

这里记录一下学习与使用Protocol Buffer的笔记,优点缺点如何使用这里不再叙述,重点关注与理解Protocol Buffers的工作原理,其大概实现。
我们经常使用Protocol Buffer进行序列化与反序列化。理解Protocol Buffer的工作原理,就要理解序列化与反序列化。
- 序列化:将数据结构或对象转换为二进制串的过程;
- 反序列化:序列化的逆过程;
如何实现呢?核心有两点:编码 + 存储。数据在计算机间通过网络进行传输时,传输的是比特流,只有0和1,并没有你所定义的各种类对象等,你如果想将一个类对象传输到对方,怎么办呢?字符是用过ASCII码编码的,这里也可以设计一套编码方案来对类似类对象这种数据进行编码,只要对方收到后能正确的解码就可以了。编码后还要确定编码后的数据存储方式,这样字节流才是有意义的字节流,这样才能知道读取的字节流有什么含义,代表什么。
好了,我们看一下Protocol Buffer是如何编码和存储的。
Protocol Buffer是如何编码的
Varint编码
Varint编码是一种变长的编码方式,核心思想是对数值越小的数字,用越少的字节数表示,这样可以减少数字的字节数,进行数据压缩。
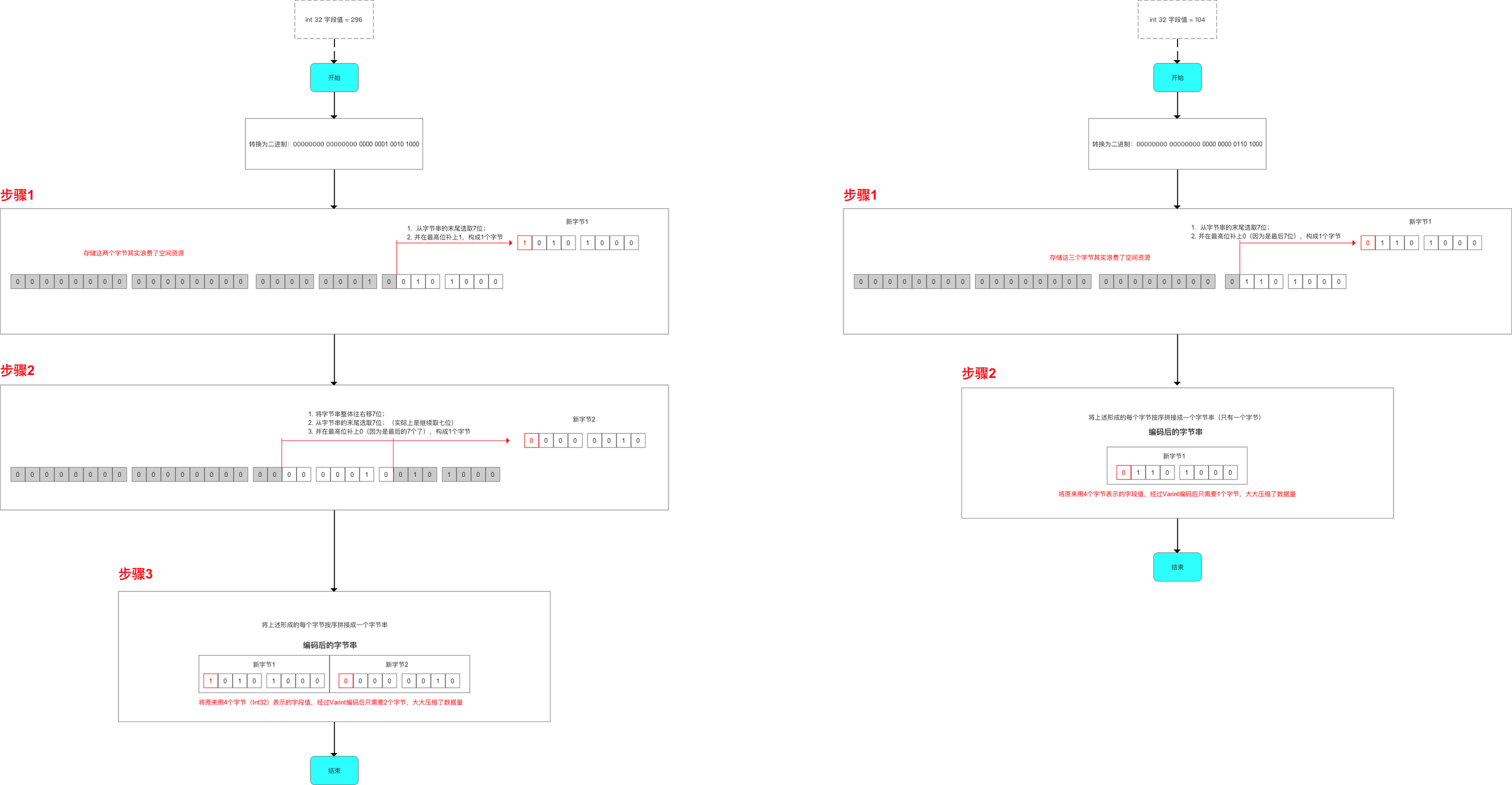
举个例子:对int数据类型,一般需要4个字节来表示,而实际上,对与数值较小的数字而言,无需这么多字节,00000000 00000000 00000000 01111111 | 127,只需要一个字节就能表示,前面3个字节意义不大,浪费了许多空间。
当然,这种编码并不是所有情况下都会变小,当数值非常大时,所需的字节会增多,但因为大多数情况下数值小的数字远比数值大的多,所以整体看来,数据是被压缩了的。
具体的,Varint编码时,对每个字节的最高位赋予特殊含义:
- 1:表示后序的字节也是该数字的一部分;
- 0:表示这是最后一个字节,且剩余7bit都用来表示数字(所以Varint解码时,如果读到最高位为0的字节时,就表示已经是Varing的最后一个字节);
因为每个字节的最高位都被占用,用来表示特殊的含义,所以,当数值非常大时,原有的字节数就不够用了,所以编码时要增加字节数。
可以参考下图加深理解:
编码示例:
解码示例:
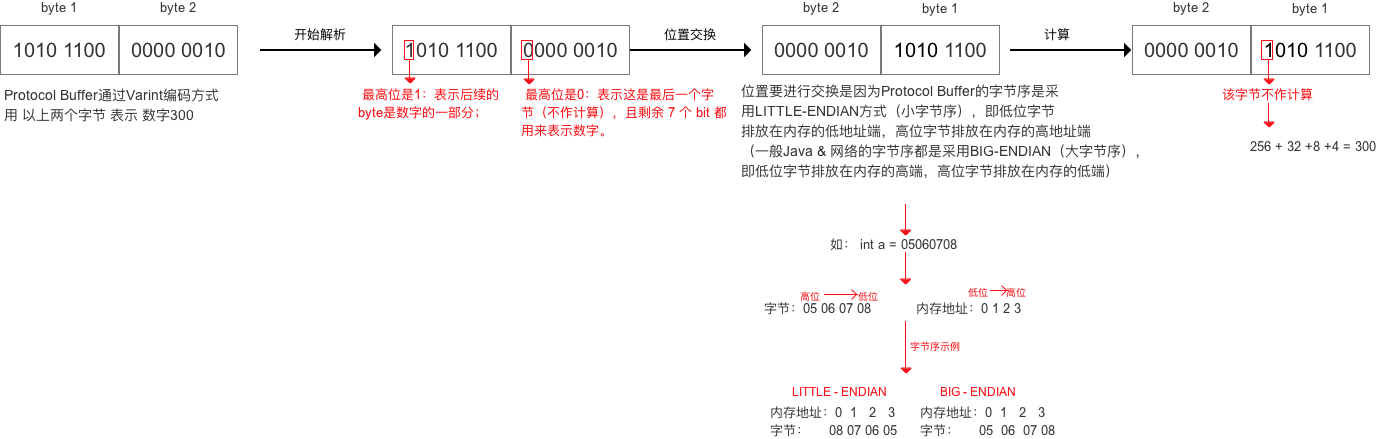
还有一个问题:就是负数时怎么办?计算机中数值用补码形式表示和存储(负数在计算机中往往用最位1来表示负数,0表示正数,负数的补码最高位为1),那按Varint编码方式所有的负数都需要增加一个字节表示,这是不能被接受的,解决方法便是下面要讲的zigzag编码。
Zigzag编码
Zigzag编码是一种变长的编码方式。zigzag按绝对值升序排列,将整数hash成递增的数值序列,哈希函数为h(n)=(n<<1)^(n>>31),对应地long型(64)位的哈希函数为h(n)=(n<<1)^(n>>63)。
| n | hex | h(n) | zigzag(hex) |
|---|---|---|---|
| 0 | 00 00 00 00 | 00 00 00 00 | 00 |
| -1 | ff ff ff ff | 00 00 00 01 | 01 |
| 1 | 00 00 00 01 | 00 00 00 02 | 02 |
| -2 | ff ff ff fe | 00 00 00 03 | 03 |
| 2 | 00 00 00 02 | 00 00 00 04 | 04 |
| ... | ... | ... | ... |
可以看到,zigzag编码将正数和负数重新映射为递增的无符号数,其主要目的就是使绝对值小的数值映射为小的无符号数,已方便后序压缩字节。
zigzag编码还有很多细节,比如为了保证编码的唯一可译性,需对哈希值进行前缀码编码,这里不再细述。
解码为编码的逆,首先将zigzag编码还原成哈希值,然后用哈希函数h的逆h’(n)=(n>>>1)^-(n&1)得到原始整数值。
这里只重点讲Varint编码和Zigzag编码,像string、double等类型这里不再描述,可参考文后的参考文档。
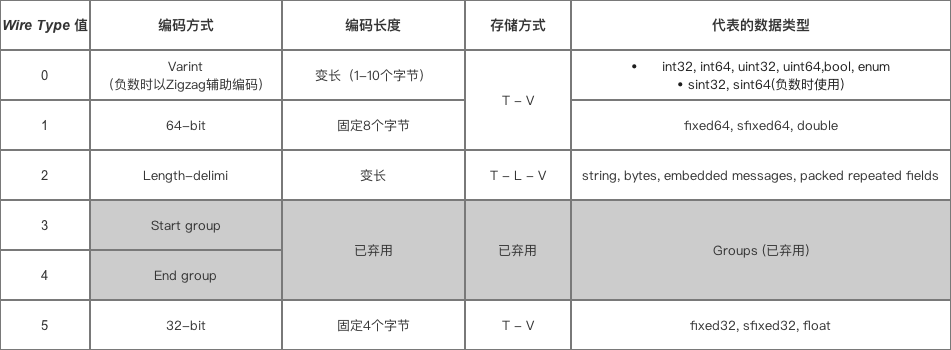
T-L-V的数据存储方式
T:tag,L:length,V:value。以标识-长度-字段值表示单个数据,最终将所有数据拼接成一个字节流,从而实现数据存储的功能。
其中Length可选存储,如存储Varint编码数据就不需要存储Length,因为可根据每个字节最高bit位来判断这个字节是不是该数据段的最后一个字节。

这里重点说一下Tag。Tag用来标识字段,通过Tag能获知这段字节流是属于什么类型数据的,其定义为:Tag = (field_number << 3) | wire_type
。这样,解包时就可根据tag将value对应消息中的字段。
Tag占用一个字节的长度(如果标识号超过了16,则多占用一个字节的位置,原因是field_number左移了3位,编码方式为Varint&Zigzag,编码的时候一个字节不够用了)。
message ChannelDataAck {
bytes uuid = 1; //这里的1 、2就是field_number
uint32 result = 2;
}
Tag(字段标识号)在序列化和反序列化过程中非常重要。举一个应用中非常常见的例子,在需要对原有结构进行增减字段的时候,同样一个结构体定义,新版本代码中对其增加了一个字段,那当新版本代码序列化后给原有旧版本反序列化解析的时候,因为旧的没有那个新增的字段,所以在解析时只解析自己有的字段,没有的不进行解析,这样旧的代码依旧能从新字节流中解析出旧数据结构。那旧的数据结构的数据解析为新数据结构时,因为没有新字段的数据,解析为新数据时该字段置为默认值。这样就能保证兼容性,对协议升级较为友好。
可以看到通过T-L-V的数据存储方式,能够较好的解决字段不完全匹配时的如何解析的问题。
序列化 & 反序列化过程
序列化过程如下:
- 判断每个字段是否有设置值,有值才进行编码.
- 根据字段标识号&数据类型将字段值通过不同的编码方式进行编码.
反序列化过程如下:
- 解析从输入流读入的二进制字节数据流.
- 将解析出来的数据按照指定的格式读取到
C++、Rust等对应的结构类型中.
到这里,基本把Protocol Buffers的工作原理简单梳理了一遍,其他技术细节待以后再深究。
欢迎关注微信公众号:后期将会在微信公众号更新。

