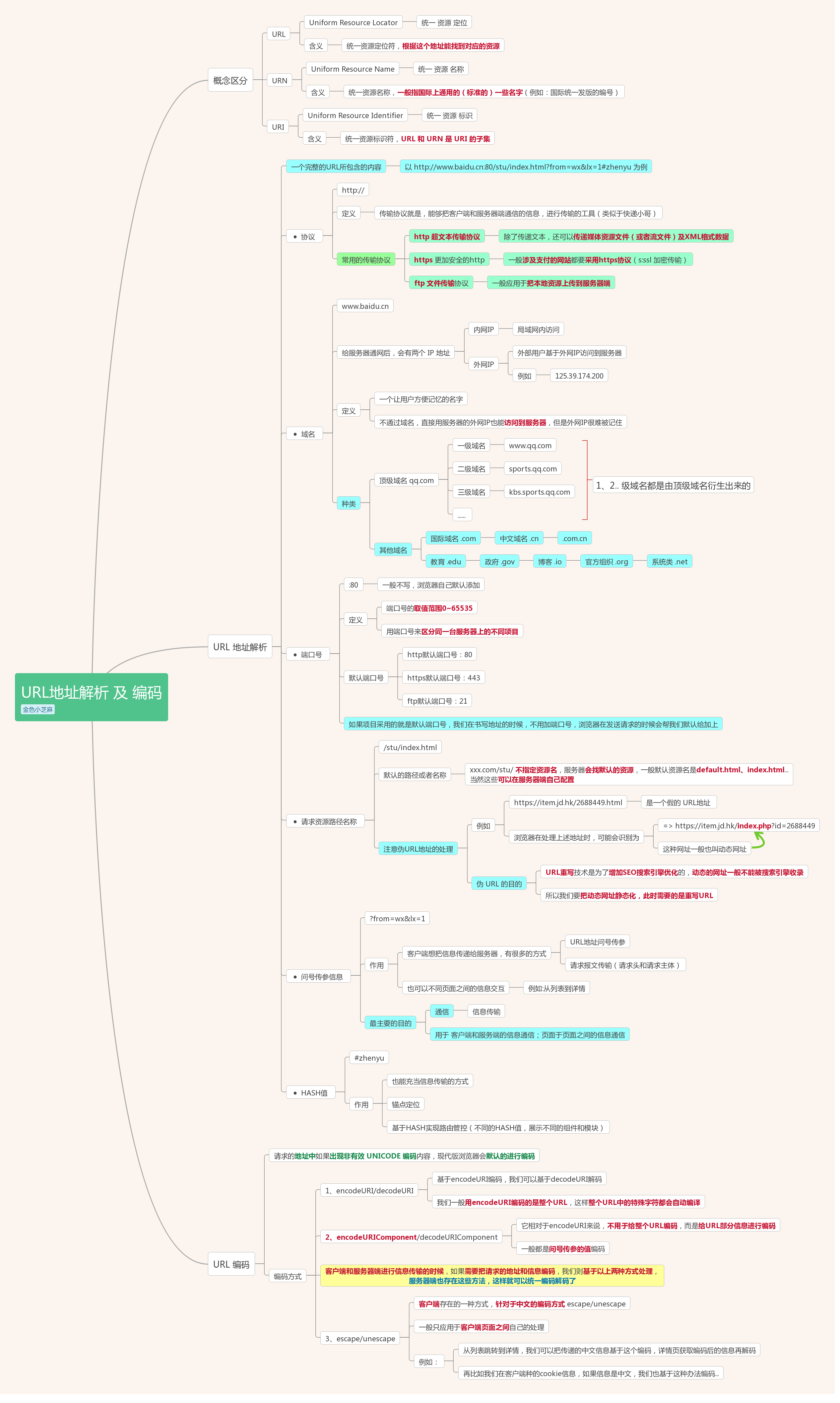
一、URL 地址解析
前面的文章里写过关于 URL参数处理的问题,那到底什么是URL呢?
1、URL/URN/URI概念区分
- URL:全称:Uniform Resource Locator(统一 资源 定位)
- 定义:统一资源定位符,根据这个地址能找到对应的资源
- URN:全称:Uniform Resource Name(统一 资源 名称)
- 定义:统一资源名称,一般指国际上通用的(标准的)一些名字(例如:国际统一发版的编号)
- URI:全称:Uniform Resource Identifier(统一 资源 标识)
- 定义:统一资源标识符,URL 和 URN 是 URI 的子集
2、URL 地址解析
一个完整的URL所包含的内容
-1)协议:(http://)
- 定义:传输协议就是,能够把客户端和服务器端通信的信息,进行传输的工具(类似于快递小哥)
- 常用的传输协议:
- http 超文本传输协议:除了传递文本,还可以传递媒体资源文件(或者流文件)及XML格式数据
- https 更加安全的http:一般涉及支付的网站都要采用https协议(s:ssl 加密传输)
- ftp 文件传输协议:一般应用于把本地资源上传到服务器端
-2)域名:(www.baidu.cn)
给服务器通网后,会有两个 IP 地址:
- 内网IP:局域网内访问
- 外网IP:外部用户基于外网IP访问到服务器(例如:125.39.174.200)
- 定义:就是一个让用户方便记忆的名字(不通过域名,直接用服务器的外网IP也能访问到服务器,但是外网IP很难被记住)
- 种类:
- 顶级域名:例如 qq.com
- 一级域名: 例如 www.qq.com
- 二级域名: 例如 sports.qq.com
- 三级域名: 例如 kbs.sports.qq.com
- .com 国际域名
- .cn 中文域名
- .com.cn
- .edu 教育
- .gov 政府(千万不要在这种域名下干什么事情哦😄)
- .io 博客
- .org 官方组织
- .net 系统类
- ......
一级、二级、三级...域名都是由顶级域名衍生出来的,所以,公司在注册域名的时候,只要买下顶级域名就可以了,就例如 qq.com ,只需要买下 qq.com 就可以用 www.qq.com、sports.qq.com、kbs.sports.qq.com...等域名了。
-3)端口号:(:80)
- 定义:用端口号来区分同一台服务器上的不同项目(端口号的取值范围0~65535)
- 默认端口号:
- http默认端口号:80
- https默认端口号:443
- ftp默认端口号:21
如果项目采用的就是默认端口号,我们在书写地址的时候,不用加端口号,浏览器在发送请求的时候会帮我们默认给加上
-4)请求资源路径名称:(/stu/index.html)
-
默认的路径或者名称:xxx.com/stu/ 不指定资源名,服务器会找默认的资源,一般默认资源名是default.html、index.html... 当然这些可以在服务器端自己配置
-
注意伪URL地址的处理:
- 例如:item.jd.hk/2688449.htm… 是一个假的 URL地址
- 浏览器在处理上述地址时,可能会识别为=> item.jd.hk/index.php?i…
-
伪 URL 的目的:URL重写技术是为了增加SEO搜索引擎优化的,动态的网址一般不能被搜索引擎收录(所以我们要把动态网址静态化,此时需要的是重写URL)
-5)问号传参信息:(?from=wx&lx=1)
- 作用:
- 客户端想把信息传递给服务器,有很多的方式(URL地址问号传参)和(请求报文传输(请求头和请求主体))
- 也可以不同页面之间的信息交互
- 最主要的目的:通信 => 信息传输
- 用于 客户端和服务端的信息通信;页面于页面之间的信息通信
-6)HASH值:(#zhenyu)
- 作用:
- 也能充当信息传输的方式
- 锚点定位
- 基于HASH实现路由管控(不同的HASH值,展示不同的组件和模块)
3、URL 编码
请求的地址中如果出现非有效 UNICODE 编码内容,现代版浏览器会默认的进行编码
编码方式:
- 1、encodeURI/decodeURI
- 基于encodeURI编码,我们可以基于decodeURI解码,
- 我们一般用encodeURI编码的是整个URL,这样整个URL中的特殊字符都会自动编译
- 2、encodeURIComponent/decodeURIComponent
- 它相对于encodeURI来说,不用于给整个URL编码,而是给URL部分信息进行编码
- 一般都是问号传参的值编码
客户端和服务器端进行信息传输的时候,如果需要把请求的地址和信息编码,我们则基于以上两种方式处理, 服务器端也存在这些方法,这样就可以统一编码解码了
-
3、escape/unescape
- 客户端存在的一种方式,针对于中文的编码方式 escape/unescape
- 一般只应用于客户端页面之间自己的处理
例如:从列表跳转到详情,我们可以把传递的中文信息基于这个编码,详情页获取编码后的信息再解码,再比如我们在客户端种的cookie信息,如果信息是中文,我们也基于这种办法编码...
二、DNS 域名解析
- DNS服务器:又叫做域名解析服务器,
- 在这个服务器上存储着 域名<=>服务器外网IP 的相关记录
而我们发送请求时候所谓的DNS解析,其实就是根据域名,在DNS服务器上查找到对应服务器的外网IP
-
本地解析查找过程:

-
非本地解析:
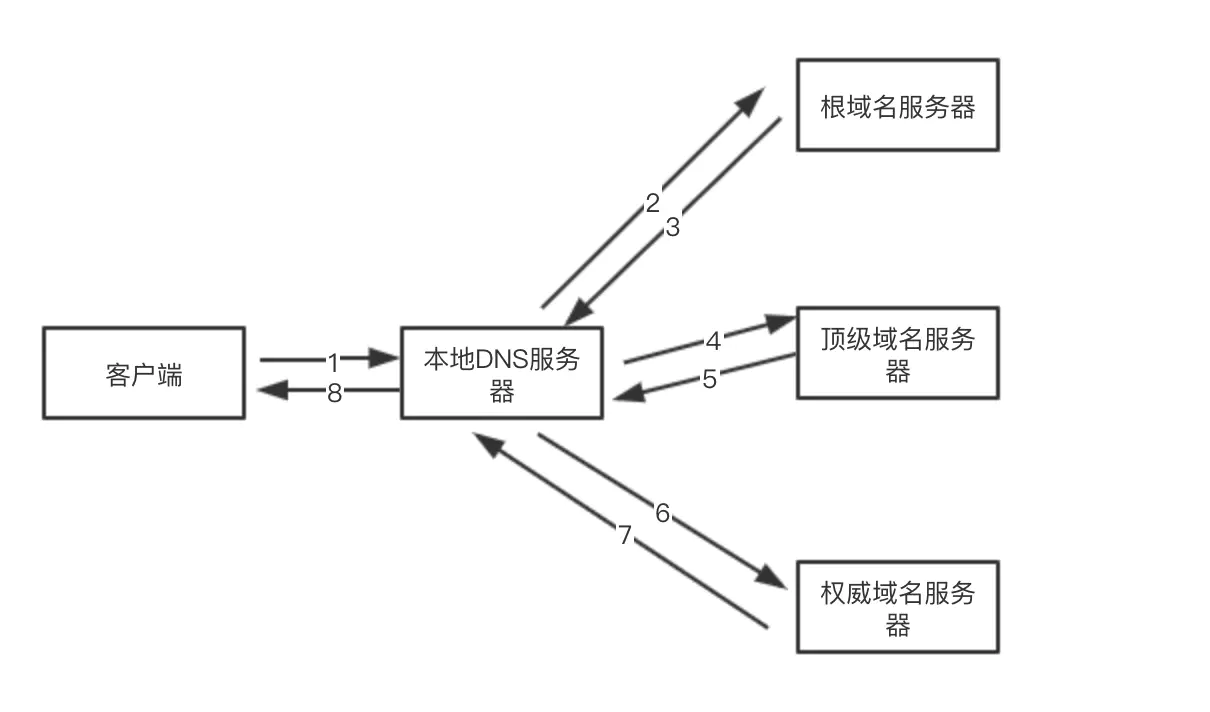
-
DNS优化:
DNS缓存:一般浏览器会在第一次解析后,默认建立缓存,时间很短,只有一分钟左右
- 减少DNS解析次数:一个网站中我们需要发送请求的域名和服务器尽可能少即可
- DNS预获取(dns-prefetch):在页面加载开始的时候,就把当前页面中需要访问其他域名(服务器)的信息进行提前DNS解析,以后加载到具体内容部分可以不用解析了
三、建立 TCP 连接(TCP的三次握手)
- 目的:三次握手之后,就能保证前端后端 能够正常交流(相当于修路 通道打通,数据才能正常交互)
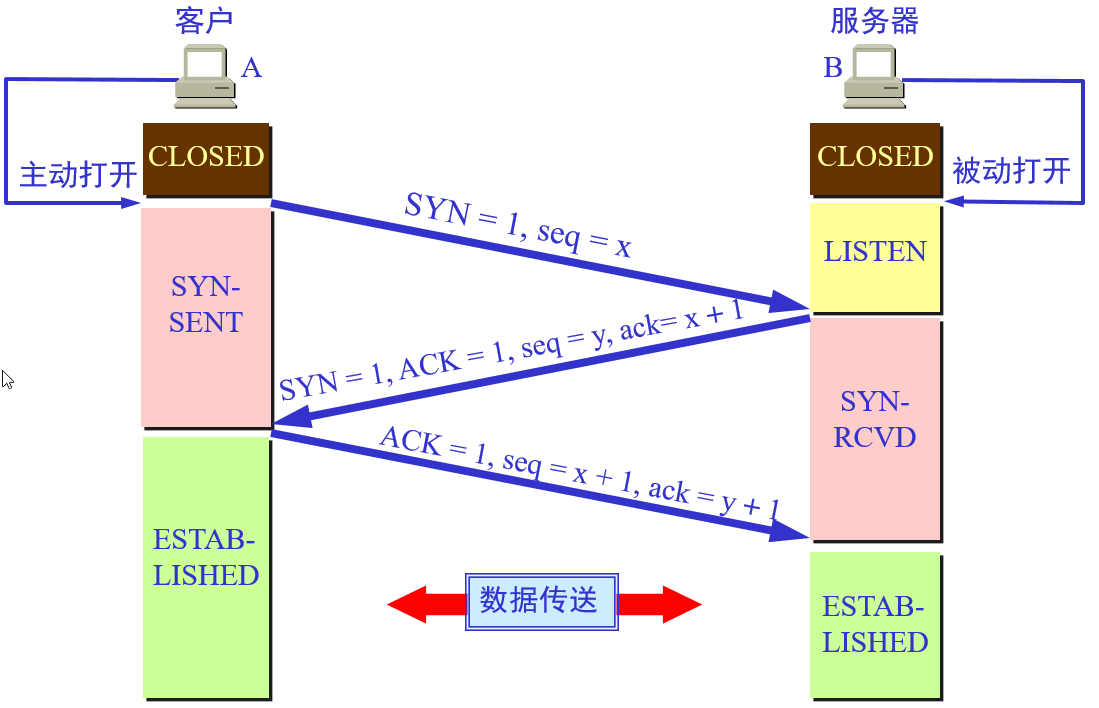
- 第一次握手:
- 建立连接时,客户端发送syn包(seq=x)到服务器,并进入SYN_SENT状态,等待服务器确认;
SYN:同步序列编号(Synchronize Sequence Numbers)。
- 建立连接时,客户端发送syn包(seq=x)到服务器,并进入SYN_SENT状态,等待服务器确认;
- 第二次握手:
- 服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(seq=y),即SYN+ACK包,此时服务器进入SYN_RECV状态。
- 第三次握手:
- 客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
以上是说的太过正式,下面说个白话版的👇:其实就类似于两个人打招呼的过程;
- 第一次握手:
- 由浏览器发起:告诉服务器我要发送请求了
- 传 SYN = 1 seq = x ;(先出个题考考服务器)
- 第二次握手:
- 由服务器发起:告诉浏览器我准备接受了,你赶紧发送吧
- 传 SYN = 1,ACK = 1 ack = x + 1,seq = y ;(看到浏览器出的题,解答完成,并且也给浏览器出了个题,一起返回给浏览器)
- 第三次握手:
- 由浏览器发送:告诉服务器,我马上要发了,准备接收吧
- 传 ACK = 1 ack = y + 1;(做完服务器给出得题,返回给服务器)
到此双方试探成功,建立友好的关系👬;(这条路算是打通了)
没有错,不要怀疑,就是这么简单~~
有了路之后,怎么传递数据呢,我们还需要个快递小哥;(HTTP 就是快递小哥了)
四、发送 HTTP 请求
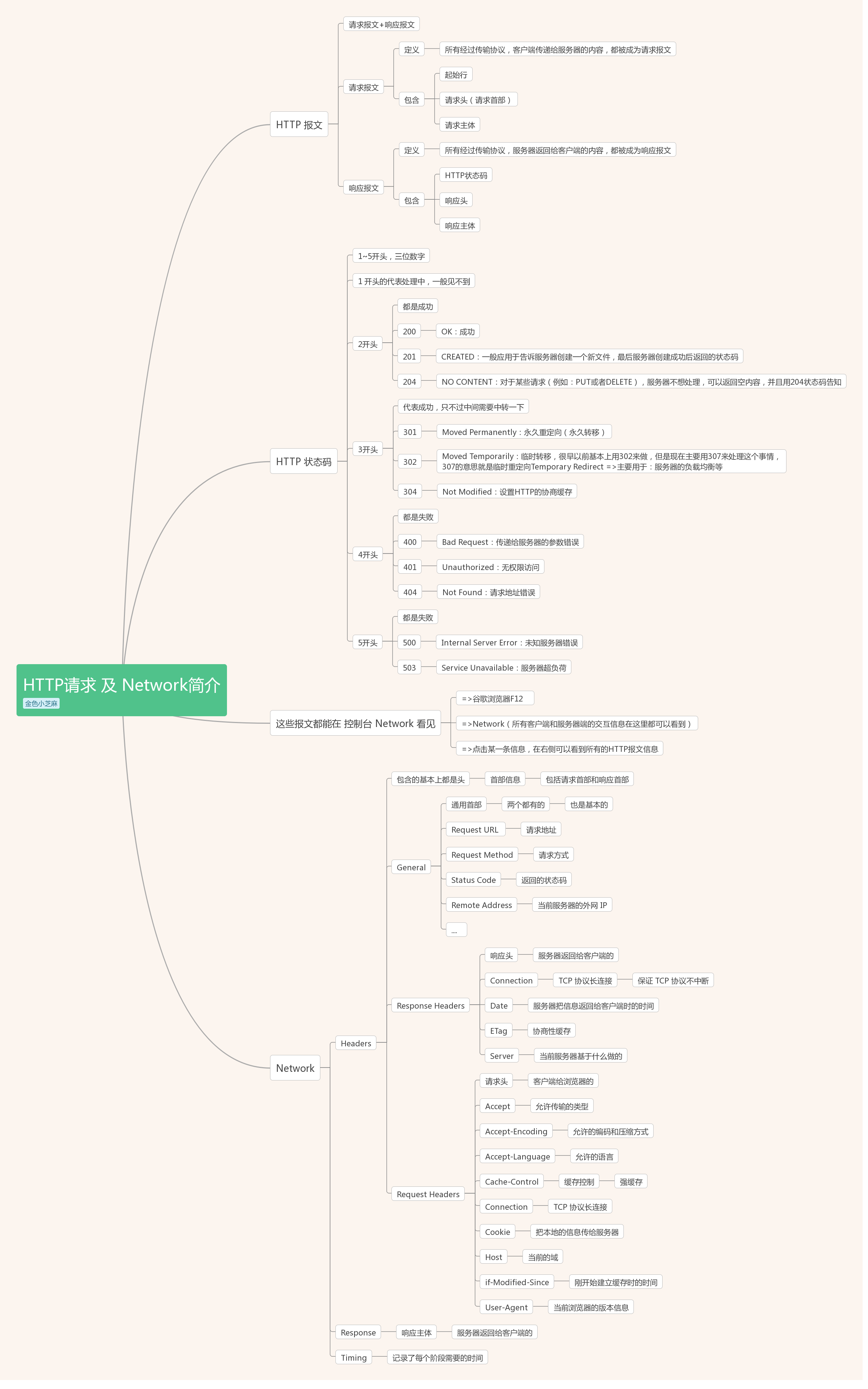
1、HTTP 报文
HTTP 报文是由 请求报文+响应报文 共同组成
- 请求报文:
- 定义:所有经过传输协议,客户端传递给服务器的内容,都被成为请求报文
- 包含:
- 起始行
- 请求头(请求首部)
- 请求主体
- 响应报文:
- 定义:所有经过传输协议,服务器返回给客户端的内容,都被成为响应报文
- 包含:
- HTTP状态码
- 响应头
- 响应主体
至于报文是啥?在哪查看我们一会再说,先看下常用的状态码有哪些;
2、HTTP 状态码
1~5开头,三位数字
- 1 开头的代表处理中,一般见不到
- 2开头:都是成功
- 200:OK:成功
- 201:CREATED:一般应用于告诉服务器创建一个新文件,最后服务器创建成功后返回的状态码
- 204:NO CONTENT:对于某些请求(例如:PUT或者DELETE),服务器不想处理,可以返回空内容,并且用204状态码告知
- 3开头:代表成功,只不过中间需要中转一下
- 301:Moved Permanently:永久重定向(永久转移)
- 302:Moved Temporarily:临时转移,很早以前基本上用302来做,但是现在主要用307来处理这个事情,
- 307的意思就是临时重定向Temporary Redirect =>主要用于:服务器的负载均衡等
- 304:Not Modified:设置HTTP的协商缓存
- 4开头:都是失败
- 400:Bad Request:传递给服务器的参数错误
- 401:Unauthorized:无权限访问
- 404:Not Found:请求地址错误
- 5开头:都是失败
- 500:Internal Server Error:未知服务器错误
- 503:Service Unavailable:服务器超负荷
3、这些报文都能在 控制台 Network 看见
=>谷歌浏览器F12
=>Network(所有客户端和服务器端的交互信息在这里都可以看到)
=>点击某一条信息,在右侧可以看到所有的HTTP报文信息
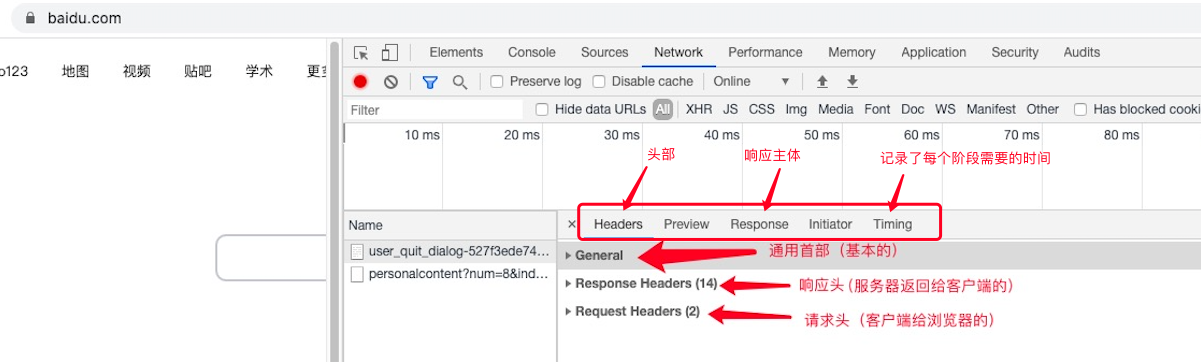
上图就是了😄,接下来我们看几个常用的
- Headers:包含的基本上都是头,首部信息(包括请求首部和响应首部)
- General:通用首部,两个都有的,也是基本的

- Request URL :请求地址
- Request Method:请求方式
- Status Code:返回的状态码
- Remote Address:当前服务器的外网 IP
- ......
- Response Headers:响应头,服务器返回给客户端的
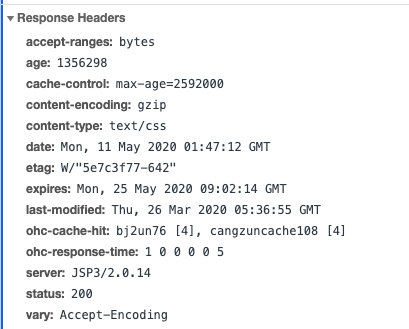
- Date:服务器把信息返回给客户端时的时间
- ETag:协商性缓存
- Server:当前服务器基于什么做的
- ......
- Request Headers:请求头,客户端给浏览器的
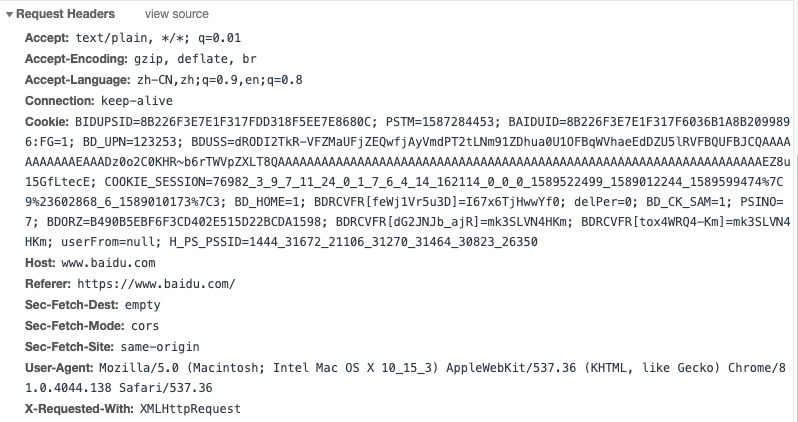
- Accept:允许传输的类型
- Accept-Encoding:允许的编码和压缩方式
- Accept-Language:允许的语言
- Connection:TCP 协议长连接
- Cookie:把本地的信息传给服务器
- Host:当前的域
- User-Agent:当前浏览器的版本信息
- ......
- General:通用首部,两个都有的,也是基本的
- Response:响应主体,服务器返回给客户端的
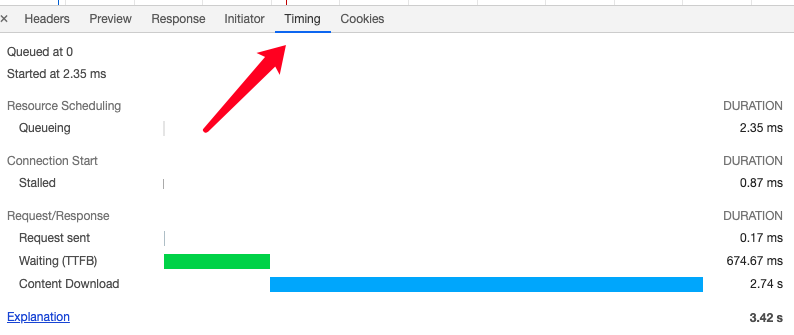
- Timing:记录了每个阶段需要的时间
4、HTTP的请求方式
主要分两种:
- GET 系列请求
- POST 系列请求
不论GET和POST都可以把信息传递给服务器,也能从服务器获取到结果
GET 与 POST 系列请求的区别(所谓的区别都是约定俗成的,并没有一定要这样做的规定)
- GET 系列请求:一般用于从服务器获取信息(GET:给的少,拿的多)
- GET
- DELETE:一般应用于告诉服务器,从服务器上删除点东西
- HEAD:只想获取响应头内容,告诉服务器响应主体内容不要了
- OPTIONS:试探性请求,发个请求给服务器,看看服务器能不能接收到,能不能返回
- POST 系列请求:一般用于给服务器推送信息(POST:给的多,拿的少)
- POST
- PUT:和DELETE对应,一般是想让服务器把我传递的信息存储到服务器上(一般应用于文件和大型数据内容)
本质区别
-
GET系列传递给服务器信息的方式一般采用:问号传参
-
POST系列传递给服务器信息的方式一般采用:设置请求主体
本质区别所导致的问题
- 1、GET传递给服务器的内容比POST少,因为URL有最长大小限制
- GET:xhr.open('GET','/list?name=xiaozhima&year=18&xxx=xxx...')
- IE浏览器一般限制2KB,谷歌浏览器一般限制4~8KB,超过长度的部分自动被浏览器截取了
- POST:xhr.send('....')
- 请求主体中传递的内容理论上没有大小限制,但是项目中,为了保证传输的速度,我们会自己限制一些
- GET:xhr.open('GET','/list?name=xiaozhima&year=18&xxx=xxx...')
- 2、GET会产生缓存(缓存不是自己可控制的)
- 因为请求的地址(尤其是问号传递的信息一样),浏览器有时候会认为你要和上次请求的数据一样,拿的是上一次信息;
- 这种缓存我们不期望有,我们期望的缓存是自己可控制的;所以项目中,如果一个地址,GET请求多次,我们要去除这个缓存;
- 解决办法:设置随机数
- xhr.open('GET','/list?name=xiaozhima&_='+Math.random());
- 3、GET相比较POST来说不安全(只是相对他俩来说)
- GET是基于问号传参传递给服务器内容,有一种技术叫做URL劫持,这样别人可以获取或者篡改传递的信息;
- 而POST基于请求主体传递信息,不容易被劫持;
好了,HTTP请求就先说到这里😄
服务器接收到请求后:
- 1、根据端口号找到对应的项目
- 2、根据请求资源的路径名称找到资源文件
- 3、读取资源文件中的内容
- 4、把内容返回
五、断开 TCP 协议(TCP四次挥手)
上面我们说 建立 TCP 连接,就是修路,HTTP 就是快递小哥,在小哥送完快递后,我们就要把之前修好的路拆掉,就有了 TCP 四次挥手
- 目的:四次挥手后,断开客户端与服务器的连接
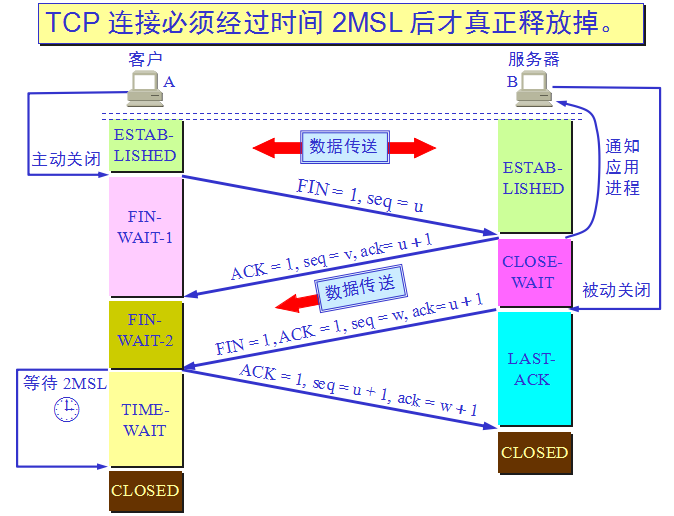
- 第一次挥手:
- 客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。
- 第二次挥手:
- 服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
- 第三次挥手:
- 服务器B关闭与客户端A的连接,发送一个FIN给客户端A。
- 第四次挥手:
- 客户端A发回ACK报文确认,并将确认序号设置为收到序号加1。
白话文翻译👇:
- 第一次挥手:
- 由浏览器发起,发送给服务器,我请求报文发送完了,你准备关闭吧
- 第二次挥手:
- 由服务器发起,告诉浏览器,我接收完请求报文,我准备关闭,你也准备吧
- 第三次挥手:
- 由服务器发起,告诉浏览器,我响应报文发送完毕,你准备关闭吧
- 第四次挥手:
- 由浏览器发起,告诉服务器,我响应报文接收完毕,我准备关闭,你也准备吧
为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
- 这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。
- 但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;
- 但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,
- 也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
六、浏览器渲染页面的步骤
这篇我们之前写过浏览器渲染页面的主体流程,这次我们把主要的步骤在写一下。
1、生成 DOM 树
渲染了所有的 HTML 标签
- 转换
- 通过 HTTP 返还的首先是十六进制的编码字节数据
- 拿到字节数据后,浏览器会通过内部的机制,把数据转换成我们能看到的代码
- 令牌
- 按照
W3C规范(第五代版本的规范H5)的规则,转换成我们能看懂的标签
- 按照
- 词法分析
- 通过转换后的标签,进行词法解析,生成
DOM节点
- 通过转换后的标签,进行词法解析,生成
- DOM构建
- 最后通过查找每个
DOM节点之间的关系,生成DOM树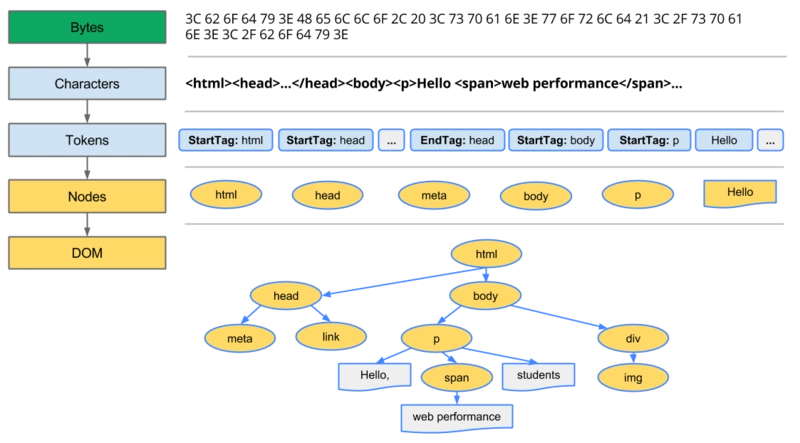
- 最后通过查找每个
2、生成 CSSOM 树
请求回来 CSS 后,渲染完 CSS
同生成DOM树一样的过程生成CSSOM树
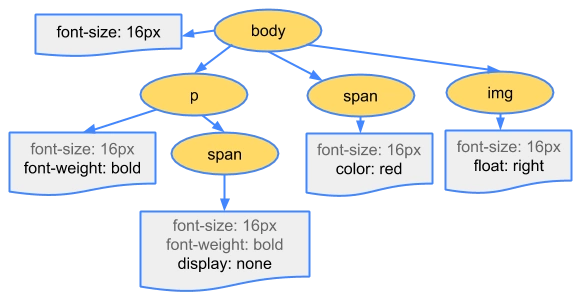
3、DOM 树 + CSSOM 树 => RENDER-TREE(渲染树)
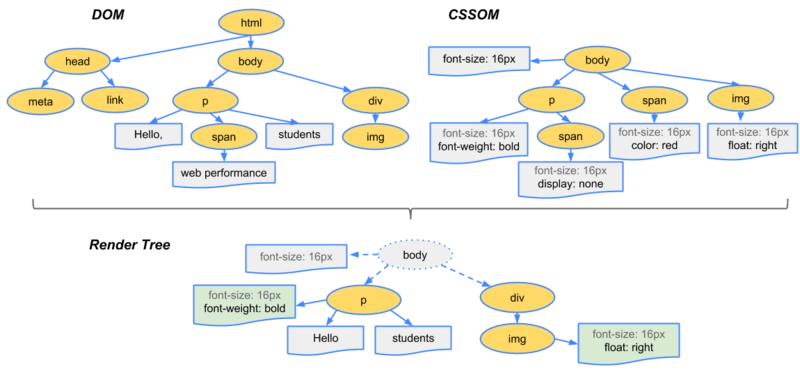
4、 布局(Layout)或 重排/回流(reflow)
按照
RENDER-TREE在设备的视口中进行结构和位置的相关计算=>布局(Layout)或 重排/回流(reflow)
5、绘制(painting)或 栅格化(rasterizing)
根据渲染树以及回流得到的几何信息,得到节点的绝对像素=>绘制(painting)或 栅格化(rasterizing)
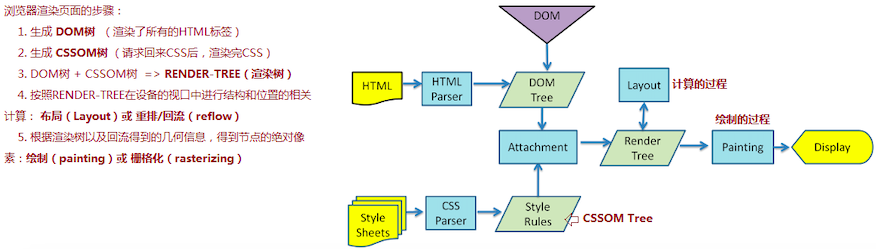
到此 “当用户在地址栏输入了网址,到看到页面中间都经历了什么?”这道题我们算是解答完了。
作为前端我们在写代码的时候,都是通过 AJAX 向服务器发送请求,下面我们在说一下 AJAX 的基础知识和操作
AJAX 的基础知识和操作
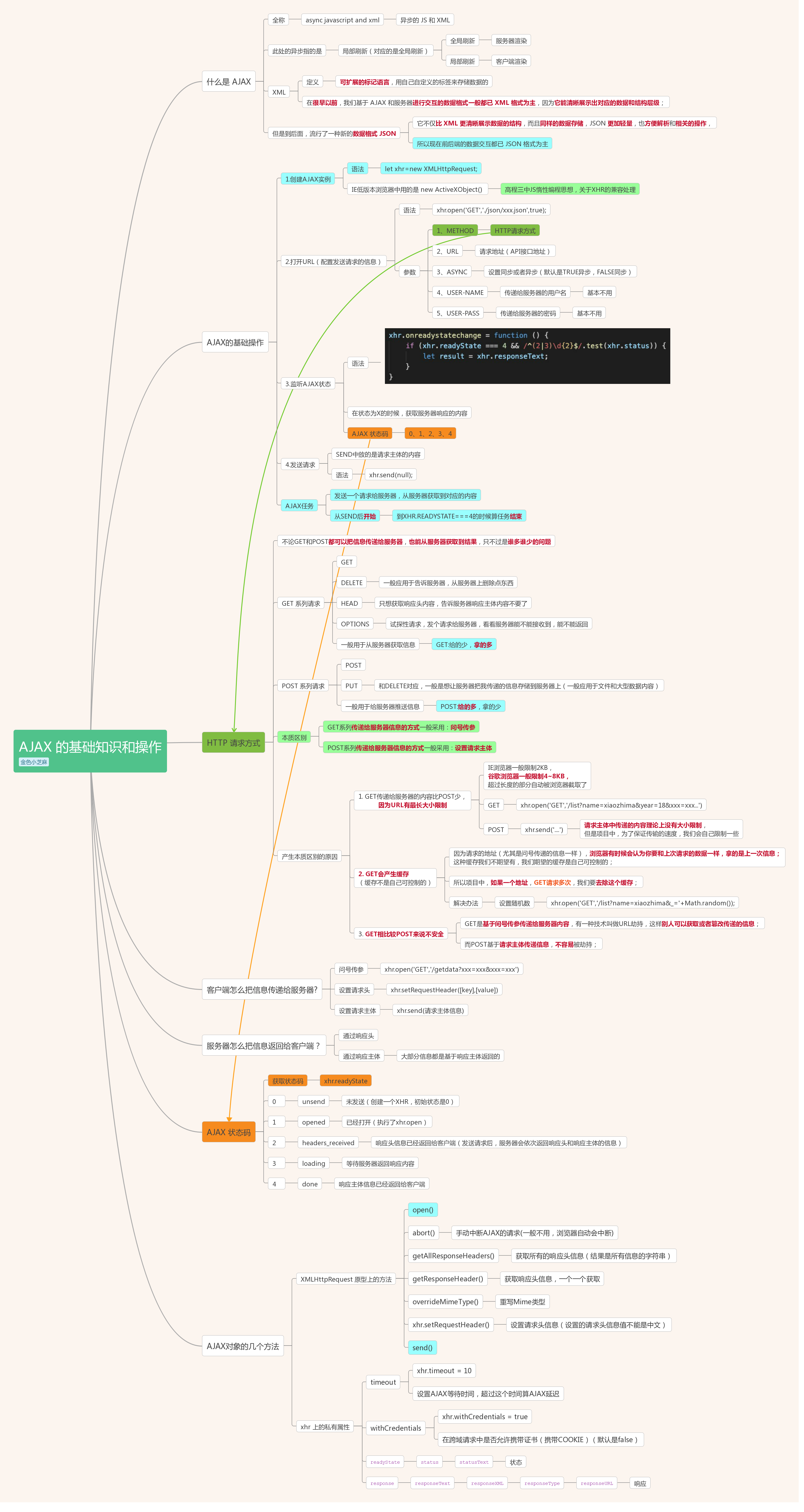
一、什么是 AJAX
全称:async javascript and xml(异步的 JS 和 XML)
-
此处的异步指的是:局部刷新(对应的是全局刷新)
-
全局刷新:服务器渲染
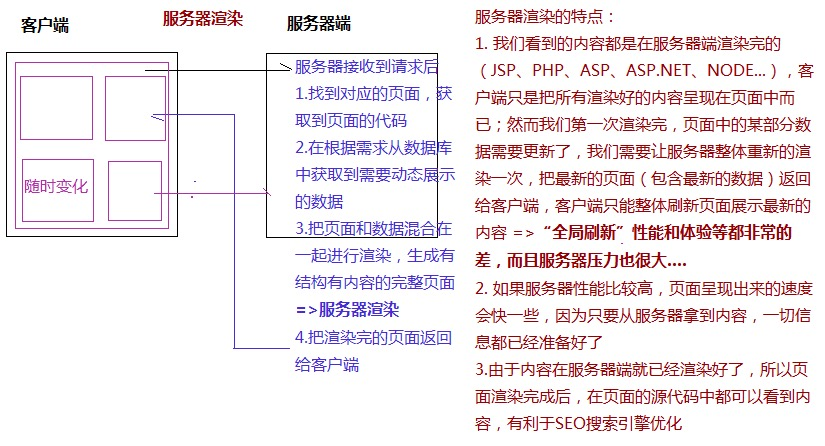
-
局部刷新:客户端渲染
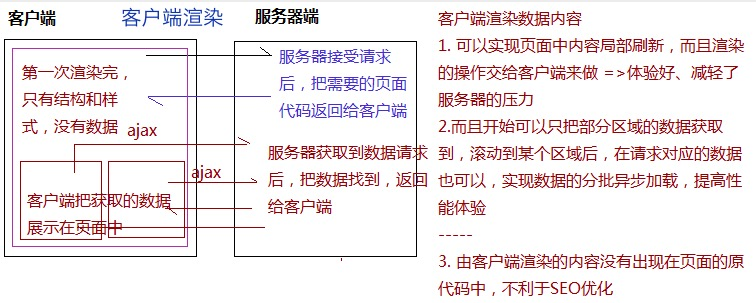
-
-
XML:可扩展的标记语言,用自己自定义的标签来存储数据的
- (在很早以前,我们基于 AJAX 和服务器进行交互的数据格式一般都已 XML 格式为主,因为它能清晰展示出对应的数据和结构层级;
- 但是到后面,流行了一种新的数据格式 JSON,它不仅比 XML 更清晰展示数据的结构,而且同样的数据存储,JSON 更加轻量,也方便解析和相关的操作,所以现在前后端的数据交互都已 JSON 格式为主)
XML 格式
<?xml version="1.0" encoding="UTF-8"?>
<root>
<student>
<name>张三</name>
<age>25</age>
<score>
<english>95</english>
</score>
</student>
<student>
<name>张三</name>
<age>25</age>
</student>
<student>
<name>张三</name>
<age>25</age>
</student>
</root>
JSON 格式
[{
"name": "张三",
"age": 25,
"score": {
"english": 95
}
}, {
"name": "张三",
"age": 25
}, {
"name": "张三",
"age": 25
}]
二、AJAX的基础操作
AJAX任务:发送一个请求给服务器,从服务器获取到对应的内容是从SEND后开始到XHR.READYSTATE===4的时候算任务结束
核心四步
-
1.创建AJAX实例
- 语法:let xhr=new XMLHttpRequest;
- IE低版本浏览器中用的是 new ActiveXObject() (高程三中JS惰性编程思想,关于XHR的兼容处理)
-
2.打开URL(配置发送请求的信息)
- 语法:xhr.open('GET','./json/xxx.json',true);
- 参数:
- 1、METHOD:HTTP请求方式
- 2、URL:请求地址(API接口地址)
- 3、ASYNC:设置同步或者异步(默认是TRUE异步,FALSE同步)
- 4、USER-NAME:传递给服务器的用户名(基本不用)
- 5、USER-PASS:传递给服务器的密码(基本不用)
-
3.监听AJAX状态

- 在状态为X的时候,获取服务器响应的内容
- AJAX 状态码:
- 获取状态码:xhr.readyState
- 0:unsend:未发送(创建一个XHR,初始状态是0)
- 1:opened:已经打开(执行了xhr.open)
- 2:headers_received:响应头信息已经返回给客户端(发送请求后,服务器会依次返回响应头和响应主体的信息)
- 3:loading:等待服务器返回响应内容
- 4:done:响应主体信息已经返回给客户端
-
4.发送请求
- 语法:xhr.send(null);
- SEND中放的是请求主体的内容
//1.创建AJAX实例
let xhr=new XMLHttpRequest;
//2.打开URL(配置发送请求的信息)
xhr.open('GET','./json/xxx.json',true);
//3.监听AJAX状态,在状态为X的时候,获取服务器响应的内容
xhr.onreadystatechange=function(){
if(xhr.readyState===4 && /^(2|3)\d{2}$/.test(xhr.status)){
let result = xhr.responseText;
}
}
//4.发送请求
//SEND中放的是请求主体的内容
xhr.send(null);
//=> AJAX任务(发送一个请求给服务器,从服务器获取到对应的内容)
//=> 从SEND后开始,到XHR.READYSTATE===4的时候算任务结束
三、AJAX对象的几个方法
- XMLHttpRequest 原型上的方法
- open()
- abort():手动中断AJAX的请求(一般不用,浏览器自动会中断)
- getAllResponseHeaders():获取所有的响应头信息(结果是所有信息的字符串)
- getResponseHeader():获取响应头信息,一个一个获取
- overrideMimeType():重写Mime类型
- xhr.setRequestHeader():设置请求头信息(设置的请求头信息值不能是中文)
- send()
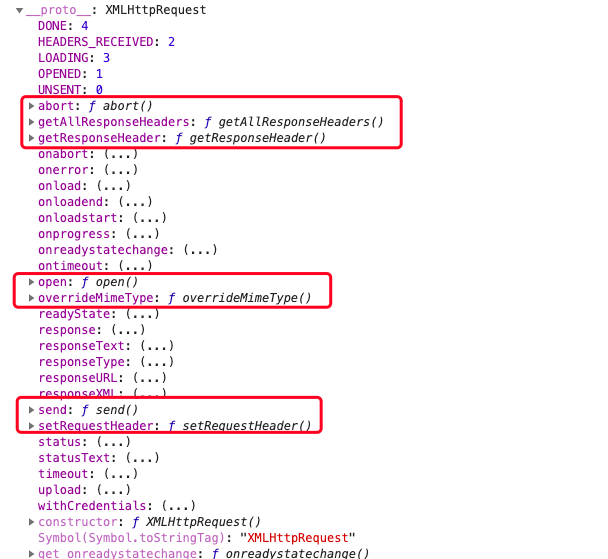
- xhr 上的私有属性:
- timeout:
- xhr.timeout = 10
- 设置AJAX等待时间,超过这个时间算AJAX延迟
- withCredentials:
- xhr.withCredentials = true
- 在跨域请求中是否允许携带证书(携带COOKIE)(默认是false)
- readyState/status/statusText
- response/responseText/responseXML/responseType/responseURL
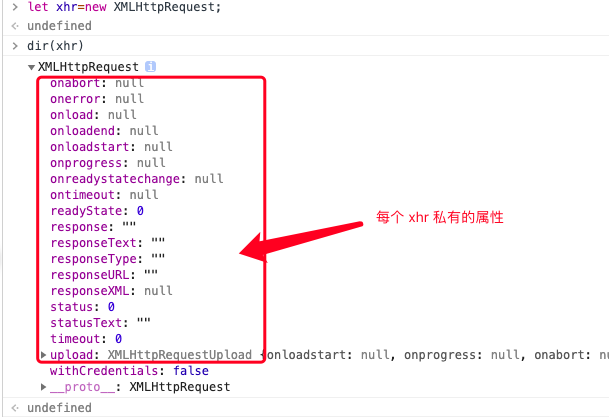
- timeout:
客户端怎么把信息传递给服务器?
- 问号传参:xhr.open('GET','/getdata?xxx=xxx&xxx=xxx')
- 设置请求头:xhr.setRequestHeader([key],[value])
- 设置请求主体:xhr.send(请求主体信息)
服务器怎么把信息返回给客户端?
- 通过响应头
- 通过响应主体(大部分信息都是基于响应主体返回的)
四、倒计时抢购案例
/*
* 倒计时抢购要注意的细节知识点:
* 1.计算剩余多久需要的时间不能是客户端本机的时间,需要获取服务器的时间
* (基于AJAX请求向服务器获取,但是也不能每隔1秒都去请求一次
* 【我们是第一次加载页面的时候,从服务器获取服务器时间,存储起来,后期我们把
* 这个时间自动的每隔1秒进行累加,页面刷新还需要从服务器获取】)
* 2.为了保证绝对安全,在购买的时候,服务器需要二次校验时间的合法性
* 3.降低服务器返回时间和真实时间的误差(减少服务器的响应时间)
* 1)请求方式基于HEAD,只获取响应头信息即可
* 2)在AJAX状态为2的时候处理,无需等到状态为4
*/
HTML
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0">
<title>Document</title>
<!-- IMPORT CSS -->
<style>
* {
margin: 0;
padding: 0;
}
#box {
box-sizing: border-box;
padding: 20px;
width: 200px;
margin: 20px auto;
background: lightblue;
line-height: 50px;
}
</style>
</head>
<body>
<div id="box">
距离秒杀还差:
<span id="content">00:00:00</span>
</div>
<!-- IMPORT JS -->
<script src="1.js"></script>
</body>
</html>
JS
let box = document.querySelector('#box'),
content = document.querySelector('#content'),
timer = null;
// 获取服务器时间
function getServerTime() {
return new Promise(resolve => {
let xhr = new XMLHttpRequest;
xhr.open('head', './data.json?_=' + Math.random());
xhr.onreadystatechange = () => {
if (xhr.readyState === 2 && /^(2|3)\d{2}$/.test(xhr.status)) {
let time = xhr.getResponseHeader('date');
// 获取的TIME是格林尼治时间 GMT(北京时间 GMT+0800)
time = new Date(time);
resolve(time);
}
};
xhr.send(null);
});
}
// 根据服务器时间计算倒计时
function computed(time) {
// time从服务器获取的当时间
// target是抢购的目标时间
// spanTime两个时间的毫秒差
let target = new Date('2020/05/13 15:57:35'),
spanTime = target - time;
if (spanTime <= 0) {
// 已经到达抢购的时间节点了
box.innerHTML = "开始抢购吧!";
clearInterval(timer);
return;
}
// 计算出毫秒差中包含多少小时、多少分钟、多少秒
let hours = Math.floor(spanTime / (60 * 60 * 1000));
spanTime = spanTime - hours * 60 * 60 * 1000;
let minutes = Math.floor(spanTime / (60 * 1000));
spanTime = spanTime - minutes * 60 * 1000;
let seconds = Math.floor(spanTime / 1000);
hours < 10 ? hours = '0' + hours : null;
minutes < 10 ? minutes = '0' + minutes : null;
seconds < 10 ? seconds = '0' + seconds : null;
content.innerHTML = `${hours}:${minutes}:${seconds}`;
}
getServerTime().then(time => {
// 获取到服务器时间后,计算倒计时
computed(time);
// 每间隔1秒中,让获取的时间累加1秒,在重新计算倒计时结果
timer = setInterval(() => {
time = new Date(time.getTime() + 1000);
computed(time);
}, 1000);
});
今天的文章到此结束,小芝麻自知还有很多不足,提升空间还有很大很大,感谢打什么批评指正🙏
