

0x00 前言
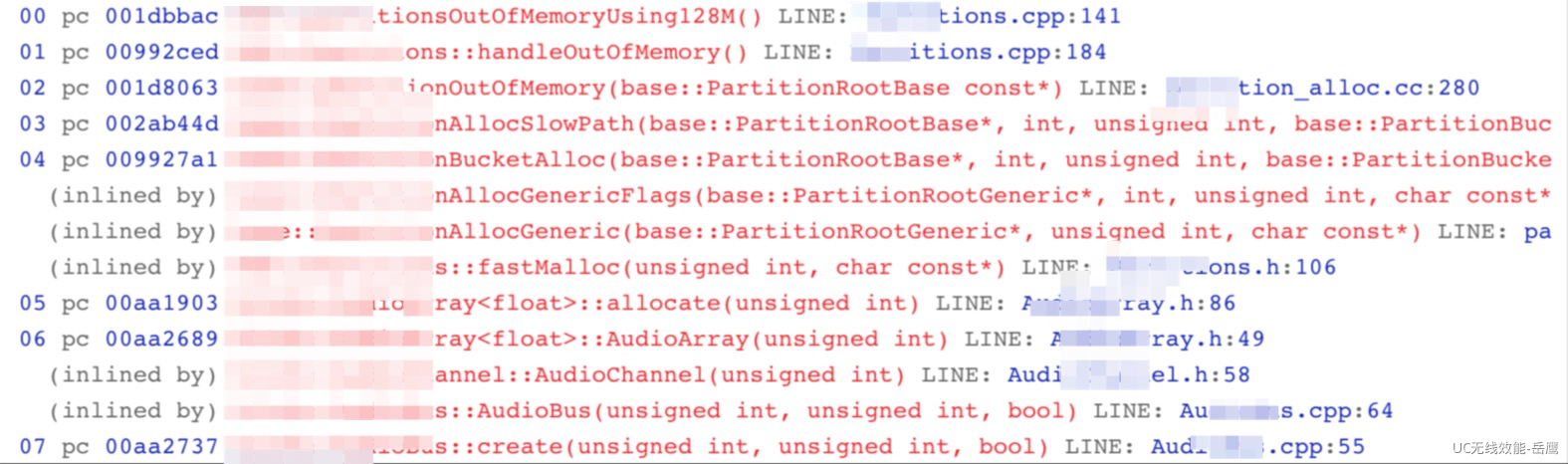
当应用出现崩溃的时候,程序员的第一反应肯定是:在我这好好的,肯定不是我的问题,不信我拿日志来定位一下,于是千辛万苦找出用户日志,符号表,提取出崩溃堆栈,拿命令开干,折腾好一个多小时,拿到了下面的结果:
addr2line -ipfCe libxxx.so 007da904 007da9db 007d7895 00002605 007dbdf1
logging::Logging::~Logging() LINE: logging.cc:856
logging::ErrLogging::~ErrLogging() LINE: logging..cc:993
base::internal::XXXX::Free(int) LINE: scoped____.cc:54
base::___Generic<int, base::internal::_____loseTraits>::_____sary() LINE: scoped_______.h:153
base::___Generic<int, base::internal::_____loseTraits>::_____eric() LINE: scoped_______.h:90
如果是接入了岳鹰全景监控平台,场景就完全不一样了。测试同学:发来一个链接,附言研发哥哥,这是你的bug,请注意查收。研发哥哥:点开链接,就可以在平台看到这条崩溃信息啦,如下图:
那么问题来了,岳鹰上有这么多的应用版本,再加上海量的日志,对于Native崩溃,总不能每个崩溃点都用addr2line或者相关的命令去符号化吧?
岳鹰的符号化系统正是为了解决该问题而设计。岳鹰最初上线的版本1.0,支持同时符号化解析数量有限,对iOS符号化时依赖Mac系统,不支持容器化部署,消耗机器资源较多。
为了更好的满足用户业务需求,岳鹰在年初启动了2.0版本的改造,并且制定以下目标:
- 同时解析不限数量的符号表
- 提升符号化的效率
- 解除Mac系统依赖,支持全容器化部署
那这样一个分布式的符号化系统该如何设计呢?接下来小编就来详细介绍下。
0x01 方案的选择
结合当前系统设计以及业界常见方案,我们有以下几条路可以走:
- 岳鹰1.0方案,用大磁盘,高CPU性能的机器搭建符号化机器,符号文件存放到磁盘,需要符号化时再调用addr2line;
- 建立一个中央存储,把符号文件上传到中央存储,符号化机器需要符号化的时候再过去拉,然后用addr2line符号化;
- 把符号信息按key-value方式提取出来,存入hbase或者其它中间件,符号化时通过类sql查询实现。
结合岳鹰2.0的目标,我们对三个方案进行对比:
| 对比项 | 方案1 | 方案2 | 方案3 |
|---|---|---|---|
| 符号表入库速度 | 快 | 快 | 慢 |
| 内存占用 | 常态高 | 常态高 | 入库时高 |
| CPU占用 | 常态高 | 常态高 | 入库时高 |
| 安全性 | 低 | 低 | 高 |
| 可扩展性 | 低 | 低 | 高 |
| 部署复杂度 | 高 | 高 | 低 |
方案1:符号文件上传倒是很快,如果需要高可用,还需要镜像一份到备机,且在做addr2line的时候,会带来高内存及高cpu的占用,而且不支持动态扩容,安全性也几乎没有,拿到机器就拿到了源码;
方案2:符号文件存放于中央存储,做好备份机制后,能保障文件不会丢失,但机器在符号化时,都需要去中央存储拉符号文件,之后的处理同方案1,查询效率不高,而且安全性也不高;
方案3:在符号入库时,把符号信息按key-value方式提取出来,然后加密存入hbase,这里要解决符号表全量导出及入库的速度及空间问题。
结合岳鹰2.0目标,我们对日志处理的及时性,可扩展性,安全性,以及海量版本同时解析的要求,我们选择了方案3。下面我们先给大家简单介绍下原理,再深入看看选择方案3要解决哪些问题。
0x02 原理(大神请忽略这一节)
国际惯例,我们先来了解一下原理,符号表是什么?符号表是记录着地址或者混淆代码与源码的对应关系表。下面我们分别用一个小demo程序来讲解符号表及符号化的过程。
0x02-1 iOS-OC、Android-SO符号化原理
a.示例源码:
int add(){
int a = 1;
a ++;
int b = a+3;
return b;
}
int div(){
int a = 1;
a ++;
int b = a/0; //这里除0会引发崩溃
return b;
}
int _tmain(int argc, _TCHAR* argv[]){
add();
sub();
return 0;
}
b.对应符号表,这里简化了符号表,没带行号信息
0x00F913B0 ~ 0x00F913F0 add()
0x00F91410 ~ 0x00F91450 div()
0x00F91A90 ~ 0x00F91ACD _tmain()
c.现有一崩溃堆栈
0x00F9143A
0x00F91AB0
d.进行符号化
0x00F9143A div() //查找符号表,地址0x00F9143A的符号名,在0x00F91410 ~ 0x00F91450范围内
0x00F91AB0 _tmain() //查找符号表,地址0x00F91AB0的符号名,在0x00F91A90 ~ 0x00F91ACD范围内
0x02-2 Android-Java 符号化原理
a.示例源码:
package com.uc.meg.wpk
class User{
int count;
UserDTO userDto;
UserDTO get(int id){...}
int set(UserDTO userDto){...}
}
class UserDTO{
int id;
String name;
}
b.符号表
com.a.b.c.d -> com.uc.meg.wpk.User
int count -> a
com.uc.meg.wpk.UserDTO -> b
com.uc.meg.wpk.UserDTO get(int) -> c
int set(com.uc.meg.wpk.UserDTO) -> d
com.a.b.c.e -> com.uc.meg.wpk.UserDTO
int id -> a
String name -> b
c.现有一崩溃堆栈
com.a.b.c.d.d(com.a.b.c.e)
d.进行符号化
//符号化com.a.b.c.d.d(com.a.b.c.e)
//查找com.a.b.c.d, 命中com.uc.meg.wpk.User
//查找com.uc.meg.wpk.User.d 命中 set()
//查找com.a.b.c.e,命中 com.uc.meg.wpk.UserDTO
//符号化结果为com.uc.meg.wpk.User.set(com.uc.meg.wpk.UserDTO)
0x03 新的难题
选择方案3后,主要瓶颈在符号表上传之后处理,这里主要工作是要把符号表转换为key-value,然后再写入hbase。现在主流的app开发有android的java及C++,iOS的OC,我们下面主要讨论这三种符号。
因为android的java符号化有google的开源工具支持,这里就不再展开。
OC因为是iOS系统,封闭系统,标准统一,上架AppStrore的应用,只用XCode进行编译,没有各种定制的需求。我们原来有一个OC实现的符号表kv提取程序,但是只能用于OSX系统,不便于线上布署,所以我们选择了用java重写了提取符号kv的功能。
但是对于Android的C++库so符号表,即ELF格式,存在着各种版本,各种定制下不同的编译参数,会大幅增加用java重写的成本,所以我们使用了Java跟C++结合的方式去实现ELF的符号表kv的提取,先用Java程序把ELF的基础信息,地址表读取出来,然后再用addr2line去遍历这个地址表,然后再把结果存入hbase,这个为100%的符号化成功率打下基础。
0x03-1 addr2line的问题
改进前后的对比
| 改进前 | 改进后 | |
|---|---|---|
| 应用场景 | 十几个地址的符号化 | 批量的地址符号化 |
| QPS | 50 | 800 |
| 地址传递方式 | 参数,有限长度 | 文件,无限长度 |
| 额外内存开销 | 1 | 0.7 |
| 多任务模式 | 不支持 | 支持 |
当然,这个addr2line,是要经过改造才能达到我们的要求,原来的addr2line是给开发者以单条命令去使用,不是给程序做批量查询的,每次查询都是要把整个ELF文件加载到内存,像UC内核,还有一些游戏的so文件,大小要到几百M的级别,每个addr2line进程都要一份独立的内存。假设一个500M的so符号,一台64核的机器,假如用60核去100%跑addr2line,加上其它开销,它就需要35G的内存。
面对这么高的cpu和内存占用,而且是一个较低的QPS,单核大约100QPS,我们也尝试去优化addr2line的binutils中的bfd部分,但是最终的接口都是调用系统内核的,这条路,短期好像走不通。面对这样的性能问题,期间也多次尝试用Java去重写这部分逻辑,但是最终结果只能实现与addr2line的90%匹配度,而且还有很多未知的兼容性问题,最后还是选择了改造addr2line,改造点主要有以下三点:
- 从文件读取地址表,使用批量请求去addr2line,减少bfd初始化的次数,因为这个过程中,bfd接口在调用一些特定的地址转换后,会导致qps降到个位数,需要重启进程才行;
- 减少额外的内存开销;
- 支持多进程,多容器分布式任务调度,支持动态扩缩容,提高资源利用率。
改造后,单核的QPS大约提升到800QPS,上面举的500M的so符号的例子,大约需要15分钟,基本能满足我们的需求。
0x03-2 存储的问题
解决完提取的问题,接下来就是存储的问题。
符号表都是经过精心设计的高度压缩的数据结构,我们通过上面的方案把它提取出kv的格式,容量上增加了10+倍,而且很多信息都是重复的,如函数名,文件名这些,虽然空间对于hbase来说不是什么问题,但是在追求极致的面前,我们还可以再折腾折腾。
前面提到我们因为要考虑数据的安全性,需要把存入hbase的数据做加密,所以不能直接用hbase本身的压缩功能,要求在加密前先做好压缩,如果是按行压缩再加密,总体的压缩比不会太高,我们可以把00006740~000069eb这一段当成一个大段,把它们压缩在一起再加密,这样因为重复信息较多,压缩比会很高,最终的体积可以缩小5+倍,相当于只是比原始符号表大3~4倍。
hbase rowkey的设计,因为后面的查询会需要用到scan,我们把符号表kv的结束地址作为rowkey的一部分,至于为什么这么设计,往下读,你就明白了。
0x03-3 查询的问题
根据0x01原理,对hbase的查询,需要get,scan的支持,get的话相对简单,直接通过rowkey命中就好了,适用于java符号化的场景,对于C++/OC的符号化,就需要scan的支持,因为地址是一个范围,不能用get直接命中,下面用伪代码举例说明scan的流程:
//1. 扫描libxxx.so符号,地址范围0x00001234 ~ 0xffffffff, 只取一条结果
//这里利用了scan的特性,我们存的rowkey是符号的结束地址,所以扫描出的第一个,
//就是最接近0x00001234的一个符号
raw = scan("libxxx.so", 0x00001234, 0xffffffff, limit=1);
//2. 解密,解压,判断有效性预处理
data = pre(raw);
//3. 精确定位地址,根据0x04-2的打包存入,再做切割拆分
result = splitData(data);
旧系统我们只用了应用级的缓存,每次重启缓存就会丢失,为了减小hbase的压力,我们增加一级分布式缓存,使用redis作为缓存,进一步减少了末端的查询QPS。
0x03-4 如果保证100%的符号化成功率
我们知道,如果符号化失败,就会出现不一样的崩溃点,这样就不能把这些崩溃点聚合在一起,会把一些严重的问题分散掉,同时会产生很多新的崩溃点,导致开发,测试无法分辨真实的崩溃情况,我们使用以下技术保障成功率:
- 高并发,低延迟的符号化查询服务,保障解析效率,防止超时出现符号化失败的情况;
- 多级缓存保障,减少hbase的scan操作;
- 使用原生addr2line提取符号kv;
- 重试机制。
0x04 总结
0x04-1 符号化系统的核心能力
通过几个平台的符号化反能力对比,我们可以看到岳鹰2.0取得的阶段性成果。
| 对比项 | 方案1 | 方案2 | 方案3 |
|---|---|---|---|
| 符号表入库速度 | 快 | 快 | 慢 |
| 内存占用 | 常态高 | 常态高 | 入库时高 |
| CPU占用 | 常态高 | 常态高 | 入库时高 |
| 安全性 | 低 | 低 | 高 |
| 可扩展性 | 低 | 低 | 高 |
| 部署复杂度 | 高 | 高 | 低 |
0x04-2 运行效果的提升
| 指标 | 岳鹰1.0到2.0的提升 |
|---|---|
| CPU核心数 | -50% |
| 平均CPU水位 | -40% |
| 内存 | 持平 |
| 符号入库速度(OC) | +20% |
| 符号入库速度(Java) | 持平 |
| 符号入库速度(SO <= 100M) | 持平 |
| 符号入库速度(SO > 100M) | 20分钟以内 |
| 符号化响应速度 | 100ms -> 9ms |
| 容器化部署 | 全容器化 |
## 0x05 欢迎免费试用 岳鹰为阿里集团众多使用UC内核的app(如手淘,支付宝,天猫,钉钉,优酷等)提供内核so的崩溃符号化功能,实现了Java,Native C++的质量监控完整闭环,并在Native C++上的支持上明显优于其它竞品,开发者能快速地还原现场并找出问题,同时整个系统支持动态扩缩容,为更多业务接入打下了坚实的基础。
更多功能,欢迎来[岳鹰全景监控平台](https://yueying.effirst.com/?vf=juejin)体验。
