


问题:
- 当前的日志数据集数据格式是不确定的。各个系统都不太一致,难以统一。
- 许多的日志异常检测系统无法做到实时检测,特别的,对于未知类型的异常无法检测。
- 当存下并发日志记录的时候,当前很多流行的工作流模式的异常诊断算法将无法正确的定位异常。
- 现在许多的日志级别异常检测算法仅仅利用了日志中的模板消息,对于其中带有的参数没有进行有效的利用。例如存在这样的场景,日志模板并没有偏离正常的工作流,但是却有参数异常,这时候仅仅利用日志模板无法准确进行异常检测。
解决策略:
-
针对问题1,文中使用了log key extraction 算法,得到了对应的log key 和 parameter列表。 a) 对于每个log key 进行工作流编号,基于预测时间步来生产训练的数据。该数据集用于训练基于日志键值的异常检测模型 b) 基于日志键值对应的参数列表,以同样的方式产生训练数据集。该数据集用于训练基于日志值的异常检测模型。
-
针对问题2,采用了全部正常数据集来训练模型,这样可以识别未知异常。由于全部的正常数据集仍然无法涵盖所有的样例,因此,采用基于用户反馈的模式来对预测阶段的假阳性数据进行权重更新,可以在不用重新训练的情况完善模型。更新过程将为 输入新的训练数据,并调整权重以最小化模型输出与来自错误肯定案例的实际观察值之间的误差。
-
当出现并发日志记录的时候,分析主要存在两种情况:
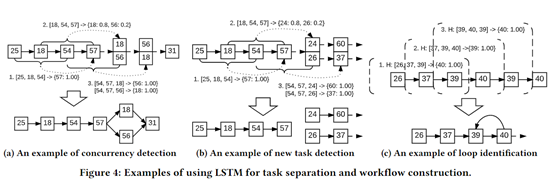
- 文中提出的模型: a) Log Key 的异常检测模型 b) Log Parameter value的异常检测模型 c) 基于用户反馈的权重更新(异常诊断中的工作流)
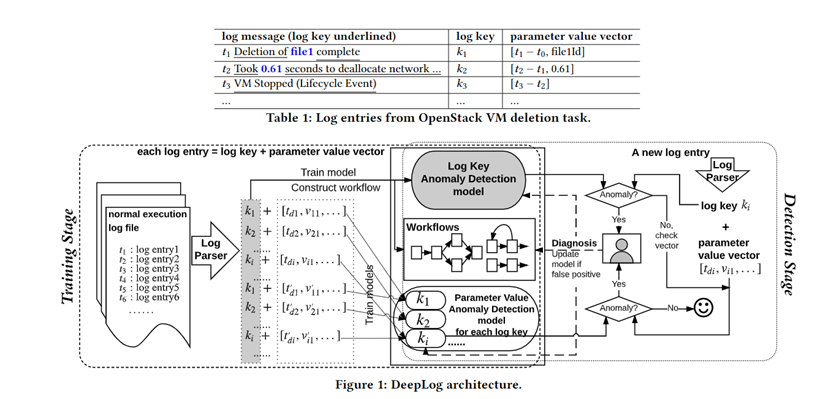
- 首次利用了日志参数值进行了异常的检测,整合到之前的主流方法中,提高了准确率。同时,增加了一个用户反馈的步骤,可以有效的提高模型的实时检测性能。
- 通过提取日志模板的方式,可以实现日志记录级别的预测,同时,日志模板的方式更加合适于构建用于机器学习的数据集。
- Du, Min, et al. "Deeplog: Anomaly detection and diagnosis from system logs through deep learning." Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017.
