

「观感度:🌟🌟🌟🌟🌟」
「口味:蚂蚁上树」
「烹饪时间:10min」
本文已收录在
Githubgithub.com/Geekhyt,感谢Star。
周树人先生曾经说过:学好树,数据结构与算法你就掌握了一半!
食堂老板(童欧巴):就算我们作为互联网浪潮中的叶子结点,也需要有蚍蜉撼树的精神,就算蚍蜉撼树是自不量力。因为就算终其一生只是个普通人,但你总不能为了成为一个普通人而终其一生吧。
今日菜谱,蚂蚁上树,下面介绍一下演员。
树的相关名词科普
- 根节点
- 叶子节点
- 父节点
- 子节点
- 兄弟节点
- 高度
- 深度
- 层
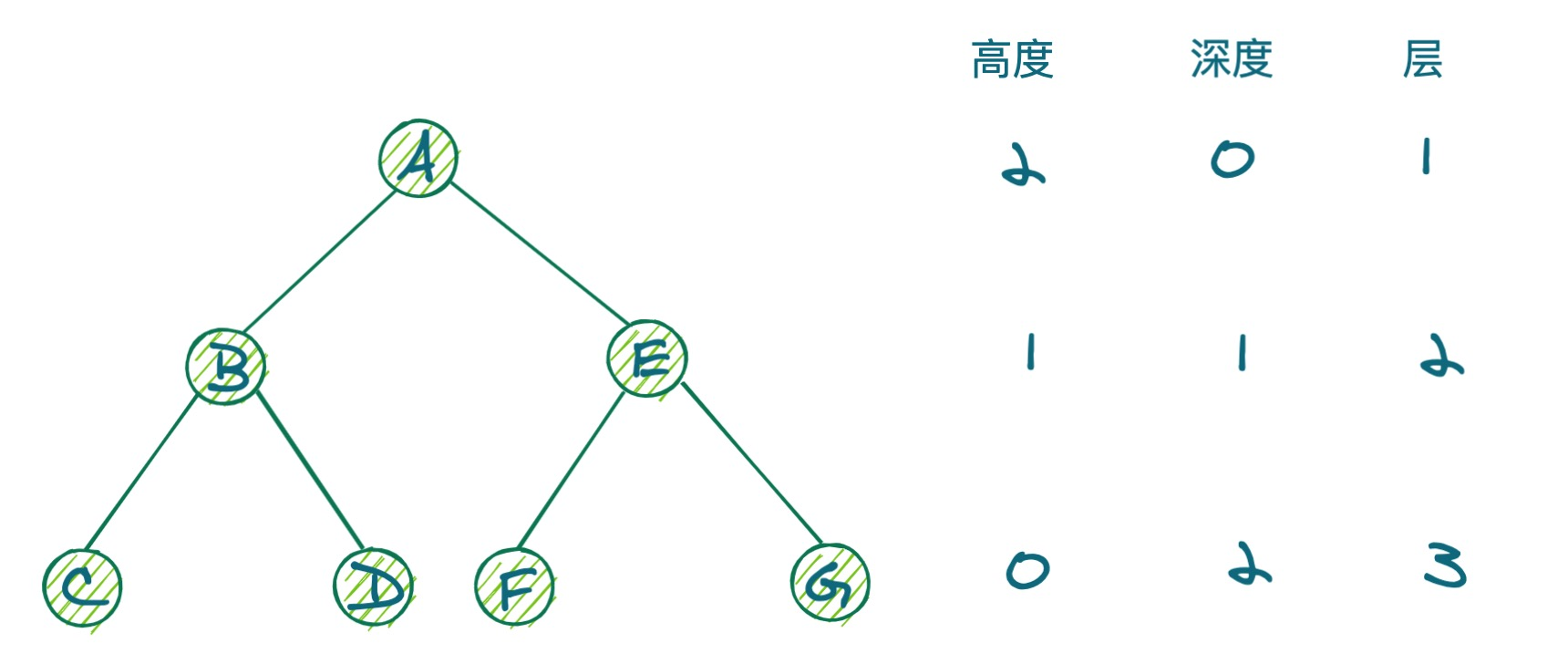
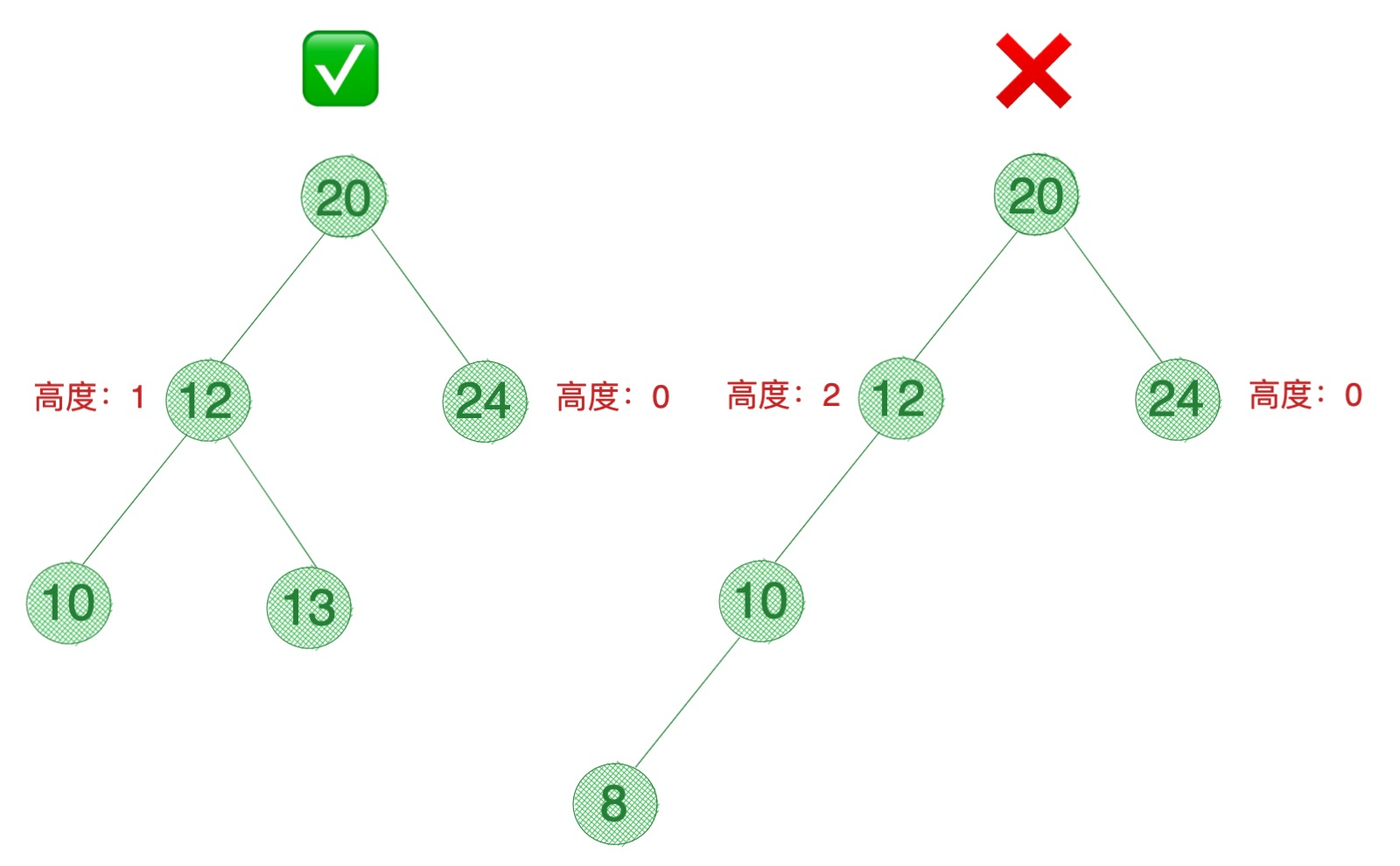
A 是 根节点。C、D、F、G 是 叶子节点。A 是 B 和 E 的 父节点。B 和 E 是 A 的 子节点。B、E 之间是 兄弟节点。高度、深度、层 如上图所示。为了方便理解记忆,高度 就是抬头看,深度 就是低头看。与 高度、深度 不同,层 类比盗梦空间里的楼,楼都是从 1 层开始计算,盗梦空间中的楼颠倒过来,从上往下。
二叉树 Binary Tree
每个节点最多有两个子节点,也就是 左子节点 和 右子节点。
满二叉树 Full Binary Tree
叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点。上文中的图就是满二叉树。
完全二叉树 Complete Binary Tree
叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大。
堆其实就是一种完全二叉树,一般采用的存储方式是数组。
采用数组存储完全二叉树,无须像链式存储一样额外存储左右子节点的指针,可以节省内存。
二叉树的遍历
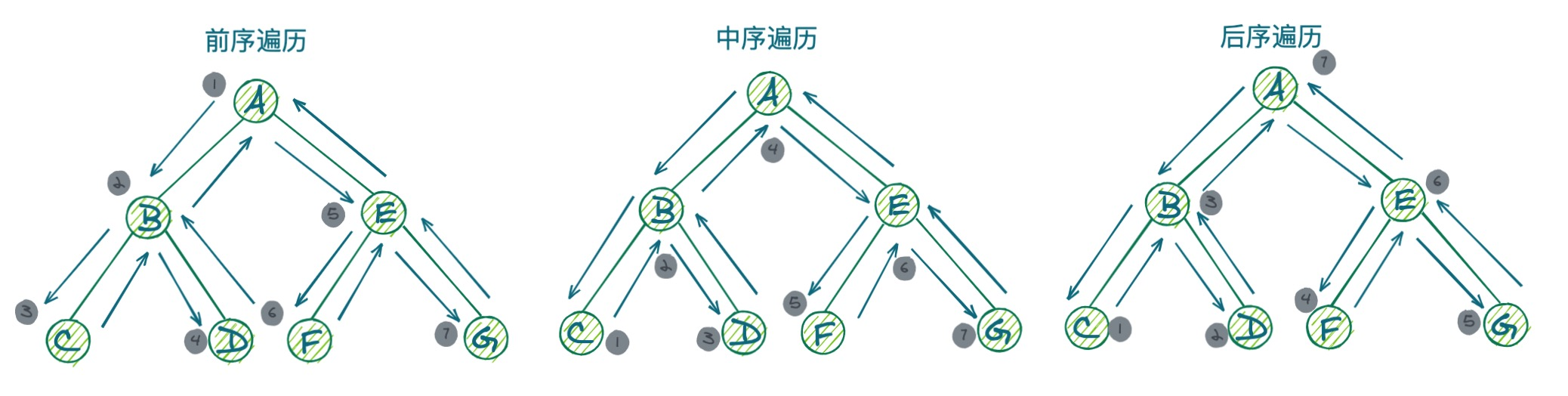
- 前序遍历:先打印当前节点,再打印当前节点的左子树,最后打印当前节点的右子树
(ABCDEFG) - 中序遍历:先打印当前节点的左子树,再打印当前节点,最后打印当前节点的右子树
(CBDAFEG) - 后序遍历:先打印当前节点的左子树,再打印当前节点的右子树,最后打印当前节点
(CDBFGEA)
// 前序遍历
const preorderTraversal = function(root) {
const result = [];
function pushRoot(node) {
if (node != null) {
result.push(node.val);
if (node.left != null) {
pushRoot(node.left);
}
if (node.right != null){
pushRoot(node.right);
}
}
}
pushRoot(root);
return result;
};
// 中序遍历
const inorderTraversal = function(root) {
const result = [];
function pushRoot(node) {
if (node != null) {
if (node.left != null) {
pushRoot(node.left);
}
result.push(node.val);
if (node.right != null){
pushRoot(node.right);
}
}
}
pushRoot(root);
return result;
};
// 后序遍历
const postorderTraversal = function(root) {
const result = [];
function pushRoot(node) {
if (node != null) {
if (node.left != null) {
pushRoot(node.left);
}
if (node.right != null){
pushRoot(node.right);
}
result.push(node.val);
}
}
pushRoot(root);
return result;
};
复杂度分析
- 时间复杂度: O(n)
- 空间复杂度:最坏情况为 O(n),平均情况为 O(logn)
二叉查找树 Binary Search Tree
又称二叉排序树、二叉搜索树。
中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度是 O(n),非常高效。
二叉查找树中的任意一个节点,左子树中的每个节点的值,都小于这个节点的值,而右子树节点的值都大于这个节点的值。
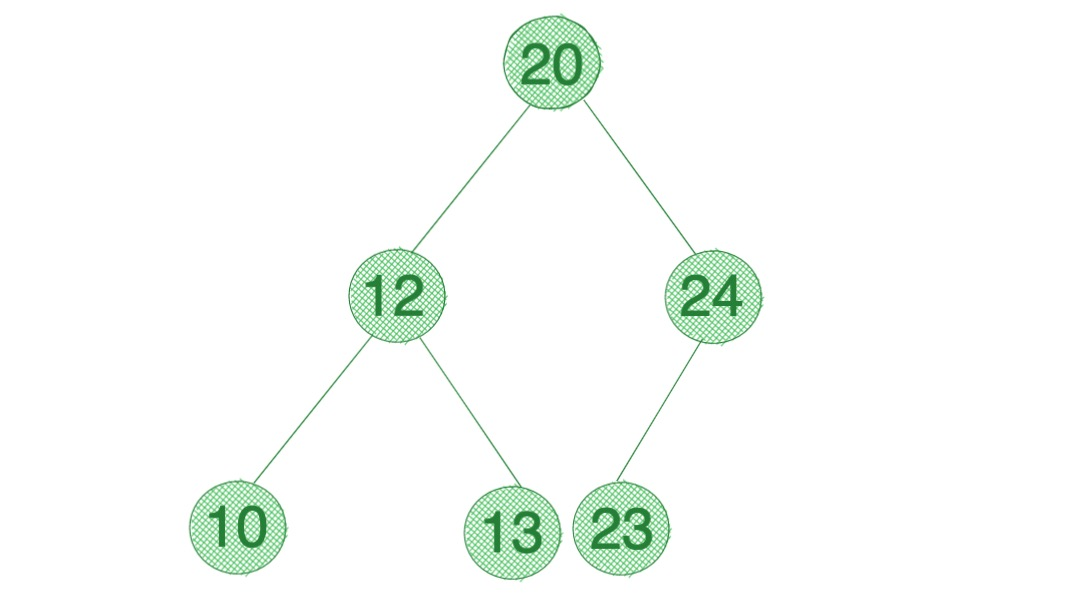
在二叉查找树中,查找、插入、删除等很多操作的时间复杂度都跟树的高度成正比。两个极端情况的时间复杂度分别是 O(n) 和 O(logn),分别对应二叉树退化成链表的情况和完全二叉树的情况。
极端情况下复杂度退化并不是我们想要的,所以我们需要设计一种平衡二叉查找树。平衡二叉查找树的高度接近 logn,所以查找、插入、删除操作的时间复杂度也比较稳定,是 O(logn)。
AVL 树 Adelson-Velsky-Landis Tree
AVL 树 是最先被发明的平衡二叉查找树(以发明者的名字来进行的命名),它定义任何节点的左右子树高度相差不超过 1,并且左右两个子树都是一棵平衡二叉树。
AVL 树是一种高度平衡的二叉查找树。虽然查找效率高,但是为了维持高度平衡,插入、删除操作时都需要进行调整(左旋,右旋),需要付出很大的维持成本。
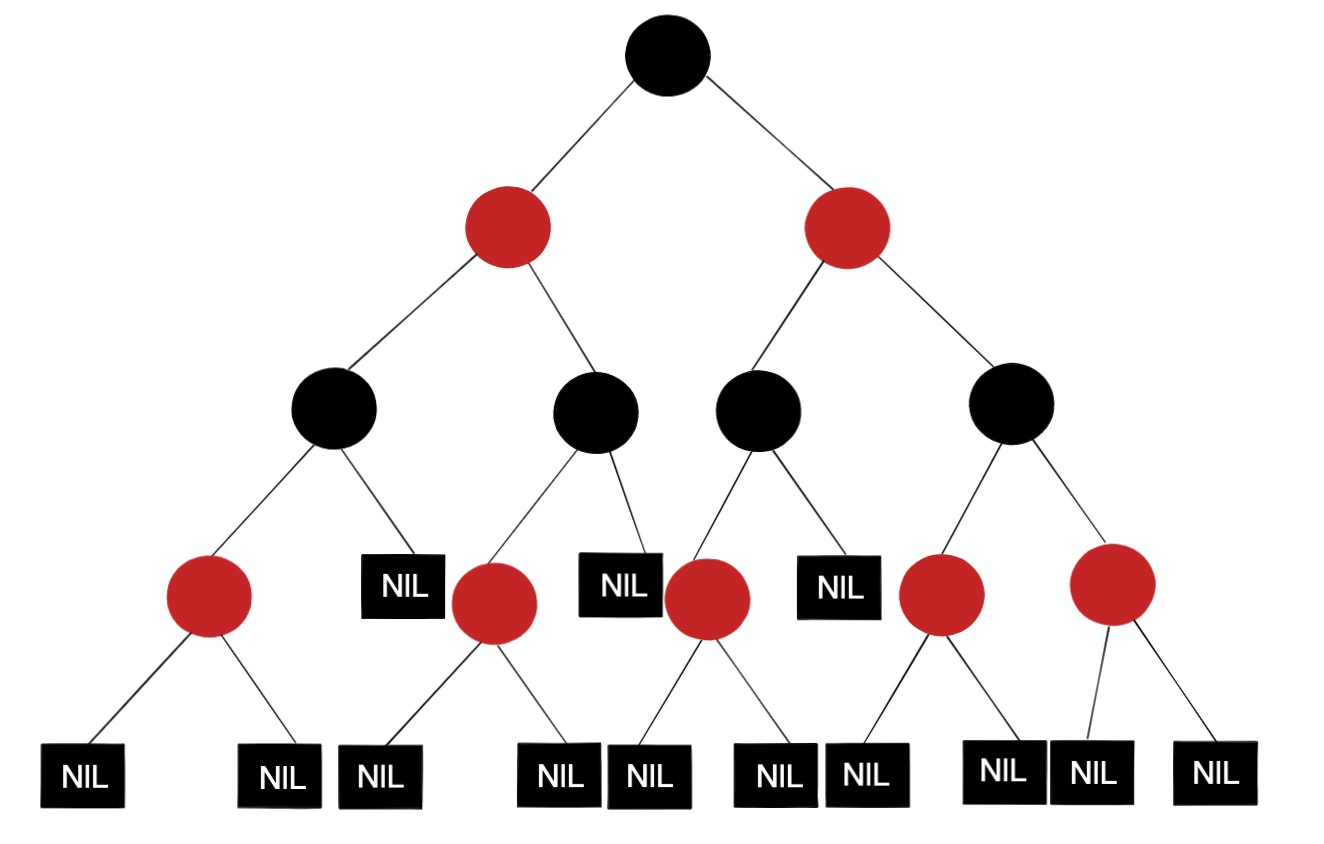
红黑树 Red-balck Tree
红黑树可以被称为“网红树”了,它的出场率相比其他的树要高出一个天际线。与 AVL 树不同,红黑树只是做到了近似平衡,并不是严格意义上的平衡。所以在维护平衡付出的成本上比 AVL 树要低,查找、插入、删除等操作的性能都比较稳定,时间复杂度都是 O(logn)。
一棵合格的红黑树应该满足:
- 每个结点或红或黑
- 根节点是黑色
- 每个叶子节点都是黑色的空节点(叶子节点不存储数据)
- 相邻的节点不能同时为红色,红黑相隔
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点
红黑树在工程上有着大量的应用,因为工程上对性能的稳定性要求是很高的。正因为红黑树的性能比较稳定,它扛起了工程应用上的大旗。
Trie 树
Google、百度一类的搜索引擎强大的关键词提示功能的背后,最基本的原理就 Trie 树,通过空间换时间,利用字符串的公共前缀,降低查询的时间以提高效率。除此之外,还有很多应用,比如:IP 路由中使用了 Trie 树的最长前缀匹配算法,利用转发表选择路径以及 IDE 中的智能提示等。
Trie 树 是一棵非典型的多叉树模型,它和一般的多叉树不同,我们可以对比一下它们结点的数据结构设计。一般的多叉树结点中包含结点值和指向子结点的指针。而 Trie 树的结点中包含的是该结点是否是一个串的结束,以及字母映射表。通过字母映射表我们可以通过一个父结点来获取它所有子结点的值。
在 Trie 树 中查找字符串的时间复杂度是 O(k),k 是要查找的字符串长度。
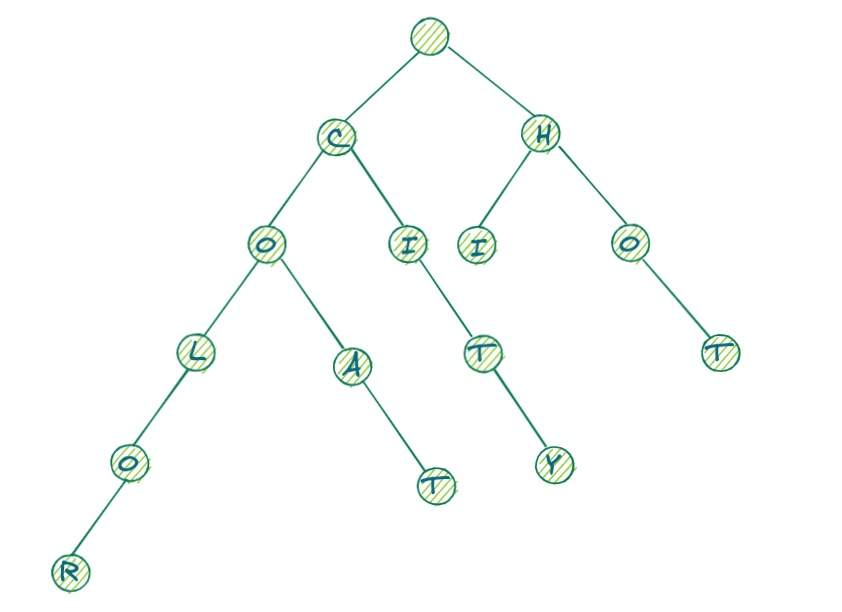
上图中的 Trie 树由 5 个单词构成,分别是 color、coat、city、hi、hot。根结点的值为空。
LeetCode 208.实现 Trie 树
class Trie {
constructor() {
this.root = {};
}
insert(word) {
let curr = this.root;
word.split('').forEach(ch => (curr = curr[ch] = curr[ch] || {}));
curr.isWord = true;
}
traverse(word) {
let curr = this.root;
for (let i = 0; i < word.length; i++) {
if (!curr) return null;
curr = curr[word[i]];
}
return curr;
}
search(word) {
let node = this.traverse(word);
return !!node && !!node.isWord;
}
startsWith(word) {
return !!this.traverse(word);
}
}
B+ 树
我们知道,将索引存储在内容中,查询速度是比存储在磁盘中快的。但是当数据量很大的情况下,索引也随之变大。内存是有限的,我们不得不将索引存储在磁盘中。那么,如何提升从磁盘中读取的效率就成了工程上的关键之一。
大部分关系型数据库的索引,比如 MySQL、Oracle,都是用 B+ 树来实现的。B+ 树比起红黑树更适合构建存储在磁盘中的索引。B+ 树是一个多叉树,在相同个数的数据构建索引时,其高度要低于红黑树。当借助索引查询数据的时,读取 B+ 树索引,需要更少的磁盘 IO 次数。
一个 m 阶的 B 树满足如下特征:
- 每个节点中子节点的个数 k 满足 m > k > m/2,根节点的子节点个数可以不超过 m/2
- 通过双向链表将叶子节点串联在一起,方便按区间查找
- m 叉树只存储索引,并不真正存储数据
- 一般情况,根节点被存储在内存中,其他节点存储在磁盘中
参考
- 《数据结构与算法之美》 王争
往期文章
❤️爱心三连击
1.看到这里了就点个赞支持下吧,你的「赞」是我创作的动力。
2.关注公众号前端食堂,「你的前端食堂,记得按时吃饭」!
3.本文已收录在前端食堂Github github.com/Geekhyt,求个小星星,感谢Star。

