


背景
2019年初,有幸参与了集团IDE 共建项目组, 打造阿里生态体系内的公共IDE底层。
一款IDE中,Tree 组件可能是所有视图中出现概率最高的一种视图形态,许多功能的基本交互形态也是落在 Tree 组件之中,其中不乏使用频率较高的文件树、调试变量树以及其他视图中的各式各样的树组件,可以这么说,Tree 组件的性能好坏会直接影响整个 IDE 的使用体验,在共建项目中,先后经历了两次的 Tree 组件实现,本文将通过介绍最近的一次重构,为剖析当前 KAITIAN框架 中的一种高性能Tree组件的实现。
Tree组件长啥样?
常见的Tree组件如下图所示,主体结构一般是由普通的节点及可折叠的节点组成,除开主体,其他诸如一些选中状态,描述信息等,这些不同的装饰(渲染)方式构成了Tree组件的多样性。
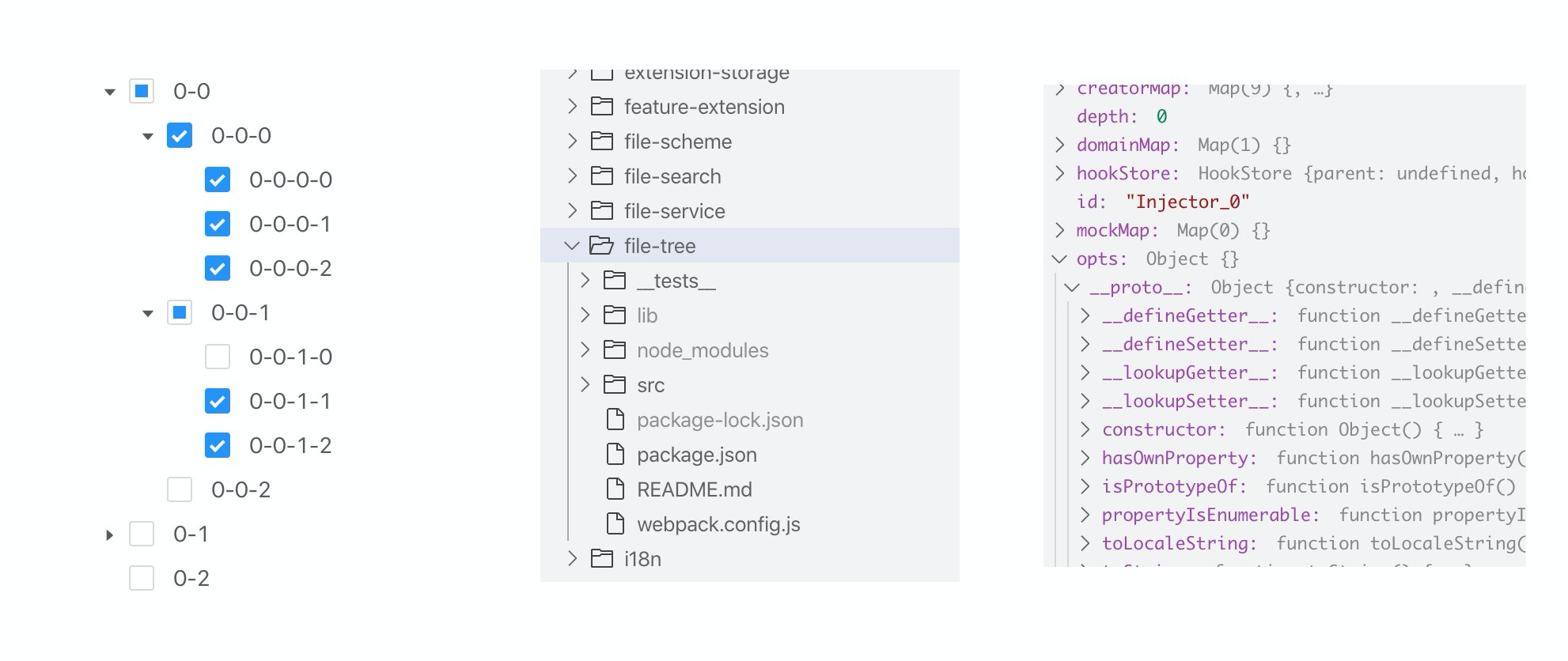
以下介绍均以文件树为例
由此我们可以推导出,我们最终实现的Tree组件,应该为一个最基础的Tree形态,上层通过不同的拼装方式组合出真正使用的组件形态:
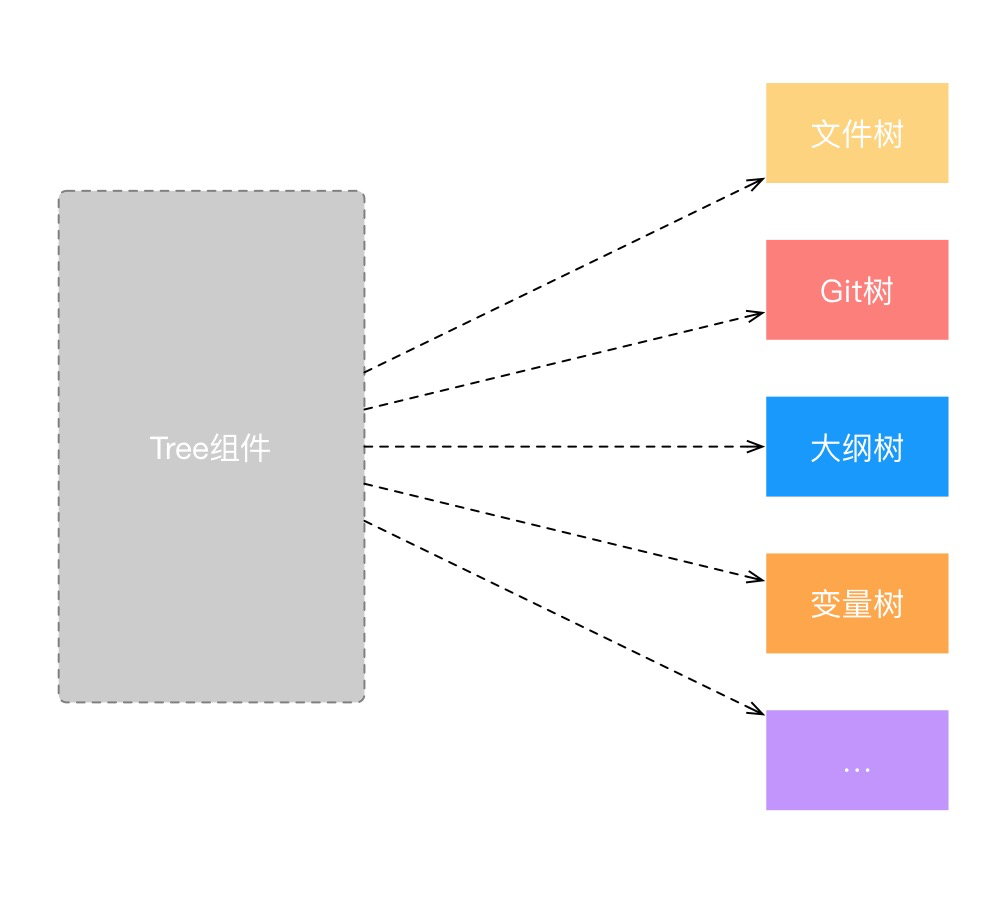
预期的数据结构
由上面的Tree结构,我们可以简单的推导出我们的基础数据结构如下(左侧),而通过对基础类型的数据进行拓展,我们便可以得到更多类型的Tree节点定义,以文件树为例:

这样我们便构造出了我们需要的文件树组件中的节点定义,而通过这种组合,我们便可以通过上层复用底层Tree组件实现的能力,但也不会受限于底层Tree的实现,我们可以通过上层定义每个节点的实际渲染方式。
定义事件驱动模型
由上面的使用方式,我们自然得能够想到我们需要定义好父子组件的通信方式,来保证父组件可以随时了解子组件状态并介入某些节点操作。如图所示:
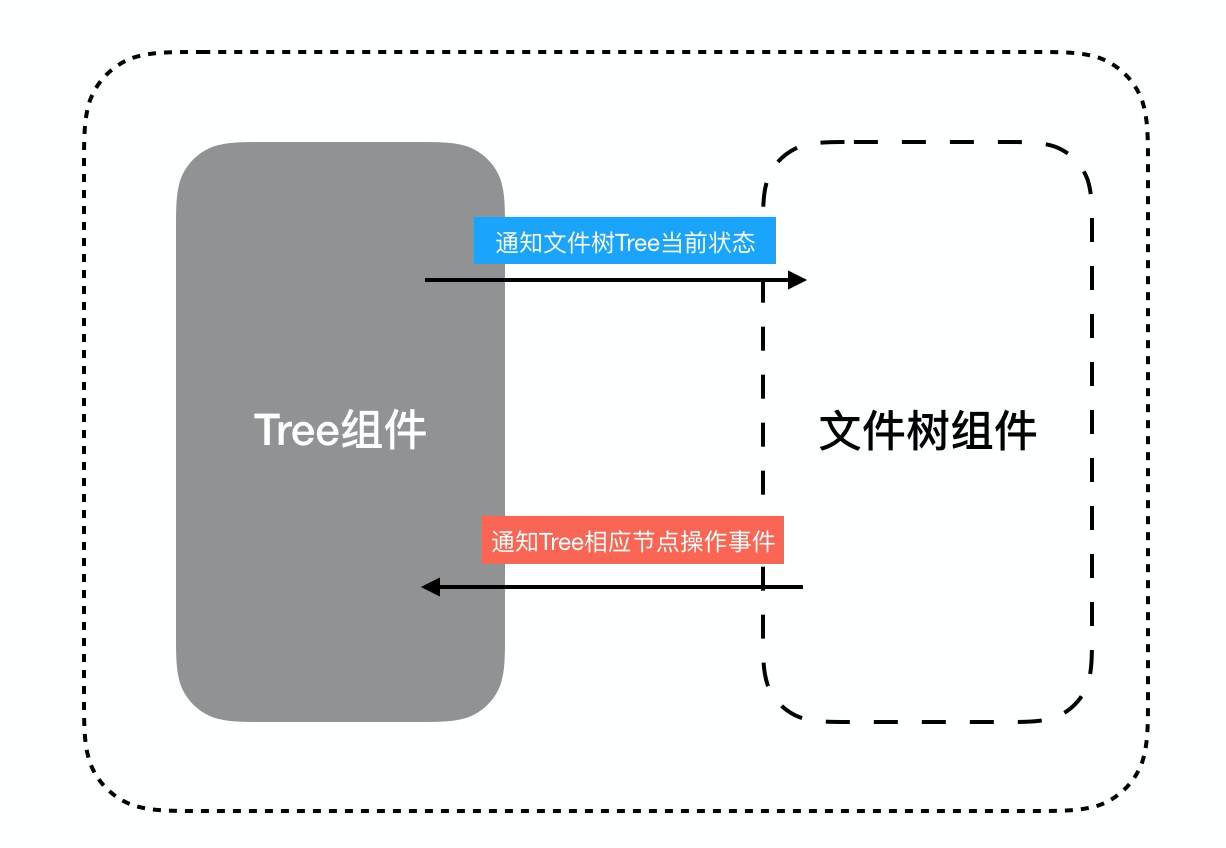
基础的事件发送/订阅模型如下:
export interface ITreeWatcher {
// 监听watcheEvent事件,如节点移动,新建,删除
onWatchEvent(path: string, callback: IWatcherCallback): IWatchTerminator;
// 监听所有事件
on(event: TreeNodeEvent, callback: any);
// 触发父节点即将变化事件
notifyWillChangeParent(target: ITreeNodeOrCompositeTreeNode, prevParent: ICompositeTreeNode, newParent: ICompositeTreeNode);
// 触发父节点变化事件
notifyDidChangeParent(target: ITreeNodeOrCompositeTreeNode, prevParent: ICompositeTreeNode, newParent: ICompositeTreeNode);
// 触发节点即将销毁事件
notifyWillDispose(target: ITreeNodeOrCompositeTreeNode);
// 触发节点销毁事件
notifyDidDispose(target: ITreeNodeOrCompositeTreeNode);
// 触发节点即将接收移动/新建/删除等事件(主要在文件树中使用)
notifyWillProcessWatchEvent(target: ICompositeTreeNode, event: IWatcherEvent);
// 触发节点接收移动/新建/删除等事件(主要在文件树中使用)
notifyDidProcessWatchEvent(target: ICompositeTreeNode, event: IWatcherEvent);
// 触发节点折叠状态即将变化事件
notifyWillChangeExpansionState(target: ICompositeTreeNode, nowExpanded: boolean);
// 触发节点折叠状态即将变化事件
notifyDidChangeExpansionState(target: ICompositeTreeNode, nowExpanded: boolean);
// 触发节点子节点即将变化事件
notifyWillResolveChildren(target: ICompositeTreeNode, nowExpanded: boolean);
// 触发节点子节点变化事件
notifyDidResolveChildren(target: ICompositeTreeNode, nowExpanded: boolean);
// 触发节点路径变化事件
notifyDidChangePath(target: ITreeNodeOrCompositeTreeNode);
// 触发节点补充信息变化事件
notifyDidChangeMetadata(target: ITreeNodeOrCompositeTreeNode, change: IMetadataChange);
// 触发节点分支变化事件
notifyDidUpdateBranch();
// 销毁函数
dispose: IDisposable;
}
所有节点中都包含监听模型引用,通过在各个子节点粒度中埋上事件触发点,这样在根节点中我们便能通过一个on 函数监听到整颗树的变化,从而去实现诸如快照、操作回滚等高级的树组件应用。
定义节点渲染模型
一个基础的Tree组件我们可以看成一个长列表,基础的节点渲染样式如下:
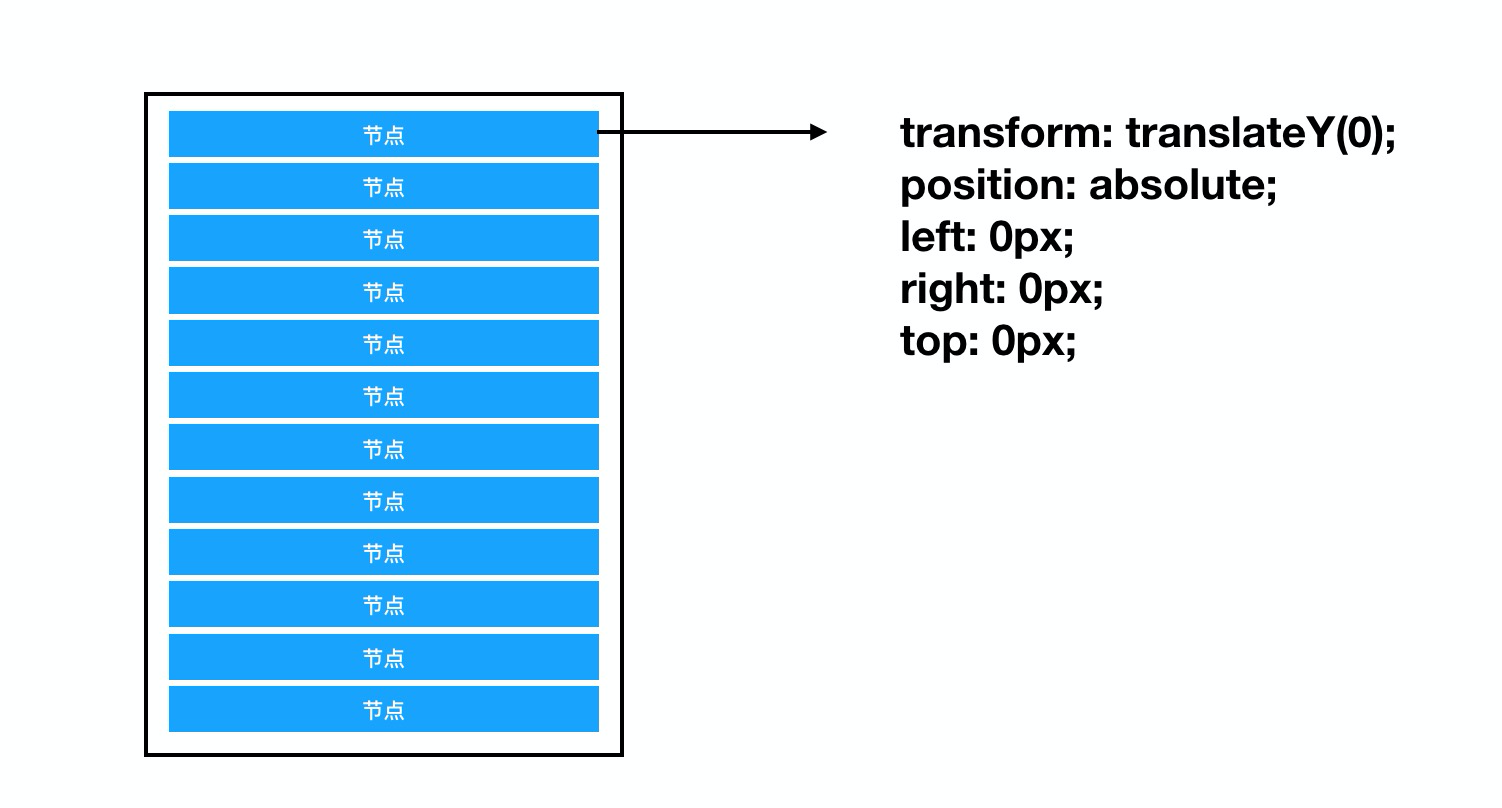
通过控制不同层级关系下的缩进样式,便可以变成“更像”一个Tree组件
小知识点:页面中只要有使用了css3中的
transform: translateY(0)属性便可开启chrome浏览器中的硬件加速能力,能获得更加良好的运行性能。
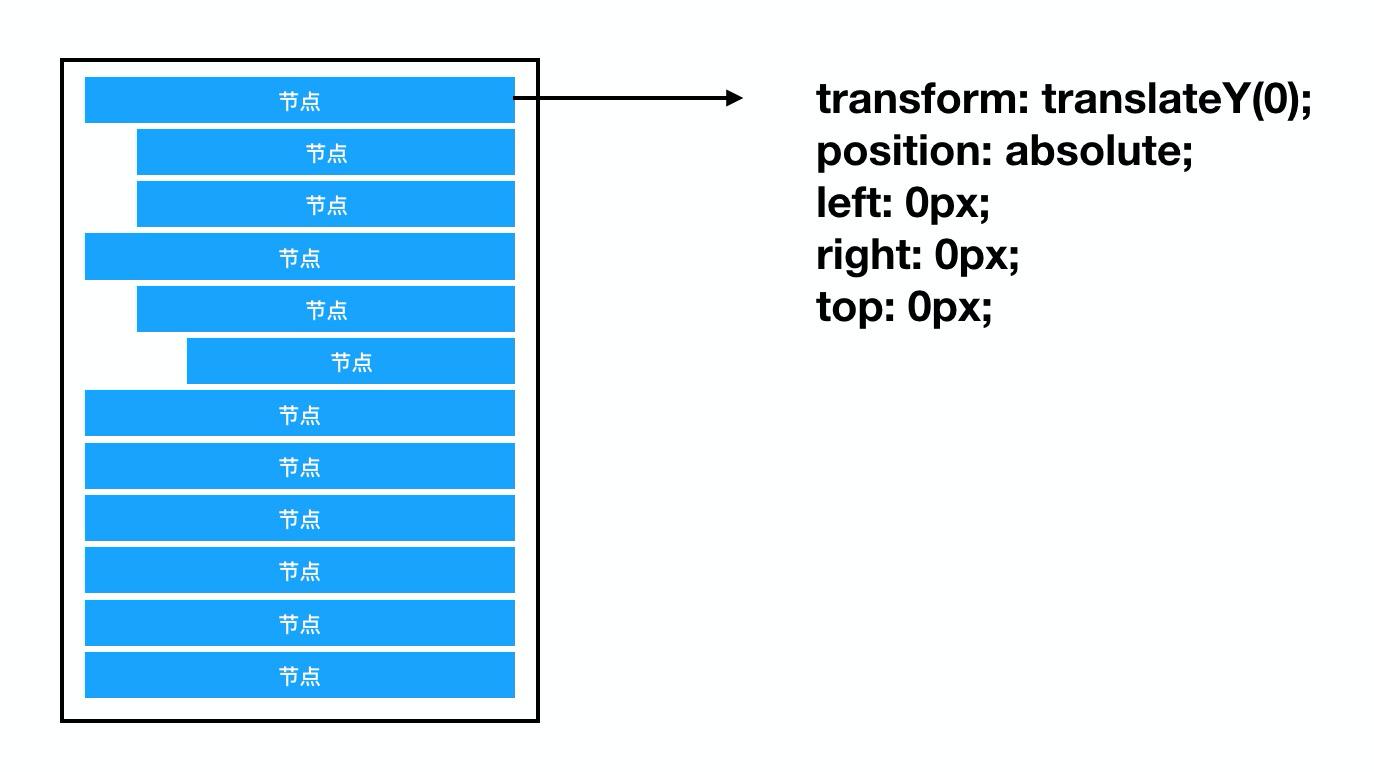
对于一个可能有上千个节点的长列表,为了性能上的考虑,我们往往只会选择性的选取部分节点渲染到页面上,为了达到更好的滚动效果,我们需要在前后预渲染部分节点(留给浏览器渲染一些反应时间),如下所示:
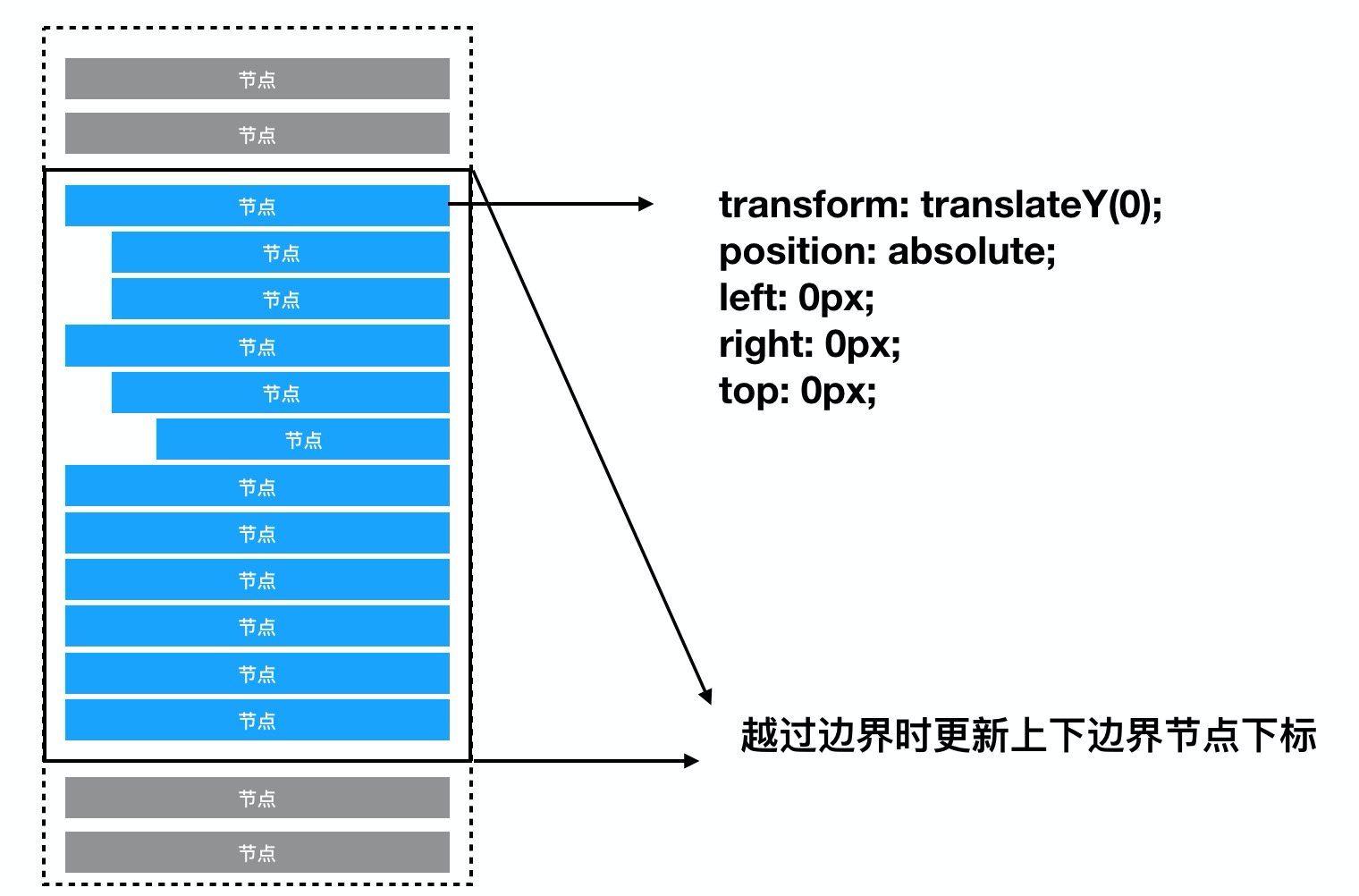
在滚动到边界的时候更新当前列表的初始渲染下标,结合 React的Diff 更新算法,从而实现节点回收的效果。
如何获取列表数据
每个可折叠节点都需要具备获取子节点数据的能力,故需要为每个节点定义一个 TreeService 用于获取数据等能力,如图所示:
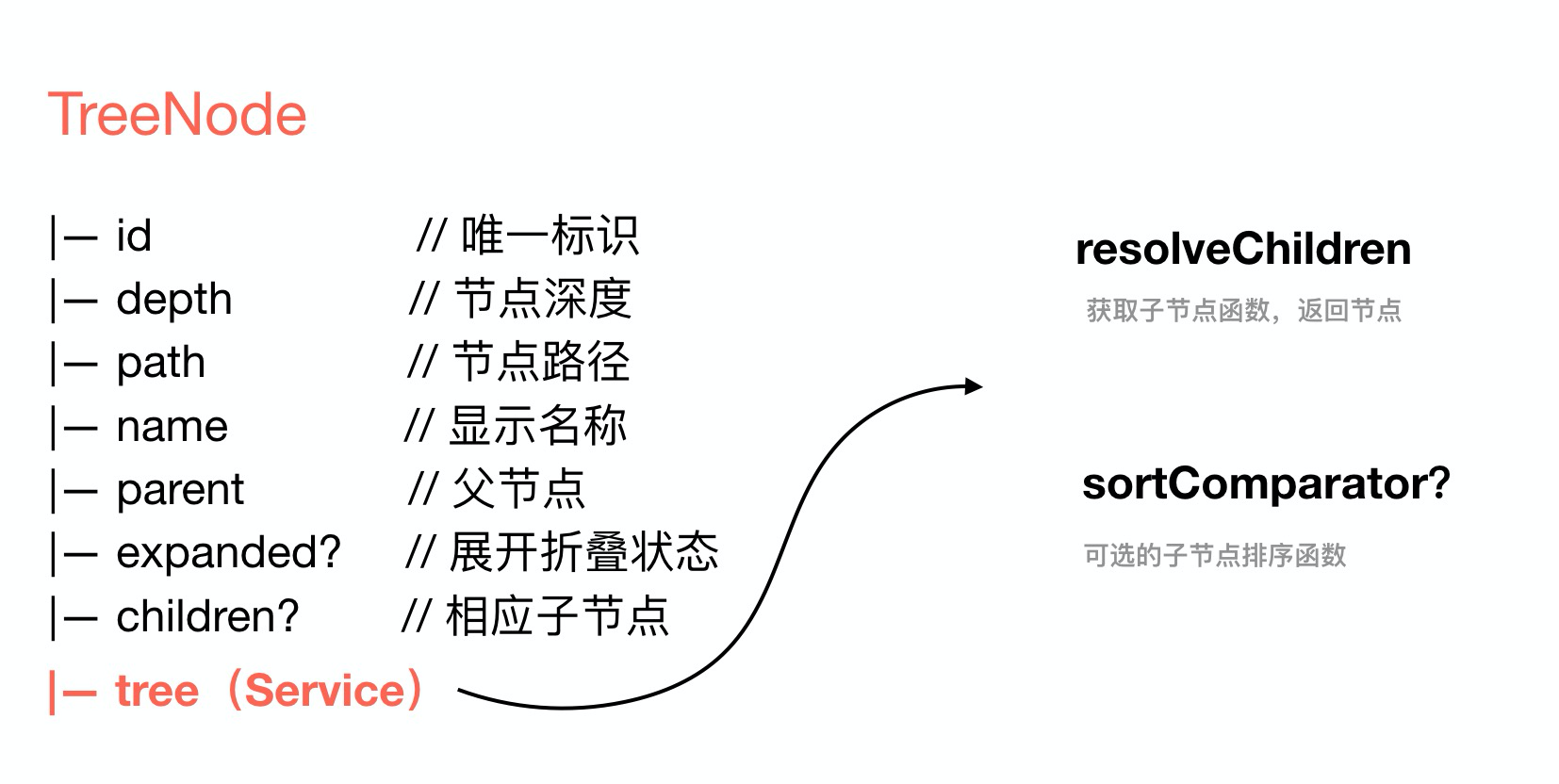
文件树通过在定义 File 及 Directory 的过程中便可定义其独有的数据获取方式。
整颗文件树渲染的主要数据来源为根节点下的 FlattenedBranch 二维数组中,该数据是将所有子节点信息平铺后的计算结果,展开根节点后基础数据结构示例如下:
注:
下标代表了节点在渲染时的实际位置,如下标 0 代表渲染 Tree 组件时第一个节点;节点ID则代表了从数据源中获取节点数据实体的唯一标识,可以理解为有了ID后便能获取到节点所有渲染的必要信息。
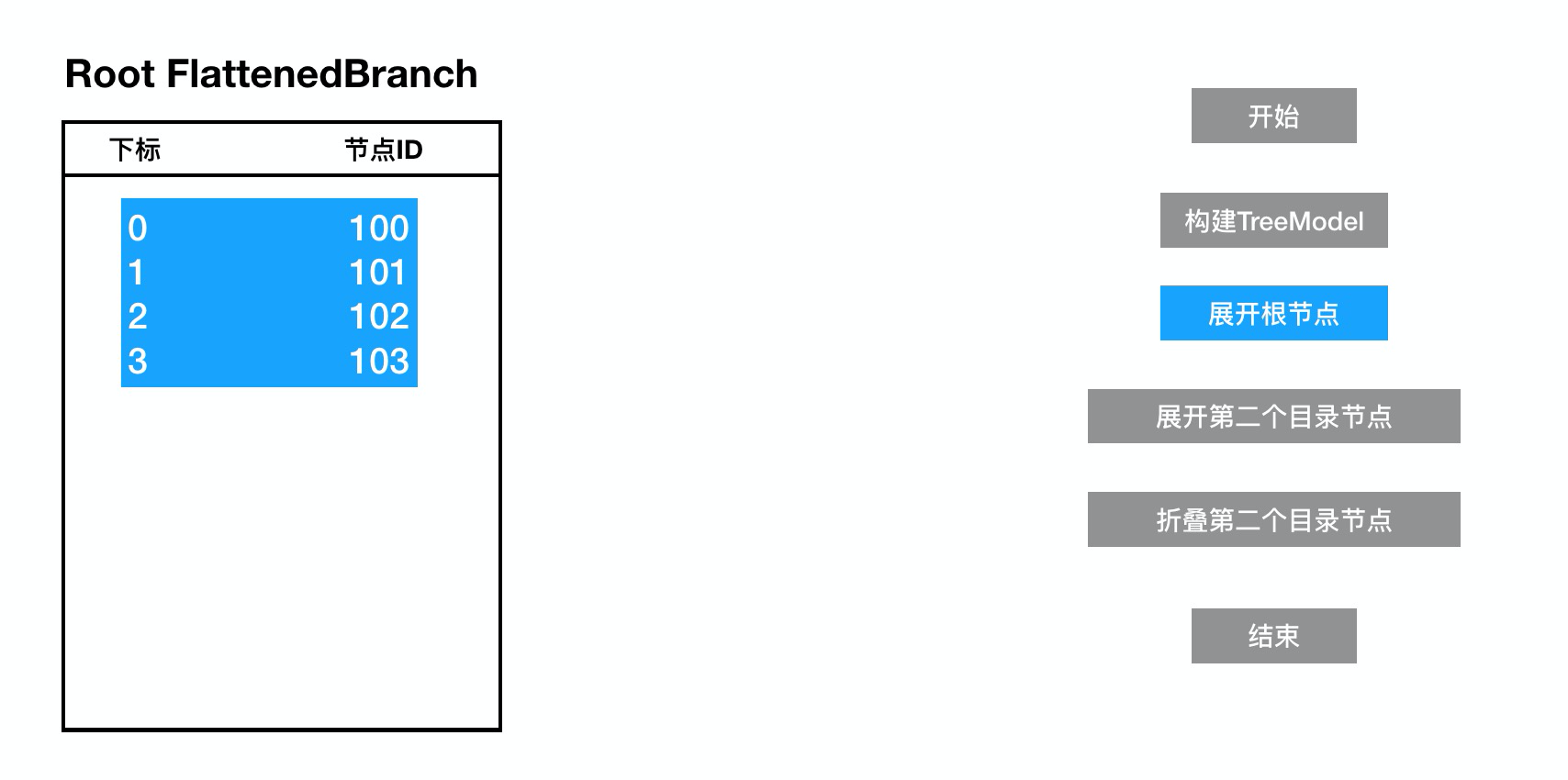
下标代表着Tree组件在列表中的渲染位置,而节点ID着对应着一个具有TreeNode数据结构的节点
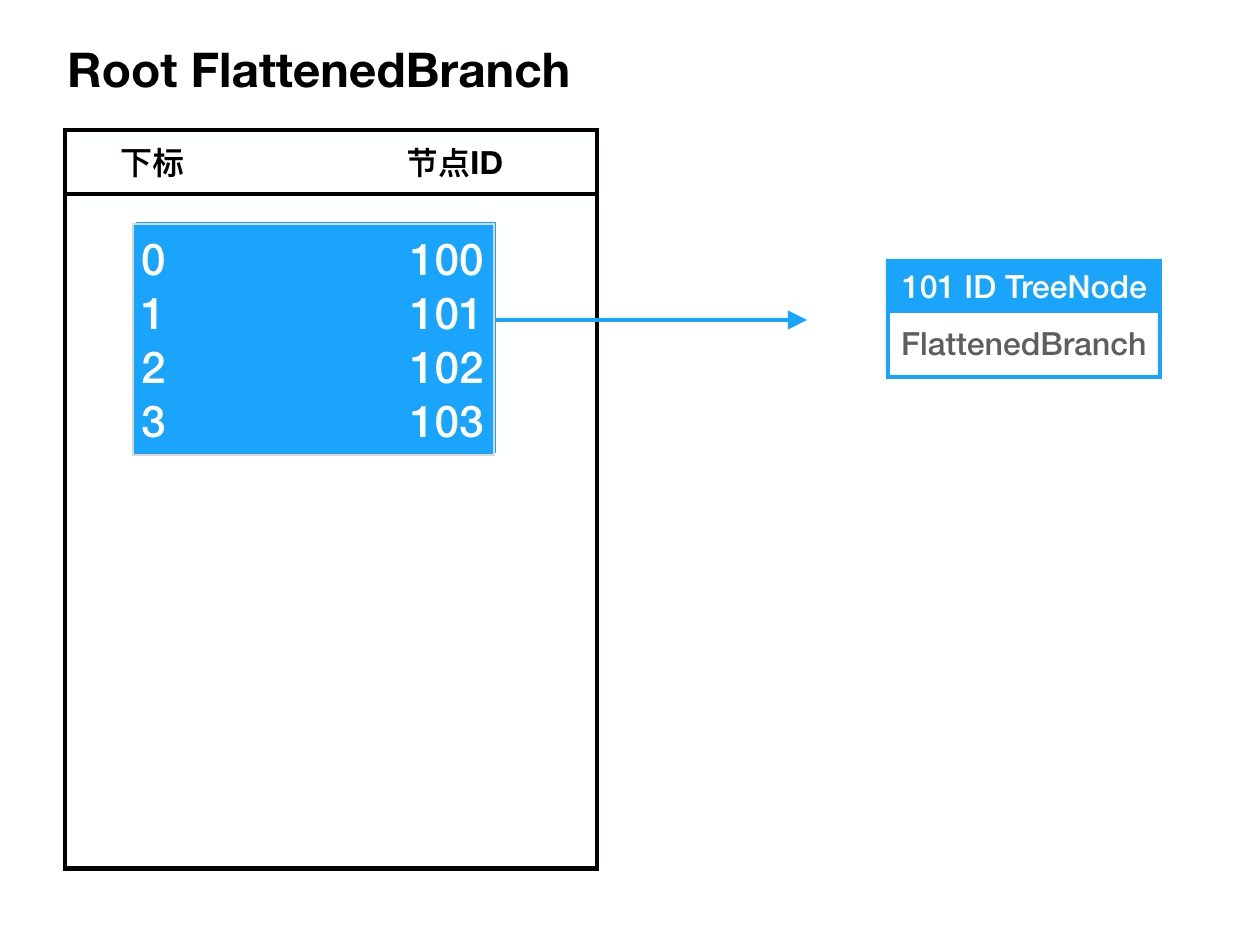
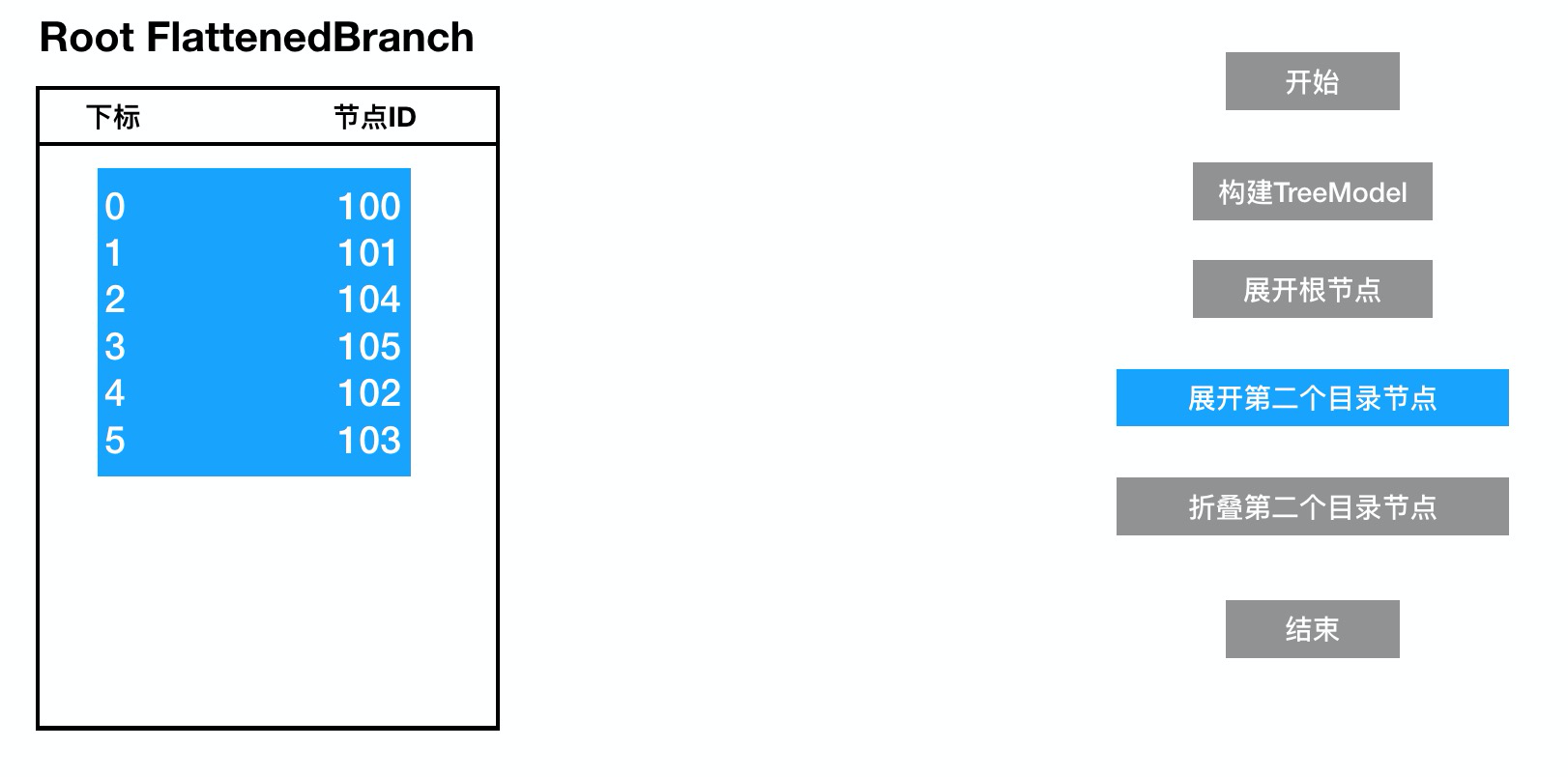
假定这里的节点101为一个可折叠节点,展开后根节点数据也会随之更新
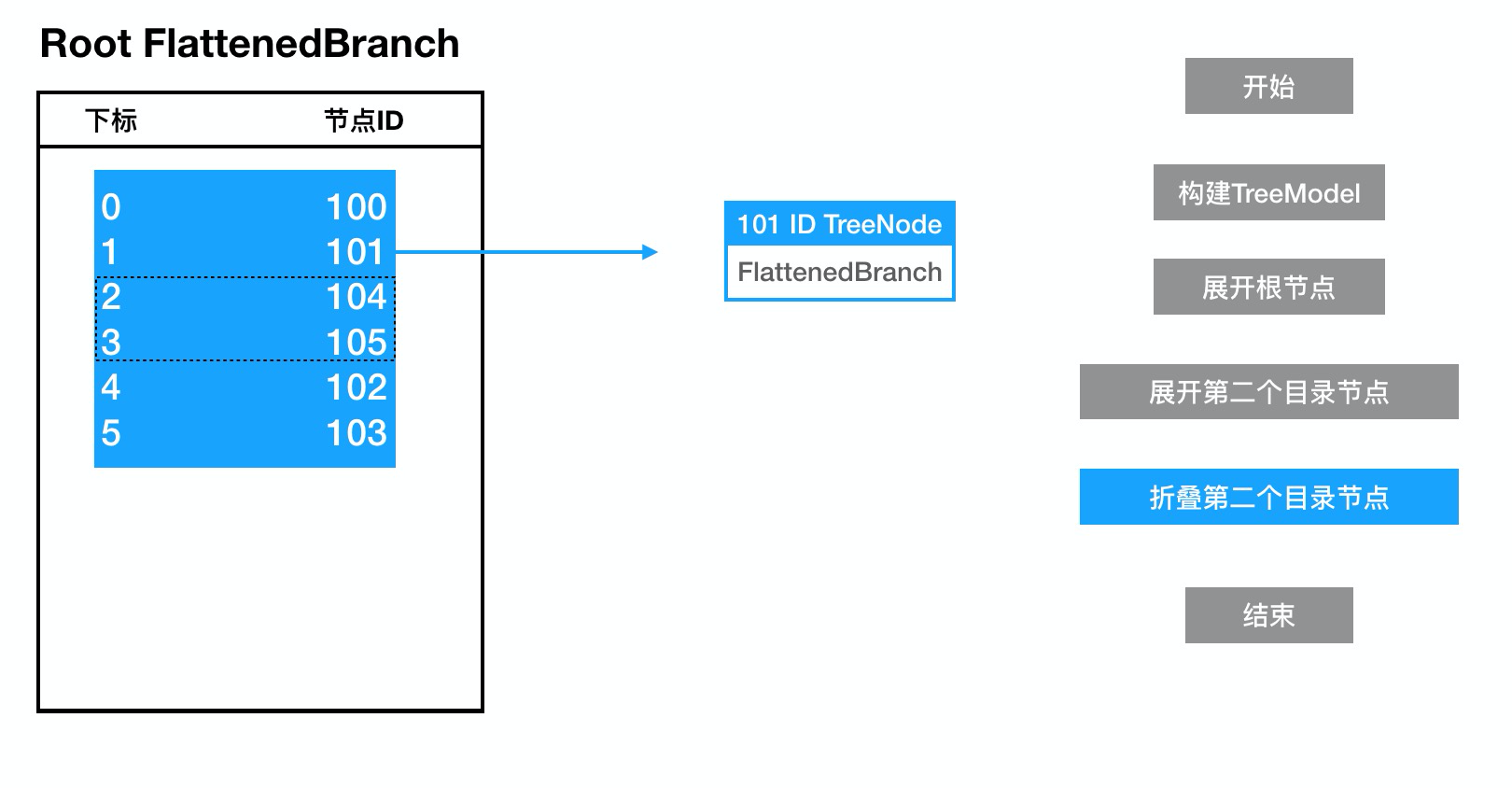
折叠节点101后,对应的子节点将会重新存储与101节点的FlattenedBranch 中,用于下次展开时使用(达到缓存的效果):
取出节点101对应子节点数据:
存储数据到节点101
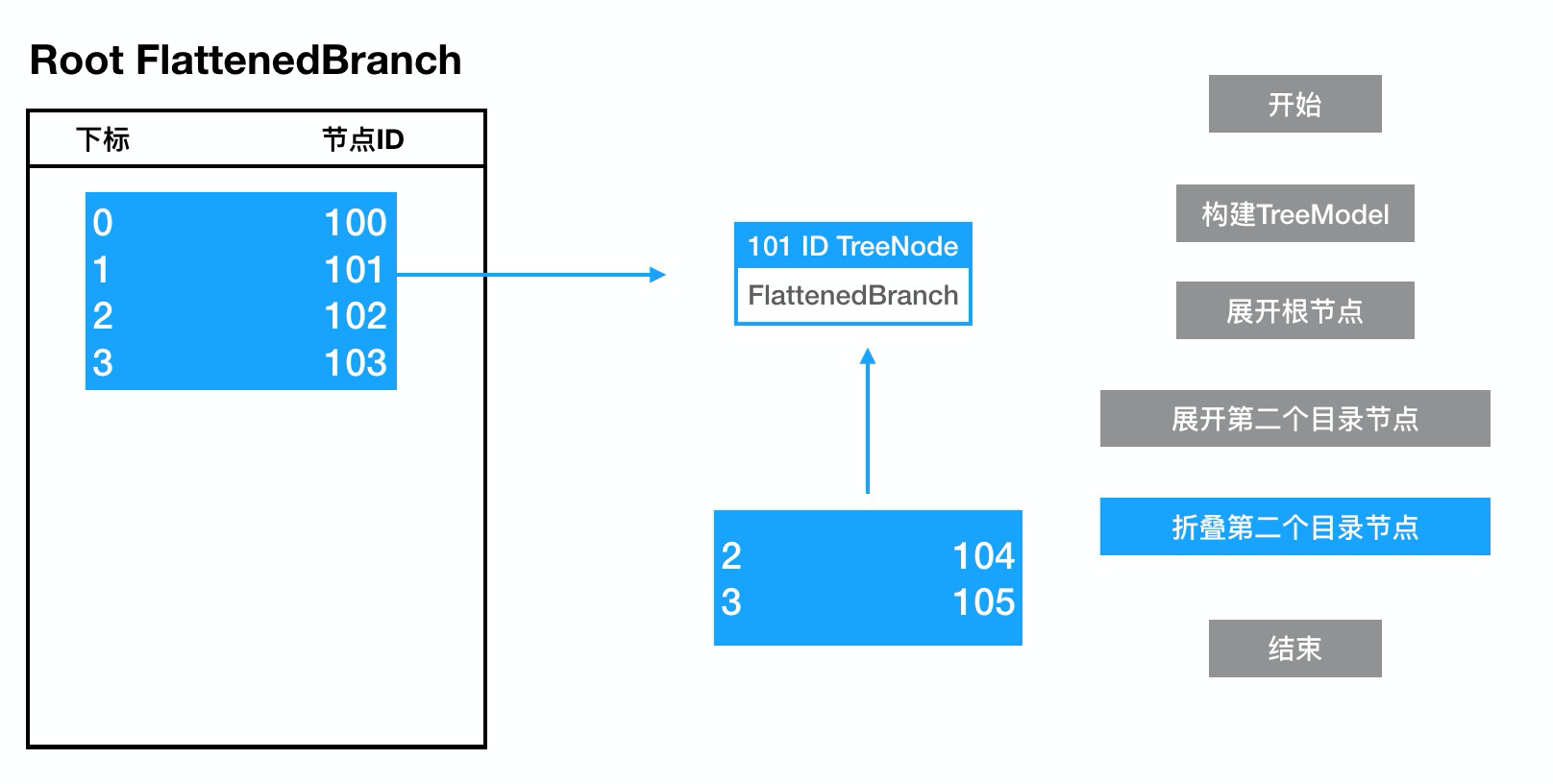
通过这样便可在一个计算复杂度为N的数据结构上去操作我们列表的渲染数据。
状态模型
讲完渲染,下一步便是对Tree组件状态的记录工作,我们需要定义一个状态模型,用于记录当前Tree组件的状态,核心数据状态如下:
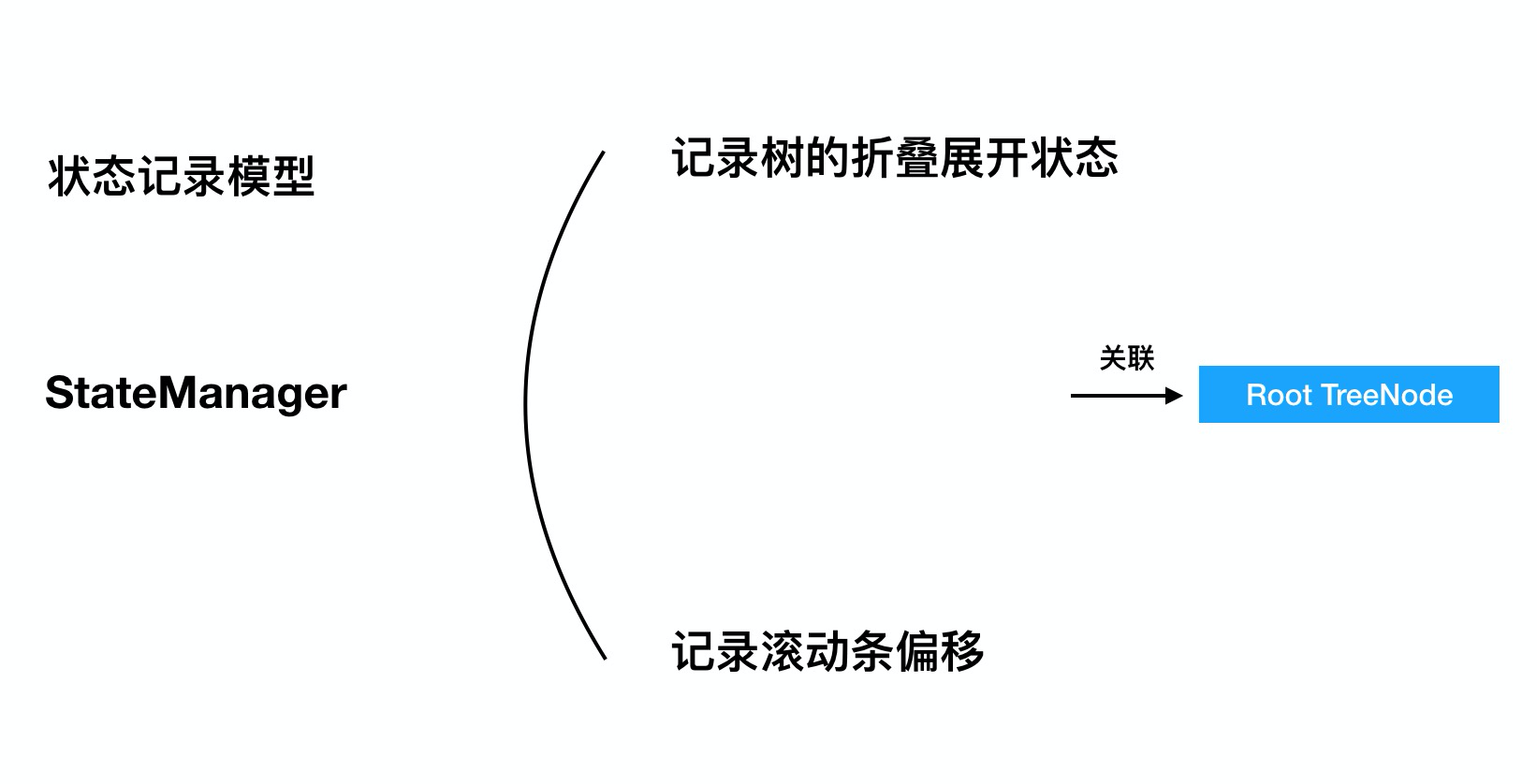
通过在根节点绑定一个状态模型,我们既可以随时随地获取当前Tree的展示状态
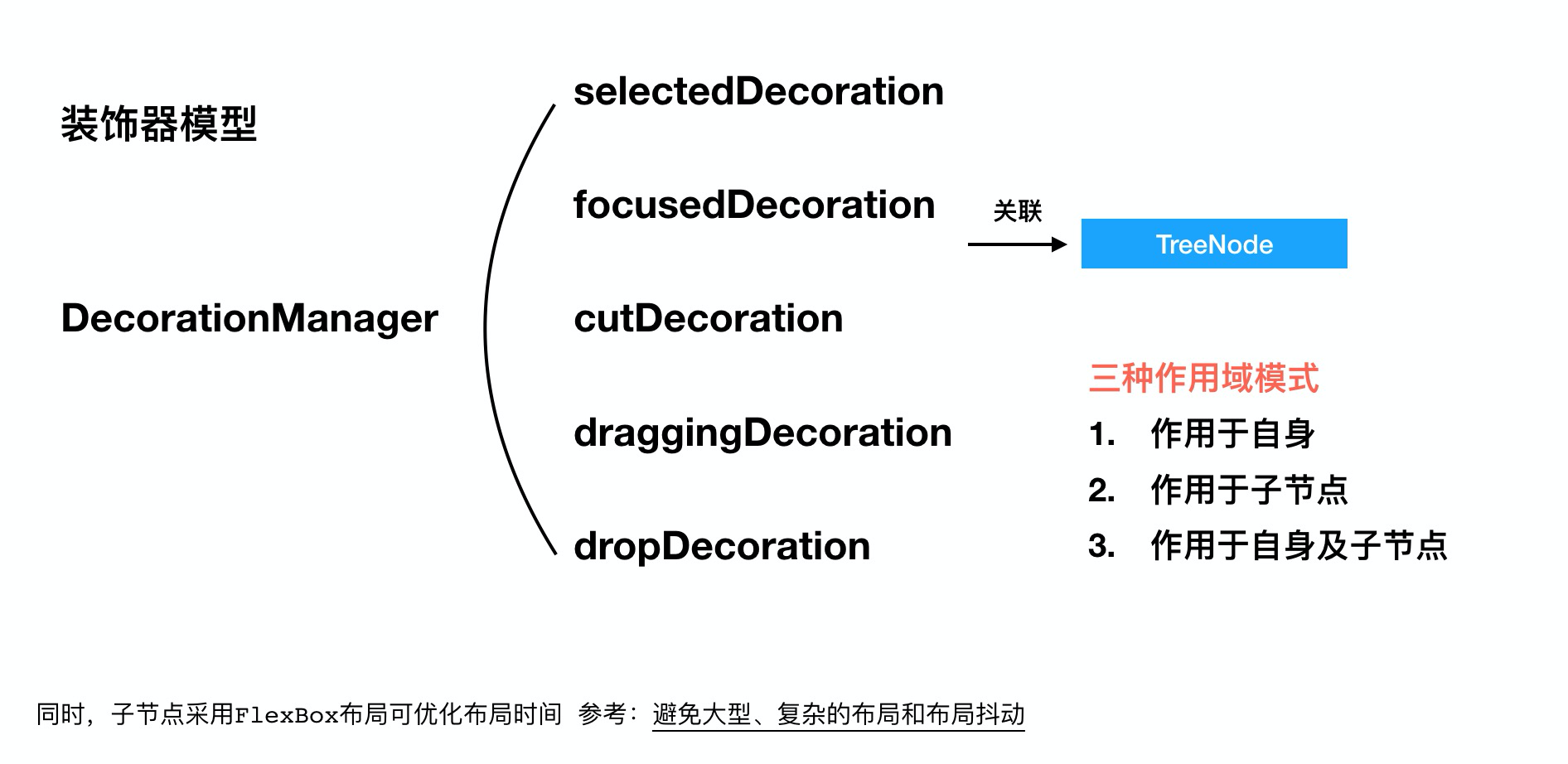
装饰器模型
到这一步,实际上我们的Tree组件已经具备了初步的能力,可以展示,也可以折叠,但我们依旧需要一种节点装饰手段来提供给开发者美化(装饰)节点的能力,装饰器模型便是来为我们提供这种装饰能力的重要手段。
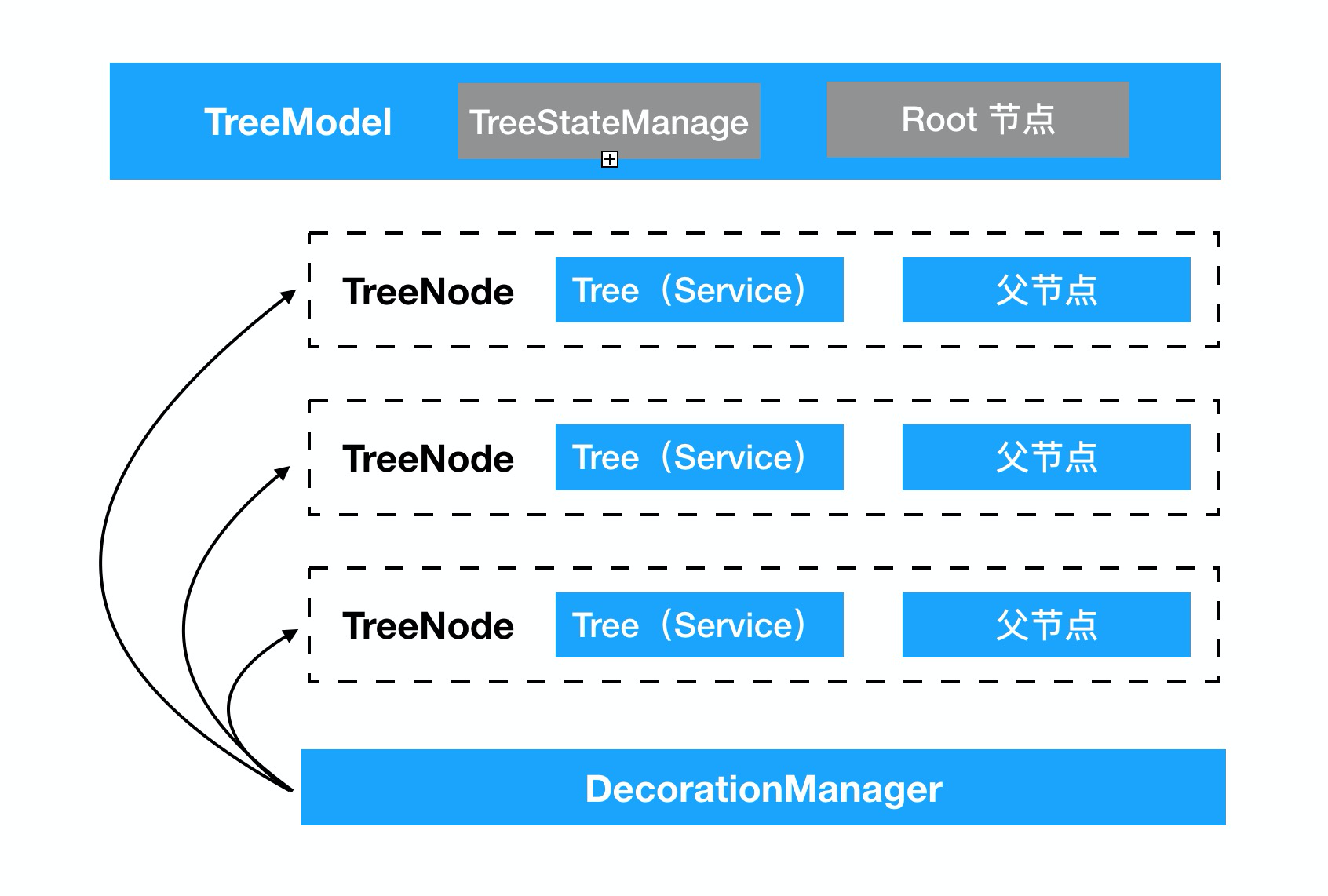
最终形态
综上,我们可以得到我们Tree组件的最终形态如下:
编码结构
我们最终实现文件树需要组装的大体结构如下:
1.文件树节点定义:
export class Directory extends CompositeTreeNode {
.constructor(
tree: ITree,
public readonly parent: CompositeTreeNode | undefined,
public uri: URI = new URI(''),
public name: string = '',
public filestat: FileStat = { children: [], isDirectory: false, uri: '', lastModification: 0 },
public tooltip: string,
) {
super(tree, parent);
if (!parent) {
// 根节点默认展开节点
this.setExpanded();
}
}
}
export class File extends TreeNode {
constructor(
tree: ITree,
public readonly parent: CompositeTreeNode | undefined,
public uri: URI = new URI(''),
public name: string = '',
public filestat: FileStat = { children: [], isDirectory: false, uri: '', lastModification: 0 },
public tooltip: string,
) {
super(tree, parent);
}
}
2.Tree(Service) 定义:
定义Tree组件的数据获取来源 resolveChildren ,以及定义节点排序逻辑 sortComparator
export class FileTreeService extends Tree {
async resolveChildren(parent?: Directory){
... 获取子节点逻辑
}
sortComparator(a: ITreeNodeOrCompositeTreeNode, b: ITreeNodeOrCompositeTreeNode) {
... 节点排序逻辑
}
}
3.TreeModel 定义:
主要用于定义Tree渲染的数据模型,这里的数据与视图渲染可以是分离的两个过程,视图可选择时机从数据中获取对应位置的展示内容,而数据操作则是脱离于视图的,存粹的数据操作,这在做一些数据预装/预处理等能力的时候会十分好用。
export class FileTreeModel extends TreeModel {
constructor(@Optional() root: Directory) {
super();
// 还可以在这里做一些其他初始化工作
}
}
4.节点渲染模型定义:
每个视图可以自定义自己的节点渲染模型,如下面的FileTreeNode,基于这种灵活的组装形式,可让Tree组件具备更灵活的拓展性。
const renderFileTree = () => {
if (isReady) {
return <RecycleTree
height={filterMode ? height - FILTER_AREA_HEIGHT : height}
width={width}
itemHeight={FILE_TREE_NODE_HEIGHT}
onReady={handleTreeReady}
model={fileTreeModelService.treeModel}
filter={filter}
>
{(props: INodeRendererProps) => <FileTreeNode
item={props.item}
itemType={props.itemType}
template={(props as any).template}
decorationService={decorationService}
labelService={labelService}
dndService={fileTreeModelService.dndService}
decorations={fileTreeModelService.decorations.getDecorations(props.item as any)}
onClick={handleItemClicked}
onTwistierClick={handleTwistierClick}
onContextMenu={handlerContextMenu}
defaultLeftPadding={baseIndent}
leftPadding={indent}
/>}
</RecycleTree>;
}
};
至此便可定义一个完整的文件树组件渲染及数据结构
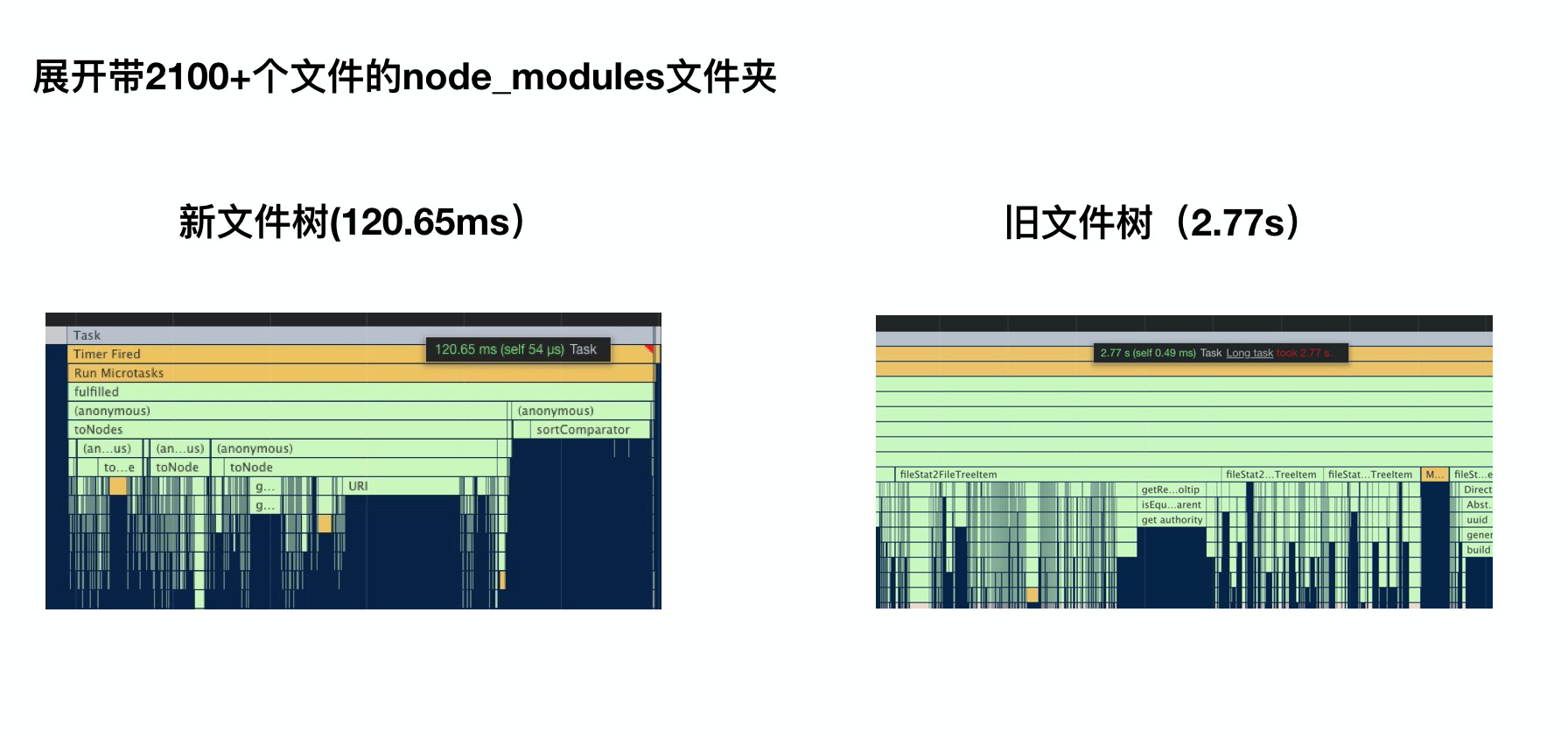
性能对比
- 新文件树 VS 旧文件树 性能对比
- 新文件树 VS VSCode文件树 性能对比
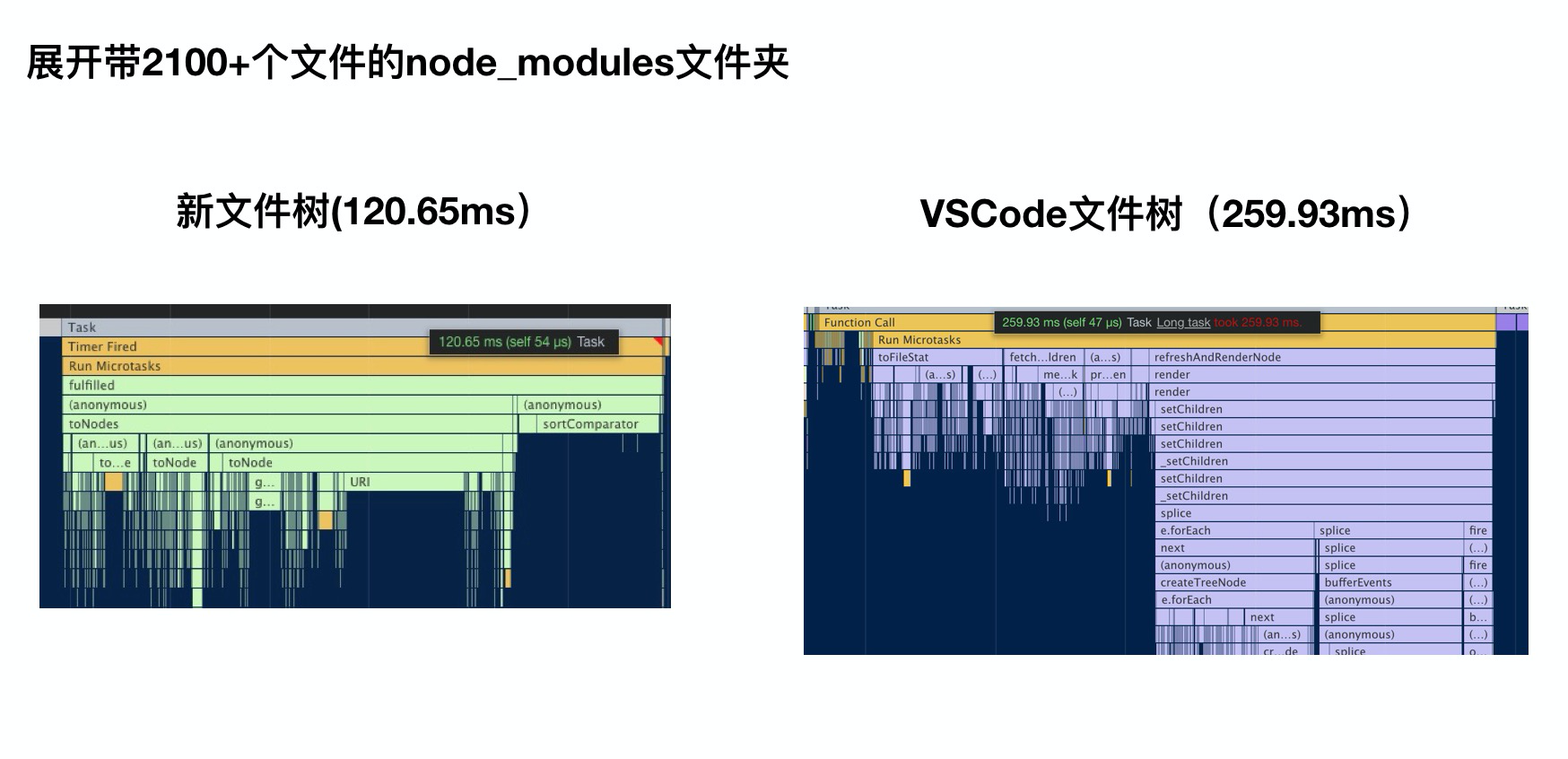
再经历二次Tree组件重构后,整体文件树性能得到了较大程度的性能优化,甚至在当前场景下得到了比VSCode文件树更加优异的性能表现。
综合对比VSCode中的实现,目前带来明显性能差异点在于:
- 对比VSCode为直接的Dom操作,React的DOM Diff算法在大文件场景下有一定性能优势
- 扁平化数据模型,去递归化
- 在父组件中独立定义渲染模型,所有渲染均是按需分配,而不必在基础Tree组件中进行冗余判断
性能之外
除了性能上的提升外,Tree组件的设计还为我们提供了更多可能性:
Tree组件的设计更重要的是为组件使用者提供了构造一个类树组件的参考,通过固定的组装模式便可产出对应的SearchTree、GitTree、TodoTree 等,一切仅需三步,定义Model、定义节点数据、获取数据后渲染节点即可,更提供了如刷新、定位、折叠全部等快捷功能调用,用简单的数据结构描述来让开发者从定义Tree的“地狱”中解放出来。
数据与渲染模型分离的设计能让我们在页面未加载前便准备好渲染数据,一切的数据操作可静默完成,在渲染时则立即可用于渲染,这在优化二、三屏加载速度场景中将会十分好用。
结合DI,我们还可以实现继续数据模型的多例实现,从而达到通过一个DI Token,产生一颗树的能力,。
...
--
总结
当前 KAITIAN框架 中的Tree组件改造仅经历了第一阶段的文件树改造,相关代码仍处于不断优化改进过程中,本文仅为大家分享一种可行的实现思路,后续我们将会在性能及功能稳定后将框架内的所有类Tree视图进行替换,并孵化出更易用的Tree组件用于其他场景下的建设。

